SQL in Pandas con Pandasql
SQL in Pandas con Pandasql Come sfruttare al massimo il potere di SQL nel tuo codice Python con l'uso di Pandasql

Se puoi aggiungere solo una competenza – e indiscutibilmente la più importante – alla tua cassetta degli attrezzi per la scienza dei dati, è SQL. Nell’ecosistema di analisi dei dati in Python, però, pandas è una libreria potente e popolare.
Tuttavia, se sei nuovo di pandas, imparare a utilizzare le sue funzioni – per raggruppamenti, aggregazioni, join e altro – può essere scoraggiante. Sarebbe molto più semplice interrogare i tuoi dataframe con SQL. La libreria pandasql ti consente di fare proprio questo!
Quindi impariamo come utilizzare la libreria pandasql per eseguire query SQL su un dataframe di pandas su un set di dati di esempio.
- 5 piattaforme gratuite per creare un solido portfolio di Data Science
- VoAGI News, 5 ottobre 5 libri gratuiti per aiutarti a padroneggiare Python • Le migliori 7 notebook cloud gratuiti per la scienza dei dati
- Massimizza le prestazioni nelle applicazioni di Edge AI
Primi passi con Pandasql
Prima di andare avanti, impostiamo il nostro ambiente di lavoro.
Installazione di pandasql
Se stai utilizzando Google Colab, puoi installare pandasql usando `pip` e seguire il codice:
pip install pandasqlSe stai utilizzando Python sul tuo computer locale, assicurati di avere pandas e Seaborn installati in un ambiente virtuale dedicato per questo progetto. Puoi utilizzare il pacchetto integrato venv per creare e gestire ambienti virtuali.
Sto utilizzando Python 3.11 su Ubuntu LTS 22.04. Quindi le seguenti istruzioni sono per Ubuntu (dovrebbero funzionare anche su un Mac). Se sei su una macchina Windows, segui queste istruzioni per creare e attivare ambienti virtuali.
Per creare un ambiente virtuale (v1) qui, esegui il seguente comando nella tua directory di progetto:
python3 -m venv v1Poi attiva l’ambiente virtuale:
source v1/bin/activateOra installa pandas, seaborn e pandasql:
pip3 install pandas seaborn pandasqlNota: Se non hai già `pip` installato, puoi aggiornare i pacchetti di sistema e installarlo eseguendo: apt install python3-pip.
La funzione `sqldf`
Per eseguire query SQL su un dataframe di pandas, puoi importare ed utilizzare `sqldf` con la seguente sintassi:
from pandasql import sqldf
sqldf(query, globals())Qui,
queryrappresenta la query SQL che desideri eseguire sul dataframe di pandas. Deve essere una stringa contenente una query SQL valida.globals()specifica il namespace globale in cui sono definite il/i dataframe utilizzati nella query.
Interrogazione di un dataframe di pandas con Pandasql
Iniziamo importando i pacchetti necessari e la funzione `sqldf` da pandasql:
import pandas as pd
import seaborn as sns
from pandasql import sqldfPoiché eseguiremo diverse query sul dataframe, possiamo definire una funzione in modo da poterla chiamare passando la query come argomento:
# Definisci una funzione riutilizzabile per eseguire query SQLrun_query = lambda query: sqldf(query, globals())Per tutti gli esempi che seguono, eseguiremo la funzione run_query (che utilizza sqldf() sotto il cofano) per eseguire la query SQL sul dataframe tips_df. Successivamente stamperemo il risultato restituito.
Caricamento del Dataset
Per questo tutorial, utilizzeremo il dataset “tips” incorporato nella libreria Seaborn. Il dataset “tips” contiene informazioni sui consigli di un ristorante, inclusi l’importo totale del conto, l’importo del consiglio, il genere del pagatore, il giorno della settimana e altro ancora.
Carica il dataset “tips” nel dataframe tips_df:
# Carica il dataset "tips" in un dataframe pandas
tips_df = sns.load_dataset("tips")
Esempio 1 – Selezione dei Dati
Ecco la nostra prima query – una semplice istruzione SELECT:
# Semplice query di selezione
query_1 = """SELECT * FROM tips_df LIMIT 10;"""
result_1 = run_query(query_1)
print(result_1)
Come si può vedere, questa query seleziona tutte le colonne dal dataframe tips_df, e limita l’output alle prime 10 righe utilizzando la parola chiave `LIMIT`. È equivalente a eseguire tips_df.head(10) in pandas:
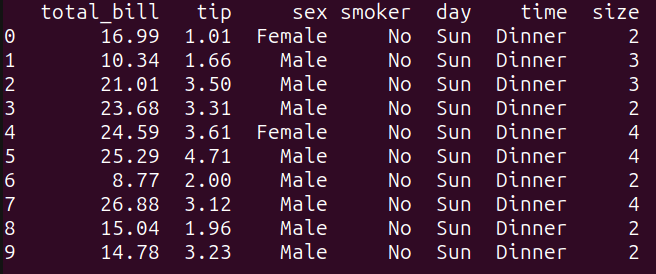
Esempio 2 – Filtraggio Basato su una Condizione
Successivamente, scriviamo una query per filtrare i risultati in base alle condizioni:
# Filtraggio basato su una condizione
query_2 = """SELECT * FROM tips_df WHERE total_bill > 30 AND tip > 5;"""
result_2 = run_query(query_2)
print(result_2)
Questa query filtra il dataframe tips_df in base alla condizione specificata nella clausola WHERE. Seleziona tutte le colonne dal dataframe tips_df in cui il ‘total_bill’ è maggiore di 30 e l’importo del consiglio ‘tip’ è maggiore di 5.
Eseguendo la query_2 si ottiene il seguente risultato:
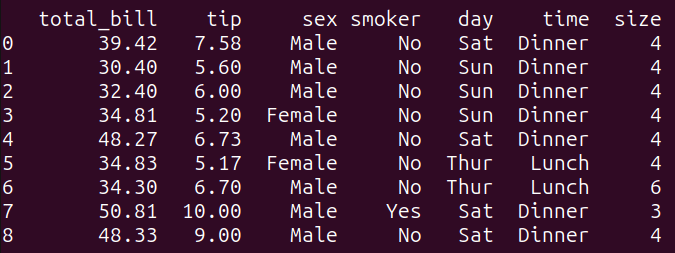
Esempio 3 – Raggruppamento e Aggregazione
Eseguiamo la seguente query per ottenere l’importo medio del conto raggruppato per giorno:
# Raggruppamento e aggregazione
query_3 = """SELECT day, AVG(total_bill) as avg_bill FROM tips_df GROUP BY day;"""
result_3 = run_query(query_3)
print(result_3)
Ecco l’output:
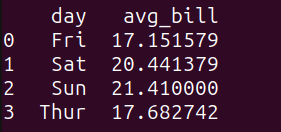
Vediamo che l’importo medio del conto nei fine settimana è leggermente più alto.
Prendiamo un altro esempio per il raggruppamento e le aggregazioni. Considera la seguente query:
query_4 = """SELECT day, COUNT(*) as num_transactions, AVG(total_bill) as avg_bill, MAX(tip) as max_tip FROM tips_df GROUP BY day;"""
result_4 = run_query(query_4)
print(result_4)
La query query_4 raggruppa i dati nel dataframe tips_df sulla colonna ‘day’ e calcola le seguenti funzioni di aggregazione per ogni gruppo:
num_transactions: il conteggio delle transazioni,avg_bill: la media della colonna ‘total_bill’, emax_tip: il valore massimo della colonna ‘tip’.
Come si può vedere, otteniamo le quantità sopra elencate raggruppate per giorno:
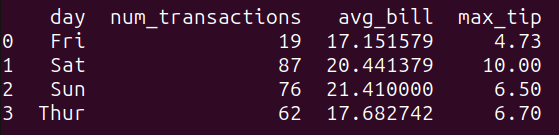
Esempio 4 – Sottoquery
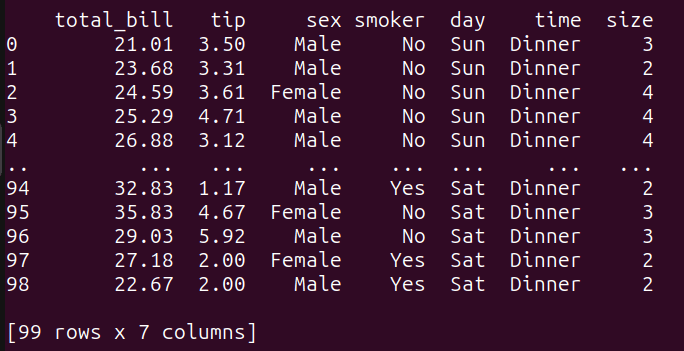
Aggiungiamo una query di esempio che utilizza una sottoquery:
# sottoqueryquery_5 = """SELECT *FROM tips_dfWHERE total_bill > (SELECT AVG(total_bill) FROM tips_df);"""result_5 = run_query(query_5)print(result_5)Qui,
- La sottoquery interna calcola il valore medio della colonna ‘total_bill’ dal dataframe
tips_df. - La query esterna seleziona quindi tutte le colonne dal dataframe
tips_dfin cui ‘total_bill’ è maggiore del valore medio calcolato.
Eseguendo la query_5 si ottiene il seguente risultato:
Esempio 5 – Unire due DataFrame
Abbiamo solo un dataframe. Per eseguire una semplice unione, creiamo un altro dataframe in questo modo:
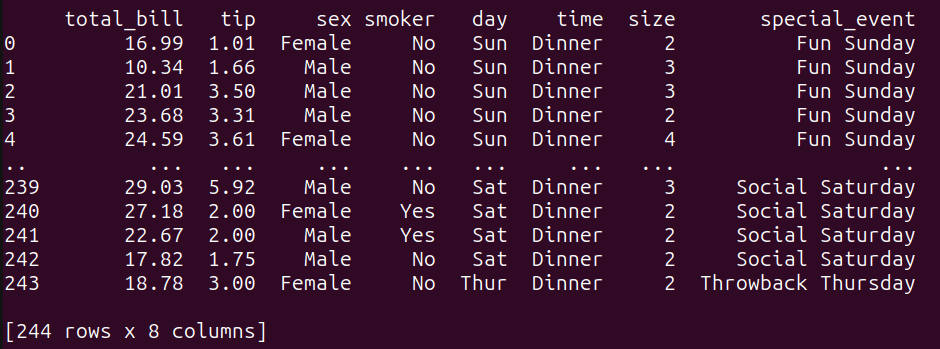
# Creiamo un altro DataFrame da unire a tips_dfother_data = pd.DataFrame({ 'day': ['Thur','Fri', 'Sat', 'Sun'], 'special_event': ['Throwback Thursday', 'Feel Good Friday', 'Social Saturday','Fun Sunday', ]})Il dataframe other_data associa ogni giorno a un evento speciale.
Uniamo ora il tips_df e il other_data dataframe sulla colonna comune ‘day’ tramite una LEFT JOIN:
query_6 = """SELECT t.*, o.special_eventFROM tips_df tLEFT JOIN other_data o ON t.day = o.day;"""result_6 = run_query(query_6)print(result_6)Ecco il risultato dell’operazione di unione:
Conclusione e prossimi passi
In questo tutorial, abbiamo visto come eseguire query SQL su dataframe pandas utilizzando pandasql. Anche se pandasql semplifica notevolmente l’interrogazione dei dataframe con SQL, ci sono alcune limitazioni.
La principale limitazione è che pandasql può essere più lento rispetto a pandas nativo. Quindi cosa dovresti fare? Beh, se devi effettuare analisi dei dati con pandas, puoi utilizzare pandasql per interrogare i dataframe quando stai imparando pandas – e ti stai avvicinando rapidamente. Successivamente, puoi passare a pandas o a un’altra libreria come Polars una volta che ti senti a tuo agio con pandas.
Per fare i primi passi in questa direzione, prova a scrivere ed eseguire gli equivalenti pandas delle query SQL che abbiamo finora eseguito. Tutti gli esempi di codice utilizzati in questo tutorial sono su GitHub. Continua a programmare! Bala Priya C è uno sviluppatore e scrittore tecnico dell’India. Le piace lavorare all’intersezione tra matematica, programmazione, data science e content creation. Le sue aree di interesse e competenza includono DevOps, data science e natural language processing. Ama leggere, scrivere, programmare e bere caffè! Attualmente, sta lavorando per imparare e condividere le sue conoscenze con la comunità degli sviluppatori attraverso la scrittura di tutorial, guide pratiche, articoli di opinione e altro ancora.






