Intelligenza Artificiale per il gioco da tavolo Diplomacy
'IA per il gioco Diplomacy'
Gli agenti cooperano meglio comunicando, negoziando e sanzionando le promesse infrante aiuta a mantenerli onesti
La comunicazione e la cooperazione di successo sono state cruciali per aiutare le società a progredire nel corso della storia. Gli ambienti chiusi dei giochi da tavolo possono fungere da sandbox per modellare e investigare l’interazione e la comunicazione, e possiamo imparare molto giocandoli. Nel nostro recente articolo, pubblicato oggi su Nature Communications, mostriamo come gli agenti artificiali possano utilizzare la comunicazione per cooperare meglio nel gioco da tavolo Diplomacy, un dominio vibrante nella ricerca sull’intelligenza artificiale (AI), noto per la sua attenzione alla costruzione di alleanze.
Diplomacy è una sfida in quanto ha regole semplici ma una complessità emergente elevata a causa delle forti interdipendenze tra i giocatori e del suo immenso spazio di azione. Per aiutare a risolvere questa sfida, abbiamo progettato algoritmi di negoziazione che consentono agli agenti di comunicare e concordare piani comuni, permettendo loro di superare gli agenti che non hanno questa capacità.
La cooperazione è particolarmente difficile quando non possiamo fare affidamento sui nostri pari per mantenere le promesse. Utilizziamo Diplomacy come sandbox per esplorare cosa succede quando gli agenti possono deviare dai loro accordi passati. La nostra ricerca illustra i rischi che sorgono quando agenti complessi sono in grado di falsare le loro intenzioni o ingannare gli altri riguardo ai loro piani futuri, il che porta a un’altra grande domanda: quali sono le condizioni che favoriscono una comunicazione e un lavoro di squadra affidabili?
Mostriamo che la strategia di sanzionare i pari che rompono i contratti riduce drasticamente i vantaggi che possono ottenere abbandonando i loro impegni, promuovendo così una comunicazione più onesta.
- Programmazione competitiva con AlphaCode
- Annuncio di Google DeepMind
- Come possiamo integrare i valori umani nell’IA?
Cos’è Diplomacy e perché è importante?
Giochi come scacchi, poker, Go e molti videogiochi sono sempre stati un terreno fertile per la ricerca sull’IA. Diplomacy è un gioco a sette giocatori di negoziazione e formazione di alleanze, giocato su una vecchia mappa dell’Europa suddivisa in province, in cui ogni giocatore controlla più unità (regole di Diplomacy). Nella versione standard del gioco, chiamata Press Diplomacy, ogni turno include una fase di negoziazione, dopo la quale tutti i giocatori rivelano le loro mosse scelte contemporaneamente.
Il cuore di Diplomacy è la fase di negoziazione, in cui i giocatori cercano di concordare le loro prossime mosse. Ad esempio, un’unità può supportare un’altra unità, consentendole di superare la resistenza delle altre unità, come illustrato qui:

Gli approcci computazionali a Diplomacy sono stati studiati dagli anni ’80, molti dei quali sono stati esplorati in una versione più semplice del gioco chiamata No-Press Diplomacy, in cui la comunicazione strategica tra i giocatori non è consentita. I ricercatori hanno anche proposto protocolli di negoziazione amichevoli per il computer, a volte chiamati “Restricted-Press”.
Cosa abbiamo studiato?
Utilizziamo Diplomacy come analogia per la negoziazione nel mondo reale, fornendo metodi per gli agenti AI per coordinare le loro mosse. Prendiamo i nostri agenti di Diplomacy non comunicanti e li potenziamo per giocare a Diplomacy con la comunicazione, dandogli un protocollo per negoziare contratti per un piano d’azione comune. Chiamiamo questi agenti potenziati Negoziatori di base, e sono vincolati dai loro accordi.

Consideriamo due protocolli: il Protocollo di Proposta Reciproca e il Protocollo di Proposta-Scelta, discussi in dettaglio nel documento completo. I nostri agenti utilizzano algoritmi che identificano accordi reciprocamente vantaggiosi simulando come il gioco potrebbe svolgersi in base a vari contratti. Utilizziamo la Soluzione di Contrattazione di Nash dalla teoria dei giochi come fondamento razionale per identificare accordi di alta qualità. Il gioco potrebbe svolgersi in molti modi a seconda delle azioni dei giocatori, quindi i nostri agenti utilizzano simulazioni di Monte Carlo per vedere cosa potrebbe accadere al turno successivo.
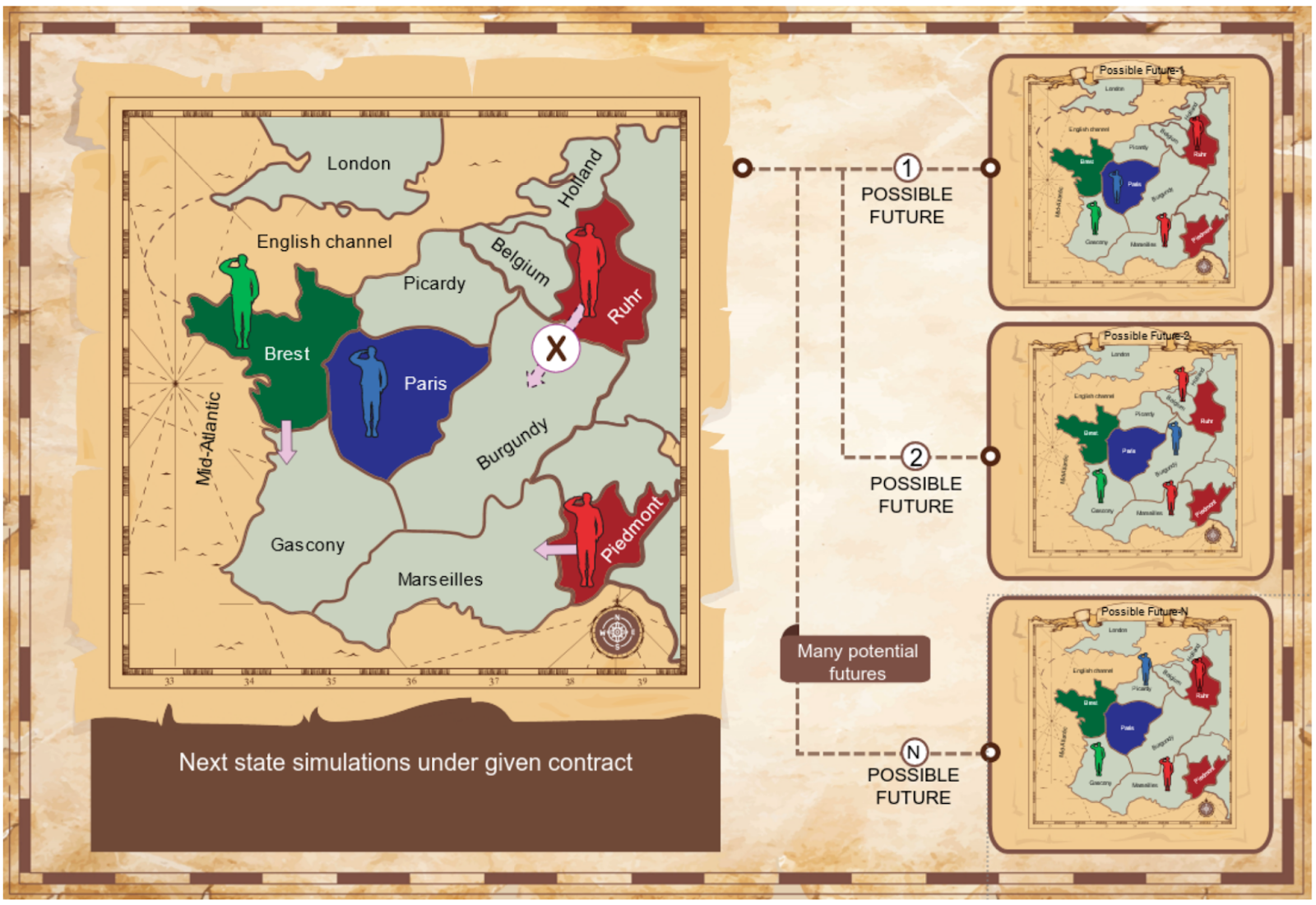
I nostri esperimenti mostrano che il nostro meccanismo di negoziazione consente agli Agenti di Riferimento di superare significativamente gli agenti non comunicanti di base.

Agenti che infrangono gli accordi
In Diplomazia, gli accordi presi durante la negoziazione non sono vincolanti (la comunicazione è “parlare a buon mercato”). Ma cosa succede quando gli agenti che si accordano su un contratto in un turno lo violano nel turno successivo? In molti contesti della vita reale le persone si accordano per agire in un certo modo, ma poi non riescono a mantenere i loro impegni. Per consentire la cooperazione tra agenti di intelligenza artificiale o tra agenti e esseri umani, dobbiamo esaminare il potenziale rischio che gli agenti infrangano strategicamente i loro accordi e individuare modi per rimediare a questo problema. Abbiamo utilizzato la Diplomazia per studiare come la possibilità di abbandonare i nostri impegni erode la fiducia e la cooperazione, e identificare le condizioni che favoriscono una cooperazione onesta.
Quindi consideriamo gli Agenti Devianti, che superano gli Agenti di Riferimento onesti deviando dai contratti concordati. I Devianti Semplici semplicemente “dimenticano” di aver accettato un contratto e si muovono come desiderano. I Devianti Condizionali sono più sofisticati e ottimizzano le loro azioni supponendo che gli altri giocatori che hanno accettato un contratto agiranno in conformità ad esso.

Mostriamo che gli “Deviator” semplici e condizionali superano significativamente i “Baseline Negotiators”, i “Conditional Deviators” lo fanno in modo schiacciante.

Incentivare gli agenti ad essere onesti
Successivamente affrontiamo il problema della deviazione utilizzando Agenti Difensivi, che reagiscono negativamente alle deviazioni. Investigando i Negoziatori Binari, che semplicemente interrompono le comunicazioni con gli agenti che violano un accordo con loro. Ma evitare è una reazione moderata, quindi sviluppiamo anche Agenti Sanzionatori, che non prendono alla leggera il tradimento, ma modificano invece i loro obiettivi per cercare attivamente di abbassare il valore del deviatore – un avversario con un rancore! Mostriamo che entrambi i tipi di Agenti Difensivi riducono il vantaggio della deviazione, in particolare gli Agenti Sanzionatori.

Infine, introduciamo i Deviator Appresi, che adattano e ottimizzano il loro comportamento contro gli Agenti Sanzionatori in più giochi, cercando di rendere meno efficaci le difese sopra menzionate. Un Deviator Appreso romperà un contratto solo quando i vantaggi immediati della deviazione sono abbastanza alti e la capacità dell’altro agente di vendicarsi è abbastanza bassa. Nella pratica, i Deviator Appresi occasionalmente rompono i contratti alla fine del gioco e, facendolo, ottengono un leggero vantaggio sugli Agenti Sanzionatori. Tuttavia, tali sanzioni spingono il Deviator Appreso ad onorare più del 99,7% dei suoi contratti.
Esaminiamo anche le possibili dinamiche di apprendimento della sanzione e della deviazione: cosa succede quando gli Agenti Sanzionatori possono anche deviare dai contratti e quale incentivo c’è per smettere di sanzionare quando questo comportamento è costoso. Tali problemi possono erodere gradualmente la cooperazione, quindi potrebbero essere necessari meccanismi aggiuntivi come l’interazione ripetuta in più giochi o l’utilizzo di sistemi di fiducia e reputazione.
Il nostro articolo lascia molte domande aperte per future ricerche: è possibile progettare protocolli più sofisticati per incoraggiare comportamenti ancora più onesti? Come si potrebbe gestire la combinazione di tecniche di comunicazione e informazioni imperfette? Infine, quali altri meccanismi potrebbero scoraggiare la violazione degli accordi? Costruire sistemi AI equi, trasparenti e affidabili è un argomento estremamente importante ed è parte integrante della missione di DeepMind. Studiare queste domande in ambienti controllati come Diplomacy ci aiuta a comprendere meglio le tensioni tra cooperazione e competizione che potrebbero esistere nel mondo reale. In definitiva, crediamo che affrontare queste sfide ci permetta di capire meglio come sviluppare sistemi AI in linea con i valori e le priorità della società.
Leggi il nostro articolo completo qui.
.jpg)

.png)



