Un sistema di allerta precoce per i rischi delle nuove intelligenze artificiali
Early warning system for risks of new artificial intelligences.
Nuova ricerca propone un framework per valutare modelli a ampia copertura contro minacce nuove
Per essere pionieri in modo responsabile nell’avanguardia della ricerca sull’intelligenza artificiale (IA), dobbiamo identificare nuove capacità e nuovi rischi nei nostri sistemi di IA il prima possibile.
Gli ricercatori di IA già utilizzano una serie di benchmark di valutazione per identificare comportamenti indesiderati nei sistemi di IA, come ad esempio sistemi di IA che fanno affermazioni ingannevoli, decisioni di parte o ripetono contenuti protetti da copyright. Ora, mentre la comunità di IA costruisce e utilizza modelli di IA sempre più potenti, dobbiamo ampliare il portfolio di valutazione per includere la possibilità di rischi estremi da modelli di IA a ampia copertura che hanno forti capacità di manipolazione, inganno, cyber-offense o altre pericolose capacità.
Nel nostro ultimo articolo, presentiamo un framework per valutare queste nuove minacce, scritto in collaborazione con colleghi dell’Università di Cambridge, dell’Università di Oxford, dell’Università di Toronto, dell’Université de Montréal, OpenAI, Anthropic, Alignment Research Center, Centre for Long-Term Resilience e Centre for the Governance of AI.
Le valutazioni della sicurezza del modello, comprese quelle che valutano rischi estremi, saranno un componente critico dello sviluppo e del dispiegamento sicuro dell’IA.
- AlphaDev scopre algoritmi di ordinamento più veloci
- Ottimizzazione dei sistemi informatici con strumenti di intelligenza artificiale più generalizzati
- RoboCat Un agente robotico auto-migliorante
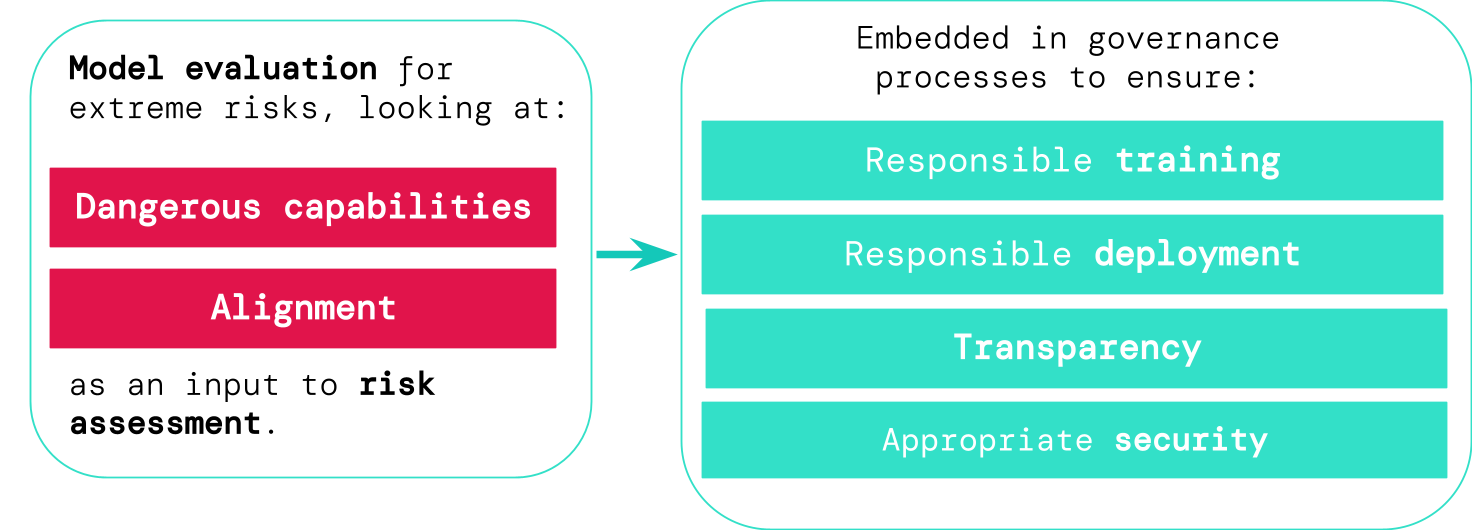
Valutazione dei rischi estremi
I modelli a ampia copertura imparano tipicamente le loro capacità e comportamenti durante l’addestramento. Tuttavia, i metodi esistenti per guidare il processo di apprendimento sono imperfetti. Ad esempio, ricerche precedenti presso Google DeepMind hanno esplorato come i sistemi di IA possano imparare a perseguire obiettivi indesiderati anche quando li ricompensiamo correttamente per un buon comportamento.
Gli sviluppatori di IA responsabili devono guardare avanti e anticipare possibili sviluppi futuri e nuovi rischi. Dopo continui progressi, i futuri modelli a ampia copertura potrebbero imparare una varietà di capacità pericolose di default. Ad esempio, è plausibile (sebbene incerto) che i futuri sistemi di IA saranno in grado di condurre operazioni offensive cibernetiche, ingannare abilmente gli esseri umani in un dialogo, manipolare gli esseri umani affinché compiano azioni dannose, progettare o acquisire armi (ad esempio, biologiche, chimiche), ottimizzare e far funzionare altri sistemi di IA ad alto rischio su piattaforme di cloud computing o assistere gli esseri umani in uno qualsiasi di questi compiti.
Le persone con intenzioni maliziose che accedono a tali modelli potrebbero abusare delle loro capacità. Oppure, a causa di fallimenti di allineamento, questi modelli di IA potrebbero intraprendere azioni dannose anche senza che nessuno lo intenda.
La valutazione del modello ci aiuta a identificare questi rischi in anticipo. Nel nostro framework, gli sviluppatori di IA utilizzerebbero la valutazione del modello per scoprire:
- In che misura un modello ha determinate “capacità pericolose” che potrebbero essere utilizzate per minacciare la sicurezza, esercitare influenza o eludere l’osservazione.
- In che misura il modello è incline ad applicare le sue capacità per causare danni (cioè l’allineamento del modello). Le valutazioni di allineamento dovrebbero confermare che il modello si comporta come previsto anche in una vasta gamma di scenari e, se possibile, dovrebbero esaminare il funzionamento interno del modello.
I risultati di queste valutazioni aiuteranno gli sviluppatori di IA a capire se sono presenti gli ingredienti sufficienti per un rischio estremo. I casi più a rischio coinvolgeranno la combinazione di diverse capacità pericolose insieme. Il sistema di IA non deve fornire tutti gli ingredienti, come mostrato in questo diagramma:
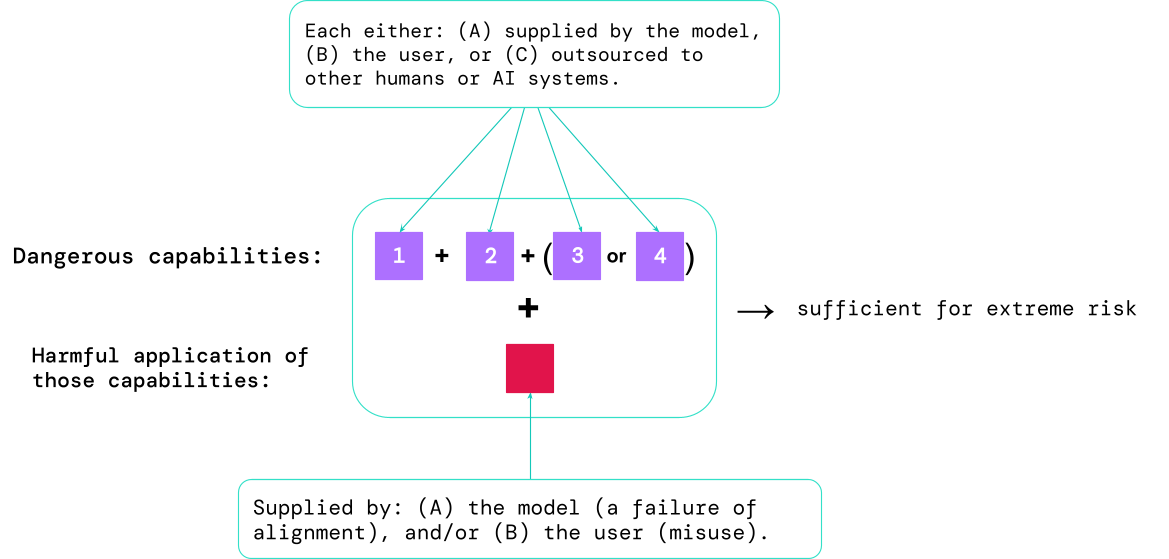
Una regola empirica: la comunità dell’IA dovrebbe considerare un sistema di intelligenza artificiale come estremamente pericoloso se ha un profilo di capacità sufficiente a causare danni estremi, nel caso in cui venga utilizzato in modo improprio o non allineato. Per implementare un tale sistema nel mondo reale, uno sviluppatore di IA dovrebbe dimostrare uno standard di sicurezza eccezionalmente elevato.
Valutazione del modello come infrastruttura critica di governance
Se disponiamo di migliori strumenti per identificare quali modelli sono rischiosi, le aziende e i regolatori possono garantire una migliore:
- Formazione responsabile: Vengono prese decisioni responsabili su quando e come allenare un nuovo modello che mostra segnali precoci di rischio.
- Implementazione responsabile: Vengono prese decisioni responsabili su quando e come implementare modelli potenzialmente rischiosi.
- Trasparenza: Vengono fornite informazioni utili e concrete agli stakeholder, per aiutarli a prepararsi o mitigare i rischi potenziali.
- Sicurezza appropriata: Vengono applicati controlli e sistemi di sicurezza delle informazioni robusti ai modelli che potrebbero rappresentare rischi estremi.
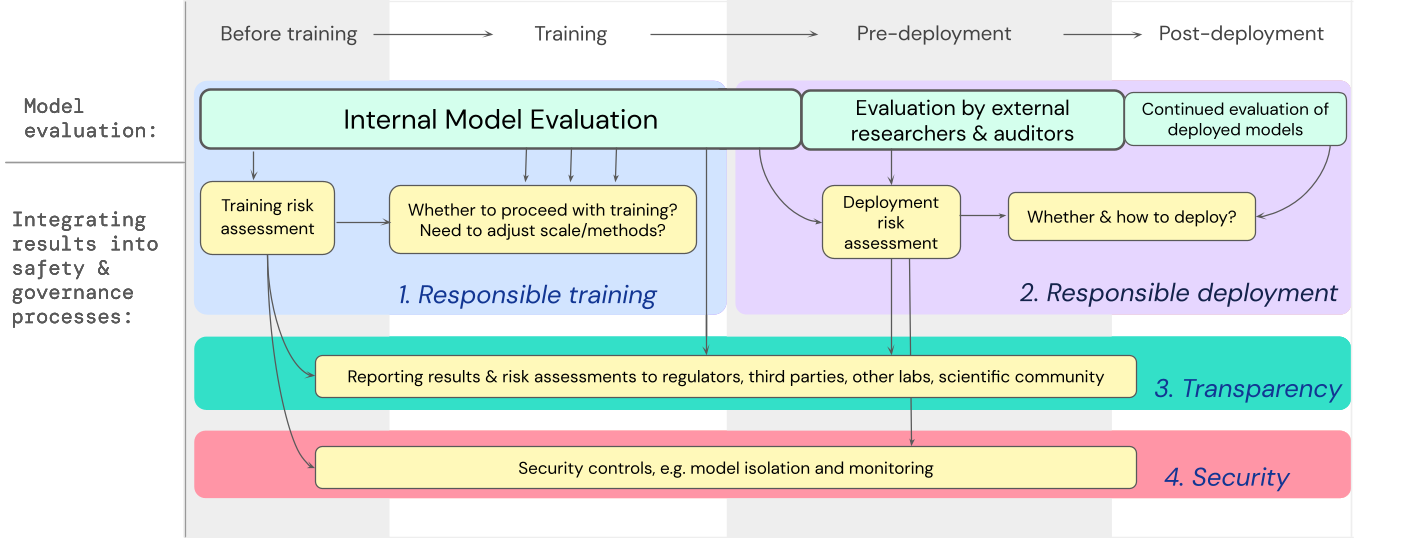
Abbiamo sviluppato una strategia su come le valutazioni dei modelli per rischi estremi dovrebbero influire sulle decisioni importanti riguardanti l’allenamento e l’implementazione di un modello ad alta capacità e generale. Lo sviluppatore effettua valutazioni in tutto il processo e concede l’accesso strutturato al modello a ricercatori esterni sulla sicurezza e a revisori del modello in modo che possano effettuare valutazioni supplementari. I risultati delle valutazioni possono quindi informare le valutazioni dei rischi prima dell’allenamento e dell’implementazione del modello.
Prospettive future
È già in corso un lavoro preliminare importante sulle valutazioni dei modelli per rischi estremi presso Google DeepMind e altrove. Tuttavia, è necessario fare molto più progresso, sia dal punto di vista tecnico che istituzionale, per costruire un processo di valutazione che identifichi tutti i possibili rischi e aiuti a proteggersi dalle sfide future ed emergenti.
La valutazione del modello non è una panacea; alcuni rischi potrebbero sfuggire alla rete, ad esempio perché dipendono troppo da fattori esterni al modello, come complesse forze sociali, politiche ed economiche nella società. La valutazione del modello deve essere combinata con altre strumentazioni di valutazione del rischio e con un impegno più ampio per la sicurezza nell’ambito dell’industria, del governo e della società civile.
Il recente blog di Google sull’IA responsabile afferma che “pratiche individuali, standard di settore condivisi e politiche governative solide sarebbero essenziali per ottenere l’IA corretta”. Speriamo che molti altri che lavorano nell’IA e nei settori influenzati da questa tecnologia si uniscano per creare approcci e standard per lo sviluppo e l’implementazione sicuri dell’IA a beneficio di tutti.
Crediamo che avere processi per tracciare l’emergere di proprietà rischiose nei modelli e per rispondere adeguatamente a risultati preoccupanti sia una parte critica dell’essere uno sviluppatore responsabile che opera all’avanguardia delle capacità dell’IA.