Pic2Word Mappare immagini a parole per il recupero di immagini composte senza training
Pic2Word mappare immagini a parole senza training per il recupero di immagini composte.
Scritto da Kuniaki Saito, Ricercatore Studente, Google Research, Cloud AI Team, e Kihyuk Sohn, Ricercatore Scientista, Google Research
Il recupero delle immagini svolge un ruolo cruciale nei motori di ricerca. Tipicamente, gli utenti si affidano sia all’immagine che al testo come query per recuperare un’immagine desiderata. Tuttavia, il recupero basato sul testo ha i suoi limiti, poiché descrivere accuratamente l’immagine target usando le parole può essere difficile. Ad esempio, quando si cerca un articolo di moda, gli utenti possono desiderare un articolo il cui attributo specifico, ad esempio il colore di un logo o il logo stesso, sia diverso da quello che trovano in un sito web. Tuttavia, cercare l’articolo in un motore di ricerca esistente non è banale poiché descrivere precisamente l’articolo di moda con il testo può essere difficile. Per affrontare questo fatto, il recupero di immagini composte (CIR) recupera immagini basate su una query che combina sia un’immagine che un campione di testo che fornisce istruzioni su come modificare l’immagine per adattarla al target di recupero desiderato. Pertanto, CIR consente il recupero preciso dell’immagine target combinando immagini e testo.
Tuttavia, i metodi di CIR richiedono grandi quantità di dati etichettati, ovvero triplette di 1) immagine di query, 2) descrizione e 3) immagine di destinazione. La raccolta di tali dati etichettati è costosa e i modelli addestrati su questi dati sono spesso personalizzati per un caso d’uso specifico, limitando la loro capacità di generalizzare a diversi dataset.
Per affrontare queste sfide, in “Pic2Word: Mapping Pictures to Words for Zero-shot Composed Image Retrieval”, proponiamo un compito chiamato Zero-shot CIR (ZS-CIR). In ZS-CIR, miriamo a costruire un singolo modello CIR che esegua una varietà di compiti CIR, come la composizione degli oggetti, la modifica degli attributi o la conversione di dominio, senza richiedere dati etichettati di triplette. Invece, proponiamo di addestrare un modello di recupero utilizzando coppie di immagini-didascalia su larga scala e immagini non etichettate, che sono considerevolmente più facili da raccogliere rispetto ai dataset CIR supervisionati su larga scala. Per favorire la riproducibilità e far progredire ulteriormente questo ambito, rilasciamo anche il codice.
- I nuovi robot di Amazon stanno portando una rivoluzione dell’automazione.
- L’Intelligenza Artificiale combatte il flagello dei detriti spaziali
- Testare le auto senza conducente in un ambiente virtuale
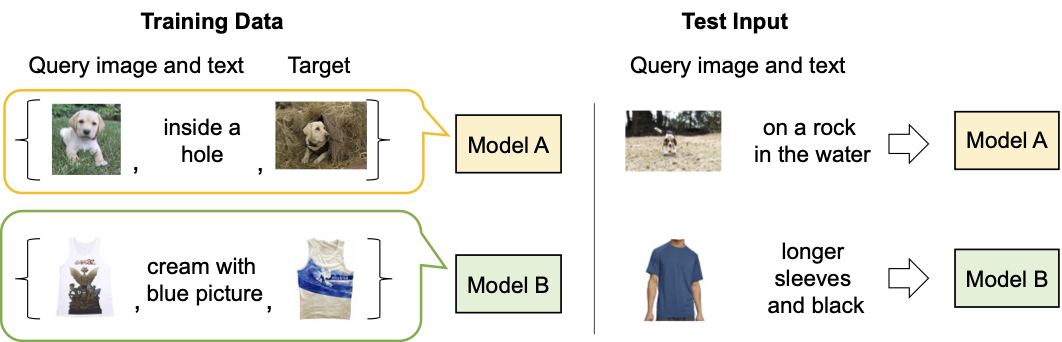 |
| Descrizione del modello di recupero immagini composte esistente. |
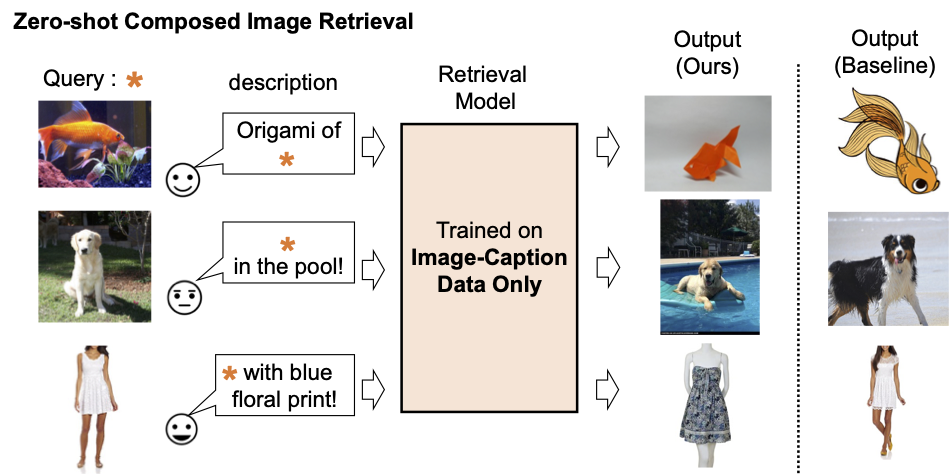 |
| Addestriamo un modello di recupero immagini composte utilizzando solo dati immagine-didascalia. Il nostro modello recupera immagini allineate con la composizione dell’immagine di query e il testo. |
Panoramica del metodo
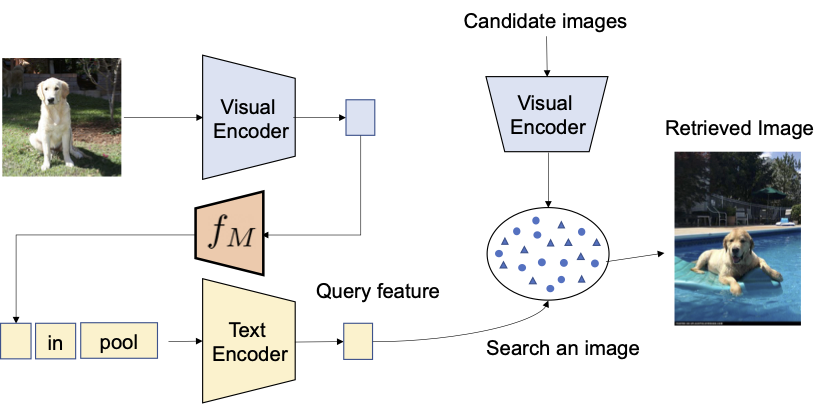
Proponiamo di sfruttare le capacità linguistiche dell’encoder di linguaggio nel modello pre-addestrato contrastivo di linguaggio-immagine (CLIP), che eccelle nella generazione di incapsulamenti linguistici semanticamente significativi per una vasta gamma di concetti e attributi testuali. A tal fine, utilizziamo un sotto-modulo di mappatura leggero in CLIP progettato per mappare un’immagine in ingresso (ad esempio, una foto di un gatto) dallo spazio di incapsulamento dell’immagine a un token di parola (ad esempio, “gatto”) nello spazio di input testuale. L’intera rete è ottimizzata con la perdita contrastiva visione-linguaggio per garantire che gli spazi di incapsulamento visivo e di testo siano il più vicini possibile dato una coppia di immagine e descrizione testuale. Quindi, l’immagine di query può essere trattata come se fosse una parola. Questo consente la composizione flessibile e senza soluzione di continuità delle caratteristiche dell’immagine di query e delle descrizioni di testo da parte dell’encoder di linguaggio. Chiamiamo il nostro metodo Pic2Word e forniamo una panoramica del suo processo di addestramento nella figura sottostante. Vogliamo che il token mappato s rappresenti l’immagine di input sotto forma di token di parola. Quindi, addestriamo la rete di mappatura a ricostruire l’incapsulamento dell’immagine nell’incapsulamento del linguaggio, p . In particolare, ottimizziamo la perdita contrastiva proposta in CLIP calcolata tra l’incapsulamento visivo v e l’incapsulamento testuale p .
 |
| Allenamento della rete di mappatura (f M) utilizzando solo immagini non etichettate. Ottimizziamo solo la rete di mappatura con un codificatore visivo e testuale congelato. |
Dato il network di mappatura addestrato, possiamo considerare un’immagine come un token di parole e abbinarla alla descrizione testuale per comporre flessibilmente la query congiunta immagine-testo come mostrato nella figura sottostante.
 |
| Con la rete di mappatura addestrata, consideriamo l’immagine come un token di parole e la abbiniamo alla descrizione testuale per comporre flessibilmente la query congiunta immagine-testo. |
Valutazione
Svolgiamo una serie di esperimenti per valutare le prestazioni di Pic2Word su una varietà di compiti CIR.
Conversione di dominio
Valutiamo innanzitutto la capacità di composizionalità del metodo proposto sulla conversione di dominio: data un’immagine e il nuovo dominio desiderato per l’immagine (ad esempio, scultura, origami, cartoni animati, giocattolo), l’output del sistema dovrebbe essere un’immagine con lo stesso contenuto, ma nel nuovo dominio o stile desiderato. Come illustrato di seguito, valutiamo la capacità di comporre le informazioni sulla categoria e la descrizione di dominio fornite rispettivamente come immagine e testo. Valutiamo la conversione da immagini reali a quattro domini utilizzando ImageNet e ImageNet-R.
Per confrontare con approcci che non richiedono dati di addestramento supervisionato, selezioniamo tre approcci: (i) solo immagine esegue solo il recupero con l’incorporamento visivo, (ii) solo testo utilizza solo l’incorporamento testuale e (iii) immagine + testo calcola la media dell’incorporamento visivo e testuale per comporre la query. Il confronto con (iii) mostra l’importanza di comporre immagine e testo utilizzando un codificatore linguistico. Confrontiamo anche con Combiner, che addestra il modello CIR su Fashion-IQ o CIRR.
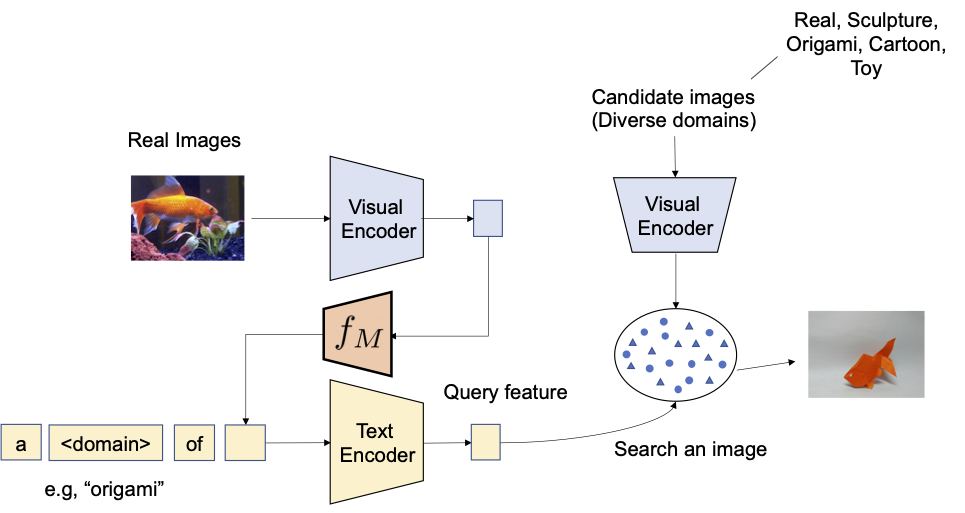 |
| Il nostro obiettivo è convertire il dominio dell’immagine di query di input in quello descritto con il testo, ad esempio origami. |
Come mostrato nella figura sottostante, il nostro approccio proposto supera di gran lunga i modelli di confronto di base.
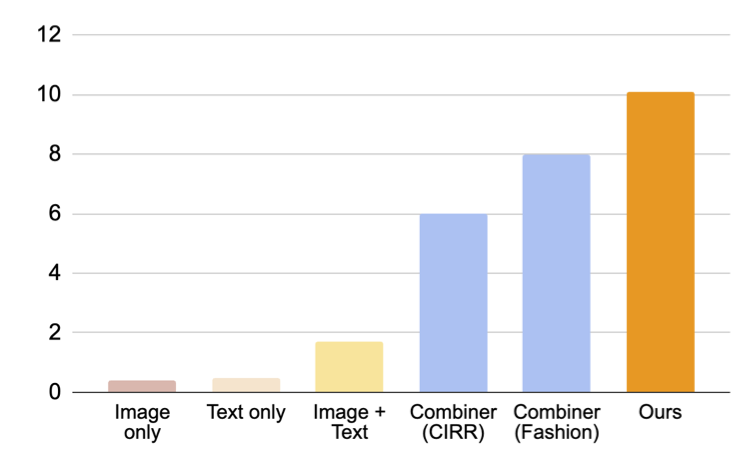 |
| Risultati (recall @10, ovvero la percentuale di istanze rilevanti nelle prime 10 immagini recuperate) per il recupero di immagini composte per la conversione di dominio. |
Composizione degli attributi di moda
Successivamente, valutiamo la composizione degli attributi di moda, come il colore del tessuto, il logo e la lunghezza della manica, utilizzando il dataset Fashion-IQ. La figura sottostante illustra l’output desiderato dato la query.
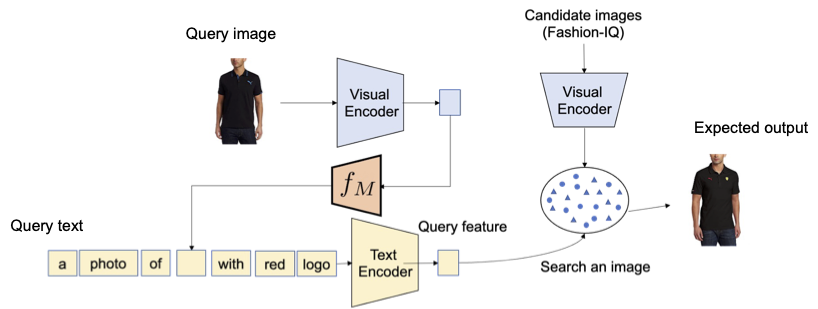 |
| Panoramica del recupero di immagini composte per gli attributi di moda. |
Nella figura sottostante, presentiamo un confronto con i modelli di confronto, compresi i modelli di confronto supervisionati che utilizzano triplette per addestrare il modello di recupero di immagini composte (CIR): (i) CB utilizza la stessa architettura del nostro approccio, (ii) CIRPLANT, ALTEMIS, MAAF utilizzano una struttura più piccola, come ResNet50. Il confronto con questi approcci ci permetterà di capire quanto bene si comporta il nostro approccio zero-shot in questo compito.
Anche se CB supera il nostro approccio, il nostro metodo si comporta meglio dei modelli di confronto supervisionati con strutture più piccole. Questo risultato suggerisce che utilizzando un modello CLIP robusto, possiamo addestrare un modello CIR altamente efficace senza richiedere triplette annotate.
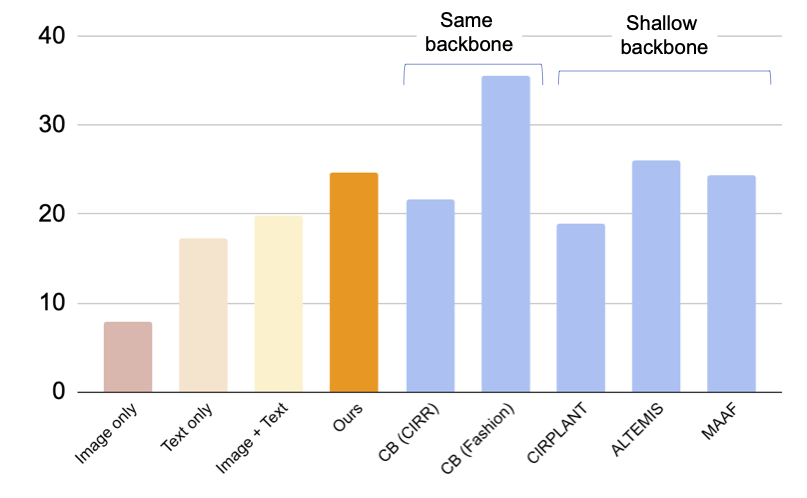 |
| Risultati (recall @10, ovvero la percentuale di istanze rilevanti nelle prime 10 immagini recuperate) per il recupero di immagini composte per il dataset Fashion-IQ (più alto è meglio). Le barre blu chiaro addestrano il modello utilizzando triplette. Si noti che il nostro approccio si comporta allo stesso livello di questi modelli di confronto supervisionati con strutture superficiali (più piccole). |
Risultati qualitativi
Mostriamo alcuni esempi nella figura sottostante. Rispetto a un metodo di confronto che non richiede dati di addestramento supervisionati (media di testo + immagine), il nostro approccio fa un lavoro migliore nel recuperare correttamente l’immagine target.
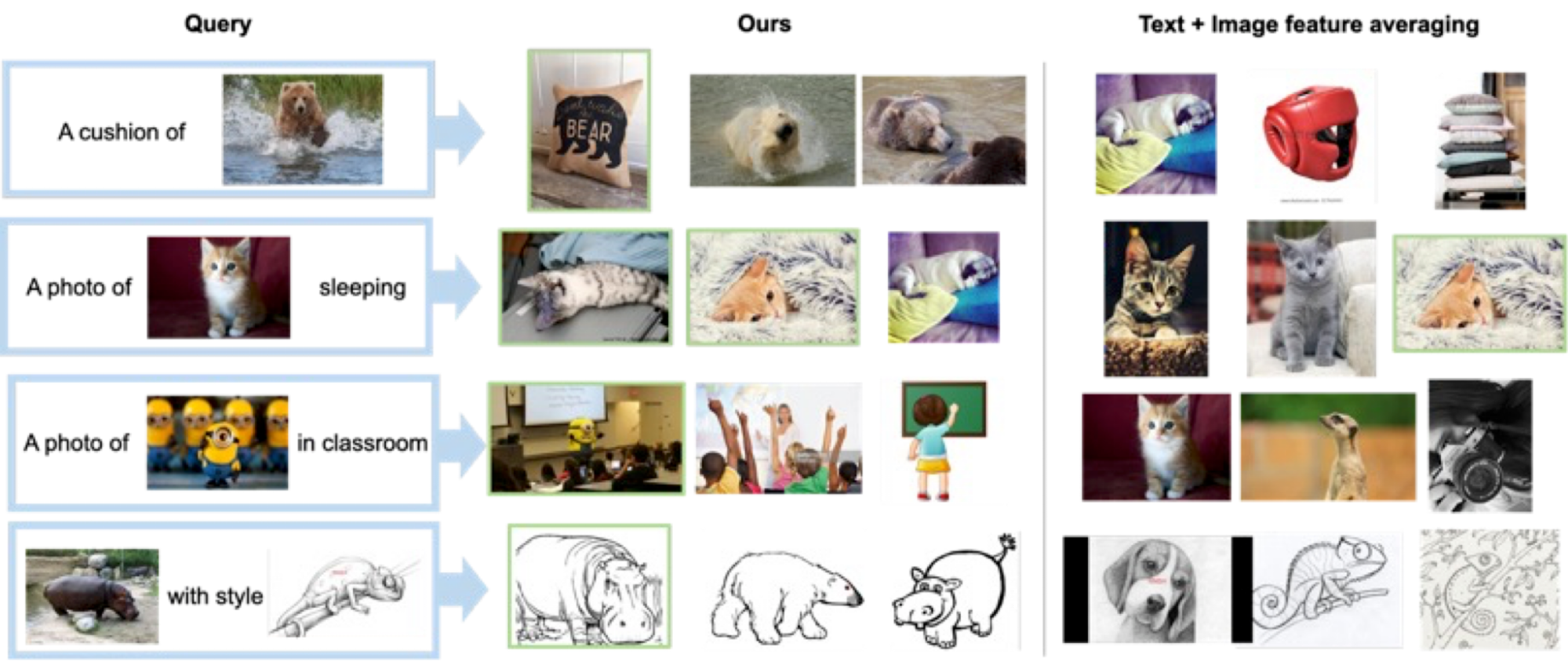 |
| Risultati qualitativi su diverse immagini di query e descrizioni di testo. |
Conclusioni e lavori futuri
In questo articolo, presentiamo Pic2Word, un metodo per mappare immagini in parole per ZS-CIR. Proponiamo di convertire l’immagine in un token di parola per ottenere un modello CIR utilizzando solo un dataset immagine-didascalia. Attraverso una varietà di esperimenti, verifichiamo l’efficacia del modello addestrato su diverse attività CIR, indicando che l’addestramento su un dataset immagine-didascalia può costruire un potente modello CIR. Una possibile direzione futura di ricerca è l’utilizzo dei dati di didascalia per addestrare la rete di mappatura, sebbene in questo lavoro utilizziamo solo dati di immagine.
Ringraziamenti
Questa ricerca è stata condotta da Kuniaki Saito, Kihyuk Sohn, Xiang Zhang, Chun-Liang Li, Chen-Yu Lee, Kate Saenko e Tomas Pfister. Un ringraziamento speciale anche a Zizhao Zhang e Sergey Ioffe per il loro prezioso feedback.





