Apprendimento per rinforzo Insegnare ai computer a prendere decisioni ottimali
Apprendimento per rinforzo insegnare ai computer decisioni ottimali.
Cos’è il Reinforcement Learning?
Il reinforcement learning è un ramo dell’apprendimento automatico che si occupa di un agente che impara, attraverso l’esperienza, come interagire con un ambiente complesso.
Dagli agenti di intelligenza artificiale che giocano e superano le prestazioni umane in giochi da tavolo complessi come scacchi e Go alla navigazione autonoma, il reinforcement learning ha una serie di applicazioni interessanti e diverse.
Progressi notevoli nel campo del reinforcement learning includono l’agente AlphaGo Zero di DeepMind che può sconfiggere addirittura campioni umani nel gioco del Go e AlphaFold che può predire la struttura proteica tridimensionale complessa.
Questa guida ti introdurrà al paradigma del reinforcement learning. Prenderemo un esempio di vita reale semplice ma motivante per comprendere il framework del reinforcement learning.
- Come diventare un analista dei dati senza esperienza?
- OpenAI disabilita la funzione Naviga con Bing in ChatGPT cosa è successo?
- I ricercatori di Georgia Tech presentano ChattyChef un dataset di ricette per rivoluzionare l’esperienza culinaria.
Il Framework del Reinforcement Learning
Iniziamo definendo i componenti di un framework di reinforcement learning.
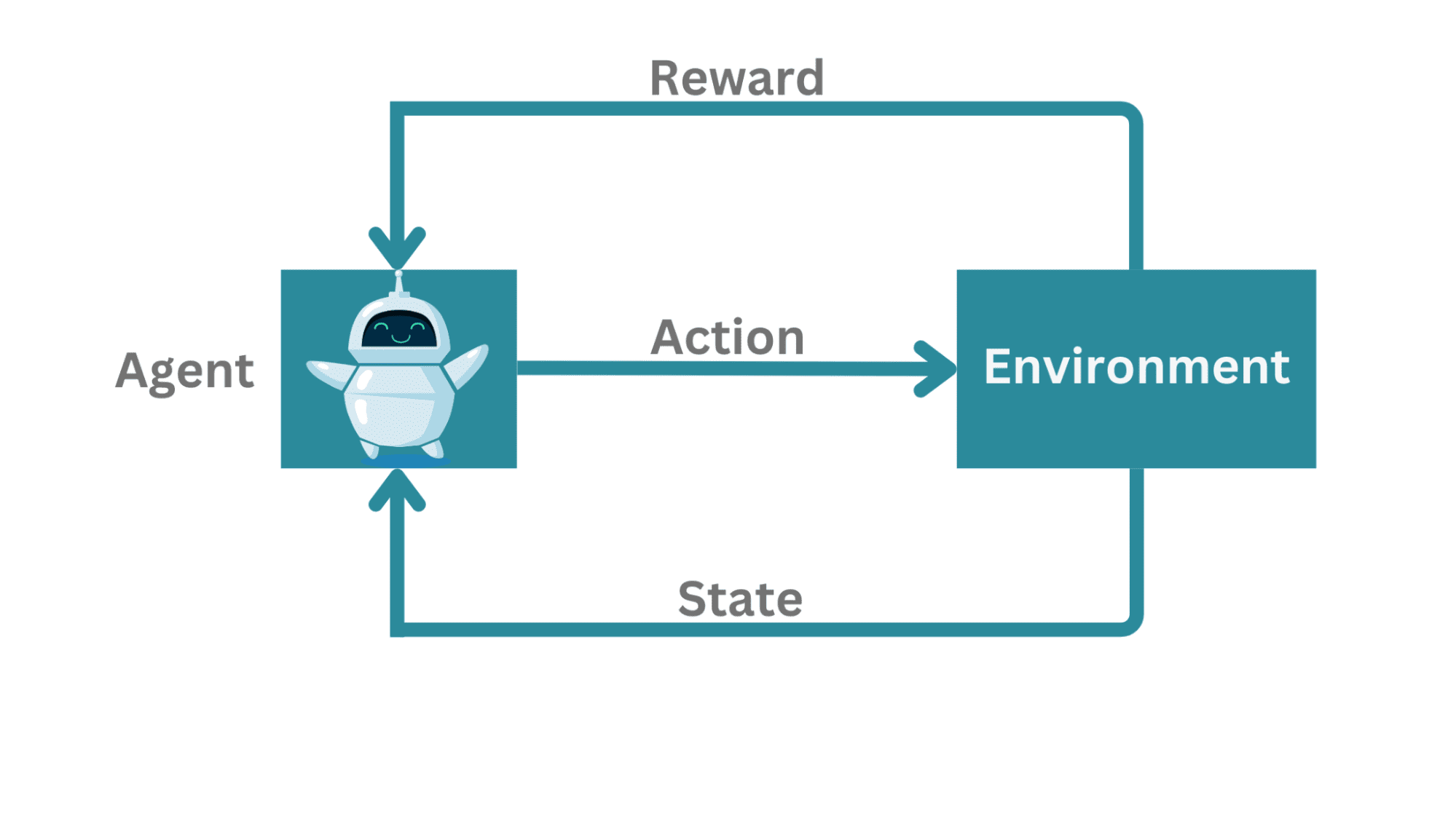
In un framework di reinforcement learning tipico:
- C’è un agente che impara ad interagire con l’ambiente.
- L’agente può misurare il suo stato, prendere azioni e occasionalmente ricevere una ricompensa.
Esempi pratici di questa impostazione: l’agente può giocare contro un avversario (ad esempio, una partita a scacchi) o cercare di navigare un ambiente complesso.
Come esempio super semplificato, considera un topo in un labirinto. Qui, l’agente non sta giocando contro un avversario ma sta cercando di trovare un percorso per uscire. Se ci sono più percorsi che portano all’uscita, potremmo preferire il percorso più breve per uscire dal labirinto.

In questo esempio, il topo è l’agente che cerca di navigare l’ambiente che è il labirinto. L’azione qui è il movimento del topo all’interno del labirinto. Quando riesce a navigare con successo il labirinto fino all’uscita, riceve un pezzo di formaggio come ricompensa.
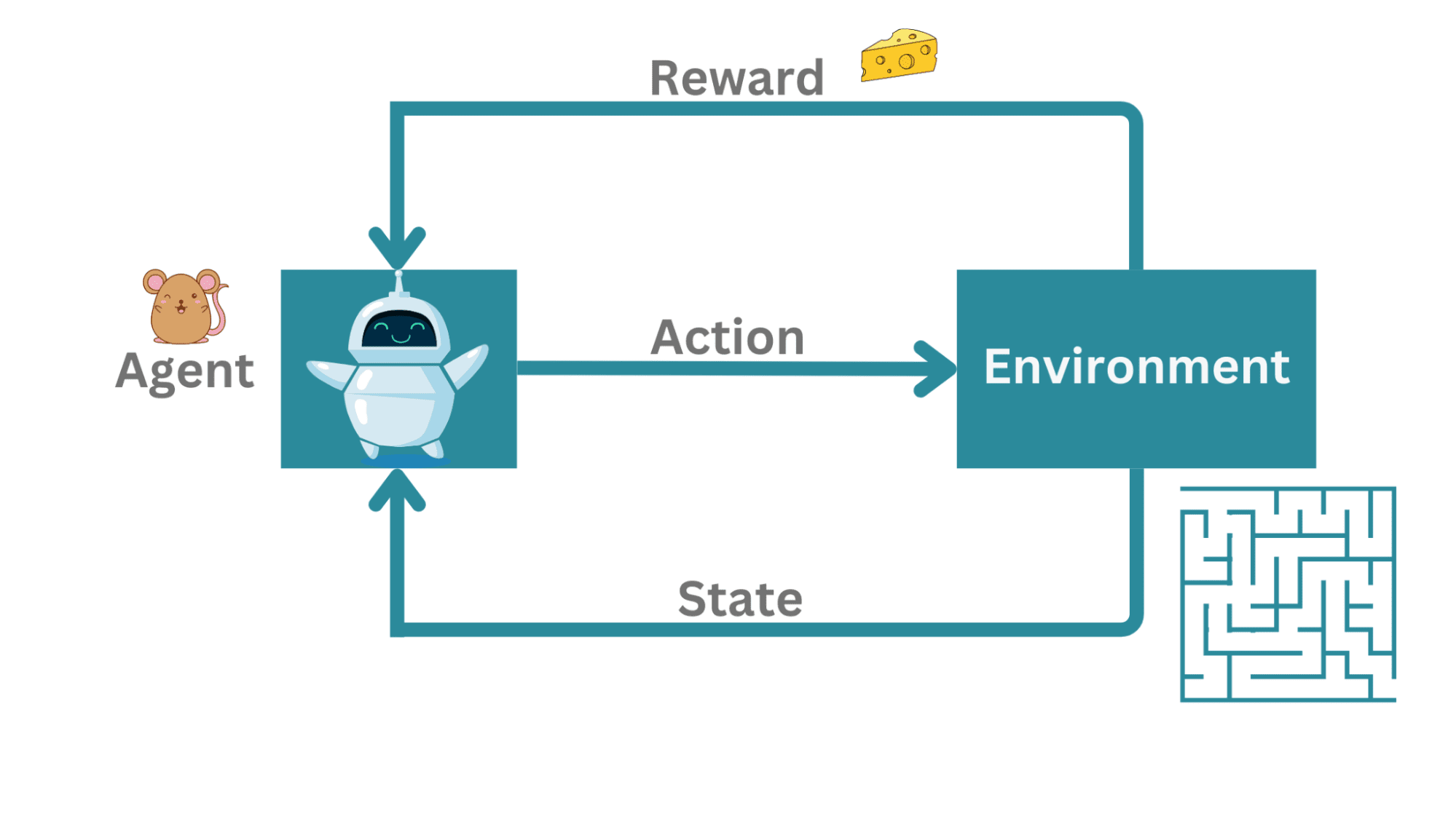
La sequenza di azioni avviene in passaggi di tempo discreti (ad esempio, t = 1, 2, 3, …). In ogni passaggio di tempo t, il topo può solo misurare il suo stato attuale nel labirinto. Non conosce ancora l’intero labirinto.
Quindi l’agente (il topo) misura il suo stato s_t nell’ambiente al passaggio di tempo t, prende un’azione valida a_t e si sposta allo stato s_(t + 1).
In cosa è diverso il Reinforcement Learning?
Nota come il topo (l’agente) deve trovare il suo modo di uscire dal labirinto attraverso prova ed errore. Ora, se il topo sbatte contro uno dei muri del labirinto, deve cercare di trovare la strada di ritorno e tracciare un percorso diverso per l’uscita.
Se questa fosse una situazione di apprendimento supervisionato, dopo ogni mossa, l’agente saprebbe se quell’azione è stata corretta e avrebbe portato a una ricompensa. L’apprendimento supervisionato è come imparare da un insegnante.
Mentre un insegnante ti dice in anticipo, un critico ti dice sempre – dopo che la performance è finita – quanto è stata buona o cattiva la tua performance. Per questo motivo, il reinforcement learning è anche chiamato apprendimento in presenza di un critico.
Stato Terminale ed Episodio
Quando il topo ha raggiunto l’uscita, raggiunge lo stato terminale. Cioè non può esplorare oltre.
E la sequenza di azioni – dallo stato iniziale allo stato terminale – viene chiamata un episodio. Per qualsiasi problema di apprendimento, abbiamo bisogno di più episodi perché l’agente impari a navigare. Qui, per il nostro agente (il topo) imparare la sequenza di azioni che lo porterà all’uscita e successivamente ricevere il pezzo di formaggio, avremmo bisogno di molti episodi.
Ricompense Dense e Sparse
Ogni volta che l’agente compie un’azione corretta o una sequenza di azioni corrette, riceve una ricompensa. In questo caso, il topo riceve un pezzo di formaggio come ricompensa per aver tracciato un percorso valido – attraverso il labirinto (l’ambiente) – verso l’uscita.
In questo esempio, il topo riceve un pezzo di formaggio solo alla fine – quando raggiunge l’uscita. Questo è un esempio di ricompensa sparsa e ritardata.
Se le ricompense sono più frequenti, avremo un sistema di ricompense denso.
Riflettendo, dobbiamo capire (non è banale) quale azione o sequenza di azioni ha causato l’ottenimento della ricompensa da parte dell’agente; questo viene comunemente chiamato problema di assegnazione del merito.
Politica, Funzione di Valore e Problema di Ottimizzazione
Spesso l’ambiente non è deterministico ma probabilistico e così lo è la politica. Dato uno stato s_t, l’agente compie un’azione e passa a un altro stato s_(t+1) con una certa probabilità.
La politica aiuta a definire una mappatura dall’insieme dei possibili stati alle azioni. Aiuta a rispondere a domande come:
- Quali azioni prendere per massimizzare la ricompensa attesa?
- O meglio ancora: Dato uno stato, qual è l’azione migliore possibile che l’agente può intraprendere per massimizzare la ricompensa attesa?
Quindi puoi pensare all’agente come all’attuazione di una politica π:

Un altro concetto correlato e utile è la funzione di valore. La funzione di valore è data da:

Questo indica il valore di essere in uno stato dato una politica π. La quantità indica la ricompensa attesa in futuro se l’agente parte dallo stato e attua la politica π in seguito.
In sintesi: l’obiettivo del reinforcement learning è ottimizzare la politica al fine di massimizzare le ricompense future attese. Pertanto, possiamo pensare ad esso come a un problema di ottimizzazione da risolvere per π.
Fattore di Sconto
Notiamo che abbiamo una nuova quantità ɣ. Cosa rappresenta? ɣ viene chiamato fattore di sconto, una quantità compresa tra 0 e 1. Significa che le ricompense future vengono scontate (leggere: perché il presente è più importante del futuro).
Tradeoff tra Esplorazione ed Sfruttamento
Tornando all’esempio del topo nel labirinto: se il topo riesce a trovare una strada per l’uscita A con un piccolo pezzo di formaggio, può continuare a ripeterla e raccogliere il pezzo di formaggio. Ma cosa succede se il labirinto ha anche un’altra uscita B con un pezzo di formaggio più grande (ricompensa maggiore)?
Fintanto che il topo continua a sfruttare questa strategia attuale senza esplorare nuove strategie, non otterrà la ricompensa molto maggiore di un pezzo di formaggio più grande all’uscita B.
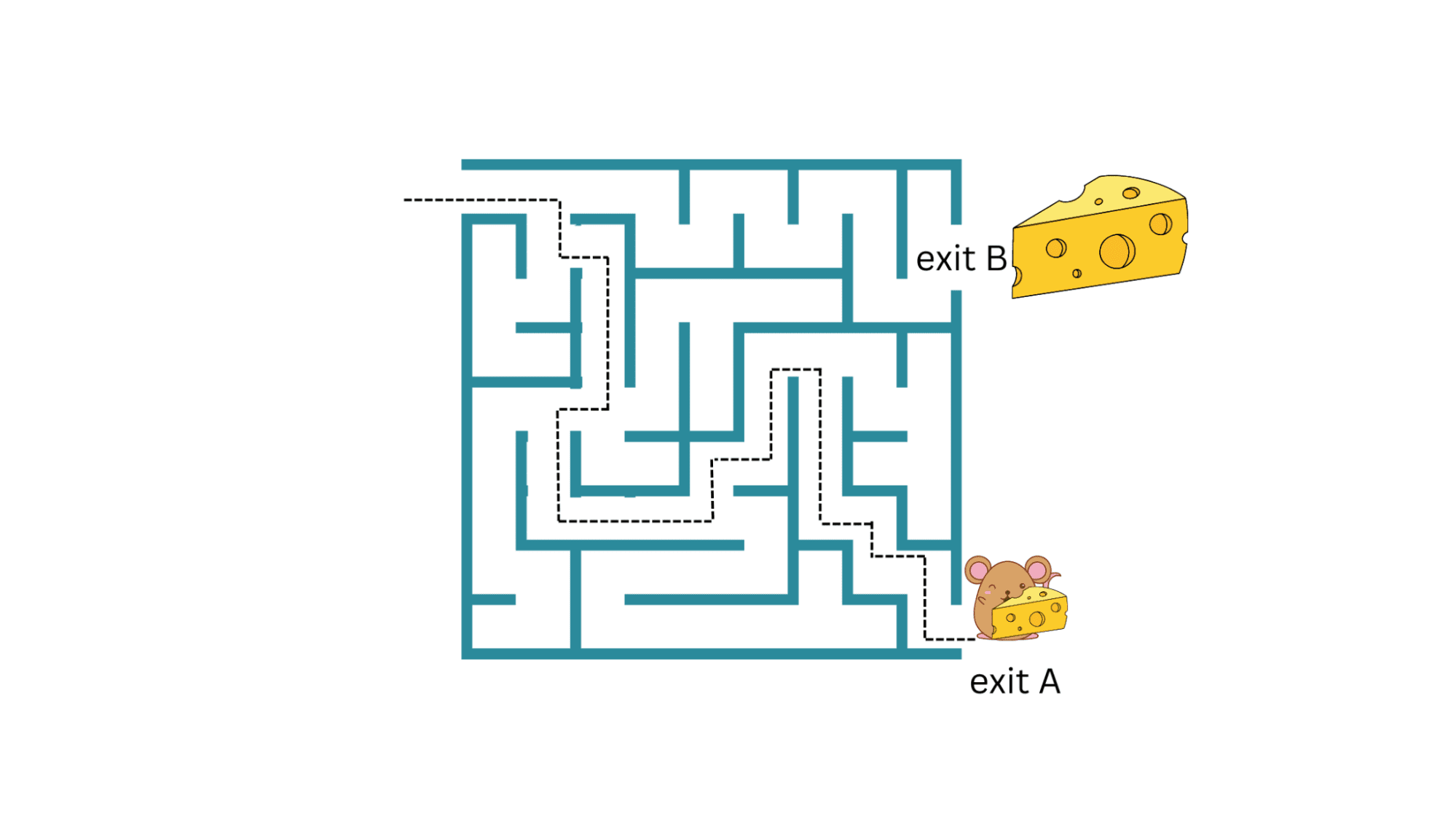
Tuttavia, l’incertezza associata all’esplorazione di nuove strategie e ricompense future è maggiore. Quindi come facciamo a sfruttare ed esplorare? Questo compromesso tra lo sfruttamento della strategia attuale e l’esplorazione di nuove strategie con ricompense potenzialmente migliori viene chiamato tradeoff tra esplorazione ed sfruttamento.
Un possibile approccio è la ricerca ε-greedy. Data un insieme di tutte le possibili azioni, la ricerca ε-greedy esplora una delle azioni possibili con una probabilità ε mentre sfrutta la strategia attuale con una probabilità 1 – ε.
Riassunto e Prossimi Passi
Riassumiamo ciò che abbiamo finora. Abbiamo appreso i componenti del framework di reinforcement learning:
- L’agente interagisce con l’ambiente, misura il suo stato attuale, compie azioni e riceve ricompense come rinforzo positivo. Il framework è probabilistico.
- Siamo poi passati alle funzioni di valore e alla politica, e come il problema di ottimizzazione spesso si riduca a trovare le politiche ottimali che massimizzano le ricompense attese in futuro.
Ora hai imparato abbastanza per navigare nel campo del reinforcement learning. Dove andare da qui? Non abbiamo parlato degli algoritmi di reinforcement learning in questa guida, quindi puoi esplorare alcuni algoritmi di base:
- Se conosciamo tutto sull’ambiente (e possiamo modellarlo completamente), possiamo utilizzare algoritmi basati sul modello come la policy iteration e la value iteration.
- Tuttavia, nella maggior parte dei casi, potremmo non essere in grado di modellare completamente l’ambiente. In questo caso, puoi considerare gli algoritmi senza modello come il Q-learning, che ottimizza le coppie stato-azione.
Se stai cercando di approfondire la tua comprensione del reinforcement learning, le lezioni di reinforcement learning di David Silver su YouTube e il corso di Deep Reinforcement Learning di Hugging Face sono alcune buone risorse a cui dare un’occhiata. Bala Priya C è una sviluppatrice e scrittrice tecnica dall’India. Le piace lavorare all’intersezione tra matematica, programmazione, data science e creazione di contenuti. Le sue aree di interesse e competenza includono DevOps, data science e natural language processing. Le piace leggere, scrivere, programmare e bere caffè! Attualmente sta lavorando per imparare e condividere le sue conoscenze con la comunità di sviluppatori scrivendo tutorial, guide pratiche, articoli di opinione e altro ancora.