Previsioni in tempo reale sull’affollamento per i viaggiatori in treno
'Real-time predictions on train crowding for travelers'
Usare la tecnologia serverless di Azure per fornire previsioni in streaming alla nostra app di pianificazione dei viaggi
Con Wessel Radstok

I viaggiatori delle Ferrovie Olandesi possono utilizzare l’app dell’agenzia ferroviaria olandese per pianificare il loro viaggio. Durante la pianificazione del viaggio, l’app mostra una previsione sulla affollamento del treno in questione. Questo viene mostrato in tre categorie: bassa occupazione, VoAGI o alta. Il viaggiatore può utilizzare queste informazioni per decidere se desidera prendere un treno diverso che potrebbe essere un po’ meno affollato.
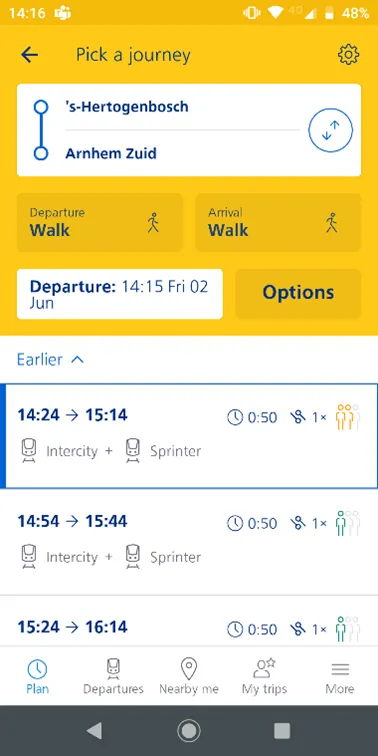
Queste previsioni vengono effettuate tramite un processo batch. Un modello di machine learning viene addestrato regolarmente sui dati storici e ogni mattina viene eseguito un processo per prevedere l’affollamento dei treni nei giorni successivi. Ciò viene fatto prevedendo quanti passeggeri sono attesi e combinando questa informazione con la capacità del treno prevista per il percorso.
Tuttavia, durante la giornata possono verificarsi incidenti che causano la cancellazione o deviazione dei treni, o può accadere che sia previsto un treno a due piani ma sia disponibile solo un treno a un piano. Di conseguenza, il viaggiatore vedrà informazioni obsolete sull’affollamento. Circa il 20% dei treni in partenza cambia capacità il giorno del viaggio, spesso poco prima della partenza.
- Effettuare il deploy di Falcon-7B in produzione
- Sfida di classificazione del testo con dataset extra-piccoli affinamento versus ChatGPT
- Apprendimento di operatori tramite Physics-Informed DeepONet Implementiamolo da zero
In questo articolo, spieghiamo come abbiamo costruito un flusso di dati in streaming che prende informazioni in tempo reale sulla lunghezza e il tipo di treno previsto per un percorso e aggiorna l’affollamento previsto nell’app. Seguiamo un’architettura Lambda in cui le nostre previsioni notturne implementano il livello batch e il processo di aggiornamento implementa il livello di streaming. Attualmente, questo flusso di lavoro è in esecuzione in produzione, fornendo a tutti i viaggiatori in treno nei Paesi Bassi che utilizzano la nostra app una visione più in tempo reale dell’affollamento previsto del loro viaggio.
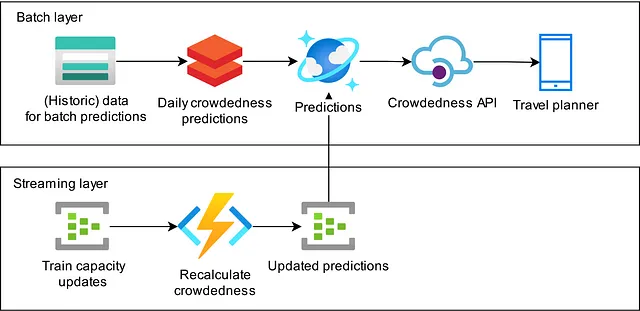
Descriviamo l’approccio che abbiamo adottato per implementare questa architettura. La nostra prima implementazione è stata fatta utilizzando Spark Structured Streaming, che però non ha funzionato come ci aspettavamo. Sulla base della nostra esperienza, che discuteremo, abbiamo deciso di adottare un approccio diverso utilizzando risorse serverless nel cloud di Azure.
Primo tentativo: Spark Structured Streaming
Le nostre previsioni giornaliere sull’affollamento vengono eseguite su Databricks utilizzando Spark per l’elaborazione dei dati. Poiché Spark supporta l’elaborazione dei dati in streaming, sembra un’opzione logica per implementare gli aggiornamenti in tempo reale delle nostre previsioni in Spark Structured Streaming. Questa decisione ci ha dato il vantaggio che la piattaforma era già disponibile e potevamo implementare la logica utilizzando il paradigma dei DataFrame con cui avevamo già esperienza.
Abbiamo iniziato l’implementazione con una versione batch del modello che volevamo eseguire in versione streaming e l’abbiamo convertita in una versione pura di Spark Structured Streaming. Alla fine, abbiamo ottenuto un piccolo notebook per avviare il job di streaming e un pacchetto python personalizzato contenente la logica di cui avevamo bisogno.
Durante il processo di sviluppo abbiamo imparato alcune cose sulla programmazione utilizzando Structured Streaming. Innanzitutto, l’interfaccia di programmazione dei SQL DataFrame e dei Structured Streaming DataFrame non è la stessa. Structured Streaming è molto più limitato in termini di ciò che può essere fatto, il che significa che non potevamo implementare il modello batch uno a uno in modo streaming e abbiamo dovuto rivedere l’algoritmo alcune volte per farlo funzionare. La limitata espressività dell’interfaccia di Structured Streaming ha portato a un codice che è diventato illeggibile e quindi difficile da mantenere.
Un esempio semplice di questo è che volevamo eseguire un outer join su due flussi di dati basati su una finestra temporale. Tuttavia, Spark Structured Streaming richiede di avere una uguaglianza nella condizione di join e non avevamo due colonne con gli stessi dati. Abbiamo provato ad aggiungere due campi letterali con lo stesso valore ai due flussi per l’uguaglianza, ma Spark non è così facilmente ingannato. Alla fine abbiamo creato un campo “millennium” poiché i nostri timestamp sono tutti nel terzo millennio: funziona, ma in pratica abbiamo creato un bug del “Y3K”.
Inoltre, abbiamo dovuto suddividere l’algoritmo in passaggi separati perché avevamo diversi vincoli temporali su diverse parti del modello che non potevamo implementare in un unico job di Structured Streaming. Abbiamo scelto di suddividere il modello in diverse parti, accoppiate tra loro utilizzando Azure Event Hubs come layer di storage persistente in mezzo. Questo aveva il vantaggio che ogni parte del processo aveva un obiettivo chiaro e poteva essere testata individualmente.
Abbiamo testato il nostro flusso in due modi. Per i test unitari, avremmo semplicemente preso la logica in streaming e l’avremmo alimentata con DataFrame Spark SQL batch creati manualmente per i test. Questo significa che potevamo testare parti del flusso in streaming senza avviare effettivamente un job in streaming. Questo approccio cattura gran parte dei requisiti funzionali, ma non cattura eventuali problemi di timing. Il secondo passaggio di test utilizzava i sink di memoria di Spark Structured Streaming per eseguire la query in modalità streaming e catturare anche alcuni effetti temporali.
Alla fine, abbiamo distribuito il nostro codice e abbiamo visto aumentare drasticamente la nostra fattura cloud. Abbiamo identificato due motivi per questo: in primo luogo, Databricks è una soluzione eccellente per i job di analisi batch, ma è costoso mantenerlo in esecuzione continuamente per i job in streaming. In secondo luogo, la politica di sicurezza delle informazioni del nostro datore di lavoro richiede di registrare l’accesso ai dati. Poiché lo state store di Structured Streaming potrebbe contenere dati, abbiamo dovuto registrarli anche. Tuttavia, lo state store viene aggiornato molto spesso e contiene molti file piccoli che generano un enorme set di log costoso da catturare.
Alla fine, abbiamo deciso di abbandonare questo approccio. I nostri costi cloud erano troppo elevati per il problema che stavamo cercando di affrontare. In combinazione con il fatto che l’implementazione del modello era molto difficile da capire e mantenere a causa della limitata espressività di Spark Structured Streaming, siamo giunti alla conclusione che non volevamo investire ulteriormente per migliorare questo approccio, ma di cercare un modo diverso per affrontare il problema.
Riprogettazione utilizzando tecnologie serverless
Osservando che molte parti del flusso non richiedono uno stato, abbiamo optato per un sistema che utilizzasse le Azure Functions come piattaforma di calcolo in modo tale che ogni messaggio possa essere gestito singolarmente. Dove è necessario uno stato, utilizziamo Stream Analytics. Questo ci consente di confrontare i messaggi, riprodurli o unirli con un altro flusso. Per consentire un accesso rapido ai dati ausiliari, utilizziamo un database Cosmos. Continuiamo a utilizzare Azure Event Hubs per collegare tutte le parti insieme.

Azure Functions
Azure Functions sono un metodo semplice per applicare operazioni a un flusso di eventi. Vengono invocati separatamente per ogni evento nel flusso, il che rende facile ragionare sulla logica di business. Hanno il supporto nativo per Python, rendendo facile scrivere operazioni manutenibili. Poiché la piattaforma gestisce tutto il boilerplate della connettività cloud, possono essere sviluppate e testate facilmente in locale. Le utilizziamo in varie parti del flusso:
- Alcune funzioni semplicemente filtrano i messaggi in ingresso, riducendo il carico di calcolo dei passaggi successivi e quindi riducendo la capacità e i costi;
- Diverse funzioni arricchiscono i messaggi unendoli ad altre fonti di dati disponibili, ad esempio Cosmos DB;
- Altre funzioni trasformano il messaggio da un formato all’altro, ad esempio il formato di output finale;
- Infine, utilizziamo le Azure Functions per acquisire i dati dal livello batch al livello di streaming.
Filtraggio, arricchimento e trasformazioni
Le funzioni che eseguono questi passaggi sono semplici codici Python. Ad esempio, la parte principale della funzione di filtraggio è solo qualche riga:
def main(event: func.EventHubEvent, evh: func.Out[bytes]) -> None: """ Filtra i messaggi per inviare solo i messaggi pertinenti per il nostro flusso di streaming. """ message = json.loads(event.get_body().decode("utf-8")) if _is_ns_operator(message): message = _remove_keys(message) message = _add_build_id(message) evh.set(str.encode(json.dumps(message)))Listing 1: Esempio di codice di Azure Function che filtra e trasforma i messaggi.
In questo caso, prendiamo ogni messaggio, filtriamo solo i messaggi relativi ai treni della nostra azienda e rimuoviamo le chiavi (campi dati) del messaggio che non ci interessano. Infine, aggiungiamo un metadato di ID di compilazione al messaggio in modo da avere alcune informazioni di tracciamento per scopi di debug. Per il lettore interessato, la stringa JSON viene codificata come un oggetto Bytes usando str.encode(). Se una stringa normale viene inviata all’Event Hub, viene formattata automaticamente con molti spazi bianchi nel messaggio. Un oggetto Bytes viene inviato senza modifiche.
Ingestione dei dati in un database Cosmos rapido
Per ricalcolare l’affollamento dei treni, è necessario accedere rapidamente al numero previsto di viaggiatori nel treno, alla capacità del nuovo materiale rotabile e ai limiti per la classificazione bassa, VoAGI e alta. Questi dati vengono generati giornalmente come parte del nostro processo batch e scritti nel nostro data lake nel formato parquet. Caricare questi dati dal data lake per ogni azione di ricalcolo è troppo lento. Utilizziamo il database di Azure Cosmos come archivio chiave-valore per rendere i dati statici richiesti disponibili con latenza ridotta per le Azure Functions che ricalcolano l’affollamento dei treni.
Lo scenario ideale è che attiviamo l’ingestione dal nostro processo batch notturno e possiamo anche ricevere informazioni su se l’ingestione è riuscita o meno. Il processo di ingestione deve anche essere in grado di leggere file parquet con tipi complessi, che hanno abbandonato il supporto per un’attività di copia di Azure Data Factory. La nostra soluzione è stata di sfruttare le Azure Durable Functions. Questa è un’estensione della piattaforma standard di Azure Functions che consente di eseguire funzioni stateful a lunga durata. In particolare, le funzioni durature supportano i webhook che ci consentono di comunicare all’orchestratore se l’ingestione è riuscita o meno.
L’ingestione funziona quindi come segue. Il nostro processo batch notturno attiva una funzione durevole. Queste funzioni durature selezionano la funzione di attività corretta per la fonte di dati da ingested e attivano questa funzione di attività per ogni file parquet disponibile. Quindi utilizziamo pandas per leggere ogni file, eseguire alcune semplici trasformazioni e inserire i record nel database Cosmos in modalità bulk-insert. La funzione duratura tiene automaticamente traccia di eventuali errori e riprova quella funzione.
Azure Stream Analytics
Alcune operazioni non possono essere facilmente eseguite con Azure Functions. Questo è principalmente vero per le operazioni con stato o per le operazioni che combinano messaggi nel corso del tempo.
Le nostre previsioni giornaliere di affollamento vengono effettuate in un processo batch che non calcola le previsioni istantaneamente. Ci vuole del tempo, tempo durante il quale possono verificarsi nuovi aggiornamenti sulla capacità del treno. Se ciò accade, desideriamo aggiornare l’affollamento due volte: prima sulla previsione più recente precedente e successivamente sulle nuove previsioni quando diventano disponibili. Utilizziamo Azure Stream Analytics per mantenere lo stato dei messaggi di aggiornamento e riprodurli da un determinato timestamp quando è disponibile una nuova previsione batch.
Le query di Azure Stream Analytics sono scritte in un dialetto SQL. È relativamente semplice implementare trasformazioni. Tuttavia, è necessario fare attenzione quando il flusso dei messaggi deve essere elevato. Nel nostro caso, un’implementazione diretta non riusciva a tenere il passo con il flusso di input e abbiamo dovuto assicurarci che la query di analisi dello stream potesse essere eseguita in modo parallello.
Le query parallelizzabili hanno alcuni requisiti e limitazioni. Devono elaborare dati partizionati e devono eseguire operazioni con stato (ad esempio, join) contenute all’interno di una partizione. Ciò significa che quando si uniscono due flussi di Event Hub, devono avere lo stesso numero di partizioni e i dati della partizione 1 sul primo Event Hub possono essere uniti solo ai dati della partizione 1 sul secondo.
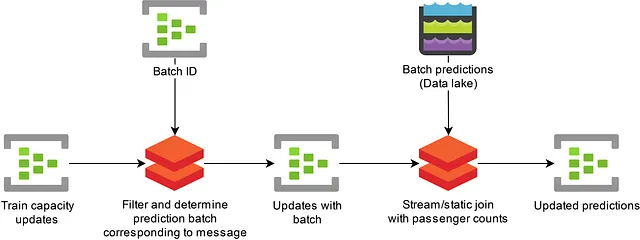
Per risolvere questo problema, duplichiamo alcuni dei nostri dati su diverse partizioni dell’Event Hub e implementiamo essenzialmente un’operazione di join broadcast. Illustreremo ciò nella query seguente. Qui, a ciascuna delle nostre previsioni di affollamento viene assegnato un ID batch e un’ora di inizio del batch che viene utilizzata per decidere a quale messaggio di aggiornamento della capacità del treno si applica ogni previsione. Un messaggio può essere applicabile a più previsioni se il messaggio arriva durante il calcolo di un nuovo set di previsioni). In questo caso, vengono prodotti più messaggi. Ogni ID batch viene duplicato su più partizioni dell’Event Hub.
SELECT batchid.batch_id, batchid.batch_start_time, event.message, event.message_timestamp INTO [Target]FROM [SourceData] event TIMESTAMP BY event.message_timestamp PARTITION BY PartitionId JOIN [BatchId] batchid TIMESTAMP BY batchid.EventEnqueuedUtcTime PARTITION BY PartitionId ON -- Join se il messaggio dell'id del batch è stato ricevuto prima del messaggio (DATEDIFF positivo) e -- riproduci quando il messaggio dell'id del batch è stato ricevuto dopo il messaggio (DATEDIFF negativo), -- ma solo se il messaggio è stato accodato dopo l'ora di inizio del batch. -- Per consentire un rapido reinserimento dei dati, scartiamo i messaggi che non sono più validi per il batch DATEDIFF(ORA, batchid, event) TRA - 24 E 24 E CAST(batchid.batch_start_time AS datetime) <= CAST(event.message_timestamp AS datetime) E CAST(event.message.valid_until AS datetime) >= CAST(batchid.batch_start_time AS datetime) E event.PartitionId = batchid.PartitionIdElenco 2: Esempio di query di Azure Stream Analytics che aggiunge l’ID del batch corrispondente per la previsione a ogni messaggio.
Test di integrazione end-to-end
Dal commit iniziale del progetto abbiamo deciso di eseguire test di integrazione end-to-end automatizzati sul flusso di streaming. Questo test assume la forma di semina di messaggi di esempio nell’hub degli eventi che generiamo e quindi la convalida dei messaggi creati nell’hub degli eventi di output. Abbiamo incluso anche l’ingestione del database Cosmos in questo flusso di test di integrazione. Includere questi test nella nostra distribuzione continua ci ha dato grande fiducia nel apportare modifiche poiché il numero di componenti nel flusso aumentava e la complessità aumentava di conseguenza.
Conclusioni e apprendimenti chiave
Nella nostra ricerca per fornire ai nostri viaggiatori in treno le informazioni più recenti sulla affluenza dei passeggeri, anche in situazioni in cui si verificano cambiamenti nel servizio ferroviario, abbiamo adottato un’architettura lambda per aggiornare le nostre previsioni quando cambia la capacità del treno.
La nostra implementazione iniziale utilizzando Spark Structured Streaming non ha dato i risultati attesi e siamo passati a un’architettura serverless utilizzando Azure Event Hubs, Azure Functions, Azure Stream Analytics e Azure Cosmos DB.
I principali vantaggi di questo approccio includono:
- Come sviluppatore, hai il controllo: è chiaro quali parti non funzionano bene e quali parti comportano i costi più elevati;
- A differenza di Spark Structured Streaming, il codice Python puro in Azure Functions è leggibile, mantenibile ed espressivo;
- Le Azure Functions sono economiche per le operazioni senza stato;
- Azure Streaming Analytics è la parte più costosa e deve essere utilizzata solo dove è necessario (operazioni con stato o finestre temporali);
- La nuova soluzione ha ridotto significativamente i costi dell’infrastruttura cloud.
Gli svantaggi principali:
- L’uso di componenti disaccoppiati come Azure Functions e Azure Cosmos DB può causare condizioni di concorrenza se il design non viene considerato molto bene;
- Vi sono molti elementi di infrastruttura e piccoli pezzi di codice da gestire: la logica non è concentrata in un unico punto e richiede test più estesi.