Come evitare di essere ingannati dalla precisione del modello
'Evitare di essere ingannati dalla precisione del modello'
Una guida visuale alle metriche dei modelli di classificazione binaria e al loro uso corretto

Contesto – Semplice in apparenza
Le metriche utilizzate per misurare le prestazioni dei modelli di classificazione sono piuttosto semplici, almeno dal punto di vista matematico. Tuttavia, ho osservato che molti modellatori e data scientist incontrano difficoltà nell’articolare queste metriche e persino nell’applicarle correttamente. Questo è un errore facile da commettere, poiché queste metriche sembrano semplici in superficie, ma le loro implicazioni possono essere profonde a seconda del dominio del problema.
Questo articolo serve come guida visuale per spiegare le metriche comuni dei modelli di classificazione. Esploreremo le definizioni e useremo esempi per evidenziare dove le metriche vengono utilizzate in modo inappropriato.
Breve nota sulla visualizzazione
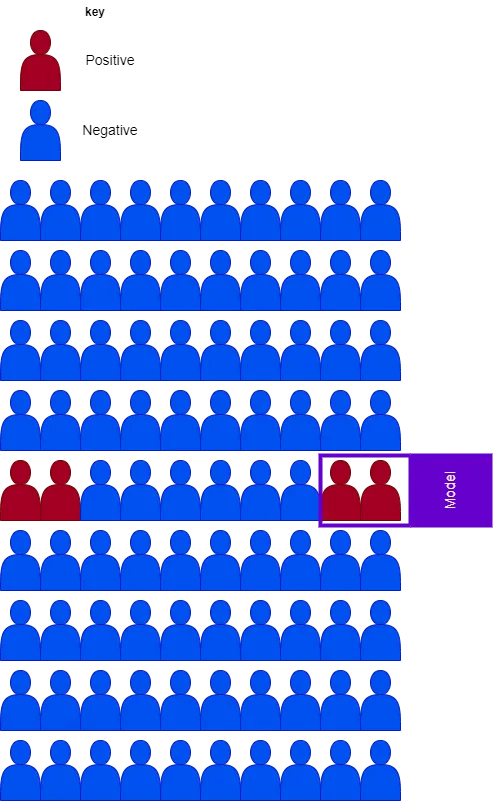
Ogni visualizzazione è composta da novanta soggetti, rappresentanti tutto ciò che potremmo voler classificare. I soggetti blu indicano campioni negativi, mentre quelli rossi sono campioni positivi. La casella viola è il modello che cerca di prevedere campioni positivi. Tutto ciò che si trova all’interno di questa casella è ciò che il modello prevede come positivo.
Con ciò chiarito, immergiamoci nelle definizioni.
- Storia del mondo attraverso le lenti dell’IA
- Introduzione alla Quantizzazione dei Pesi
- Presentando PandasAI Una libreria di analisi dati alimentata da GenAI
Precisione e Richiamo
Per molti compiti di classificazione, c’è un compromesso tra precisione e richiamo. Spesso accade che ottimizzare il richiamo comporti un costo per la precisione. Ma cosa significano realmente questi termini? Iniziamo con le definizioni matematiche e poi passiamo alle rappresentazioni visive.
Precisione = TP / (TP + FP)
Richiamo = TP / (TP + FN)
Dove TP = Numero di veri positivi, FP = Numero di falsi positivi, FN = Numero di falsi negativi.
Concentriamoci sul grafico direttamente sotto, in cui ci sono quattro campioni positivi. Ricorda, le previsioni positive del modello sono rappresentate dalla casella sul grafico. Osservando il grafico, vediamo che il modello prevede correttamente tutti e quattro i campioni positivi – possiamo vederlo poiché tutti i campioni positivi si trovano all’interno della casella. Possiamo calcolare il richiamo del modello dal grafico contando i casi positivi all’interno della casella (TP = 4) diviso per il numero totale di casi positivi (TP = 4 + FN = 0).
Nota che FN è 0 perché non ci sono casi positivi al di fuori della casella.

La precisione può essere spiegata in modo simile. È semplicemente il numero di casi positivi nella casella (TP = 4) diviso per il numero totale di casi nella casella (TP = 4 + FP = 6). Un calcolo semplice rivela che la precisione del modello è solo del 40%.
Puoi osservare che un modello può avere un alto richiamo ma una bassa precisione, e viceversa. Il grafico sottostante mostra questo, in cui il richiamo è solo del 50%, mentre la precisione è del 100%. Vedi se riesci ad interiorizzare come arrivare a questi numeri.
Ecco un suggerimento per aiutarti: il numero di falsi negativi è due poiché ci sono due campioni positivi al di fuori della casella.
Tassi di falsi positivi e tassi di veri negativi
Il tasso di falsi positivi (FPR) appare forse più intuitivo, probabilmente a causa del suo nome. Tuttavia, esploriamo il concetto allo stesso modo in cui abbiamo fatto per le altre metriche. Matematicamente, esprimiamo il FPR come segue:
FPR = FP/(FP + TN)
Qui, TN rappresenta il numero di soggetti veri negativi.
Riesaminando la prima immagine, il FPR può essere determinato guardando il numero di campioni negativi all’interno del riquadro (FP=6) diviso per il numero totale di campioni negativi (FP=6 + TN=80). Per la nostra prima immagine, il tasso di falsi positivi è solo del 7%, e per la seconda immagine è del 0%. Cerca di capire perché questo è il caso.
Ricorda, i soggetti all’interno del riquadro sono quelli che il modello prevede come positivi. Quindi, per estensione, i campioni negativi al di fuori del riquadro sono quelli che il modello ha identificato come negativi.
Il tasso di veri negativi (TNR) può essere calcolato utilizzando la seguente formula:
TNR = TN/(TN + FP)
Notare che il TNR è sempre uno meno il tasso di falsi positivi.
Precisione
Precisione è un termine che viene usato in modo generico nel contesto delle prestazioni del modello, ma cosa significa effettivamente? Iniziamo con la definizione matematica:
Precisione = (TP + TN) / (TP + TN + FP + FN)
Utilizzando la stessa logica applicata in precedenza, possiamo calcolare la precisione del modello come 93% per la prima immagine e 97% per la seconda (vedi se riesci a derivare tu stesso questo valore). Questo potrebbe sollevare dei dubbi sulla precisione come metrica fuorviante in alcuni casi. Esploreremo questo argomento in maggior dettaglio successivamente.
Utilizzare le Metriche Correttamente
Perché ci preoccupiamo di queste metriche? Perché ci dotano di modi per valutare le prestazioni dei nostri modelli. Una volta comprese queste metriche, possiamo persino determinare il valore commerciale associato ai modelli. Ecco perché è importante avere una buona intuizione su come utilizzarle in modo appropriato (e inappropriato). Per illustrare questo concetto, esamineremo brevemente le due situazioni comuni nei compiti di classificazione, ovvero i dataset bilanciati e quelli sbilanciati.
Dataset Sbilanciati
I diagrammi rappresentati in precedenza sono esempi di compiti di classificazione sbilanciati. In termini semplici, i compiti sbilanciati hanno una bassa rappresentazione dei soggetti positivi rispetto ai soggetti negativi. Molti casi d’uso commerciali per la classificazione binaria rientrano in questa categoria, come la rilevazione delle frodi con le carte di credito, la previsione dell’abbandono dei clienti, il filtraggio dello spam, ecc. Scegliere le metriche sbagliate per la classificazione sbilanciata può portare a credere in modo eccessivamente ottimistico alle prestazioni del proprio modello.
Il problema principale della classificazione sbilanciata è la possibilità che il numero di campioni veri negativi sia alto e che i falsi negativi siano bassi. Per illustrare questo concetto, consideriamo un altro modello e valutiamolo sui nostri dati sbilanciati. Possiamo creare uno scenario estremo in cui il modello semplicemente prevede che ogni soggetto sia negativo.

Calcoliamo ora ciascuna delle metriche in questa situazione.
- Precisione: (TP=0 + TN=86) / (TP=0 + TN=86 + FP=0 + FN=4) = 95%
- Recall: (TP=0) / (TP=0 + FN=4) = 0%
- FPR: (FP=0) / (FP=0 + TN=86) = 0%
- TNR: (TN=86) / (TN=86 + FP=0) = 100%
I problemi con la precisione, FPR e TNR dovrebbero diventare più evidenti. Quando lavoriamo con dataset sbilanciati, possiamo ottenere un modello ad alta precisione che si comporta male durante l’applicazione. Nell’esempio precedente, il modello non ha la capacità di rilevare soggetti positivi ma raggiunge comunque una precisione del 95%, un FPR del 0% e un TNR perfetto.
Immagina ora di utilizzare un modello del genere per condurre diagnosi mediche o rilevare frodi; risulterebbe chiaramente inutile e forse persino pericoloso. Questo esempio estremo illustra il problema di utilizzare metriche come la precisione, il FPR e il TPR per valutare le prestazioni dei modelli che lavorano su dati sbilanciati.
Dataset Bilanciati
Per problemi di classificazione bilanciati, il numero di possibili veri negativi è significativamente più piccolo rispetto al caso sbilanciato.

Se prendiamo il nostro modello “non discriminatorio” e lo applichiamo al caso bilanciato, otteniamo i seguenti risultati:
- Accuracy: (TP=0 + TN=45) / (TP=0 + TN=45 + FP=0 + FN=45) = 50%
- Precision: (TP=0) / (TP=0 + FP=0) = non definita
- Recall: (TP=0) / (TP=0 + FN=45) = 0%
- FPR: (FP=0) / (FP=0 + TN=45) = 0%
- TNR: (TN=45) / (TN=45 + FP=0) = 100%
Mentre tutte le altre metriche rimangono uguali, l’accuratezza del modello è scesa al 50%, probabilmente una rappresentazione molto più indicativa delle prestazioni effettive del modello. Tuttavia, l’accuratezza rimane fuorviante senza precisione e recall.
Curve ROC vs Curve Precision-Recall
Le curve ROC sono un approccio comune utilizzato per valutare le prestazioni dei modelli di classificazione binaria. Tuttavia, quando si lavora con dataset sbilanciati, possono fornire risultati ottimistici e non completamente significativi.
Una breve panoramica delle curve ROC e Precision-Recall: stiamo essenzialmente tracciando le metriche di classificazione l’una contro l’altra per diversi soglie decisionali. Comunemente misuriamo l’area sotto la curva (o AUC) per avere un’indicazione delle prestazioni del modello. Segui i link per saperne di più sulle curve ROC e Precision-Recall.
Per illustrare come le curve ROC possano essere troppo ottimistiche, ho costruito un modello di classificazione su un dataset di frodi con carte di credito preso da Kaggle. Il dataset comprende 284.807 transazioni, di cui 492 sono fraudolente.
Nota: I dati sono gratuiti per l’uso commerciale e non commerciale senza permesso, come indicato nella licenza Open Data Commons attribuita ai dati.
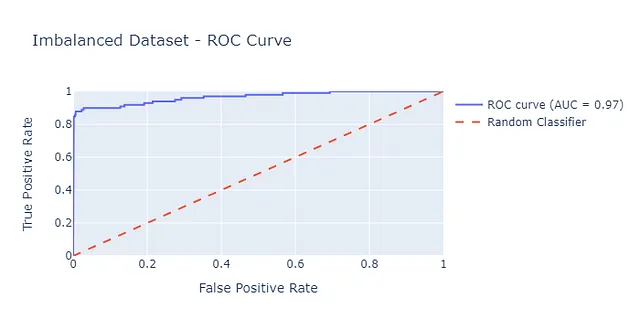
Esaminando la curva ROC, potremmo essere portati a credere che le prestazioni del modello siano migliori di quanto in realtà siano, poiché l’area sotto questa curva è 0,97. Come abbiamo visto in precedenza, il tasso di falsi positivi può essere eccessivamente ottimistico per problemi di classificazione sbilanciati.
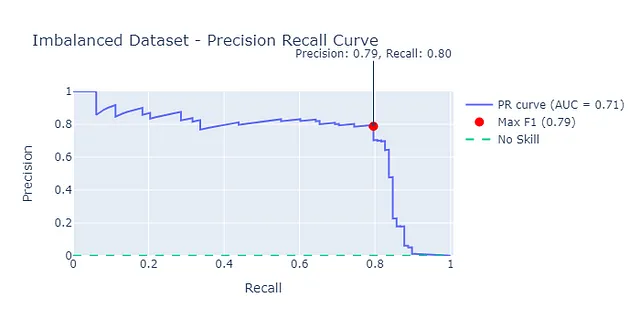
Un approccio più robusto sarebbe utilizzare la curva precisione-recall. Questa fornisce una stima molto più affidabile delle prestazioni del nostro modello. Qui possiamo vedere che l’area sotto la curva precisione-recall (AUC-PR) è molto più conservativa e pari a 0,71.
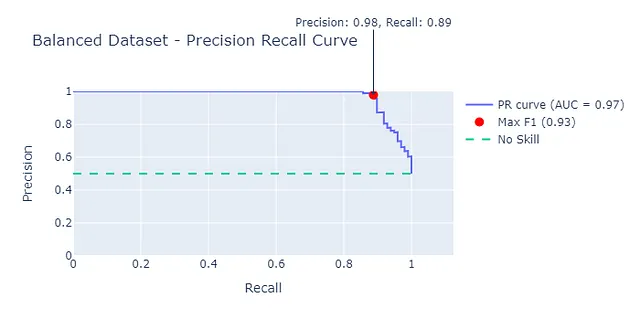
Prendendo una versione bilanciata del dataset in cui le transazioni fraudolente e non fraudolente sono 50:50, possiamo vedere che l’AUC e l’AUC-PR sono molto più vicine tra loro.

Il notebook per generare questi grafici è disponibile nel mio repository GitHub.
Ci sono modi per migliorare le prestazioni dei modelli di classificazione su set di dati sbilanciati, esplorerò questi nel mio articolo sui dati sintetici.
I Dati Sintetici Possono Migliorare le Prestazioni del Machine Learning?
Indagare la Capacità dei Dati Sintetici di Migliorare le Prestazioni del Modello su Set di Dati Sbilanciati
towardsdatascience.com
Conclusione
Comprendere le metriche dei modelli di classificazione va oltre le formule matematiche. Dovresti anche capire come utilizzare ciascuna metrica e le loro implicazioni sia per set di dati bilanciati che sbilanciati. Come regola generale, le metriche che vengono calcolate in base ai veri negativi o ai falsi negativi possono essere troppo ottimistiche quando vengono applicate a set di dati sbilanciati. Spero che questo tour visuale ti abbia dato un’intuizione maggiore.
Ho trovato questa spiegazione visuale utile per illustrare l’approccio ai miei stakeholder non tecnici. Sentiti libero di condividere o prendere in prestito l’approccio.
Seguimi su LinkedIn
Iscriviti a VoAGI per ottenere maggiori approfondimenti da parte mia:
Unisciti a VoAGI con il mio link di riferimento — John Adeojo
Condivido progetti, esperienze ed esperienza di data science per assisterti nel tuo percorso. Puoi registrarti a VoAGI tramite…
johnadeojo.medium.com
Se sei interessato a integrare l’IA o la data science nelle tue operazioni aziendali, ti invitiamo a pianificare una consulenza iniziale gratuita con noi:
Prenota Online | Soluzioni Centrate sui Dati
Scopri la nostra esperienza nel aiutare le aziende a raggiungere obiettivi ambiziosi con una consulenza gratuita. I nostri data scientist e…
www.data-centric-solutions.com