Esplorazione dei Trasformatori Immagine-Linguaggio per la Comprensione dei Verbi
'Esplorazione dei Trasformatori Immagine-Linguaggio per la Comprensione dei Verbi' can be condensed to 'Esplorazione dei Trasformatori Immagine-Linguaggio per i Verbi'.
Collegare il linguaggio alla visione è un problema fondamentale per molti sistemi di intelligenza artificiale del mondo reale, come il recupero di immagini o la generazione di descrizioni per i non vedenti. Il successo in queste attività richiede che i modelli mettano in relazione diversi aspetti del linguaggio, come oggetti e verbi, alle immagini. Ad esempio, per distinguere tra le due immagini nella colonna centrale qui sotto, i modelli devono differenziare tra i verbi “prendere” e “calciare”. La comprensione dei verbi è particolarmente difficile in quanto richiede non solo il riconoscimento degli oggetti, ma anche la comprensione di come gli oggetti diversi in un’immagine siano correlati tra loro. Per superare questa difficoltà, introduciamo il dataset SVO-Probes e lo utilizziamo per analizzare la comprensione dei verbi da parte dei modelli linguistici e visivi.

In particolare, consideriamo modelli di trasformatori multimodali (ad esempio, Lu et al., 2019; Chen et al., 2020; Tan and Bansal, 2019; Li et al., 2020), che hanno dimostrato successo in una varietà di compiti linguistici e visivi. Tuttavia, nonostante le ottime prestazioni sui benchmark, non è chiaro se questi modelli abbiano una comprensione multimodale dettagliata. In particolare, lavori precedenti mostrano che i modelli linguistici e visivi possono avere successo sui benchmark senza una comprensione multimodale: ad esempio, rispondendo a domande sulle immagini basandosi solo su criteri linguistici (Agrawal et al., 2018) o “inventando” oggetti che non sono nell’immagine durante la descrizione delle immagini (Rohrbach et al., 2018). Per prevedere le limitazioni del modello, lavori come Shekhar et al. propongono valutazioni specializzate per analizzare sistematicamente i modelli della comprensione del linguaggio. Tuttavia, i set di test precedenti sono limitati per quanto riguarda il numero di oggetti e verbi. Abbiamo sviluppato SVO-Probes per valutare meglio le possibili limitazioni nella comprensione dei verbi nei modelli attuali.
SVO-Probes include 48.000 coppie immagine-frase e testa la comprensione per oltre 400 verbi. Ogni frase può essere scomposta in una tripletta <Soggetto, Verbo, Oggetto> (o tripletta SVO) e accoppiata con immagini di esempio positive e negative. Gli esempi negativi differiscono solo in un modo: il soggetto, il verbo o l’oggetto viene modificato. La figura qui sopra mostra esempi negativi in cui il soggetto (sinistra), il verbo (centro) o l’oggetto (destra) non corrisponde all’immagine. Questa formulazione del compito permette di isolare quali parti della frase il modello ha più difficoltà a comprendere. Inoltre, rende SVO-Probes più impegnativo rispetto ai compiti standard di recupero di immagini, in cui gli esempi negativi sono spesso completamente slegati dalla frase di ricerca.
- Apprendimento di trasmissione culturale robusta in tempo reale senza dati umani
- Prevedere il passato con Ithaca
- GopherCite Insegnare ai modelli di linguaggio a fornire risposte supportate da citazioni verificate
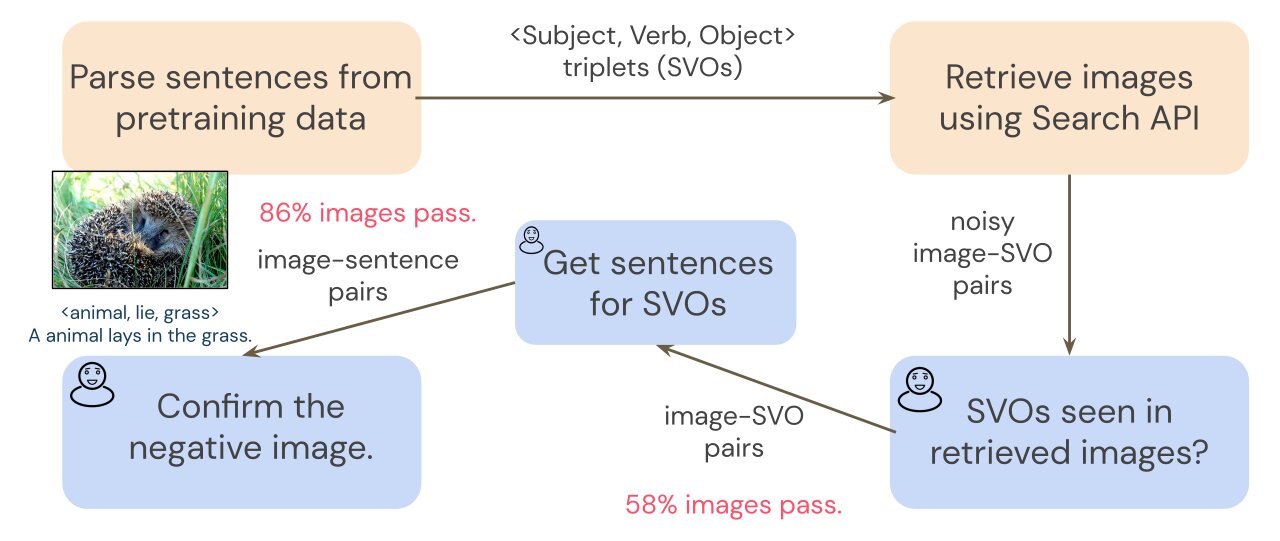
Per creare SVO-Probes, effettuiamo una ricerca di immagini utilizzando le triplette SVO da un dataset di addestramento comune, Conceptual Captions (Sharma et al., 2018). Poiché la ricerca di immagini può essere rumorosa, una fase preliminare di annotazione filtra le immagini recuperate per assicurarci di avere un insieme pulito di coppie immagine-SVO. Poiché i trasformatori vengono addestrati su coppie immagine-frase, e non su coppie immagine-SVO, abbiamo bisogno di coppie immagine-frase per analizzare il nostro modello. Per raccogliere frasi che descrivono ciascuna immagine, gli annotatori scrivono una breve frase per ogni immagine che include la tripletta SVO. Ad esempio, data la tripletta SVO <animale, giacere, erba>, un annotatore potrebbe scrivere la frase “Un animale si sdraia sull’erba”. Utilizziamo poi le annotazioni SVO per accoppiare ciascuna frase con un’immagine negativa e chiediamo agli annotatori di verificare i negativi in una fase finale di annotazione. Consulta la figura qui sotto per ulteriori dettagli.
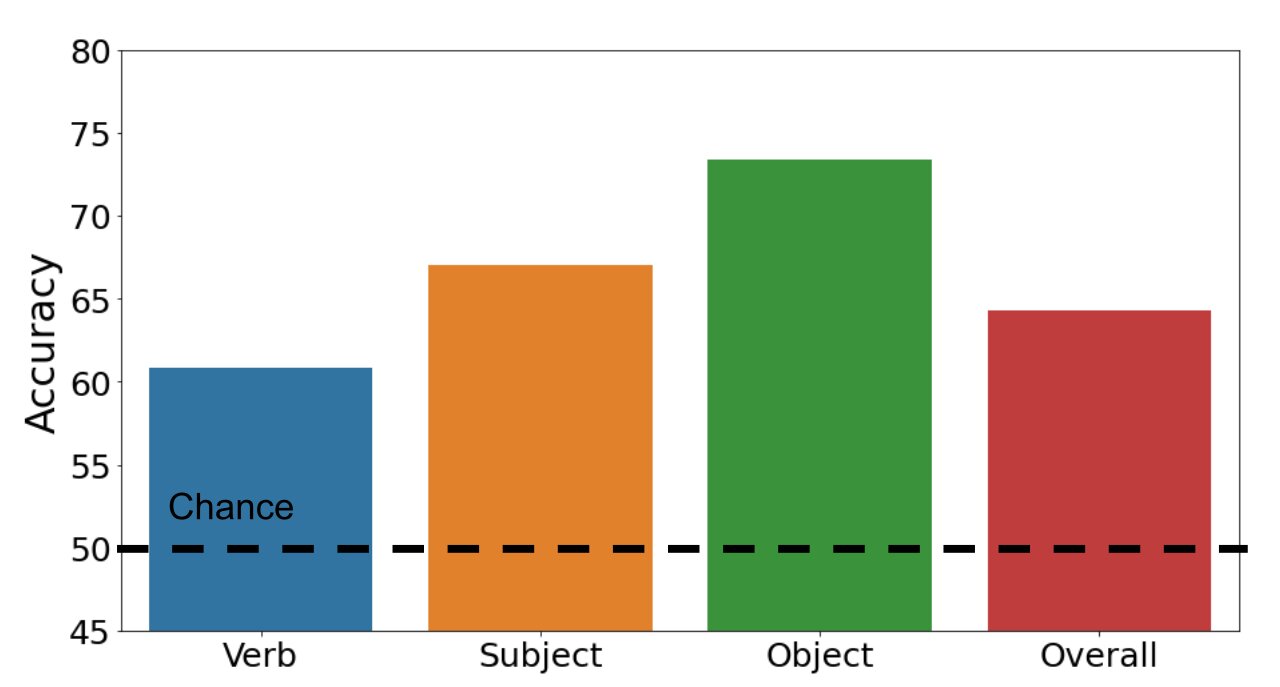
Esaminiamo se i trasformatori multimodali possono classificare correttamente gli esempi come positivi o negativi. Il grafico a barre qui sotto illustra i nostri risultati. Il nostro dataset è impegnativo: il nostro modello standard di trasformatore multimodale raggiunge un’accuratezza complessiva del 64,3% (il caso fortuito è del 50%). Mentre l’accuratezza è del 67,0% e del 73,4% rispettivamente per i soggetti e gli oggetti, la performance scende al 60,8% per i verbi. Questo risultato mostra che il riconoscimento dei verbi è davvero difficile per i modelli linguistici e visivi.
Esploriamo anche quali architetture di modelli ottengono i migliori risultati nel nostro dataset. Sorprendentemente, i modelli con una modellazione più debole delle immagini ottengono risultati migliori rispetto al modello standard di trasformatore. Un’ipotesi è che il nostro modello standard (con una maggiore capacità di modellazione delle immagini) si adatti eccessivamente all’insieme di addestramento. Poiché entrambi questi modelli ottengono risultati peggiori in altri compiti linguistici e visivi, il nostro compito mirato di analisi rivela debolezze del modello che non sono osservate su altri benchmark.
In generale, abbiamo scoperto che nonostante le prestazioni impressionanti sui benchmark, i multimodal transformers faticano ancora con la comprensione dettagliata, soprattutto la comprensione dettagliata dei verbi. Speriamo che SVO-Probes possa contribuire a stimolare l’esplorazione della comprensione dei verbi nei modelli di linguaggio e visione e ispirare dataset di probe più mirati.
Visita il nostro benchmark e i modelli SVO-Probes su GitHub: benchmark e modelli.






