Valutazione degli agenti interattivi multimodali
'Valutazione agenti interattivi multimodali'
Per addestrare gli agenti a interagire bene con gli esseri umani, dobbiamo essere in grado di misurare il progresso. Ma l’interazione umana è complessa e misurare il progresso è difficile. In questo lavoro abbiamo sviluppato un metodo, chiamato Standardised Test Suite (STS), per valutare gli agenti in interazioni temporali estese e multi-modalità. Abbiamo esaminato interazioni che consistono in partecipanti umani che chiedono agli agenti di svolgere compiti e rispondere a domande in un ambiente simulato 3D.
La metodologia STS posiziona gli agenti in un insieme di scenari comportamentali estratti da dati reali di interazione umana. Gli agenti vedono un contesto di scenario riprodotto, ricevono un’istruzione e quindi hanno il controllo per completare l’interazione in modalità offline. Queste continuazioni degli agenti vengono registrate e quindi inviate a valutatori umani per annotarle come successo o fallimento. Gli agenti vengono quindi classificati in base alla proporzione di scenari in cui hanno successo.
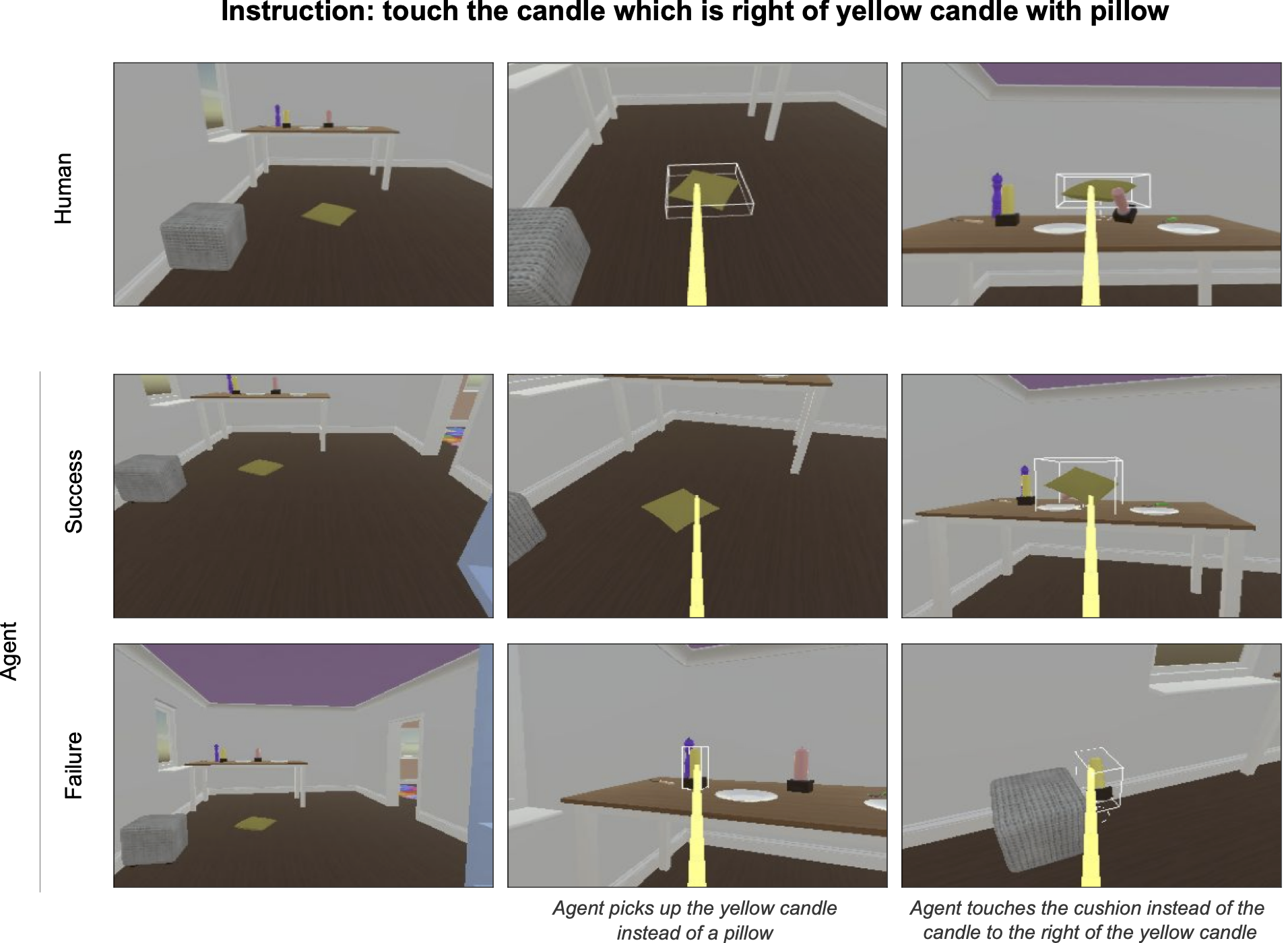
Molti dei comportamenti che sono naturali per gli esseri umani nelle nostre interazioni quotidiane sono difficili da esprimere a parole e impossibili da formalizzare. Pertanto, il meccanismo utilizzato per risolvere giochi (come Atari, Go, DotA e Starcraft) con l’apprendimento per rinforzo non funzionerà quando cerchiamo di insegnare agli agenti a interagire in modo fluido e di successo con gli esseri umani. Ad esempio, pensa alla differenza tra queste due domande: “Chi ha vinto questa partita di Go?” rispetto a “Cosa stai guardando?” Nel primo caso, possiamo scrivere un pezzo di codice informatico che conta le pietre sulla scacchiera alla fine della partita e determina con certezza il vincitore. Nel secondo caso, non abbiamo idea di come codificare questo: la risposta può dipendere dagli interlocutori, dalle dimensioni e dalle forme degli oggetti coinvolti, dal fatto che l’interlocutore stia scherzando e da altri aspetti del contesto in cui viene pronunciata l’enunciazione. Gli esseri umani comprendono intuitivamente la miriade di fattori rilevanti coinvolti nel rispondere a questa domanda apparentemente banale.
La valutazione interattiva da parte di partecipanti umani può servire come punto di riferimento per comprendere le prestazioni degli agenti, ma è rumorosa e costosa. È difficile controllare le istruzioni esatte che gli esseri umani danno agli agenti durante l’interazione con loro per la valutazione. Questo tipo di valutazione è anche in tempo reale, quindi è troppo lenta per fare progressi rapidi. Lavori precedenti si sono basati su proxy per la valutazione interattiva. I proxy, come le perdite e le attività di indagine scritte (ad esempio “solleva il x” dove x viene selezionato casualmente dall’ambiente e la funzione di successo viene creata manualmente), sono utili per ottenere rapidamente informazioni sugli agenti, ma non correlano effettivamente molto bene con la valutazione interattiva. Il nostro nuovo metodo ha vantaggi, principalmente offrendo controllo e velocità a una metrica che si allinea strettamente con il nostro obiettivo finale: creare agenti che interagiscono bene con gli esseri umani.
- Promuovere la comunità LGBTQ+ nella ricerca di intelligenza artificiale
- Collegando la ricerca di DeepMind ai prodotti di Alphabet
- Sblocco dell’alta precisione della classificazione differenziale privata delle immagini attraverso la scala
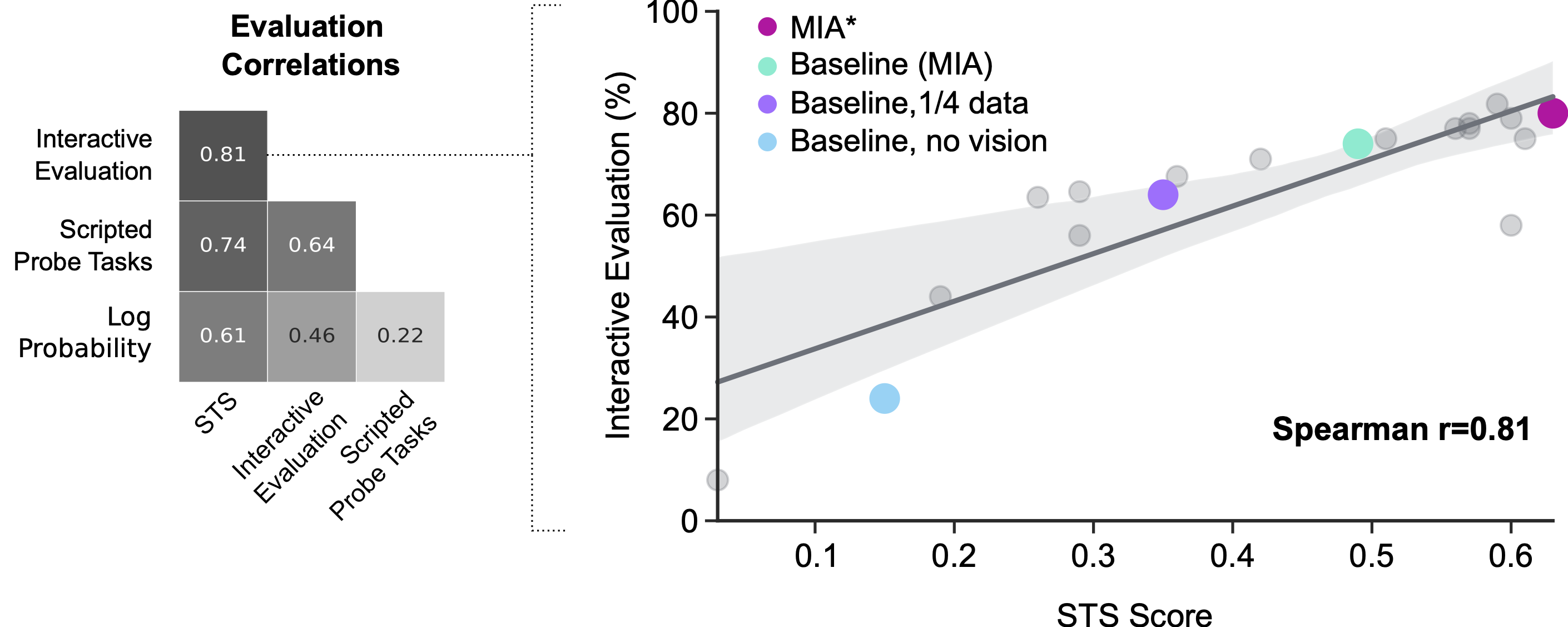
Lo sviluppo di MNIST, ImageNet e altri dataset annotati dall’uomo è stato essenziale per il progresso nell’apprendimento automatico. Questi dataset hanno consentito ai ricercatori di addestrare e valutare modelli di classificazione per un costo unico di input umani. La metodologia STS mira a fare lo stesso per la ricerca sull’interazione uomo-agente. Questo metodo di valutazione richiede ancora che gli esseri umani annotino le continuazioni degli agenti; tuttavia, esperimenti preliminari suggeriscono che l’automazione di queste annotazioni potrebbe essere possibile, consentendo una valutazione automatizzata veloce ed efficace degli agenti interattivi. Nel frattempo, speriamo che altri ricercatori possano utilizzare la metodologia e il design del sistema per accelerare le proprie ricerche in questo campo.






