Comportamento emergente di baratto nella Reinforcement Learning Multi-Agente
Emergent bartering behavior in Multi-Agent Reinforcement Learning.
Nel nostro recente articolo, esploriamo come popolazioni di agenti di deep reinforcement learning (deep RL) possano imparare comportamenti microeconomici, come la produzione, il consumo e il commercio di beni. Riscontriamo che gli agenti artificiali imparano a prendere decisioni economicamente razionali sulla produzione, il consumo e i prezzi, e reagiscono in modo appropriato ai cambiamenti di offerta e domanda. La popolazione converge verso prezzi locali che riflettono l’abbondanza di risorse nelle vicinanze, e alcuni agenti imparano a trasportare beni tra queste aree per “comprare a poco prezzo e vendere a caro prezzo”. Questo lavoro promuove l’agenda di ricerca più ampia sul reinforcement learning multi-agente introducendo nuove sfide sociali per gli agenti nell’apprendimento di come risolverle.
Nel contesto della ricerca sul reinforcement learning multi-agente, l’obiettivo è alla fine quello di produrre agenti che possano lavorare su tutta la gamma e complessità dell’intelligenza sociale umana, ma l’insieme di domini considerati finora è stato incredibilmente incompleto. Mancano ancora domini cruciali in cui l’intelligenza umana eccelle e in cui gli esseri umani dedicano quantità significative di tempo ed energia. L’economia è uno di questi domini. Il nostro obiettivo in questo lavoro è quello di creare ambienti basati sui temi del commercio e della negoziazione da utilizzare da parte dei ricercatori nel reinforcement learning multi-agente.
L’economia utilizza modelli basati su agenti per simulare il comportamento delle economie. Questi modelli basati su agenti spesso includono assunzioni economiche su come gli agenti dovrebbero comportarsi. In questo lavoro, presentiamo un mondo simulato multi-agente in cui gli agenti possono imparare comportamenti economici da zero, in modo familiare a qualsiasi studente di Microeconomia 101: decisioni sulla produzione, il consumo e i prezzi. Ma i nostri agenti devono anche prendere altre decisioni che derivano da un modo di pensare più fisicamente incarnato. Devono navigare in un ambiente fisico, trovare alberi per raccogliere frutta e partner con cui commerciare. I recenti progressi nelle tecniche di deep RL rendono ora possibile creare agenti in grado di imparare questi comportamenti da soli, senza richiedere a un programmatore di codificare la conoscenza di dominio.
Il nostro ambiente, chiamato Fruit Market, è un ambiente multiplayer in cui gli agenti producono e consumano due tipi di frutta: mele e banane. Ogni agente è abile nella produzione di un tipo di frutta, ma ha una preferenza per l’altro: se gli agenti riescono a imparare a barattare e scambiare beni, entrambe le parti ne beneficeranno.
- Dalle competizioni LEGO al laboratorio di robotica di DeepMind
- Apertura del codice sorgente di MuJoCo
- Costruire una cultura di pionierismo responsabile

Nelle nostre sperimentazioni, dimostriamo che gli attuali agenti di deep RL possono imparare a commerciare e che i loro comportamenti in risposta a cambiamenti di offerta e domanda si allineano con ciò che prevede la teoria microeconomica. Successivamente, basandoci su questo lavoro, presentiamo scenari che sarebbero molto difficili da risolvere utilizzando modelli analitici, ma che sono semplici per i nostri agenti di deep RL. Ad esempio, in ambienti in cui ogni tipo di frutta cresce in un’area diversa, osserviamo l’emergere di diverse regioni di prezzo legate all’abbondanza locale di frutta e successivamente l’apprendimento di comportamenti di arbitraggio da parte di alcuni agenti, che iniziano a specializzarsi nel trasporto di frutta tra queste regioni.
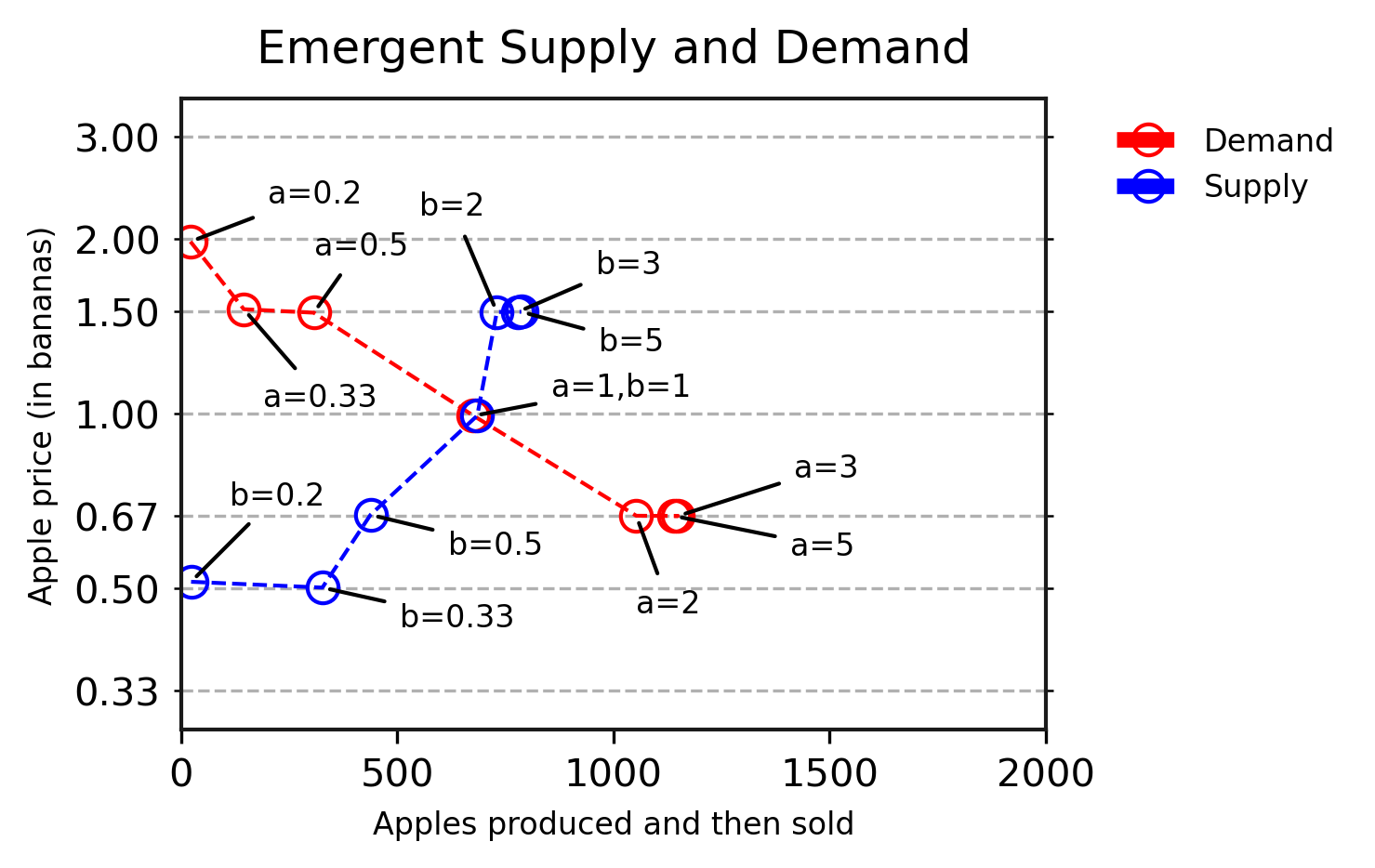
Il campo dell’economia computazionale basata su agenti utilizza simulazioni simili per la ricerca economica. In questo lavoro, dimostriamo anche che le tecniche di deep RL all’avanguardia possono imparare in modo flessibile ad agire in questi ambienti sulla base della loro esperienza, senza la necessità di conoscenze economiche predefinite. Ciò mette in evidenza i recenti progressi della comunità di reinforcement learning multi-agente e deep RL e dimostra il potenziale delle tecniche multi-agente come strumenti per avanzare nella ricerca economica simulata.
Come percorso verso l’intelligenza artificiale generale (AGI), la ricerca sul reinforcement learning multi-agente dovrebbe comprendere tutti i domini critici dell’intelligenza sociale. Tuttavia, finora non ha incluso fenomeni economici tradizionali come il commercio, la contrattazione, la specializzazione, il consumo e la produzione. Questo articolo colma questa lacuna e fornisce una piattaforma per ulteriori ricerche. Per agevolare future ricerche in questo campo, l’ambiente Fruit Market sarà incluso nella prossima versione della suite di ambienti Melting Pot.

.png)




