Distribuire il tuo modello di machine learning in produzione nel cloud
Come distribuire il tuo modello di machine learning in produzione nel cloud

AWS, o Amazon Web Services, è un servizio di cloud computing utilizzato in molte aziende per lo storage, l’analisi dei dati, le applicazioni, i servizi di distribuzione e molti altri. Si tratta di una piattaforma che utilizza diversi servizi per supportare le aziende in modo serverless con schemi di pagamento basati sull’utilizzo.
L’attività di modellazione dell’apprendimento automatico è anche una delle attività supportate da AWS. Con diversi servizi, è possibile supportare diverse attività di modellazione, come lo sviluppo del modello fino alla sua messa in produzione. AWS ha dimostrato di essere versatile, il che è essenziale per qualsiasi azienda che necessiti di scalabilità e velocità.
In questo articolo parleremo della messa in produzione di un modello di apprendimento automatico nel cloud di AWS. Come possiamo fare ciò? Esploriamolo ulteriormente.
- Elaborazione parallela nell’ingegneria dei prompt La tecnica dello scheletro del pensiero
- Vuoi diventare un Data Scientist? Parte 2 10 soft skills che ti servono
- La ricerca della fiducia delle modelle Puoi fidarti di una scatola nera?
Preparazione
Prima di iniziare questo tutorial, è necessario creare un account AWS, poiché ne avremo bisogno per accedere a tutti i servizi AWS. Indichiamo che il lettore utilizzerà il livello gratuito per seguire questo articolo. Inoltre, assumiamo che il lettore conosca già il linguaggio di programmazione Python e abbia una conoscenza di base dell’apprendimento automatico. Inoltre, ci concentreremo sulla parte di messa in produzione del modello e non presteremo attenzione ad altri aspetti dell’attività di data science, come la preelaborazione dei dati e la valutazione del modello.
Con questo in mente, inizieremo il nostro percorso per mettere in produzione il tuo modello di apprendimento automatico nei servizi cloud di AWS.
Messa in produzione del modello su AWS
In questo tutorial, svilupperemo un modello di apprendimento automatico per prevedere le disdette dai dati forniti. Il set di dati di addestramento viene acquisito da Kaggle, che puoi scaricare qui.
Dopo aver acquisito il set di dati, creeremo un bucket S3 per archiviare il set di dati. Cerca S3 nei servizi di AWS e crea il bucket.
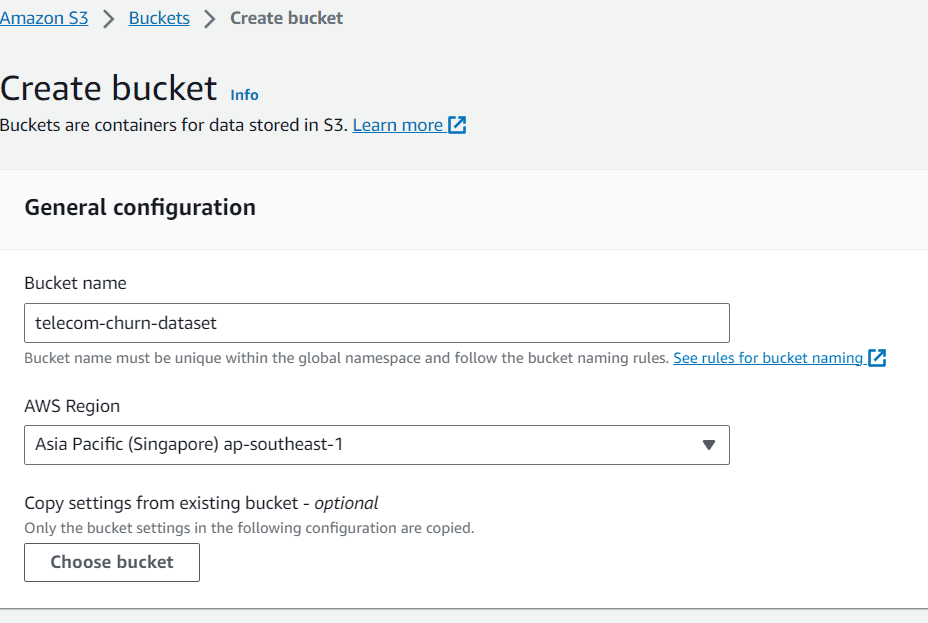
In questo articolo, ho chiamato il bucket “telecom-churn-dataset” e si trova a Singapore. Puoi cambiarlo se vuoi, ma per ora andiamo avanti così.
Dopo aver finito di creare il bucket e caricare i dati nel tuo bucket, passeremo al servizio AWS SageMaker. In questo servizio, utilizzeremo lo Studio come ambiente di lavoro. Se non hai mai utilizzato lo Studio, crea un dominio e un utente prima di procedere ulteriormente.
Prima, scegli Domini nelle configurazioni di Amazon SageMaker Admin.
Nella sezione Domini, vedrai molti pulsanti da selezionare. In questa schermata, seleziona il pulsante Crea dominio.
Scegli il setup rapido se vuoi accelerare il processo di creazione. Dopo aver finito, dovresti vedere un nuovo dominio creato nel dashboard. Seleziona il nuovo dominio appena creato e quindi clicca sul pulsante Aggiungi utente.
Successivamente, dovresti dare un nome al profilo utente secondo le tue preferenze. Per il ruolo di esecuzione, puoi lasciarlo su predefinito per ora, poiché è quello che è stato creato durante il processo di creazione del dominio.
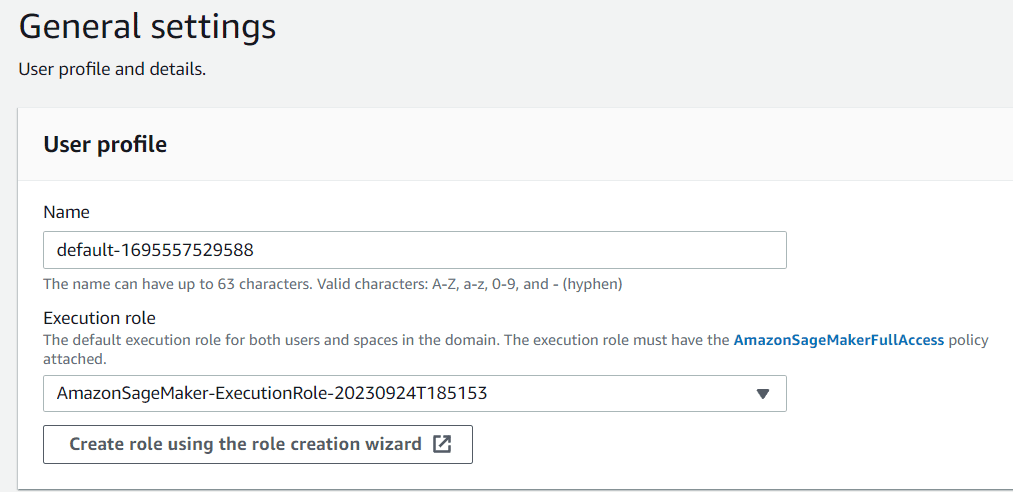
Fai semplicemente clic su Avanti fino alle impostazioni canvas. In questa sezione, disattivo alcune impostazioni che non ci servono, come la previsione di serie temporali.
Dopo aver impostato tutto, vai alla selezione dello Studio e seleziona il pulsante Apri studio con il nome utente appena creato.
All’interno dello Studio, navigare nella barra laterale che assomiglia a un’icona di una cartella e creare un nuovo notebook lì. Possiamo lasciarli per impostazione predefinita, come nell’immagine sottostante.
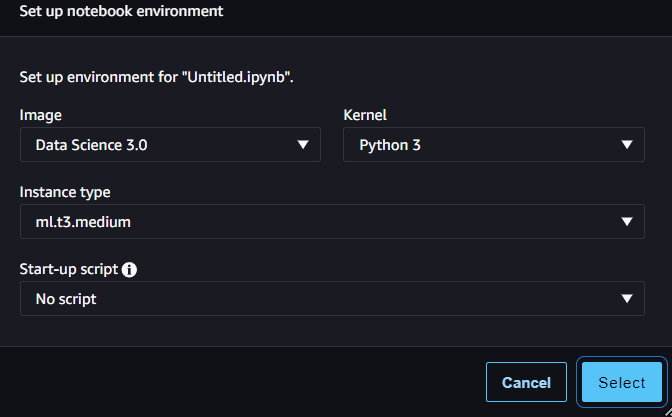 Immagine di Author
Immagine di Author
Con il nuovo notebook, lavoreremo per creare un modello di previsione di churn e distribuirlo in API inferences che possiamo utilizzare in produzione.
Per prima cosa, importiamo il pacchetto necessario e leggiamo i dati di churn.
import boto3 import pandas as pd import sagemaker sagemaker_session = sagemaker.Session() role = sagemaker.get_execution_role() df = pd.read_csv('s3://telecom-churn-dataset/telecom_churn.csv')  Immagine di Author
Immagine di Author
Successivamente, divideremo i dati sopra in dati di addestramento e dati di test con il seguente codice.
from sklearn.model_selection import train_test_split train, test = train_test_split(df, test_size = 0.3, random_state = 42)Impostiamo i dati di test al 30% dei dati originali. Con i nostri dati divisi, li caricheremo nuovamente nel bucket S3.
bucket = 'telecom-churn-dataset' train.to_csv(f's3://{bucket}/telecom_churn_train.csv', index = False) test.to_csv(f's3://{bucket}/telecom_churn_test.csv', index = False)Puoi vedere i dati all’interno del tuo bucket S3, che attualmente consiste in tre diverse serie di dati.
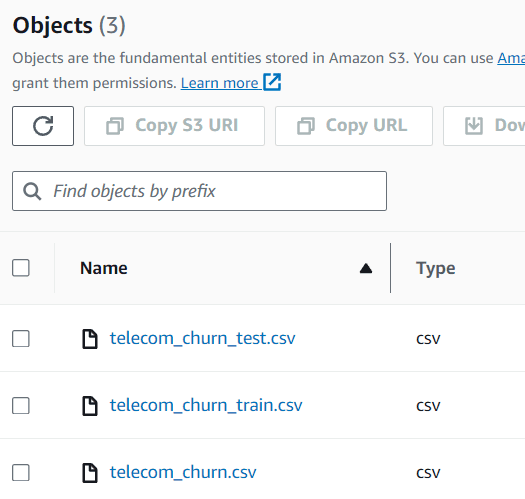 Immagine di Author
Immagine di Author
Con il nostro dataset pronto, svilupperemo ora un modello di previsione del churn e li distribuiremo. Nell’AWS, spesso usiamo un metodo di addestramento dello script per l’addestramento del machine learning. Ecco perché svilupperemo uno script prima di avviare l’addestramento.
Per il prossimo passaggio, dobbiamo creare un file Python aggiuntivo, che ho chiamato train.py, nella stessa cartella.
 Immagine di Author
Immagine di Author
All’interno di questo file, impostiamo il nostro processo di sviluppo del modello per creare il modello di churn. Per questo tutorial, adotterò del codice da Ram Vegiraju.
Per prima cosa, importeremo tutti i pacchetti necessari per lo sviluppo del modello.
import argparse import os import io import boto3 import json import pandas as pd from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import accuracy_score import joblibSuccessivamente, utilizzeremo il metodo parser per controllare la variabile che possiamo inserire nel nostro processo di addestramento. Il codice generale che inseriremo nel nostro script per addestrare il nostro modello è nel codice seguente.
if __name__ == '__main__': parser = argparse.ArgumentParser() parser.add_argument('--estimator', type=int, default=10) parser.add_argument('--sm-model-dir', type=str, default=os.environ.get('SM_MODEL_DIR')) parser.add_argument('--model_dir', type=str) parser.add_argument('--train', type=str, default=os.environ.get('SM_CHANNEL_TRAIN')) args, _ = parser.parse_known_args() estimator = args.estimator model_dir = args.model_dir sm_model_dir = args.sm_model_dir training_dir = args.train s3_client = boto3.client('s3') bucket = 'telecom-churn-dataset' obj = s3_client.get_object(Bucket=bucket, Key='telecom_churn_train.csv') train_data = pd.read_csv(io.BytesIO(obj['Body'].read())) obj = s3_client.get_object(Bucket=bucket, Key='telecom_churn_test.csv') test_data = pd.read_csv(io.BytesIO(obj['Body'].read())) X_train = train_data.drop('Churn', axis =1) X_test = test_data.drop('Churn', axis =1) y_train = train_data['Churn'] y_test = test_data['Churn'] rfc = RandomForestClassifier(n_estimators=estimator) rfc.fit(X_train, y_train) y_pred = rfc.predict(X_test) print('Punteggio di accuratezza: ',accuracy_score(y_test, y_pred)) joblib.dump(rfc, os.path.join(args.sm_model_dir, "rfc_model.joblib"))Infine, dobbiamo inserire quattro diverse funzioni che SageMaker richiede per fare le inferenze: model_fn, input_fn, output_fn e predict_fn.
# Modello deserializzato per caricarli def model_fn(model_dir): model = joblib.load(os.path.join(model_dir, "rfc_model.joblib")) return model # Richiesta di input dell'applicazione def input_fn(request_body, request_content_type): if request_content_type == 'application/json': request_body = json.loads(request_body) inp_var = request_body['Input'] return inp_var else: raise ValueError("Questo modello supporta solo l'input application/json") # Funzioni di previsione def predict_fn(input_data, model): return model.predict(input_data) # Funzione di output def output_fn(prediction, content_type): res = int(prediction[0]) resJSON = {'Output': res} return resJSON Con il nostro script pronto, eseguiremo il processo di formazione. Nel passaggio successivo, passeremo lo script creato in precedenza all’estimatore SKLearn. Questo estimatore è un oggetto Sagemaker che gestirà l’intero processo di formazione e avremmo solo bisogno di passare tutti i parametri simili al codice qui sotto.
from sagemaker.sklearn import SKLearnsklearn_estimator = SKLearn(entry_point='train.py', role=role, instance_count=1, instance_type='ml.c4.2xlarge', py_version='py3', framework_version='0.23-1', script_mode=True, hyperparameters={ 'estimator': 15})sklearn_estimator.fit() Se la formazione ha successo, otterrai il seguente report.
 Immagine di autore
Immagine di autore
Se desideri verificare l’immagine Docker per la formazione SKLearn e la posizione dell’artefatto del modello, puoi accedervi utilizzando il seguente codice.
model_artifact = sklearn_estimator.model_dataimage_uri = sklearn_estimator.image_uriprint(f'L'artefatto del modello è salvato in: {model_artifact}')print(f'L'URI dell'immagine è: {image_uri}') Con il modello al suo posto, successivamente distribuiremmo il modello in un punto di fornitura API che possiamo utilizzare per la previsione. Per farlo, possiamo utilizzare il seguente codice.
import timechurn_endpoint_name = 'churn-rf-model-' + time.strftime("%Y-%m-%d-%H-%M-%S", time.gmtime())churn_predictor = sklearn_estimator.deploy(initial_instance_count=1,instance_type = 'ml.m5.large',endpoint_name=churn_endpoint_name) Se la distribuzione ha successo, verrà creato il punto di fornitura del modello e potrai accedervi per creare una previsione. Puoi anche vedere il punto di fornitura nel dashboard di Sagemaker.
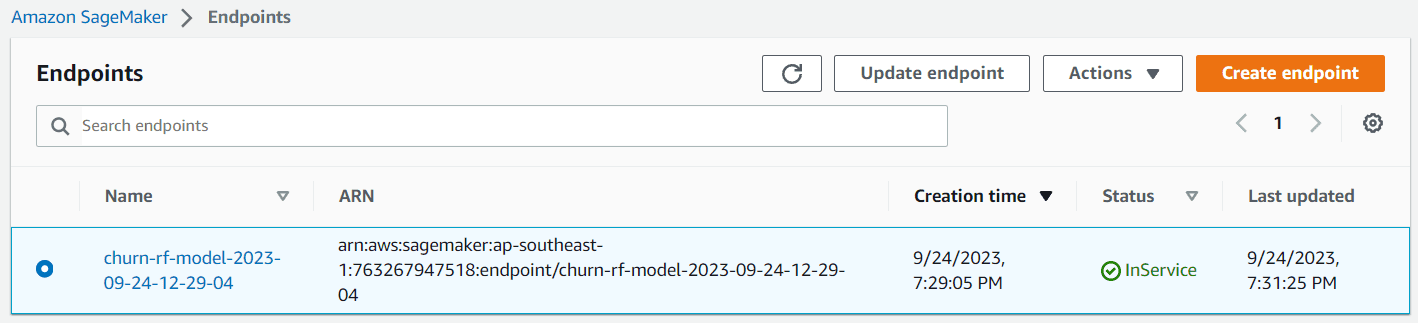 Immagine di autore
Immagine di autore
Ora puoi fare previsioni con questo punto di fornitura. Per farlo, puoi testare il punto di fornitura con il seguente codice.
client = boto3.client('sagemaker-runtime')content_type = "application/json"#sostituisci con i tuoi dati in input previsti request_body = {"Input": [[128,1,1,2.70,1,265.1,110,89.0, 9.87,10.0]]} #sostituisci con il nome del tuo punto di fornitura endpoint_name = "churn-rf-model-2023-09-24-12-29-04" #Serializzazione dei dati data = json.loads(json.dumps(request_body))payload = json.dumps(data)#Invoca il punto di fornituraresponse = client.invoke_endpoint(EndpointName = endpoint_name, ContentType = content_type, Body = payload)result = json.loads(response['Body'].read().decode())['Output']result Congratulazioni. Hai ora distribuito con successo il tuo modello nel cloud di AWS. Dopo aver completato il processo di test, non dimenticare di eliminare il punto di fornitura. Puoi usare il seguente codice per farlo.
from sagemaker import Sessionsagemaker_session = Session()sagemaker_session.delete_endpoint(endpoint_name='nome-del-tuo-punto-di-fornitura') Non dimenticare di spegnere l’istanza che utilizzi e pulire lo spazio di archiviazione S3 se non ne hai più bisogno.
Per ulteriori letture, puoi leggere di più sul SKLearn estimator e sulle inferenze di Batch Transform se preferisci non avere un modello di punto finale.
Conclusioni
La piattaforma Cloud di AWS è una piattaforma multiuso che molte aziende utilizzano per supportare il proprio business. Uno dei servizi spesso utilizzati è per fini di analisi dei dati, specialmente nella produzione del modello. In questo articolo, impariamo a utilizzare AWS SageMaker e come distribuire il modello nel punto finale. Cornellius Yudha Wijaya è assistente responsabile della scienza dei dati e scrittore di dati. Mentre lavora a tempo pieno presso Allianz Indonesia, ama condividere consigli su Python e dati tramite i social media e i media scritti.





