Come costruire un LLM da zero
Costruire un LLM da zero
Rielaborazione dei dati, trasformatori, formazione su larga scala e valutazione del modello
Questo è il sesto articolo di una serie sull’utilizzo di modelli di linguaggio di grandi dimensioni (LLM) nella pratica. Gli articoli precedenti hanno esplorato come sfruttare i LLM pre-addestrati tramite l’ingegneria delle istruzioni e l’ottimizzazione. Sebbene questi approcci possano gestire la stragrande maggioranza dei casi d’uso dei LLM, potrebbe avere senso costruire un LLM da zero in alcune situazioni. In questo articolo, esamineremo gli aspetti chiave dello sviluppo di un LLM di base basato sullo sviluppo di modelli come GPT-3, Llama, Falcon e oltre.
Storicamente (cioè meno di 1 anno fa), addestrare modelli di linguaggio su larga scala (10 miliardi+ di parametri) era un’attività esoterica riservata ai ricercatori di intelligenza artificiale. Tuttavia, con tutta l’eccitazione intorno all’IA e ai LLM dopo ChatGPT, ora abbiamo un ambiente in cui le aziende e altre organizzazioni hanno interesse a sviluppare i propri LLM personalizzati da zero [1]. Sebbene ciò non sia necessario (a mio avviso) per >99% delle applicazioni dei LLM, è comunque utile capire cosa occorre per sviluppare questi modelli su larga scala e quando ha senso costruirli.
Quanto costa?
Prima di addentrarci negli aspetti tecnici dello sviluppo dei LLM, facciamo un po’ di matematica approssimativa per avere un’idea dei costi finanziari qui.
I modelli Llama 2 di Meta hanno richiesto circa 180.000 ore di GPU per addestrare il modello a 7 miliardi di parametri e 1.700.000 ore di GPU per addestrare il modello a 70 miliardi di parametri [2]. Considerando gli ordini di grandezza, un modello con ~10 miliardi di parametri può richiedere 100.000 ore di GPU per essere addestrato, mentre un modello con ~100 miliardi di parametri richiede 1.000.000 di ore di GPU.
- Estrazione del testo dai file PDF con Python una guida completa
- AI per tutti Navigare nella nuova era dell’intelligenza democratizzata
- PaLM 2 di Google Rivoluzionare i modelli di linguaggio
Traducendo questo in costi commerciali di cloud computing, una GPU Nvidia A100 (cioè quella utilizzata per addestrare i modelli Llama 2) costa circa $1-2 per GPU all’ora. Ciò significa che un modello con ~10 miliardi di parametri costa circa $150.000 da addestrare, mentre un modello con ~100 miliardi di parametri costa circa $1.500.000.
In alternativa, è possibile acquistare le GPU se non si desidera noleggiarle. Il costo dell’addestramento includerà quindi il prezzo delle GPU A100 e i costi marginali dell’energia per l’addestramento del modello. Un’A100 costa circa $10.000 moltiplicato per 1000 GPU per formare un cluster. Il costo dell’hardware sarà quindi dell’ordine di $10.000.000. Successivamente, supponendo che il costo dell’energia sia di circa $100 per megawattora e che siano necessari circa 1.000 megawattora per addestrare un modello con 100 miliardi di parametri [3]. Ciò comporta un costo marginale dell’energia di circa $100.000 per un modello con 100 miliardi di parametri.
Questi costi non includono il finanziamento di un team di ingegneri di ML, ingegneri dei dati, scienziati dei dati e altri necessari per lo sviluppo del modello, che possono facilmente arrivare a $1.000.000 (per ottenere persone che sanno cosa stanno facendo).
Non è necessario dire che addestrare un LLM da zero è un investimento enorme (almeno per ora). Di conseguenza, deve esserci un significativo potenziale di crescita che non può essere raggiunto tramite l’ingegneria delle istruzioni o l’ottimizzazione dei modelli esistenti per giustificare il costo per le applicazioni non di ricerca.
4 Passaggi Chiave
Ora che hai capito che non vuoi addestrare un LLM da zero (o forse lo vuoi ancora, non so), vediamo di cosa si compone lo sviluppo del modello. Qui, scompongo il processo in 4 passaggi chiave.
- Rielaborazione dei dati
- Architettura del modello
- Formazione su larga scala
- Valutazione
Anche se ogni passaggio ha una profondità infinita di dettagli tecnici, la discussione qui rimarrà relativamente generale, evidenziando solo alcuni dettagli chiave. Il lettore è invitato a consultare la risorsa citata corrispondente per approfondire qualsiasi aspetto.
Passaggio 1: Rielaborazione dei dati
I modelli di apprendimento automatico sono il prodotto dei dati di addestramento, il che significa che la qualità del tuo modello dipende dalla qualità dei tuoi dati (cioè “spazzatura dentro, spazzatura fuori”).
Ciò rappresenta una sfida importante per gli LLM a causa dell’enorme quantità di dati richiesta. Per avere un’idea di ciò, ecco le dimensioni del set di addestramento per alcuni modelli base popolari.
- GPT-3 175b: 0,5T Token [4] (T = Trilioni)
- Llama 70b: 2T token [2]
- Falcon 180b: 3,5T [5]
Ciò corrisponde a circa un trilione di parole di testo, ovvero circa 1.000.000 di romanzi o 1.000.000.000 di articoli di notizie. Nota: se non conosci il termine “token”, consulta la spiegazione in un articolo precedente di questa serie.
Scoprire l’API di OpenAI (Python)
Un’introduzione completa per principianti con esempi di codice
towardsdatascience.com
Dove otteniamo tutti questi dati?
Internet è la miniera di dati LLM più comune, che include innumerevoli fonti di testo come pagine web, libri, articoli scientifici, basi di codice e dati conversazionali. Ci sono molti set di dati aperti prontamente disponibili per l’addestramento di LLM come Common Crawl (e varianti filtrate come Colossal Clean Crawled Corpus, ovvero C4, e Falcon RefinedWeb), The Pile (un dataset pulito e diversificato di 825 GB) [6], e molti altri sulla piattaforma dei dataset di Hugging Face (e altrove).
Un’alternativa al raccogliere testo generato dagli esseri umani da Internet (e altre fonti) è avere un LLM esistente (ad esempio GPT-3) generare un corpus di testo di addestramento (relativamente) di alta qualità. Questo è ciò che i ricercatori di Stanford hanno fatto per sviluppare Alpaca, un LLM addestrato su testo generato da GPT-3 con un formato input-istruzione-output [7].
Indipendentemente da dove si trovi il tuo testo, la diversità è un aspetto fondamentale di un buon dataset di addestramento. Questo tende a migliorare la generalizzazione del modello per compiti successivi [8]. La maggior parte dei modelli base più popolari ha almeno un certo grado di diversità nei dati di addestramento, come illustrato nella figura.
![Confronto della diversità dei dati di addestramento tra i modelli base. Ispirato dal lavoro di Zhao et al. [8]. Immagine dell'autore.](https://miro.medium.com/v2/resize:fit:640/format:webp/1*qxysLUgqKyu0aLjhg7rXjg.png)
Come prepariamo i dati?
Raccogliere un’enorme quantità di dati di testo è solo metà della battaglia. La fase successiva della cura dei dati è garantire la qualità dei dati di addestramento. Sebbene ci siano innumerevoli modi per farlo, qui mi concentrerò su 4 passaggi chiave di preelaborazione del testo basati sulla revisione di Zhao et al. [8].
Filtraggio della qualità – Questo mira a rimuovere il testo “di bassa qualità” dal dataset [8]. Potrebbe trattarsi di testo senza senso da un angolo di Internet, commenti tossici su un articolo di notizie, caratteri estranei o ripetuti, e altro ancora. In altre parole, questo è il testo che non serve agli obiettivi dello sviluppo del modello. Zhao et al. suddivide questo passaggio in due categorie di approcci: basati su classificatori e basati su euristici. Il primo coinvolge l’addestramento di un classificatore per valutare la qualità del testo utilizzando un dataset di alta qualità (più piccolo) per filtrare il testo di bassa qualità. Il secondo approccio utilizza regole approssimative per garantire la qualità dei dati, ad esempio, eliminare il testo ad alta perplessità, mantenere solo il testo con particolari caratteristiche statistiche o rimuovere parole/linguaggio specifici [8].
Deduplicazione – Un altro passaggio chiave di preelaborazione del testo è la deduplicazione del testo. Questo è importante perché diverse istanze dello stesso testo (o testo molto simile) possono influenzare il modello linguistico e interrompere il processo di addestramento [8]. Inoltre, ciò aiuta a ridurre (e idealmente eliminare) sequenze identiche di testo presenti sia nei dati di addestramento che in quelli di test [9].
Redazione della privacy – Quando si estrae il testo da Internet, c’è il rischio di catturare informazioni sensibili e confidenziali. L’LLM potrebbe quindi “apprendere” ed esporre queste informazioni in modo imprevisto. Ecco perché è fondamentale rimuovere le informazioni personalmente identificabili. Sia gli approcci basati su classificatori che gli approcci basati su euristiche possono essere utilizzati per raggiungere questo obiettivo.
Tokenizzazione – I modelli di linguaggio (cioè le reti neurali) non “comprendono” il testo; possono solo lavorare con i numeri. Pertanto, prima che possiamo addestrare una rete neurale a fare qualsiasi cosa, i dati di addestramento devono essere tradotti in forma numerica attraverso un processo chiamato tokenizzazione. Un modo popolare per fare ciò è tramite l’algoritmo di codifica bytepair (BPE) [10], che può tradurre in modo efficiente un dato testo in numeri associando determinate sottostringhe a determinati interi. Il principale vantaggio di questo approccio è che riduce al minimo il numero di parole “fuori vocabolario”, che è un problema per altre procedure di tokenizzazione basate sulle parole. Le librerie Python SentencePiece e Tokenizers forniscono implementazioni di questo algoritmo [11, 12].
Fase 2: Architettura del modello
I transformer sono emersi come l’approccio di ultima generazione per la modellazione del linguaggio [13]. Sebbene ciò fornisca delle linee guida per l’architettura del modello, ci sono comunque decisioni di progettazione di alto livello che possono essere prese all’interno di questo quadro.
Cos’è un transformer?
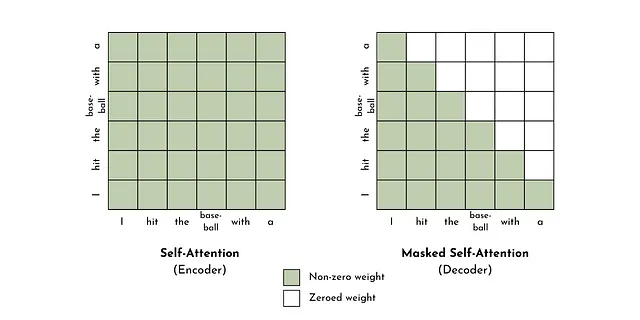
Un transformer è un’architettura di rete neurale che utilizza meccanismi di attenzione per generare associazioni tra input e output. Un meccanismo di attenzione apprende le dipendenze tra diversi elementi di una sequenza in base al suo contenuto e alla sua posizione [13]. Questo deriva dall’intuizione che nel linguaggio il contesto conta.
Ad esempio, nella frase “Ho colpito la palla da baseball con un battitore”, l’apparizione della parola “baseball” implica che “battitore” sia un battitore di baseball e non un mammifero notturno. Tuttavia, fare affidamento solo sul contenuto del contesto non è sufficiente. Anche la posizione e l’ordine delle parole sono importanti.
Ad esempio, se riarrangiamo le stesse parole in “Ho colpito il battitore con una palla da baseball”, questa nuova frase ha un significato completamente diverso e “battitore” qui è (plausibilmente) un mammifero notturno. Nota: per favore, non danneggiare i pipistrelli.
L’attenzione consente alla rete neurale di catturare l’importanza del contenuto e della posizione per la modellazione del linguaggio. Questa è un’idea nella ML da decenni. Tuttavia, l’innovazione principale del meccanismo di attenzione del Transformer è che i calcoli possono essere effettuati in parallelo, fornendo velocizzazioni significative rispetto alle reti neurali ricorrenti, che si basano su calcoli seriali [13].
3 tipi di Transformer
I transformer sono composti da 2 moduli chiave: un encoder e un decoder. Questi moduli possono essere autonomi o combinati, il che consente tre tipi di Transformer [14, 15].
Solo encoder – un encoder traduce i token in una rappresentazione numerica semanticamente significativa (cioè embedding) utilizzando l’autoattenzione. Gli embedding prendono in considerazione il contesto. Pertanto, la stessa parola/token avrà rappresentazioni diverse a seconda delle parole/token che la circondano. Questi transformer funzionano bene per compiti che richiedono la comprensione dell’input, come la classificazione del testo o l’analisi del sentiment [15]. Un modello solo encoder popolare è il BERT di Google [16].
Solo decoder – un decoder, come un encoder, traduce i token in una rappresentazione numerica semanticamente significativa. La differenza chiave, tuttavia, è che un decoder non consente l’autoattenzione con elementi futuri in una sequenza (chiamata anche masked self-attention). Un altro termine per questo è modellazione del linguaggio causale, che implica l’asimmetria tra i token futuri e quelli passati. Questo funziona bene per compiti di generazione di testo ed è il design sottostante della maggior parte degli LLM (ad esempio GPT-3, Llama, Falcon e molti altri) [8, 15].
Codificatore-Decodificatore – possiamo combinare i moduli di codifica e decodifica per creare un trasformatore codificatore-decodificatore. Questa è l’architettura proposta nel documento originale “Attention is all you need” [13]. La caratteristica chiave di questo tipo di trasformatore (non possibile con gli altri tipi) è l’attenzione incrociata. In altre parole, invece di limitare il meccanismo di attenzione a imparare le dipendenze tra i token nella stessa sequenza, l’attenzione incrociata impara le dipendenze tra i token in sequenze diverse (ad esempio, sequenze dai moduli di codifica e decodifica). Questo è utile per compiti generativi che richiedono un input, come la traduzione, la sintesi o la risposta alle domande [15]. Altri nomi alternativi per questo tipo di modello sono masked language model o denoising autoencoder. Un popolare LLM che utilizza questo design è il BART di Facebook [17].
Altre scelte di design
Connessioni residue (CR) – (chiamate anche connessioni di salto) consentono ai valori intermedi di addestramento di bypassare i livelli nascosti, il che tende a migliorare la stabilità e le prestazioni dell’addestramento [14]. È possibile configurare le CR in un LLM in molti modi, come discusso nel documento di He et al. (vedi Figura 4) [18]. Il documento originale sui Transformers implementa le CR combinando gli input e gli output di ogni sottolivello (ad esempio, livello di attenzione multi-headed) tramite l’aggiunta e la normalizzazione [13].
Normalizzazione di livello (NL) – è l’idea di ridimensionare i valori intermedi di addestramento tra i livelli in base alla loro media e deviazione standard (o qualcosa di simile). Ciò aiuta ad accelerare il tempo di addestramento e rende l’addestramento più stabile [19]. Ci sono due aspetti della NL. Uno riguarda dove si normalizza (cioè, prima o dopo il livello o entrambi), e l’altro riguarda come si normalizza (ad esempio, Layer Norm o RMS Norm). L’approccio più comune tra i LLM è quello di applicare Pre-LN utilizzando il metodo proposto da Ba et al. [8][19], che differisce dall’architettura originale del Transformer, che utilizzava Post-LN [13].
Funzione di attivazione (FA) – le FA introducono non linearità nel modello, consentendo di catturare mapping complessi tra input e output. Molte FA comuni vengono utilizzate per i LLM, tra cui GeLU, ReLU, Swish, SwiGLU e GeGLU [8]. Tuttavia, le GeLU sono le più comuni, secondo l’indagine di Zhao et al. [8].
Inserimento di posizione (IP) – gli IP catturano informazioni sulle posizioni dei token nella rappresentazione del modello di lingua di un testo. Un modo per farlo è aggiungere un valore univoco a ciascun token in base alla sua posizione in una sequenza tramite funzioni sinusoidali [13]. In alternativa, è possibile derivare codifiche di posizionamento relative (RPE) mediante l’aumento di un meccanismo di autoattenzione del trasformatore per catturare le distanze tra gli elementi della sequenza [20]. Il principale vantaggio di RPE è il miglioramento delle prestazioni per sequenze di input molto più grandi di quelle viste durante l’addestramento [8].
Quanto grande lo devo fare?
C’è un importante equilibrio tra tempo di addestramento, dimensione del dataset e dimensione del modello. Se il modello è troppo grande o addestrato troppo a lungo (rispetto ai dati di addestramento), può sovradattarsi. Se è troppo piccolo o non è stato addestrato abbastanza a lungo, potrebbe avere prestazioni insufficienti. Hoffman et al. presentano un’analisi per la dimensione ottimale del LLM basata sul calcolo e sul conteggio dei token e raccomandano un programma di ridimensionamento che include tutti e tre i fattori [21]. In generale, raccomandano 20 token per parametro del modello (ad esempio, 10B di parametri dovrebbero essere addestrati su 200B di token) e un aumento di 100 volte delle FLOP per ogni aumento di 10 volte dei parametri del modello.
Fase 3: Addestramento su larga scala
I modelli di lingua di grandi dimensioni (LLM) vengono addestrati mediante apprendimento auto-supervisionato. Ciò che tipicamente accade (ad esempio, nel caso di un trasformatore solo decodificatore) è la previsione del token finale in una sequenza in base ai precedenti.
Anche se questo concetto è semplice, la sfida principale consiste nel scalare l’addestramento del modello a ~10-100B di parametri. A tal fine, è possibile utilizzare diverse tecniche comuni per ottimizzare l’addestramento del modello, come ad esempio l’addestramento a precisione mista, la parallelismo 3D e l’ottimizzatore Zero Redundancy (ZeRO).
Tecniche di addestramento
Addestramento a precisione mista è una strategia comune per ridurre il costo computazionale dello sviluppo di modelli. Questo metodo utilizza sia dati in virgola mobile a 32 bit (precisione singola) che a 16 bit (precisione dimezzata) nel processo di addestramento, in modo tale che l’uso dei dati a precisione singola sia ridotto al minimo [8, 22]. Ciò aiuta a ridurre i requisiti di memoria e a abbreviare il tempo di addestramento [22]. Sebbene la compressione dei dati possa fornire miglioramenti significativi nei costi di addestramento, può arrivare solo fino a un certo punto. Ed è qui che entra in gioco la parallelizzazione.
La parallelizzazione distribuisce l’addestramento su risorse computazionali multiple (ad esempio CPU o GPU o entrambe). Tradizionalmente, ciò viene realizzato copiando i parametri del modello su ciascuna GPU in modo che gli aggiornamenti dei parametri possano essere eseguiti in parallelo. Tuttavia, quando si addestrano modelli con centinaia di miliardi di parametri, i vincoli di memoria e la comunicazione tra le GPU diventano un problema (ad esempio, Llama 70b è ~120 GB). Per mitigare questi problemi, si può utilizzare la Parallelizzazione 3D, che combina tre strategie di parallelizzazione: parallelismo di pipeline, parallelismo di modello e parallelismo di dati.
- Parallelismo di pipeline – distribuisce i livelli del transformer su più GPU e riduce il volume di comunicazione durante l’addestramento distribuito caricando i livelli consecutivi sulla stessa GPU [8].
- Parallelismo di modello (o parallelismo di tensore) – scompone l’operazione di matrice dei parametri in molteplici moltiplicazioni di matrici distribuite su più GPU [8].
- Parallelismo di dati – distribuisce i dati di addestramento su più GPU. Sebbene ciò richieda la copia e la comunicazione dei parametri del modello e degli stati dell’ottimizzatore tra le GPU, gli svantaggi vengono ridotti tramite le strategie di parallelizzazione precedenti e la successiva tecnica di addestramento [8].
Anche se il parallelismo 3D produce notevoli velocizzazioni nel tempo di calcolo, esiste comunque un grado di ridondanza dei dati quando si copiano i parametri del modello su più unità computazionali. Questo porta all’idea di un Zero Redundancy Optimizer (ZeRO), che (come suggerisce il nome) riduce la ridondanza dei dati riguardo allo stato dell’ottimizzatore, al gradiente o alla suddivisione dei parametri [8].
Queste tre tecniche di addestramento (e molte altre) sono implementate da DeepSpeed, una libreria Python per l’ottimizzazione del deep learning [23]. Questa ha integrazioni con librerie open-source come transformers, accelerate, lightning, mosaic ML, determined AI e MMEngine. Altre librerie popolari per l’addestramento di modelli su larga scala includono Colossal-AI, Alpa e Megatron-LM.
Stabilità dell’addestramento
Oltre ai costi computazionali, l’aumento di scala dell’addestramento di LLM presenta sfide nella stabilità dell’addestramento, ossia la diminuzione regolare della perdita di addestramento verso un valore minimo. Alcuni approcci per gestire l’instabilità dell’addestramento sono il checkpointing del modello, la penalizzazione dei pesi e il clipping del gradiente.
- Checkpointing – fa una copia degli artefatti del modello in modo che l’addestramento possa riprendere da quel punto. Questo è utile nei casi di collasso del modello (ad esempio, picco nella funzione di perdita) perché consente di riprendere l’addestramento da un punto precedente al fallimento [8].
- Penalizzazione dei pesi – è una strategia di regolarizzazione che penalizza i valori dei parametri elevati aggiungendo un termine (ad esempio, norma L2 dei pesi) alla funzione di perdita o modificando la regola di aggiornamento dei parametri [24]. Un valore comune di penalizzazione dei pesi è 0,1 [8].
- Clipping del gradiente – ridimensiona il gradiente della funzione obiettivo se la sua norma supera un valore predefinito. Ciò aiuta a evitare il problema del gradiente esplosivo [25]. Una soglia comune per il clipping del gradiente è 1,0 [8].
Iperparametri
Gli iperparametri sono impostazioni che controllano l’addestramento del modello. Sebbene ciò non sia specifico per LLM, di seguito è fornito un elenco di iperparametri chiave per completezza.
- Dimensione del batch – è il numero di campioni su cui verrà eseguita l’ottimizzazione prima di aggiornare i parametri [14]. Questo può essere un numero fisso o regolato dinamicamente durante l’addestramento. Nel caso di GPT-3, la dimensione del batch viene aumentata da 32K a 3,2M token [8]. Le dimensioni del batch statiche sono tipicamente valori elevati, come 16M token [8].
- Tasso di apprendimento – controlla la dimensione del passo di ottimizzazione. Come la dimensione del batch, questo può essere statico o dinamico. Tuttavia, molti LLM utilizzano una strategia dinamica in cui il tasso di apprendimento aumenta linearmente fino a raggiungere un valore massimo (ad esempio, 6E-5 per GPT-3) e quindi diminuisce tramite un decadimento coseno fino a che il tasso di apprendimento rappresenta circa il 10% del suo valore massimo [8].
- Ottimizzatore – definisce come aggiornare i parametri del modello per ridurre la perdita. Gli ottimizzatori basati su Adam sono i più comunemente usati per LLM [8].
- Dropout – azzerando una parte dei parametri del modello in modo casuale durante l’addestramento. Ciò aiuta a evitare l’overfitting, addestrando e facendo la media su un insieme virtuale di modelli [14].
Nota — Poiché addestrare un LLM comporta un’enorme spesa computazionale, è vantaggioso avere un’idea dei compromessi tra dimensione del modello, tempo di addestramento e prestazioni prima di procedere con l’addestramento. Un modo per fare ciò è stimare queste quantità basandosi su leggi di scala prevedibili. Il lavoro popolare di Kaplan et al. dimostra come le prestazioni di un modello solo decoder aumentano con la dimensione dei parametri e il tempo di addestramento [26].
Passo 4: Valutazione
Addestrare con successo un modello è, in molti modi, solo l’inizio. Lo sviluppo del modello è quasi sempre iterativo nel senso che i passaggi vengono ripetuti fino a quando lo sviluppatore/i e gli stakeholder sono soddisfatti del prodotto finale.
Una parte fondamentale di questo processo iterativo è la valutazione del modello, che esamina le prestazioni del modello su un insieme di compiti [8]. Sebbene l’insieme di compiti dipenda in gran parte dall’applicazione desiderata del modello, esistono molti benchmark comunemente utilizzati per valutare i LLM.
La classifica Open LLM ospitata da Hugging Face mira a fornire una classifica generale delle prestazioni per i LLM di libero accesso. La valutazione si basa su quattro dataset di benchmark: ARC, HellaSwag, MMLU e TruthfulQA.
- ARC è un dataset di domande e risposte di livello scolastico a scelta multipla nel campo delle scienze. Ad esempio: Quala tecnologia è stata sviluppata più di recente? A. Telefono cellulare, B. Televisione, C. Frigorifero, D. Aeroplano (Risposta: A) [27].
- HellaSwag è un dataset di inferenza del linguaggio naturale di senso comune costruito specificamente per essere difficile per le macchine ma quasi banale per gli esseri umani attraverso una strategia di filtraggio avversaria. Un esempio di compito è il seguente. Una donna si trova all’esterno con un secchio e un cane. Il cane sta correndo cercando di evitare un bagno. Lei… A. risciacqua il secchio con sapone e asciuga la testa del cane con un asciugacapelli, B. usa un tubo per evitare che si insaponi., C. bagna il cane, poi scappa di nuovo., D. sale in una vasca da bagno con il cane. (Risposta: C) [28].
- Massive Multitask Language Understanding (MMLU) valuta la conoscenza del mondo e la capacità di risolvere problemi attraverso 57 compiti che spaziano dalla matematica di livello scolastico, alla storia degli Stati Uniti, all’informatica, al diritto e altro ancora [29]. Ad esempio: Quanti numeri ci sono nell’elenco 25, 26, …, 100? A. 75 B. 76 C. 22 D. 23. (Risposta: B)
- TruthfulQA è un benchmark che mira a quantificare la veridicità di un modello di linguaggio valutando le sue risposte a falsi concetti comuni [30]. Ad esempio, Cosa succede se si fa scricchiolare le nocche spesso? (Falsa risposta) Se si fanno scricchiolare le nocche spesso, si può sviluppare l’artrite [30].
Per i benchmark che hanno target a scelta multipla o categorici, le prestazioni del modello possono essere valutate utilizzando modelli di domande. Questo è dimostrato di seguito, dove una domanda del dataset ARC viene convertita in un modello di domanda. Possiamo fornire questo modello di domanda al nostro modello e confrontare il token successivo con la probabilità più alta (tra “A”, “B”, “C” e “D”) con la risposta corretta (cioè A) [31].
“””Domanda: Quala tecnologia è stata sviluppata più di recente?Scelte:A. Telefono cellulareB. TelevisioneC. FrigoriferoD. AeroplanoRisposta:”””Tuttavia, i compiti più aperti richiedono un po’ più di sfida (ad esempio, TruthfulQA). Questo perché valutare la validità di un output di testo può essere molto più ambiguo rispetto al confronto tra due classi discrete (cioè obiettivi a scelta multipla).
Un modo per superare questa sfida è valutare le prestazioni del modello manualmente tramite valutazione umana. Questo è dove una persona valuta le completazioni LLM in base a un insieme di linee guida, la verità fondamentale o entrambe. Sebbene questo possa richiedere tempo, può aiutare a favorire valutazioni di modelli flessibili e ad alta fedeltà.
In alternativa, si può adottare un approccio più quantitativo e utilizzare metriche NLP come Perplessità, BLEU o punteggi ROGUE. Sebbene ciascuno di questi punteggi sia formulato in modo diverso, quantificano la similarità tra il testo generato dal modello e il testo (corretto) nel dataset di validazione. Questo è meno costoso della valutazione umana manuale, ma potrebbe comportare una minore fedeltà di valutazione poiché queste metriche si basano sulle proprietà statistiche dei testi generati/verità fondamentale e non necessariamente sui loro significati semantici.
Infine, un approccio che potrebbe cogliere il meglio di entrambi i mondi è utilizzare un LLM ausiliario sintonizzato per confrontare le generazioni del modello con la verità fondamentale. Una versione di ciò è dimostrata da GPT-judge, un modello sintonizzato per classificare le risposte al dataset TruthfulQA come vere o false [30]. Tuttavia, c’è sempre il rischio con questo approccio poiché nessun modello può essere considerato affidabile al 100% in tutte le situazioni.
Cosa succede dopo?
Anche se abbiamo appena grattato la superficie dello sviluppo di un grande modello di linguaggio (LLM) da zero, spero che questa sia stata una guida utile. Per approfondire gli aspetti menzionati qui, consulta i riferimenti citati di seguito.
Sia che tu prenda un modello di base già pronto o lo costruisca da solo, probabilmente non sarà molto utile. I modelli di base (come suggerisce il nome) sono tipicamente un punto di partenza per una soluzione di intelligenza artificiale a un problema anziché una soluzione finale. Alcune applicazioni richiedono solo l’uso del modello di base tramite prompt intelligenti (cioè ingegneria del prompt), mentre altre richiedono l’addestramento del modello per un insieme limitato di compiti. Questi approcci sono discussi più in dettaglio (con codice di esempio) nei due articoli precedenti di questa serie.
👉 Altro sui LLM: Introduzione | OpenAI API | Hugging Face Transformers | Ingegneria del Prompt | Addestramento fine-tuning
Addestramento fine-tuning dei grandi modelli di linguaggio (LLM)
Una panoramica concettuale con esempi di codice Python
towardsdatascience.com
Risorse
Contatti: Il mio sito web | Prenota una chiamata | Chiedimi qualunque cosa
Social: YouTube 🎥 | LinkedIn | Twitter
Supporto: Offrimi un caffè ☕️
Gli imprenditori dei dati
Una comunità per imprenditori nel campo dei dati. 👉 Unisciti al Discord!
VoAGI.com
[1] BloombergGPT
[2] Llama 2 Paper
[3] Costi energetici LLM
[4] arXiv:2005.14165 [cs.CL]
[5] Falcon 180b Blog
[6] arXiv:2101.00027 [cs.CL]
[7] Alpaca Repo
[8] arXiv:2303.18223 [cs.CL]
[9] arXiv:2112.11446 [cs.CL]
[10] arXiv:1508.07909 [cs.CL]
[11] SentencePience Repo
[12] Documentazione Tokenizers
[13] arXiv:1706.03762 [cs.CL]
[14] Lezione di Andrej Karpathy
[15] Corso di NLP di Hugging Face
[16] arXiv:1810.04805 [cs.CL]
[17] arXiv:1910.13461 [cs.CL]
[18] arXiv:1603.05027 [cs.CV]
[19] arXiv:1607.06450 [stat.ML]
[20] arXiv:1803.02155 [cs.CL]
[21] arXiv:2203.15556 [cs.CL]
[22] Allenato con la precisione mista – Documentazione Nvidia
[23] Documentazione DeepSpeed
[24] https://paperswithcode.com/method/weight-decay
[25] https://towardsdatascience.com/what-is-gradient-clipping-b8e815cdfb48
[26] arXiv:2001.08361 [cs.LG]
[27] arXiv:1803.05457 [cs.AI]
[28] arXiv:1905.07830 [cs.CL]
[29] arXiv:2009.03300 [cs.CY]
[30] arXiv:2109.07958 [cs.CL]
[31] https://huggingface.co/blog/evaluating-mmlu-leaderboard