Come United Airlines ha costruito un efficiente flusso di lavoro di apprendimento attivo per il riconoscimento ottico dei caratteri a costo ridotto
United Airlines ha creato un flusso di lavoro di apprendimento attivo efficiente e a basso costo per il riconoscimento ottico dei caratteri.
In questo post, discutiamo di come United Airlines, in collaborazione con il Laboratorio delle Soluzioni di Apprendimento Automatico di Amazon, abbia costruito un framework di apprendimento attivo su AWS per automatizzare l’elaborazione dei documenti dei passeggeri.
“Al fine di offrire la migliore esperienza di volo ai nostri passeggeri e rendere il nostro processo aziendale interno il più efficiente possibile, abbiamo sviluppato una pipeline di elaborazione dei documenti basata sull’apprendimento automatico automatizzato in AWS. Per alimentare queste applicazioni, così come quelle che utilizzano altre modalità di dati come la visione artificiale, abbiamo bisogno di un flusso di lavoro robusto ed efficiente per annotare rapidamente i dati, addestrare e valutare i modelli e iterare velocemente. Nel corso di un paio di mesi, United si è associata ai Laboratori delle Soluzioni di Apprendimento Automatico di Amazon per progettare e sviluppare un flusso di lavoro attivo riutilizzabile e indipendente dal caso d’uso utilizzando AWS CDK. Questo flusso di lavoro sarà fondamentale per le nostre applicazioni di apprendimento automatico basate su dati non strutturati poiché ci consentirà di ridurre al minimo lo sforzo di etichettatura umana, fornire rapidamente prestazioni solide del modello e adattarsi alle variazioni dei dati.”
– Jon Nelson, Senior Manager di Data Science e Machine Learning presso United Airlines.
Problema
Il team di Tecnologia Digitale di United è composto da individui globalmente diversi che lavorano insieme con tecnologie all’avanguardia per ottenere risultati aziendali e mantenere elevati i livelli di soddisfazione dei clienti. Volevano sfruttare tecniche di apprendimento automatico (ML) come la visione artificiale (CV) e l’elaborazione del linguaggio naturale (NLP) per automatizzare le pipeline di elaborazione dei documenti. Come parte di questa strategia, hanno sviluppato un modello interno di analisi del passaporto per verificare le identità dei passeggeri. Il processo si basa su annotazioni manuali per addestrare i modelli di apprendimento automatico, che sono molto costose.
- Incasso ‘PAYDAY 3’ in streaming su GeForce NOW
- Il CEO di NVIDIA, Jensen Huang, sarà il protagonista del Summit sull’Intelligenza Artificiale a Tel Aviv
- Nell’Omniverso il rilascio dell’Alpha di Blender 4.0 apre la strada a una nuova era di arte OpenUSD
United voleva creare un framework di ML flessibile, resiliente ed efficiente dal punto di vista dei costi per automatizzare la verifica delle informazioni del passaporto, convalidare l’identità dei passeggeri e rilevare possibili documenti fraudolenti. Hanno coinvolto il ML Solutions Lab per aiutare a raggiungere questo obiettivo, il che consente a United di continuare a fornire un servizio di classe mondiale di fronte alla crescita futura dei passeggeri.
Panoramica della soluzione
Il nostro team congiunto ha progettato e sviluppato un framework di apprendimento attivo basato su AWS Cloud Development Kit (AWS CDK), che configura e fornisce in modo programmato tutti i servizi AWS necessari. Il framework utilizza Amazon SageMaker per elaborare i dati non etichettati, crea etichette soft, avvia lavori di etichettatura manuale con Amazon SageMaker Ground Truth e addestra un modello ML arbitrario con il dataset risultante. Abbiamo utilizzato Amazon Textract per automatizzare l’estrazione delle informazioni da campi specifici del documento come nome e numero di passaporto. A grandi linee, l’approccio può essere descritto con il seguente diagramma.
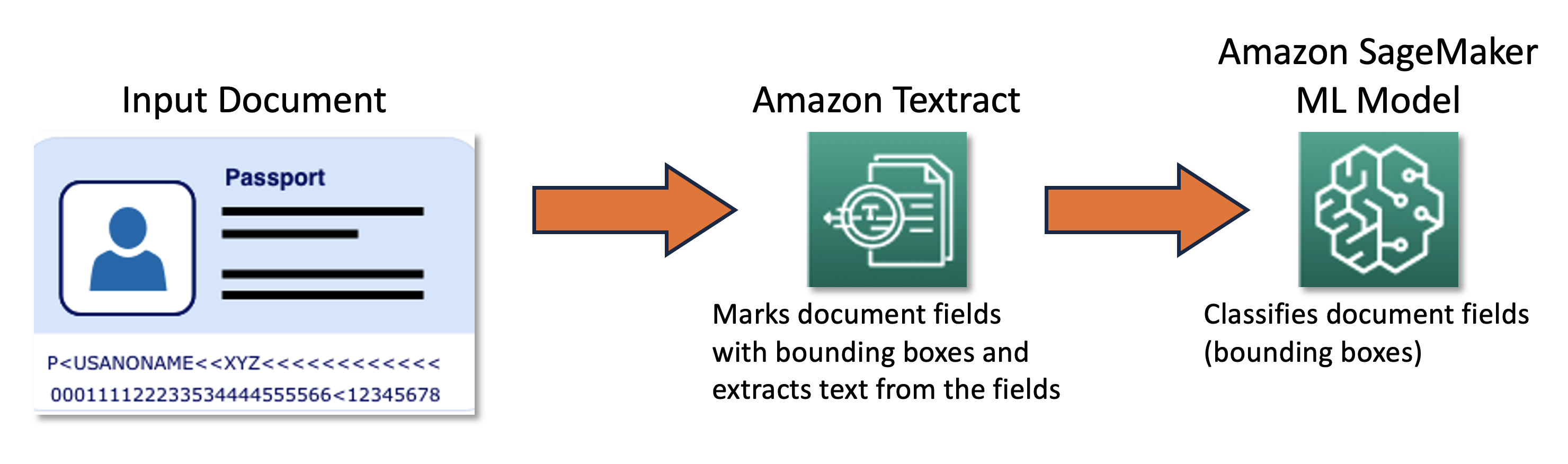
Dati
Il dataset principale per questo problema è composto da decine di migliaia di immagini di passaporti della pagina principale da cui devono essere estratte informazioni personali (nome, data di nascita, numero di passaporto, ecc.). La dimensione dell’immagine, il layout e la struttura variano a seconda del paese che emette il documento. Normalizziamo queste immagini in un insieme di miniature uniformi, che costituiscono l’input funzionale per la pipeline di apprendimento attivo (etichettatura automatica e inferenza).
Il secondo dataset contiene file di manifesto formattati in formato JSON line che collegano immagini di passaporti grezzi, immagini di miniature e informazioni sull’etichetta come etichette soft e posizioni dei bounding box. I file di manifesto fungono da set di metadati che memorizzano i risultati dei vari servizi AWS in un formato unificato e separano la pipeline di apprendimento attivo dai servizi downstream utilizzati da United. Il seguente diagramma illustra questa architettura.
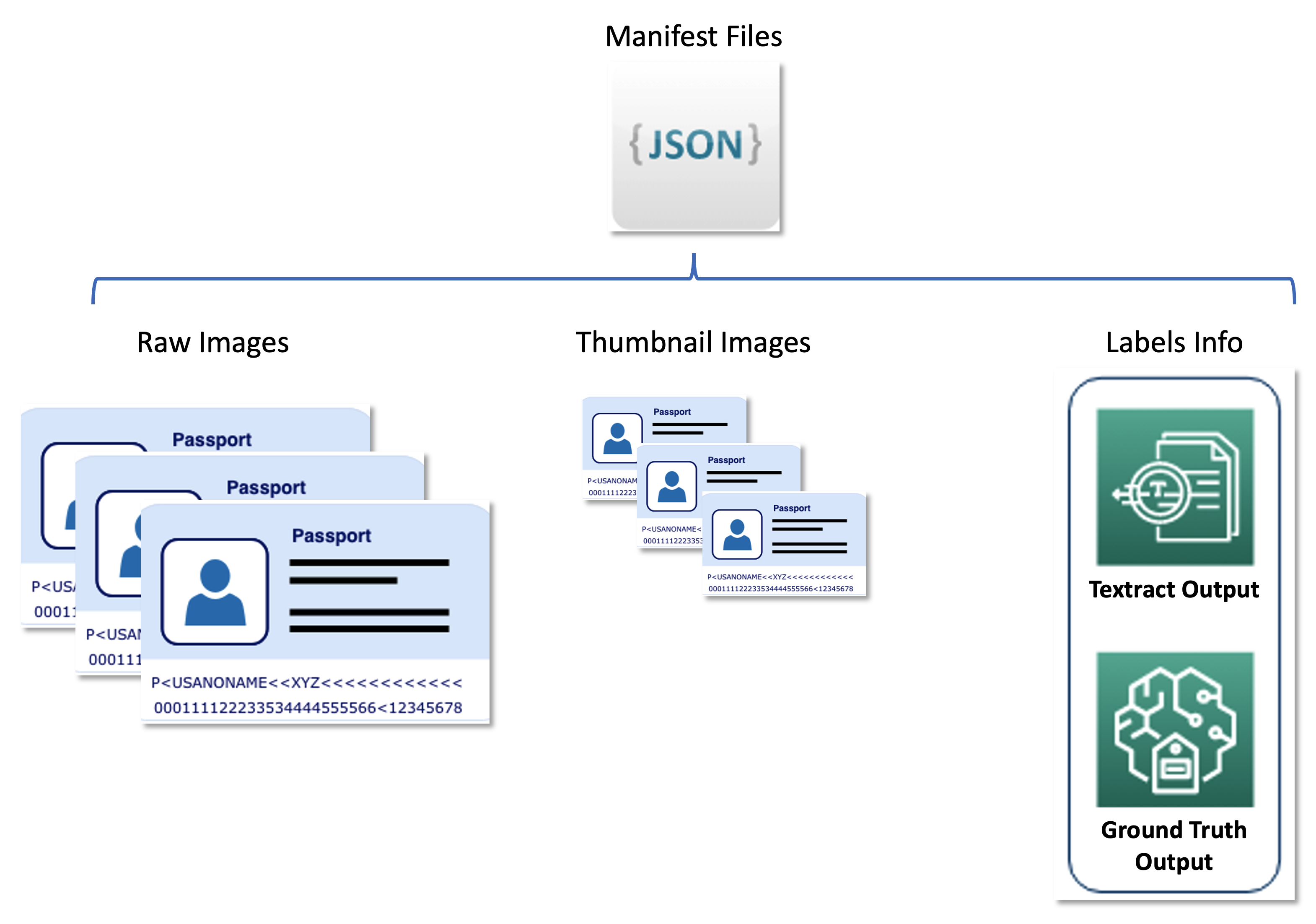
Il seguente codice è un esempio di file di manifesto:
{
"raw-ref": "s3://bucket/passport-0.jpg",
"textract-ref": "s3://bucket/textract/passport-0.jpg",
"source-ref": "s3://bucket/clean-images/passport-0.jpg",
"page-num": 1,
"label": {
"image_size": [...],
"annotations": [
{
"class_id": 0,
"top": 1856,
"left": 1476,
"height": 67,
"width": 329
},
{"class_id": 1 ...},
{"class_id": 2 ...},
{"class_id": 3 ...},
{"class_id": 4 ...},
{"class_id": 5 ...},
{"class_id": 6 ...},
{"class_id": 7 ...},
{"class_id": 8 ...},
{"class_id": 9 ...},
{"class_id": 10 ...},
]
},
"label-metadata": {
"objects": [...],
"class-map ": {"0": "Numero del passaporto" ...},
"type": "groundtruth/object-detection",
"human-annotated": "yes",
"creation-date": "2022-09-19T00:58:55.729305",
"job-name": "labeling-job/passports-20220918-195035"
}
}Componenti della soluzione
La soluzione include due componenti principali:
- Un framework di ML, responsabile dell’addestramento del modello
- Un pipeline di auto-etichettatura, responsabile di migliorare l’accuratezza del modello addestrato in modo efficiente in termini di costi
Il framework di ML è responsabile dell’addestramento del modello di ML e del suo rilascio come endpoint SageMaker. La pipeline di auto-etichettatura si concentra sull’automazione dei lavori di SageMaker Ground Truth e sul campionamento di immagini per l’etichettatura attraverso tali lavori.
I due componenti sono disaccoppiati l’uno dall’altro e interagiscono solo attraverso l’insieme di immagini etichettate prodotte dalla pipeline di auto-etichettatura. Ciò significa che la pipeline di etichettatura crea etichette che vengono successivamente utilizzate dal framework di ML per addestrare il modello di ML.
Framework di ML
Il team di ML Solutions Lab ha costruito il framework di ML utilizzando l’implementazione di Hugging Face del modello LayoutLMV2 all’avanguardia (LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding, Yang Xu, et al.). L’addestramento si basava sugli output di Amazon Textract, che fungevano da preprocessore e producevano bounding box attorno al testo di interesse. Il framework utilizza l’addestramento distribuito e viene eseguito su un contenitore Docker personalizzato basato sull’immagine pre-costruita di SageMaker Hugging Face con dipendenze aggiuntive (dipendenze mancanti nell’immagine Docker pre-costruita di SageMaker ma richieste per Hugging Face LayoutLMv2).
Il modello di ML è stato addestrato per classificare i campi di documento nelle seguenti 11 classi:
"0": "Numero del passaporto",
"1": "Cognome",
"2": "Nomi",
"3": "Nazionalità",
"4": "Data di nascita",
"5": "Luogo di nascita",
"6": "Sesso",
"7": "Data di rilascio",
"8": "Autorità",
"9": "Data di scadenza",
"10": "Note"
I parametri dell'immagine pre-costruita sono:
{
"framework": "huggingface",
"py_version": "py38",
"version": "4.17",
"base_framework_version": "pytorch1.10"
}Il Dockerfile dell’immagine personalizzata è il seguente: (BASE_IMAGE si riferisce all’immagine di base precedente):
ARG BASE_IMAGE
FROM ${BASE_IMAGE}
RUN pip install "amazon-textract-response-parser>=0.1,<0.2" "Pillow>=8,<9" \
&& pip install git+https://github.com/facebookresearch/detectron2.git
RUN pip install pytesseract "datasets==2.2.1" "torchvision>=0.11.3,<0.12"
RUN pip install setuptools==59.5.0La pipeline di addestramento può essere riassunta nel seguente diagramma.
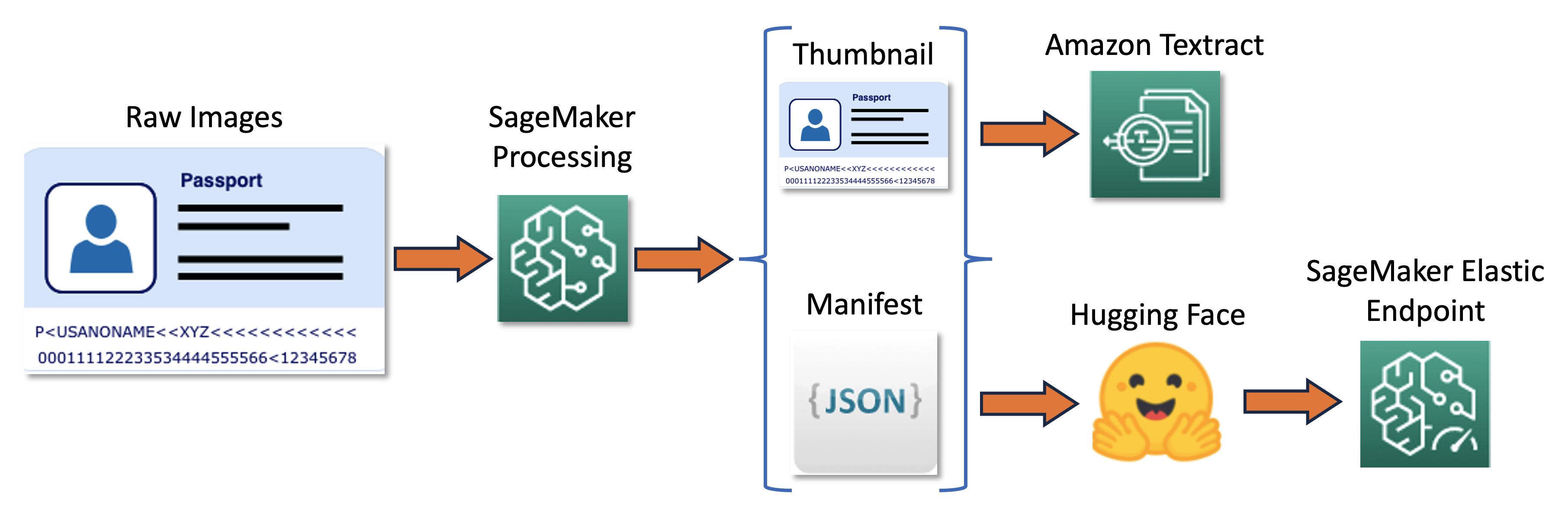
Prima, ridimensioniamo e normalizziamo un batch di immagini grezze in miniature. Allo stesso tempo, viene creato un file manifesto JSON con una riga per immagine con informazioni sulle immagini grezze e in miniatura del batch. Successivamente, utilizziamo Amazon Textract per estrarre le bounding box del testo nelle immagini in miniatura. Tutte le informazioni prodotte da Amazon Textract vengono registrate nello stesso file manifesto. Infine, utilizziamo le immagini in miniatura e i dati del manifesto per addestrare un modello, che viene successivamente distribuito come endpoint SageMaker.
Pipeline di auto-etichettatura
Abbiamo sviluppato una pipeline di auto-etichettatura progettata per svolgere le seguenti funzioni:
- Eseguire l’inferenza periodica su un dataset non etichettato.
- Filtrare i risultati in base a una specifica strategia di campionamento di incertezza.
- Avviare un lavoro di SageMaker Ground Truth per etichettare le immagini campionate utilizzando una forza lavoro umana.
- Aggiungere le immagini appena etichettate al dataset di addestramento per il successivo raffinamento del modello.
La strategia di campionamento di incertezza riduce il numero di immagini inviate al lavoro di etichettatura umana selezionando le immagini che probabilmente contribuiranno di più al miglioramento dell’accuratezza del modello. Poiché l’etichettatura umana è un compito costoso, tale campionamento è una tecnica importante per ridurre i costi. Supportiamo quattro strategie di campionamento, che possono essere selezionate come parametro memorizzato in Parameter Store, una capacità di AWS Systems Manager:
- Confidenza minima
- Confidenza marginale
- Rapporto di confidenza
- Entropia
L’intero flusso di lavoro di auto-etichettatura è stato implementato con AWS Step Functions, che orchestra il lavoro di elaborazione (chiamato endpoint elastico per l’inferenza batch), il campionamento di incertezza e SageMaker Ground Truth. Il seguente diagramma illustra il flusso di lavoro di Step Functions.

Efficienza dei costi
Il fattore principale che influenza i costi dell’etichettatura è l’annotazione manuale. Prima di implementare questa soluzione, il team di United doveva utilizzare un approccio basato su regole, che richiedeva costose annotazioni manuali dei dati e tecniche OCR di analisi dei dati di terze parti. Con la nostra soluzione, United ha ridotto il carico di lavoro dell’etichettatura manuale, etichettando manualmente solo le immagini che avrebbero comportato i miglioramenti più significativi del modello. Poiché il framework è agnostico rispetto al modello, può essere utilizzato in altri scenari simili, estendendo il suo valore oltre le immagini dei passaporti a un insieme molto più ampio di documenti.
Abbiamo effettuato un’analisi dei costi basata sulle seguenti ipotesi:
- Ogni batch contiene 1.000 immagini
- La formazione viene eseguita utilizzando un’istanza mlg4dn.16xlarge
- L’infrazione viene eseguita su un’istanza mlg4dn.xlarge
- La formazione viene effettuata dopo ogni batch con il 10% delle etichette annotate
- Ogni round di formazione comporta i seguenti miglioramenti di precisione:
- 50% dopo il primo batch
- 25% dopo il secondo batch
- 10% dopo il terzo batch
La nostra analisi mostra che i costi di formazione rimangono costanti ed elevati senza l’apprendimento attivo. L’incorporazione dell’apprendimento attivo comporta una riduzione dei costi in modo esponenziale con ogni nuovo batch di dati.
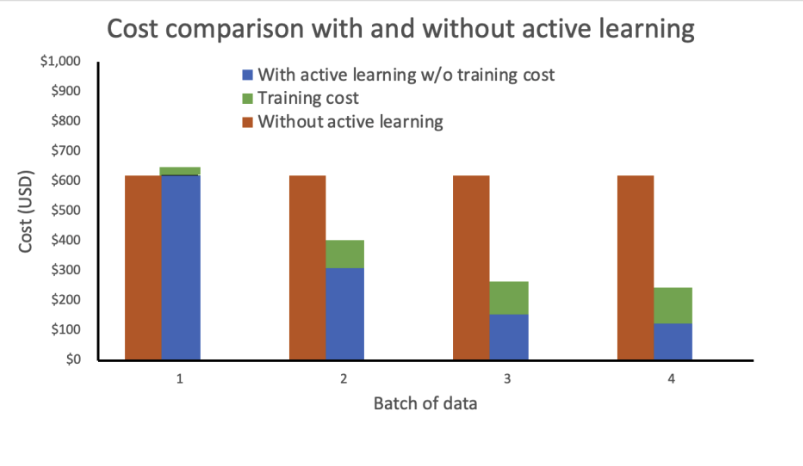
Abbiamo ulteriormente ridotto i costi implementando il punto di ingresso dell’infrazione come un punto di ingresso elastico mediante l’aggiunta di una politica di ridimensionamento automatico. Le risorse del punto di ingresso possono scalare verso l’alto o verso il basso tra zero e un numero massimo di istanze configurato.
Architettura definitiva della soluzione
Il nostro obiettivo era aiutare il team di United a soddisfare i loro requisiti funzionali mentre costruivamo un’applicazione cloud scalabile e flessibile. Il team del ML Solutions Lab ha sviluppato la soluzione completa pronta per la produzione con l’aiuto di AWS CDK, automatizzando la gestione e l’approvvigionamento di tutte le risorse e i servizi cloud. L’applicazione cloud finale è stata implementata come un’unica pila AWS CloudFormation con quattro stack nidificati, ognuno dei quali rappresenta un singolo componente funzionale.
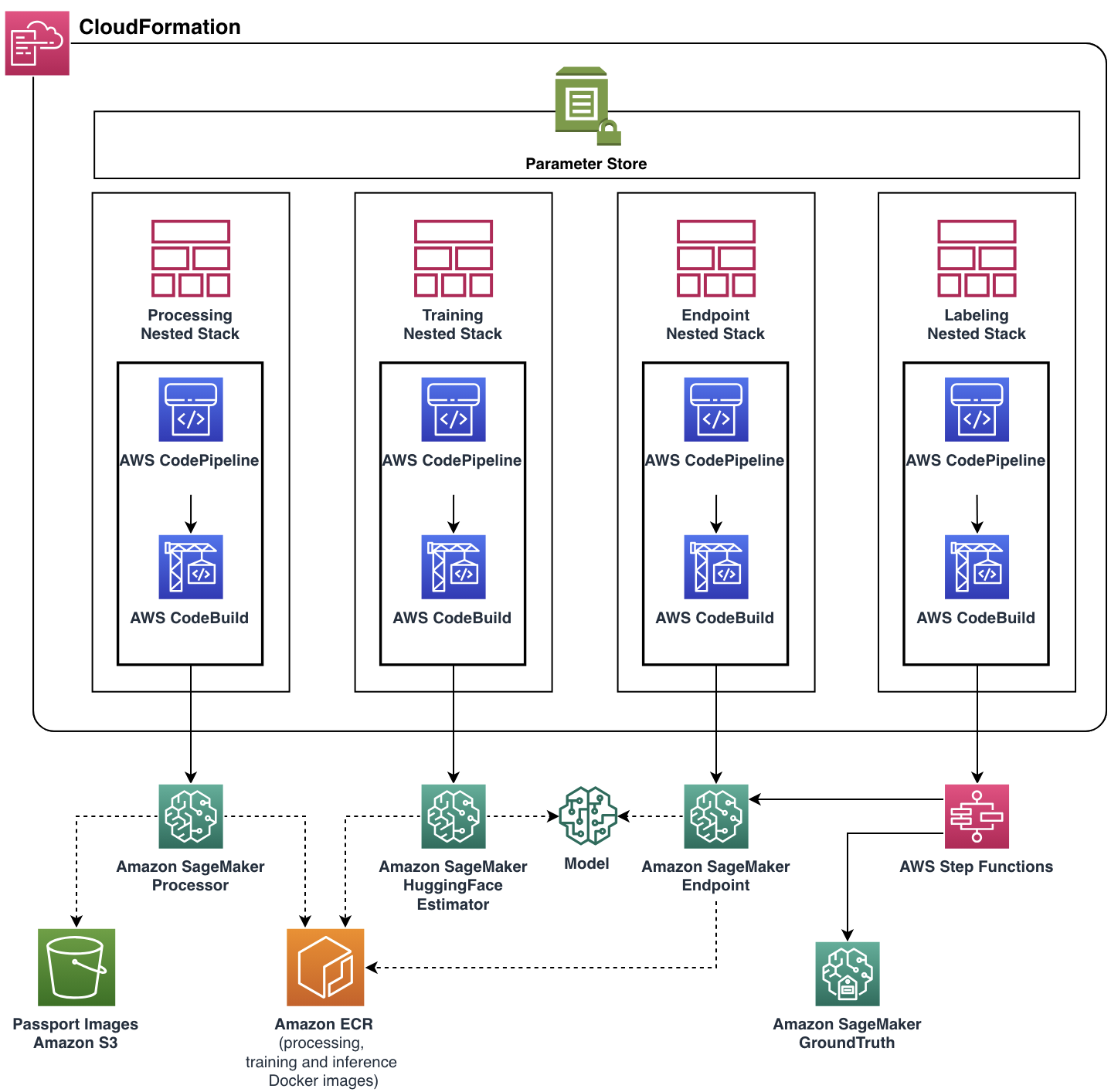
Quasi tutte le caratteristiche del pipeline, inclusi le immagini Docker, la politica di ridimensionamento automatico del punto di ingresso e altro ancora, sono state parametrizzate tramite Parameter Store. Con tale flessibilità, la stessa istanza del pipeline potrebbe essere eseguita con un’ampia gamma di impostazioni, aggiungendo la possibilità di sperimentare.
Conclusione
In questo post, abbiamo discusso come United Airlines, in collaborazione con il ML Solutions Lab, abbia costruito un framework di apprendimento attivo su AWS per automatizzare l’elaborazione dei documenti dei passeggeri. La soluzione ha avuto un grande impatto su due aspetti importanti degli obiettivi di automazione di United:
- Riutilizzabilità – Grazie al design modulare e all’implementazione agnostica del modello, United Airlines può riutilizzare questa soluzione su quasi ogni altro caso d’uso di etichettatura automatica di ML
- Riduzione dei costi ricorrenti – Combinando intelligentemente processi di etichettatura manuale ed etichettatura automatica, il team di United può ridurre i costi medi dell’etichettatura e sostituire costosi servizi di etichettatura di terze parti
Se sei interessato a implementare una soluzione simile o desideri saperne di più sul ML Solutions Lab, contatta il tuo account manager o visita il nostro sito web presso Amazon Machine Learning Solutions Lab.






