Estrazione del testo dai file PDF con Python una guida completa
Estrazione testo file PDF con Python guida completa
Un processo completo per estrarre informazioni testuali da tabelle, immagini e testo puro da un file PDF
Introduzione
Nell’era dei Large Language Models (LLM) e delle loro molteplici applicazioni, dalla semplice sintesi del testo alla traduzione fino alla previsione delle performance azionarie basate sul sentiment e sugli argomenti dei report finanziari, l’importanza dei dati testuali non è mai stata così grande.
Ci sono molti tipi di documenti che condividono questo tipo di informazioni non strutturate, dai articoli web e post di blog alle lettere scritte a mano e alle poesie. Tuttavia, una parte significativa di questi dati testuali è memorizzata e trasferita in formato PDF. In particolare, è stato riscontrato che ogni anno vengono aperti oltre 2 miliardi di PDF in Outlook, mentre ogni giorno vengono salvati in Google Drive ed inviati via email 73 milioni di nuovi file PDF (2).
Sviluppare, quindi, un modo più sistematico per elaborare questi documenti ed estrarre informazioni da essi ci darebbe la possibilità di avere un flusso automatizzato e di comprendere e utilizzare al meglio questo vasto volume di dati testuali. E per questa attività, naturalmente, il nostro migliore amico potrebbe essere solo Python.
Tuttavia, prima di iniziare il nostro processo, è necessario specificare i diversi tipi di PDF che si trovano in giro in questi giorni, e più specificamente, i tre più frequenti:
- AI per tutti Navigare nella nuova era dell’intelligenza democratizzata
- PaLM 2 di Google Rivoluzionare i modelli di linguaggio
- Due nuovi articoli analizzano in dettaglio l’universo delle proteine svelato dai 200 milioni di modelli di AlphaFold 2
- PDF generati in modo programmato: Questi PDF vengono creati su un computer utilizzando tecnologie come HTML, CSS e Javascript o un altro software come Adobe Acrobat. Questo tipo di file può contenere vari componenti, come immagini, testo e link, che sono tutti ricercabili e facili da modificare.
- Documenti scannerizzati tradizionali: Questi PDF vengono creati da VoAGI non elettronici tramite uno scanner o un’app mobile. Questi file non sono altro che una collezione di immagini memorizzate insieme in un file PDF. Detto questo, gli elementi presenti in queste immagini, come il testo o i link, non possono essere selezionati o cercati. In sostanza, il PDF funge da contenitore per queste immagini.
- Documenti scannerizzati con OCR: In questo caso, dopo la scansione del documento viene utilizzato un software di Optical Character Recognition (OCR) per identificare il testo all’interno di ciascuna immagine nel file, convertendolo in testo ricercabile e modificabile. Successivamente, il software aggiunge un livello con il testo effettivo all’immagine, in modo da poterlo selezionare come un componente separato durante la navigazione nel file (3).
Anche se oggi sempre più macchine hanno sistemi OCR installati che identificano il testo dai documenti scannerizzati, ci sono ancora documenti che contengono intere pagine in formato immagine. Probabilmente hai visto che quando leggi un ottimo articolo e provi a selezionare una frase, selezioni invece l’intera pagina. Questo può essere il risultato di una limitazione nella specifica macchina OCR o della sua completa assenza. In modo da non lasciare queste informazioni non rilevate in questo articolo, ho cercato di creare un processo che tenga conto anche di questi casi e che sfrutti al massimo i nostri preziosi e ricchi di informazioni PDF.
L’Approccio Teorico
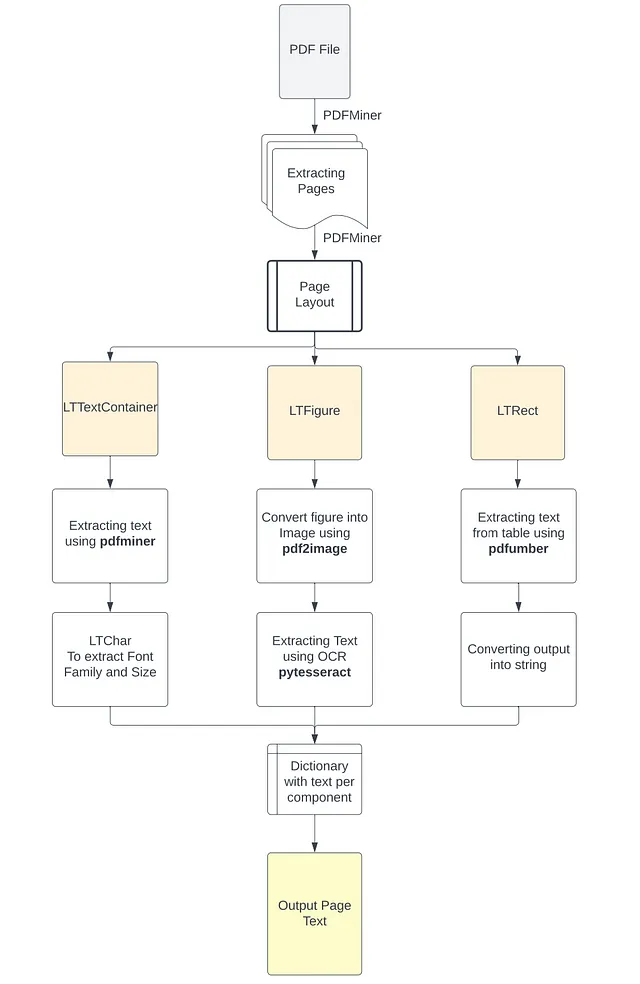
Avendo in mente tutti questi diversi tipi di file PDF e i vari elementi che li compongono, è importante effettuare un’analisi iniziale del layout del PDF per identificare lo strumento appropriato per ogni componente. Più specificamente, basandoci sui risultati di questa analisi, applicheremo il metodo appropriato per estrarre il testo dal PDF, che sia testo renderizzato in un blocco di corpus con i relativi metadati, testo all’interno di immagini o testo strutturato all’interno di tabelle. Nel documento scannerizzato senza OCR, l’approccio che identifica ed estrae il testo dalle immagini svolgerà tutto il lavoro pesante. L’output di questo processo sarà un dizionario Python contenente le informazioni estratte per ogni pagina del file PDF. Ogni chiave in questo dizionario rappresenterà il numero di pagina del documento e il suo valore corrispondente sarà una lista con le seguenti 5 liste nidificate contenenti:
- Il testo estratto per ogni blocco di testo del corpus
- Il formato del testo in ogni blocco di testo in termini di famiglia di caratteri e dimensione
- Il testo estratto dalle immagini nella pagina
- Il testo estratto dalle tabelle in un formato strutturato
- Il contenuto testuale completo della pagina

In questo modo possiamo ottenere una separazione più logica del testo estratto per componente di origine e talvolta ci può aiutare a recuperare più facilmente le informazioni che di solito compaiono nella componente specifica (ad esempio, il nome dell’azienda in un’immagine del logo). Inoltre, i metadati estratti dal testo, come il tipo di font e la dimensione, possono essere utilizzati per identificare facilmente gli intestazioni di testo o il testo evidenziato di maggiore importanza che ci aiuteranno a separare o post-elaborare ulteriormente il testo in più parti diverse. Infine, mantenendo le informazioni strutturate della tabella in un modo che un LLM può comprendere, migliorerà significativamente la qualità delle inferenze fatte sulle relazioni all’interno dei dati estratti. Poi questi risultati possono essere composti come un output con tutte le informazioni testuali che sono apparse su ogni pagina.
Puoi vedere un diagramma di flusso di questo approccio nelle immagini qui sotto.
Installazione di tutte le librerie necessarie
Prima di iniziare questo progetto, dovremmo installare le librerie necessarie. Assumiamo che tu abbia installato Python 3.10 o versioni successive sul tuo computer. In caso contrario, puoi installarlo da qui. Quindi procediamo con l’installazione delle seguenti librerie:
PyPDF2: Per leggere il file PDF dal percorso del repository.
pip install PyPDF2Pdfminer: Per eseguire l’analisi del layout ed estrarre testo e formattazione dal PDF. (la versione .six della libreria è quella che supporta Python 3)
pip install pdfminer.sixPdfplumber: Per identificare le tabelle in una pagina PDF ed estrarre le informazioni da esse.
pip install pdfplumberPdf2image: Per convertire l’immagine PDF ritagliata in un’immagine PNG.
pip install pdf2imagePIL: Per leggere l’immagine PNG.
pip install PillowPytesseract: Per estrarre il testo dalle immagini utilizzando la tecnologia OCR
Questo è un po’ più complicato da installare perché prima devi installare Google Tesseract OCR, che è una macchina OCR basata su un modello LSTM per identificare il riconoscimento delle linee e i modelli dei caratteri.
Puoi installarlo sul tuo computer se sei un utente Mac tramite Brew dal tuo terminale, e sei pronto per andare.
brew install tesseractPer gli utenti Windows, puoi seguire questi passaggi per installare il collegamento. Quindi, quando scarichi e installi il software, devi aggiungere i loro percorsi eseguibili alle variabili di ambiente sul tuo computer. In alternativa, puoi eseguire i seguenti comandi per includere direttamente i loro percorsi nello script Python utilizzando il codice seguente:
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'Poi puoi installare la libreria Python
pip install pytesseractInfine, importeremo tutte le librerie all’inizio del nostro script.
# Per leggere il PDFimport PyPDF2# Per analizzare il layout del PDF ed estrarre il testofrom pdfminer.high_level import extract_pages, extract_textfrom pdfminer.layout import LTTextContainer, LTChar, LTRect, LTFigure# Per estrarre il testo dalle tabelle in PDFimport pdfplumber# Per estrarre le immagini dai PDFdalla libreria PIL import Imagefrom pdf2image import convert_from_path# Per eseguire OCR per estrarre il testo dalle immagini import pytesseract # Per rimuovere i file creati in piùimport osOra siamo pronti. Passiamo alla parte divertente.
Analisi del layout del documento con Python

Per l’analisi preliminare, abbiamo utilizzato la libreria Python PDFMiner per separare il testo da un oggetto documento in più oggetti pagina e quindi scomporre ed esaminare il layout di ogni pagina. I file PDF mancano intrinsecamente di informazioni strutturate, come paragrafi, frasi o parole come viste dall’occhio umano. Invece, comprendono solo i singoli caratteri del testo insieme alla loro posizione sulla pagina. In questo modo, PDFMiner cerca di ricostruire il contenuto della pagina nei singoli caratteri insieme alla loro posizione nel file. Quindi, confrontando le distanze di quei caratteri dagli altri, compone le parole, le frasi, le linee e i paragrafi di testo appropriati. (4) Per raggiungere questo obiettivo, la libreria:
Separa le singole pagine dal file PDF utilizzando la funzione di alto livello extract_pages() e le converte in oggetti LTPage.
Quindi, per ogni oggetto LTPage, itera su ogni elemento dall’alto verso il basso e cerca di identificare il componente appropriato come:
- LTFigure che rappresenta l’area del PDF che può presentare figure o immagini incorporate come un altro documento PDF nella pagina.
- LTTextContainer che rappresenta un gruppo di righe di testo in un’area rettangolare, viene quindi analizzato ulteriormente in una lista di oggetti LTTextLine. Ognuno di essi rappresenta una lista di oggetti LTChar, che memorizzano i singoli caratteri di testo insieme ai loro metadati. (5)
- LTRect rappresenta un rettangolo bidimensionale che può essere utilizzato per incorniciare immagini e figure o creare tabelle in un oggetto LTPage.
Pertanto, in base a questa ricostruzione della pagina e alla classificazione dei suoi elementi, sia in LTFigure, che contiene le immagini o le figure della pagina, in LTTextContainer, che rappresenta le informazioni testuali della pagina, o in LTRect, che sarà un forte indicazione della presenza di una tabella, possiamo applicare la funzione appropriata per estrarre meglio le informazioni.
per pagenum, page in enumerate(extract_pages(pdf_path)): # Itera sugli elementi che compongono una pagina for element in page: # Verifica se l'elemento è un elemento di testo if isinstance(element, LTTextContainer): # Funzione per estrarre il testo dal blocco di testo pass # Funzione per estrarre il formato del testo pass # Verifica gli elementi per le immagini if isinstance(element, LTFigure): # Funzione per convertire PDF in immagine pass # Funzione per estrarre il testo con OCR pass # Verifica gli elementi per le tabelle if isinstance(element, LTRect): # Funzione per estrarre la tabella pass # Funzione per convertire il contenuto della tabella in una stringa passOra che comprendiamo la parte di analisi del processo, creiamo le funzioni necessarie per estrarre il testo da ogni componente.
Definisci la funzione per estrarre il testo dal PDF
Da qui in poi, l’estrazione del testo da un contenitore di testo è davvero semplice.
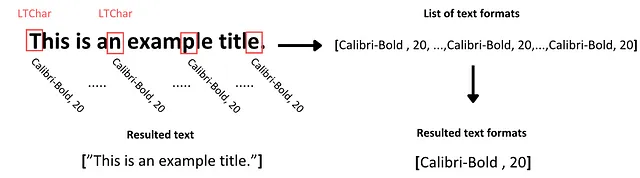
# Crea una funzione per estrarre il testodef text_extraction(element): # Estrarre il testo dall'elemento di testo in linea line_text = element.get_text() # Trova i formati del testo # Inizializza la lista con tutti i formati che sono apparsi nella riga di testo line_formats = [] for text_line in element: if isinstance(text_line, LTTextContainer): # Itera su ogni carattere nella riga di testo for character in text_line: if isinstance(character, LTChar): # Aggiungi il nome del font del carattere alla lista line_formats.append(character.fontname) # Aggiungi la dimensione del font del carattere alla lista line_formats.append(character.size) # Trova i formati del testo unici e i nomi nella riga format_per_line = list(set(line_formats)) # Restituisci una tupla con il testo in ogni riga insieme al suo formato return (line_text, format_per_line)Quindi, per estrarre il testo da un contenitore di testo, utilizziamo semplicemente il metodo get_text() dell’elemento LTTextContainer. Questo metodo recupera tutti i caratteri che compongono le parole all’interno della specifica casella di testo, memorizzando l’output in una lista di dati di testo. Ogni elemento in questa lista rappresenta l’informazione testuale grezza contenuta nel contenitore.
Ora, per identificare il formato di questo testo, iteriamo sull’oggetto LTTextContainer per accedere singolarmente a ciascuna riga di testo di questo corpus. In ogni iterazione, viene creato un nuovo oggetto LTTextLine, che rappresenta una riga di testo in questo chunk di corpus. Quindi verifichiamo se l’elemento di riga nidificato contiene testo. In caso affermativo, accediamo a ciascun elemento carattere individuale come LTChar, che contiene tutti i metadati per quel carattere. Da questi metadati, estraiamo due tipi di formati e li memorizziamo in una lista separata, posizionata corrispondentemente al testo esaminato:
- La famiglia di caratteri, inclusa l’informazione se il carattere è in formato grassetto o corsivo
- La dimensione del carattere
In generale, i caratteri all’interno di un determinato blocco di testo tendono ad avere una formattazione coerente a meno che alcuni non siano evidenziati in grassetto. Per facilitare ulteriori analisi, catturiamo i valori unici della formattazione del testo per tutti i caratteri all’interno del testo e li memorizziamo nella lista appropriata.
Definire la funzione per estrarre il testo dalle immagini
Credo che questa sia una parte più complicata.
Come gestire il testo nelle immagini trovate nei PDF?
Innanzitutto, dobbiamo stabilire qui che gli elementi di immagine memorizzati nei PDF non sono in un formato diverso dal file, come ad esempio JPEG o PNG. Per applicare il software OCR su di essi, è quindi necessario separarli dal file e convertirli in un formato di immagine.
# Crea una funzione per ritagliare gli elementi di immagine dai PDFdef crop_image(element, pageObj): # Ottieni le coordinate per ritagliare l'immagine dal PDF [image_left, image_top, image_right, image_bottom] = [element.x0,element.y0,element.x1,element.y1] # Ritaglia la pagina usando le coordinate (sinistra, basso, destra, alto) pageObj.mediabox.lower_left = (image_left, image_bottom) pageObj.mediabox.upper_right = (image_right, image_top) # Salva la pagina ritagliata in un nuovo PDF cropped_pdf_writer = PyPDF2.PdfWriter() cropped_pdf_writer.add_page(pageObj) # Salva il PDF ritagliato in un nuovo file with open('cropped_image.pdf', 'wb') as cropped_pdf_file: cropped_pdf_writer.write(cropped_pdf_file)# Crea una funzione per convertire il PDF in immaginidef convert_to_images(input_file,): images = convert_from_path(input_file) image = images[0] output_file = "PDF_image.png" image.save(output_file, "PNG")# Crea una funzione per leggere il testo dalle immaginidef image_to_text(image_path): # Leggi l'immagine img = Image.open(image_path) # Estrai il testo dall'immagine text = pytesseract.image_to_string(img) return textPer ottenere questo, seguiamo il seguente processo:
- Utilizziamo i metadati dell’oggetto LTFigure rilevato da PDFMiner per ritagliare la casella dell’immagine, utilizzando le sue coordinate nel layout della pagina. Poi la salviamo come un nuovo PDF nella nostra directory utilizzando la libreria PyPDF2.
- Poi utilizziamo la funzione convert_from_file() della libreria pdf2image per convertire tutti i file PDF nella directory in una lista di immagini, salvandole nel formato PNG.
- Infine, ora che abbiamo i nostri file di immagine, li leggiamo nel nostro script utilizzando il pacchetto Image del modulo PIL e implementiamo la funzione image_to_string() di pytesseract per estrarre il testo dalle immagini utilizzando il motore OCR tesseract.
Come risultato, questo processo restituisce il testo dalle immagini, che poi salviamo in una terza lista all’interno del dizionario di output. Questa lista contiene le informazioni testuali estratte dalle immagini nella pagina esaminata.
Definire la funzione per estrarre il testo dalle tabelle
In questa sezione, estrarremo un testo più logicamente strutturato dalle tabelle presenti in una pagina PDF. Questo è un compito leggermente più complesso rispetto all’estrazione del testo da un corpus perché dobbiamo tenere conto della granularità delle informazioni e delle relazioni formate tra i punti dati presentati in una tabella.
Anche se esistono diverse librerie utilizzate per estrarre dati tabellari dai PDF, con Tabula-py che è una delle più conosciute, abbiamo identificato alcune limitazioni nella loro funzionalità.
La più evidente, secondo noi, deriva dal modo in cui la libreria identifica le diverse righe della tabella utilizzando il carattere speciale di interruzione di riga \n nel testo della tabella. Questo funziona molto bene nella maggior parte dei casi, ma non riesce a catturare correttamente quando il testo in una cella è diviso in 2 o più righe, portando all’aggiunta di righe vuote inutili e alla perdita del contesto della cella estratta.
Puoi vedere l’esempio qui sotto quando abbiamo cercato di estrarre i dati da una tabella utilizzando tabula-py:
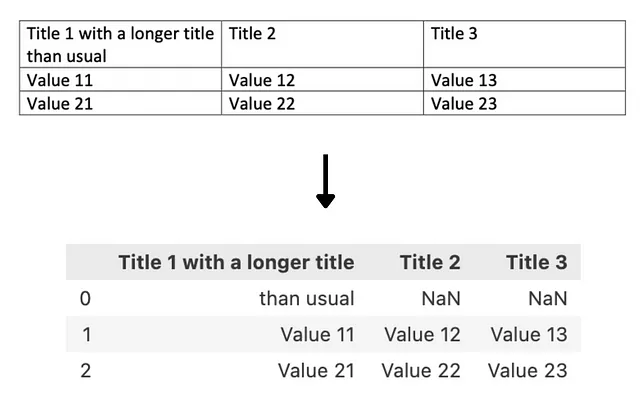
In seguito, le informazioni estratte vengono visualizzate in un Pandas DataFrame invece di una stringa. Nella maggior parte dei casi, questo può essere un formato desiderabile, ma nel caso dei trasformatori che tengono conto del testo, questi risultati devono essere trasformati prima di essere inseriti in un modello.
Per questo motivo, per affrontare questo compito abbiamo utilizzato la libreria pdfplumber per vari motivi. In primo luogo, è basata su pdfminer.six che abbiamo usato per la nostra analisi preliminare, il che significa che contiene oggetti simili. Inoltre, il suo approccio alla rilevazione delle tabelle si basa sugli elementi di linea insieme alle loro intersezioni che costruiscono la cella che contiene il testo e quindi la tabella stessa. In questo modo, dopo aver identificato una cella di una tabella, possiamo estrarre solo il contenuto all’interno della cella senza preoccuparci di quante righe devono essere visualizzate. Quindi, quando abbiamo i contenuti di una tabella, li formattiamo in una stringa simile a una tabella e li archiviamo nella lista appropriata.
# Estrazione delle tabelle dal pagedef extract_table(pdf_path, page_num, table_num): # Apri il file pdf pdf = pdfplumber.open(pdf_path) # Trova la pagina esaminata table_page = pdf.pages[page_num] # Estrai la tabella appropriata table = table_page.extract_tables()[table_num] return table# Converti la tabella nel formato appropriatodef table_converter(table): table_string = '' # Itera attraverso ogni riga della tabella for row_num in range(len(table)): row = table[row_num] # Rimuovi il separatore di riga dai testi incapsulati cleaned_row = [item.replace('\n', ' ') if item is not None and '\n' in item else 'None' if item is None else item for item in row] # Converti la tabella in una stringa table_string+=('|'+'|'.join(cleaned_row)+'|'+'\n') # Rimuovi l'ultimo separatore di riga table_string = table_string[:-1] return table_stringPer ottenere ciò, abbiamo creato due funzioni, extract_table() per estrarre i contenuti della tabella in una lista di liste e table_converter() per unire i contenuti di quelle liste in una stringa simile a una tabella.
Nella funzione extract_table():
- Apriamo il file PDF.
- Navighiamo alla pagina esaminata del file PDF.
- Dalla lista di tabelle trovate nella pagina tramite pdfplumber, selezioniamo quella desiderata.
- Estraiamo il contenuto della tabella e lo visualizziamo in una lista di liste nidificate che rappresentano ciascuna riga della tabella.
Nella funzione table_converter():
- Iteriamo in ogni lista nidificata e puliamo il suo contenuto da eventuali interruzioni di linea indesiderate derivanti da testi incapsulati.
- Uniamo ciascun elemento della riga separandoli usando il simbolo | per creare la struttura di una cella della tabella.
- Infine, aggiungiamo un’interruzione di linea alla fine per passare alla riga successiva.
Ciò produrrà una stringa di testo che presenterà il contenuto della tabella senza perdere la granularità dei dati presentati in essa.
Aggiungendo tutto insieme
Ora che abbiamo tutti i componenti del codice pronti, aggiungiamoli tutti a un codice completamente funzionante. Puoi copiare il codice da qui o puoi trovarlo insieme all’esempio di PDF nel mio repository Github qui.
# Trova il percorso del PDFpdf_path = 'OFFER 3.pdf'# crea un oggetto file PDFpdfFileObj = open(pdf_path, 'rb')# crea un oggetto lettore PDFpdfReaded = PyPDF2.PdfReader(pdfFileObj)# Crea il dizionario per estrarre il testo da ogni immaginetext_per_page = {}# Estraiamo le pagine dal PDFfor pagenum, page in enumerate(extract_pages(pdf_path)): # Inizializza le variabili necessarie per l'estrazione del testo dalla pagina pageObj = pdfReaded.pages[pagenum] page_text = [] line_format = [] text_from_images = [] text_from_tables = [] page_content = [] # Inizializza il numero delle tabelle esaminate table_num = 0 first_element= True table_extraction_flag= False # Apri il file pdf pdf = pdfplumber.open(pdf_path) # Trova la pagina esaminata page_tables = pdf.pages[pagenum] # Trova il numero di tabelle nella pagina tables = page_tables.find_tables() # Trova tutti gli elementi page_elements = [(element.y1, element) for element in page._objs] # Ordina tutti gli elementi come appaiono nella pagina page_elements.sort(key=lambda a: a[0], reverse=True) # Trova gli elementi che compongono una pagina for i,component in enumerate(page_elements): # Estrai la posizione del lato superiore dell'elemento nel PDF pos= component[0] # Estrai l'elemento del layout della pagina element = component[1] # Verifica se l'elemento è un elemento di testo if isinstance(element, LTTextContainer): # Verifica se il testo è apparso in una tabella if table_extraction_flag == False: # Utilizza la funzione per estrarre il testo e il formato per ogni elemento di testo (line_text, format_per_line) = text_extraction(element) # Aggiungi il testo di ogni riga al testo della pagina page_text.append(line_text) # Aggiungi il formato per ogni riga contenente testo line_format.append(format_per_line) page_content.append(line_text) else: # Ometti il testo che appare in una tabella pass # Verifica gli elementi per le immagini if isinstance(element, LTFigure): # Ritaglia l'immagine dal PDF crop_image(element, pageObj) # Converti il PDF ritagliato in un'immagine convert_to_images('cropped_image.pdf') # Estrai il testo dall'immagine image_text = image_to_text('PDF_image.png') text_from_images.append(image_text) page_content.append(image_text) # Aggiungi un segnaposto nelle liste di testo e formato page_text.append('immagine') line_format.append('immagine') # Verifica gli elementi per le tabelle if isinstance(element, LTRect): # Se è il primo elemento rettangolare if first_element == True and (table_num+1) <= len(tables): # Trova il bounding box della tabella lower_side = page.bbox[3] - tables[table_num].bbox[3] upper_side = element.y1 # Estrai le informazioni dalla tabella table = extract_table(pdf_path, pagenum, table_num) # Converti le informazioni della tabella in formato di stringa strutturata table_string = table_converter(table) # Aggiungi la stringa della tabella in una lista text_from_tables.append(table_string) page_content.append(table_string) # Imposta il flag su True per evitare di estrarre nuovamente il contenuto table_extraction_flag = True # Rendilo un altro elemento first_element = False # Aggiungi un segnaposto nelle liste di testo e formato page_text.append('tabella') line_format.append('tabella') # Verifica se abbiamo già estratto le tabelle dalla pagina if element.y0 >= lower_side and element.y1 <= upper_side: pass elif not isinstance(page_elements[i+1][1], LTRect): table_extraction_flag = False first_element = True table_num+=1 # Crea la chiave del dizionario dctkey = 'Pagina_'+str(pagenum) # Aggiungi la lista di liste come valore della chiave della pagina text_per_page[dctkey]= [page_text, line_format, text_from_images,text_from_tables, page_content]# Chiudi l'oggetto file pdfpdfFileObj.close()# Elimina i file aggiuntivi creatios.remove('cropped_image.pdf')os.remove('PDF_image.png')# Visualizza il contenuto della paginarisultato = ''.join(text_per_page['Pagina_0'][4])print(result)Lo script sopra farà:
Importare le librerie necessarie.
Aprire il file PDF utilizzando la libreria pyPDF2.
Estrarre ogni pagina del PDF e iterare i seguenti passaggi.
Esaminare se ci sono tabelle sulla pagina e crearne una lista utilizzando pdfplumber.
Trovare tutti gli elementi nidificati nella pagina e ordinarli come appaiono nel layout.
Quindi, per ogni elemento:
Esaminare se è un contenitore di testo e non appare in un elemento di tabella. Utilizzare quindi la funzione text_extraction() per estrarre il testo insieme al suo formato, altrimenti passare questo testo.
Esaminare se è un’immagine e utilizzare la funzione crop_image() per ritagliare il componente dell’immagine dal PDF, convertirlo in un file immagine utilizzando convert_to_images(), ed estrarre il testo da esso utilizzando l’OCR con la funzione image_to_text().
Esaminare se è un elemento rettangolare. In tal caso, verifichiamo se il primo rettangolo fa parte di una tabella della pagina e, in caso affermativo, passiamo ai seguenti passaggi:
- Trovare il bounding box della tabella per non estrarre di nuovo il suo testo con la funzione text_extraction().
- Estrarre il contenuto della tabella e convertirlo in una stringa.
- Aggiungere quindi un parametro booleano per chiarire che stiamo estraendo il testo dalla tabella.
- Questo processo terminerà dopo l’ultimo LTRect che cade nel bounding box della tabella e l’elemento successivo nel layout non è un oggetto rettangolare. (Tutti gli altri oggetti che compongono la tabella saranno passati)
I risultati del processo verranno memorizzati in 5 liste per ogni iterazione, denominate:
- page_text: contiene il testo proveniente dai contenitori di testo nel PDF (verrà inserito un segnaposto quando il testo viene estratto da un altro elemento)
- line_format: contiene i formati dei testi estratti sopra (verrà inserito un segnaposto quando il testo viene estratto da un altro elemento)
- text_from_images: contiene i testi estratti dalle immagini sulla pagina
- text_from_tables: contiene la stringa simile a una tabella con i contenuti delle tabelle
- page_content: contiene tutto il testo visualizzato sulla pagina in una lista di elementi
Tutte le liste saranno memorizzate sotto la chiave in un dizionario che rappresenterà il numero della pagina esaminata ogni volta.
In seguito, chiuderemo il file PDF.
Quindi elimineremo tutti i file aggiuntivi creati durante il processo.
Infine, possiamo visualizzare il contenuto della pagina unendo gli elementi della lista page_content.
Conclusioni
Questo è stato un approccio che ritengo utilizzi le migliori caratteristiche di molte librerie e rende il processo resistente a vari tipi di PDF ed elementi che possiamo incontrare, con PDFMiner che si occupa della maggior parte del lavoro pesante. Inoltre, le informazioni riguardanti il formato del testo possono aiutarci nell’identificazione di potenziali titoli che possono separare il testo in sezioni logiche distinte anziché solo contenuto per pagina e possono aiutarci a identificare il testo di maggiore importanza.
Tuttavia, ci saranno sempre modi più efficienti per svolgere questo compito e anche se ritengo che questo approccio sia più inclusivo, non vedo l’ora di discutere con voi nuovi e migliori modi per affrontare questo problema.
📖 Riferimenti:
- https://www.techopedia.com/12-practical-large-language-model-llm-applications
- https://www.pdfa.org/wp-content/uploads/2018/06/1330_Johnson.pdf
- https://pdfpro.com/blog/guides/pdf-ocr-guide/#:~:text=OCR technology reads text from, a searchable and editable PDF.
- https://pdfminersix.readthedocs.io/en/latest/topic/converting_pdf_to_text.html#id1
- https://github.com/pdfminer/pdfminer.six