ANPR con YOLOV8
ANPR con YOLOV8
Introduzione:
YOLO V8 è l’ultimo modello sviluppato dal team di Ultralytics. È un modello YOLO all’avanguardia che supera i suoi predecessori sia in termini di precisione che di efficienza.
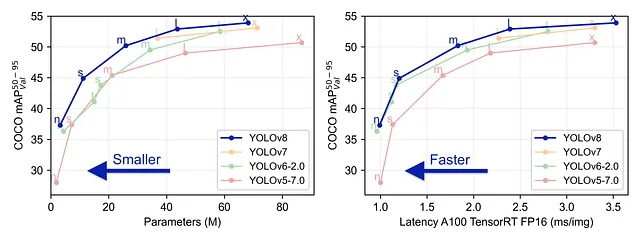
È facile da usare e accessibile dalla riga di comando o tramite il pacchetto Python. Offre un supporto immediato per le attività di rilevamento oggetti, classificazione e segmentazione. Di recente ha aggiunto il supporto nativo per il tracciamento degli oggetti, quindi non dovremo occuparci di clonare repository di algoritmi di tracciamento.
In questo articolo, tratterò i passaggi per utilizzare YOLOV8 per costruire uno strumento di riconoscimento automatico delle targhe dei veicoli (ANPR). Quindi cominciamo.
Tracciamento dei veicoli:
Come abbiamo accennato in precedenza, YOLOV8 ha il tracciamento nativo, quindi questa fase è piuttosto semplice. Prima, installa il pacchetto ultralytics
- Efficient Deep Learning Sfruttare il Potere della Compressione del Modello
- La dissolvenza controllata
- Top Strumenti per Videoconferenze 2023
pip install ultralyticsPoi, dobbiamo leggere i frame del video con OpenCV e applicare il metodo di tracciamento del modello con l’argomento persist impostato su True per garantire che gli ID persistano nel frame successivo. Il modello restituisce le coordinate per disegnare un rettangolo di delimitazione più l’ID, l’etichetta e il punteggio
import cv2from ultralytics import YOLOmodel = YOLO('yolov8n.pt')cap = cv2.VideoCapture("test_vids/vid1.mp4")ret = Truewhile ret: # Leggi un frame dalla telecamera ret, frame = cap.read() if ret and frame_nbr % 10 == 0 : results = model.track(frame,persist=True) for result in results[0].boxes.data.tolist(): x1, y1, x2, y2, id, score,label = result # verifica se la soglia è soddisfatta e l'oggetto è un'auto if score > 0.5 and label==2: cv2.rectangle(frame, (int(x1), int(y1)), (int(x2), int(y2)), (0, 255, 0), 4) text_x = int(x1) text_y = int(y1) - 10 cv2.putText(frame, str(id), (text_x, text_y), cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 255, 0), 2) cropped_img = frame[int(y1):int(y2), int(x1):int(x2)]ecco il risultato su un frame:
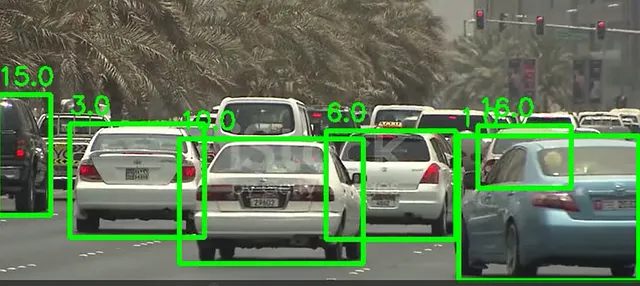
Le coordinate dei rettangoli di delimitazione vengono quindi utilizzate per ritagliare ogni auto nel frame in un’immagine
Riconoscimento delle targhe:
Ora che abbiamo le nostre auto, dobbiamo rilevare le targhe, per questo, dobbiamo addestrare il modello Yolo. A tal fine, ho utilizzato il seguente dataset di Kaggle.
Rilevamento delle targhe dei veicoli
433 immagini di targhe
www.kaggle.com
Tuttavia le etichette in questo dataset sono in formato PASCAL VOC XML:
<annotation> <folder>images</folder> <filename>Cars105.png</filename> <size> <width>400</width> <height>240</height> <depth>3</depth> </size> <segmented>0</segmented> <object> <name>licence</name> <pose>Unspecified</pose> <truncated>0</truncated> <occluded>0</occluded> <difficult>0</difficult> <bndbox> <xmin>152</xmin> <ymin>147</ymin> <xmax>206</xmax> <ymax>159</ymax> </bndbox> </object></annotation>YOLO ha bisogno delle annotazioni di ogni immagine in un file con il seguente formato: etichetta, centro x, centro y, larghezza, altezza
Questo codice gestisce la trasformazione dei nostri dati:
def xml_to_yolo(bbox, w, h): # xmin, ymin, xmax, ymax x_center = ((bbox[2] + bbox[0]) / 2) / w y_center = ((bbox[3] + bbox[1]) / 2) / h width = (bbox[2] - bbox[0]) / w height = (bbox[3] - bbox[1]) / h return [x_center, y_center, width, height]def convert_dataset(): for filename in os.listdir("annotations"): tree = ET.parse(f"annotations/{filename}") root = tree.getroot() name = root.find("filename").text.replace(".png", "") width = int(root.find("size").find("width").text) height = int(root.find("size").find("height").text) for obj in root.findall('object'): box = [] for x in obj.find("bndbox"): box.append(int(x.text)) yolo_box = xml_to_yolo(box, width, height) line = f"0 {yolo_box[0]} {yolo_box[1]} {yolo_box[2]} {yolo_box[3]}" with open(f"train/labels/{name}.txt", "a") as file: # Scrivi una riga nel file file.write(f"{line}\n")ora, l’unica cosa che rimane è configurare il nostro file yaml di configurazione con i percorsi alle cartelle dei dati di train e di validazione, quindi allenare il modello nota (i nomi delle cartelle all’interno delle cartelle di train e di validazione dovrebbero essere labels e images). Quindi, lo passiamo come argomento all’istanza del nostro modello e iniziamo l’allenamento
path: C:/Users/msi/PycharmProjects/ANPR_Yolov8train: trainval: val# Classesnames: 0: targa
model = YOLO('yolov8n.yaml')result = model.train(data="config.yaml",device="0",epochs=100,verbose=True,plots=True,save=True)
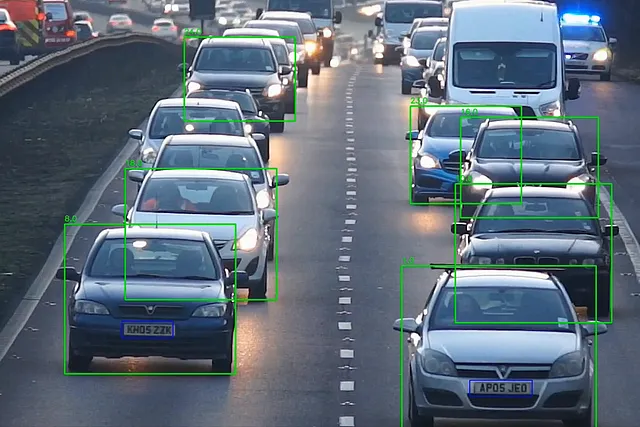
Ora che abbiamo il nostro modello di targa, dobbiamo semplicemente caricarlo e usarlo sulle immagini di auto ritagliate dal video, applichiamo la scala di grigi sul ritaglio della targa e usiamo easy_ocr per leggerne il contenuto
cropped_img = frame[int(y1):int(y2), int(x1):int(x2)]plates = lp_detector(cropped_img)for plate in plates[0].boxes.data.tolist(): if score > 0.6: x1, y1, x2, y2, score, _ = plate cv2.rectangle(cropped_img, (int(x1), int(y1)), (int(x2), int(y2)), (255, 0, 0), 2) lp_crop = cropped_img[int(y1):int(y2), int(x1):int(x2)] lp_crop_gray = cv2.cvtColor(lp_crop, cv2.COLOR_BGR2GRAY) ocr_res = reader.readtext(lp_crop_gray) if not ocr_res: print("Nessuna targa rilevata") else: entry = {'id': id, 'number': ocr_res[0][1], 'score': ocr_res[0][2]} update_csv(entry) out.write(frame) cv2.imshow('frame', frame) frame_nbr += 1la funzione update_csv scriverà l’id dell’auto e il numero di targa in un file CSV. E questo è il flusso di lavoro ANPR con yolov8
Conclusioni:
Come abbiamo visto, YOLOV8 semplifica il processo di costruzione di un flusso di lavoro ANPR in quanto offre il tracciamento nativo e la rilevazione degli oggetti.
questo repository contiene il progetto completo in cui ho creato un’app ANPR con streamlit:
GitHub – skandermenzli/ANPR_Yolov8
Contribuisci allo sviluppo di skandermenzli/ANPR_Yolov8 creando un account su GitHub.
github.com