Questo articolo di ricerca sull’IA presenta un’ampia panoramica del Deep Learning per la localizzazione visuale e la mappatura
Articolo di ricerca sull'IA panoramica del Deep Learning per la localizzazione visuale e la mappatura


Se ti chiedo: “Dove sei adesso?” o “Com’è il tuo ambiente circostante?” sarai in grado di rispondere immediatamente grazie a una capacità unica conosciuta come percezione multisensoriale negli esseri umani, che ti consente di percepire il tuo movimento e l’ambiente circostante garantendo una completa consapevolezza spaziale. Ma pensa se la stessa domanda fosse posta a un robot: come affronterebbe la sfida?
Il problema è che se questo robot non ha una mappa, non può sapere dove si trova, e se non sa com’è il suo ambiente circostante, non può nemmeno creare una mappa. Fondamentalmente, questo diventa un problema del tipo “chi è venuto prima, l’uovo o la gallina?” che nel contesto del machine learning viene definito problema di localizzazione e mappatura.
“La localizzazione” è la capacità di acquisire informazioni interne relative al movimento di un robot, incluse la sua posizione, l’orientamento e la velocità. D’altra parte, “la mappatura” riguarda la capacità di percepire le condizioni ambientali esterne, compresi aspetti come la forma dell’ambiente circostante, le sue caratteristiche visive e gli attributi semantici. Queste funzioni possono operare indipendentemente, con una focalizzata sugli stati interni e l’altra sulle condizioni esterne, oppure possono lavorare insieme come un unico sistema noto come Localizzazione e Mappatura Simultanea (SLAM).
- Sfrutta il potere di LLM Prompting senza shot e con pochi shot
- L’icona dell’horror Stephen King non ha paura dell’IA
- Predizione dell’incertezza basata sull’entropia
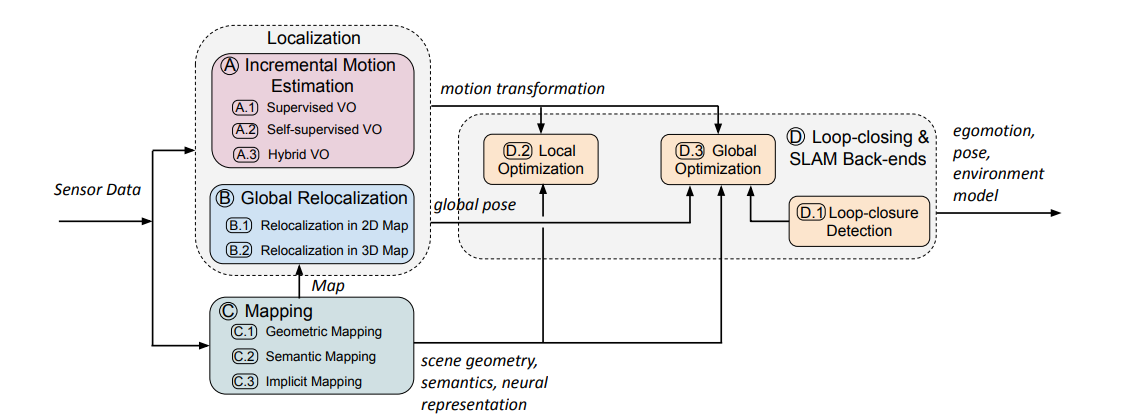
Le sfide attuali con algoritmi come la rilocazione basata su immagini, l’odometria visuale e SLAM includono misurazioni imperfette dei sensori, scene dinamiche, condizioni di illuminazione avverse e vincoli del mondo reale che in parte ostacolano la loro implementazione pratica. L’immagine sopra mostra come i singoli moduli possono essere integrati in un sistema SLAM basato sull’apprendimento profondo. Questo studio presenta un’ampia indagine su come approcci basati sull’apprendimento profondo e approcci tradizionali possano rispondere contemporaneamente a due domande essenziali:
- L’apprendimento profondo è promettente per la localizzazione e la mappatura visiva?
I ricercatori credono che le tre proprietà elencate di seguito potrebbero rendere l’apprendimento profondo una direzione unica per un sistema SLAM a uso generale in futuro.
- In primo luogo, l’apprendimento profondo offre potenti strumenti di percezione che possono essere integrati nella parte anteriore visiva di SLAM per estrarre caratteristiche in aree sfidanti per la stima dell’odometria o la rilocazione e fornire profondità densa per la mappatura.
- In secondo luogo, l’apprendimento profondo dota i robot di capacità avanzate di comprensione e interazione. Le reti neurali eccellono nel collegare concetti astratti a termini comprensibili dall’uomo, come l’etichettatura della semantica della scena all’interno di una mappatura o di un sistema SLAM, che sono tipicamente difficili da descrivere usando metodi matematici formali.
- Infine, i metodi di apprendimento consentono ai sistemi SLAM o agli algoritmi di localizzazione/mappatura individuali di imparare dall’esperienza e sfruttare attivamente nuove informazioni per l’apprendimento autonomo.
- Come può essere applicato l’apprendimento profondo per risolvere il problema della localizzazione e mappatura visiva?
- L’apprendimento profondo è uno strumento versatile per modellare vari aspetti di SLAM e algoritmi di localizzazione/mappatura individuali. Ad esempio, può essere impiegato per creare modelli di reti neurali end-to-end che stimano direttamente la posa dalle immagini. Risulta particolarmente utile per gestire condizioni sfidanti come aree prive di caratteristiche, illuminazione dinamica e mosso, in cui i metodi di modellazione convenzionali possono faticare.
- L’apprendimento profondo viene utilizzato per risolvere problemi di associazione in SLAM. Aiuta nella rilocazione, nella mappatura semantica e nella rilevazione della chiusura del ciclo collegando immagini a mappe, etichettando pixel semanticamente e riconoscendo scene rilevanti da visite precedenti.
- L’apprendimento profondo viene sfruttato per scoprire automaticamente le caratteristiche pertinenti al compito di interesse. Sfruttando la conoscenza precedente, ad esempio i vincoli di geometria, è possibile configurare automaticamente un framework di autoapprendimento per SLAM per aggiornare i parametri in base alle immagini di input.
È importante sottolineare che le tecniche di apprendimento profondo si basano su grandi set di dati accuratamente etichettati per estrarre modelli significativi, ma possono avere difficoltà a generalizzare a ambienti sconosciuti. Questi modelli mancano di interpretabilità, spesso funzionando come scatole nere. Inoltre, i sistemi di localizzazione e mappatura possono richiedere molte risorse computazionali, ma possono essere altamente parallelizzabili a meno che non vengano applicate tecniche di compressione del modello.