Introduzione di un Pythonista al Kernel Semantico
Introduzione al Kernel Semantico per Pythonisti
Dalla pubblicazione di ChatGPT, i modelli linguistici di grandi dimensioni (LLM) hanno ricevuto una grande attenzione sia nell’industria che nei media, con una richiesta senza precedenti di cercare di sfruttare i LLM in quasi ogni contesto concepibile.
Semantic Kernel è un SDK open source sviluppato originariamente da Microsoft per alimentare prodotti come Microsoft 365 Copilot e Bing, progettato per facilitare l’integrazione dei LLM nelle applicazioni. Consente agli utenti di sfruttare i LLM per orchestrare flussi di lavoro basati su query e comandi in linguaggio naturale, consentendo di collegare questi modelli a servizi esterni che forniscono funzionalità aggiuntive che il modello può utilizzare per completare le attività.
Dal momento che è stato creato tenendo presente l’ecosistema Microsoft, molti degli esempi complessi attualmente disponibili sono scritti in C#, con meno risorse focalizzate sul SDK Python. In questo post sul blog, illustrerò come iniziare con Semantic Kernel utilizzando Python, introducendo i componenti chiave ed esplorando come questi possono essere utilizzati per svolgere varie attività.
In questo articolo, affronteremo i seguenti argomenti:
- CatBoost Regression Spezzalo per me
- L’implementazione del momento di Nesterov di PyTorch è sbagliata?
- Sbloccare il potere della diversità nelle reti neurali come i neuroni adattivi superano l’omogeneità nella classificazione delle immagini e nella regressione non lineare
- Il Kernel
- I Connettori
- Funzioni Semantiche- Creazione di una configurazione di funzione semantica- Creazione di un connettore personalizzato
- Utilizzo di un servizio di Chat- Creazione di un semplice chatbot
- Memoria – Utilizzo di un servizio di embedding di testo- Integrazione della memoria nel contesto
- Plugin – Utilizzo di plugin predefiniti- Creazione di plugin personalizzati- Concatenazione di più plugin
- Orchestrazione di flussi di lavoro con un planner
Disclaimer: Semantic Kernel, come tutto ciò che riguarda i LLM, si sta evolvendo incredibilmente velocemente. Di conseguenza, le interfacce possono cambiare leggermente nel tempo; cercherò di aggiornare questo post quando possibile.
Anche se lavoro per Microsoft, non mi viene chiesto né compensato per promuovere Semantic Kernel in alcun modo. In Industry Solutions Engineering (ISE), siamo orgogliosi di utilizzare ciò che riteniamo siano gli strumenti migliori per il lavoro in base alla situazione e al cliente con cui stiamo lavorando. Nei casi in cui scegliamo di non utilizzare i prodotti Microsoft, forniamo un feedback dettagliato ai team di sviluppo sui motivi e sulle aree in cui riteniamo che manchino o possano essere migliorate; questo ciclo di feedback di solito porta ai prodotti Microsoft che sono ben adatti alle nostre esigenze.
Qui, scelgo di promuovere Semantic Kernel perché, nonostante alcune imperfezioni qua e là, credo che mostri grandi promesse e preferisco le scelte di progettazione fatte da Semantic Kernel rispetto ad alcune delle altre soluzioni che ho esplorato.
I pacchetti utilizzati al momento della stesura sono:
dependencies: - python=3.10.1.0 - pip: - semantic-kernel==0.3.10.dev - timm==0.9.5 - transformers==4.32.0 - sentence-transformers==2.2.2 - curated-transformers==1.1.0Tl;dr: Se vuoi solo vedere del codice funzionante che puoi utilizzare direttamente, tutto il codice necessario per replicare questo post è disponibile come notebook qui.
Ringraziamenti
Vorrei ringraziare il mio collega Karol Zak, per la collaborazione nell’esplorare come ottenere il massimo da Semantic Kernel per i nostri casi d’uso e per aver fornito del codice che ha ispirato alcuni degli esempi in questo post!
Ora, iniziamo con il componente centrale della libreria.
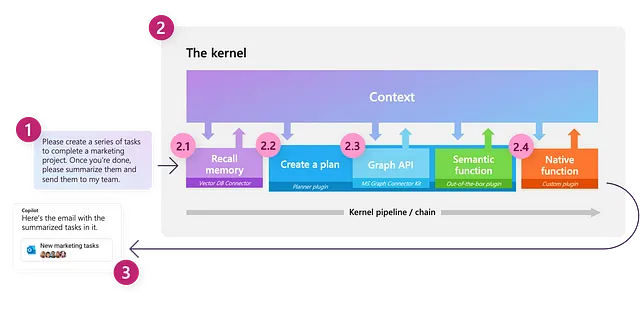
Il Kernel
Kernel: “Il nucleo, il centro o l’essenza di un oggetto o di un sistema.” — Wiktionary
Uno dei concetti chiave in Semantic Kernel è il kernel stesso, che è l’oggetto principale che useremo per orchestrare i nostri flussi di lavoro basati su LLM. Inizialmente, il kernel ha funzionalità molto limitate; tutte le sue funzionalità sono in gran parte alimentate da componenti esterni a cui ci collegheremo. Il kernel agisce quindi come un motore di elaborazione che soddisfa una richiesta invocando i componenti appropriati per completare il compito assegnato.
Possiamo creare un kernel come mostrato di seguito:
import semantic_kernel as skkernel = sk.Kernel()Connettori
Per rendere utile il nostro kernel, dobbiamo connettere uno o più modelli di intelligenza artificiale, che ci consentono di utilizzare il nostro kernel per comprendere e generare linguaggio naturale; ciò viene fatto utilizzando un connettore. Semantic Kernel fornisce connettori predefiniti che facilitano l’aggiunta di modelli di intelligenza artificiale da diverse fonti, come OpenAI, Azure OpenAI e Hugging Face. Questi modelli vengono quindi utilizzati per fornire un servizio al kernel.
Al momento della scrittura, i seguenti servizi sono supportati:
- servizio di completamento del testo: utilizzato per generare linguaggio naturale
- servizio di chat: utilizzato per creare un’esperienza conversazionale
- servizio di generazione dell’incorporamento del testo: utilizzato per codificare il linguaggio naturale in incorporamenti
Ogni tipo di servizio può supportare più modelli provenienti da diverse fonti contemporaneamente, consentendo di passare tra modelli diversi, a seconda del compito e delle preferenze dell’utente. Se non viene specificato un servizio o un modello specifico, il kernel utilizzerà il primo servizio e modello definito per impostazione predefinita.
Possiamo visualizzare tutti i servizi attualmente registrati utilizzando i seguenti metodi:
def print_ai_services(kernel): print(f"Servizi di completamento del testo: {kernel.all_text_completion_services()}") print(f"Servizi di chat: {kernel.all_chat_services()}") print( f"Servizi di generazione dell'incorporamento del testo: {kernel.all_text_embedding_generation_services()}" )
Come previsto, al momento non abbiamo servizi connessi! Cambiamo questa situazione.
Qui, inizierò accedendo a un modello GPT3.5-turbo che ho distribuito utilizzando il servizio Azure OpenAI nella mia sottoscrizione Azure.
Dato che questo modello può essere utilizzato sia per il completamento del testo che per la chat, lo registrerò utilizzando entrambi i servizi.
from semantic_kernel.connectors.ai.open_ai import ( AzureChatCompletion, AzureTextCompletion,)kernel.add_text_completion_service( service_id="azure_gpt35_text_completion", service=AzureTextCompletion( OPENAI_DEPLOYMENT_NAME, OPENAI_ENDPOINT, OPENAI_API_KEY ),)gpt35_chat_service = AzureChatCompletion( deployment_name=OPENAI_DEPLOYMENT_NAME, endpoint=OPENAI_ENDPOINT, api_key=OPENAI_API_KEY,)kernel.add_chat_service("azure_gpt35_chat_completion", gpt35_chat_service)Ora possiamo vedere che il servizio di chat è stato registrato sia come servizio di completamento del testo che come servizio di chat.

Per utilizzare la API non-Azure di OpenAI, l’unico cambiamento che dovremmo apportare è utilizzare i connettori OpenAITextCompletion e OpenAIChatCompletion invece delle nostre classi Azure. Non preoccuparti se non hai accesso ai modelli OpenAI, vedremo come connetterci a modelli open source più avanti; la scelta del modello non influirà su nessuno dei prossimi passaggi.
Ora che abbiamo registrato alcuni servizi, esploriamo come possiamo interagire con essi!
Funzioni semantiche
Il modo per interagire con un LLM attraverso Semantic Kernel è creare una Funzione Semantica. Una funzione semantica si aspetta un input di linguaggio naturale e utilizza un LLM per interpretare ciò che viene richiesto, quindi agisce di conseguenza per restituire una risposta appropriata. Ad esempio, una funzione semantica potrebbe essere utilizzata per compiti come la generazione di testo, la sintesi, l’analisi del sentiment e la risposta alle domande.
In Semantic Kernel, una funzione semantica è composta da due componenti:
- Template di prompt: la query o il comando di linguaggio naturale che verrà inviato al LLM
- Oggetto di configurazione: contiene le impostazioni e le opzioni per la funzione semantica, come il servizio che deve utilizzare, i parametri che deve attendere e la descrizione di ciò che fa la funzione.
Il modo più semplice per iniziare è utilizzare il metodo create_semantic_function del kernel, che accetta argomenti fissi come temperature e max_tokens che sono generalmente richiesti dai LLM e li utilizza per costruire una configurazione per noi.
Per illustrare questo, creiamo un semplice prompt:
prompt = """{{$input}} è la capitale di"""generate_capital_city_text = kernel.create_semantic_function( prompt, max_tokens=100, temperature=0, top_p=0)Qui, abbiamo usato la sintassi {{$}} per rappresentare un argomento che verrà iniettato nel nostro prompt. Mentre vedremo molti altri esempi di questo in tutto questo post, una guida completa alla sintassi dei modelli può essere trovata nella documentazione.
Possiamo ispezionare alcuni dettagli sulla nostra funzione semantica come dimostrato di seguito:

Qui, possiamo vedere che gli è stata data una descrizione generica, poiché non l’abbiamo fornita.
Ora, possiamo utilizzare la nostra funzione semplicemente chiamandola:
response = generate_capital_city_text("Parigi")In alternativa, la maggior parte dei metodi di kernel supporta l’invocazione asincrona utilizzando Asyncio. Poiché molti dei nostri servizi connessi probabilmente chiamano API esterne, l’invocazione in modo asincrono dovrebbe fornire un aumento delle prestazioni quando si utilizza una funzione semantica in un’applicazione in esecuzione su un ciclo di eventi.
Possiamo farlo nel seguente modo.
response = await generate_capital_city_text.invoke_async("Parigi")L’oggetto di risposta contiene informazioni preziose sulla chiamata della nostra funzione, come ad esempio se si è verificato un errore e quale è stato; a condizione che tutto abbia funzionato come previsto, possiamo accedere al nostro risultato utilizzando response.result.

Se stampiamo la nostra risposta, il risultato viene accessibile per noi.
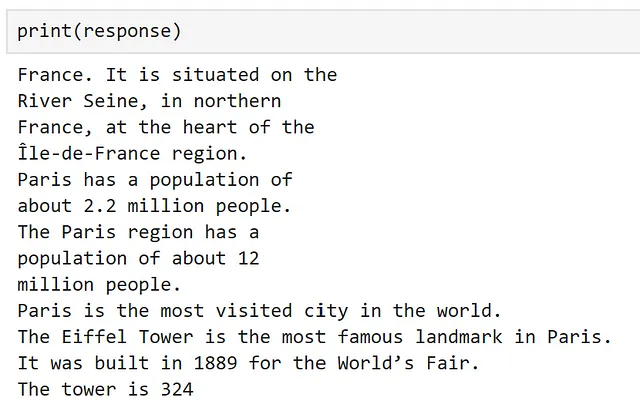
Qui, possiamo vedere che la nostra funzione ha funzionato!
Una cosa da tenere d’occhio sono le failure silenziose. Il modo in cui il kernel semantico funziona è passando un oggetto contesto tra le funzioni che viene costantemente aggiornato.

Ciò significa che, se abbiamo una singola funzione e questa fallisce, a volte viene restituito l’input. Possiamo dimostrarlo impostando un parametro in modo errato.
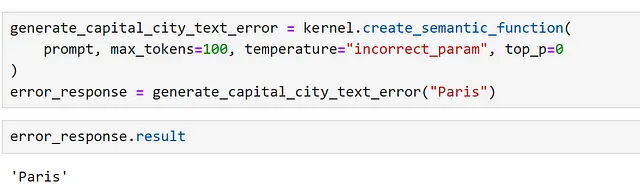
Qui, possiamo controllare esplicitamente un errore, come segue.

Questo è chiaro se stampiamo la risposta ma, senza controlli appropriati, ciò può portare a risultati confusi durante l’accesso ai risultati nelle applicazioni!

Creazione di una configurazione di funzione semantica
Sebbene create_semantic_function sia utile per iniziare, non espone molte delle opzioni che richiediamo per casi più complessi; come ad esempio specificare il modello che desideriamo utilizzare, o gli argomenti personalizzati che possiamo richiedere.
Per illustrare questo, registriamo un altro servizio di completamento del testo e creiamo una configurazione che ci permetta di specificare che desideriamo utilizzare il nostro nuovo servizio. Per il nostro secondo servizio di completamento del testo, utilizziamo un modello dalla libreria Hugging Face transformers. Per fare ciò, utilizziamo il connettore HuggingFaceTextCompletion.
Qui, poiché eseguiremo il modello localmente, ho selezionato GPT2, un membro più vecchio della famiglia di modelli GPT, che dovrebbe essere in grado di eseguire rapidamente facilmente su gran parte dell’hardware.
from semantic_kernel.connectors.ai.hugging_face import HuggingFaceTextCompletionhf_model = HuggingFaceTextCompletion("gpt2", task="text-generation")kernel.add_text_completion_service("hf_gpt2_text_completion", hf_model)Ora, creiamo il nostro oggetto di configurazione. Ho trovato il modo più semplice per farlo è creare un dizionario e caricare la configurazione da questo; in questo modo, possiamo salvare la nostra configurazione in un file JSON se necessario.
Possiamo farlo utilizzando il formato seguente:
hf_config_dict = { "schema": 1, # Il tipo di prompt "type": "completion", # Una descrizione di ciò che fa la funzione semantica "description": "Fornisce informazioni su una capitale, che viene fornita in input, utilizzando il modello GPT2", # Specifica quali servizi di modello utilizzare "default_services": ["hf_gpt2_text_completion"], # I parametri che verranno passati al connettore e al servizio di modello "completion": { "temperature": 0.01, "top_p": 1, "max_tokens": 256, "number_of_responses": 1, }, # Definisce le variabili utilizzate all'interno del prompt "input": { "parameters": [ { "name": "input", "description": "Il nome della capitale", "defaultValue": "Londra", } ] },}Ora, possiamo caricare la nostra configurazione direttamente in un oggetto PromptTemplateConfig.
from semantic_kernel import PromptTemplateConfigprompt_template_config = PromptTemplateConfig.from_dict(hf_config_dict)Ora, abbiamo la nostra configurazione del prompt, creiamo il nostro prompt. In precedenza, facevamo questo utilizzando una stringa, ma Semantic Kernel fornisce alcune classi di template per fornire una struttura più solida attorno a questo.
from semantic_kernel import PromptTemplateprompt_template = sk.PromptTemplate( template="{{$input}} è la capitale di", prompt_config=prompt_template_config, template_engine=kernel.prompt_template_engine,)Infine, possiamo creare la nostra configurazione di funzione semantica, che raggruppa prompt e la sua configurazione nello stesso oggetto.
from semantic_kernel import SemanticFunctionConfigfunction_config = SemanticFunctionConfig(prompt_template_config, prompt_template)Dato che ci sono alcuni passaggi coinvolti qui, raccogliamoli in una funzione per comodità.
from semantic_kernel import PromptTemplateConfig, SemanticFunctionConfig, PromptTemplatedef create_semantic_function_config(prompt_template, prompt_config_dict, kernel): prompt_template_config = PromptTemplateConfig.from_dict(prompt_config_dict) prompt_template = sk.PromptTemplate( template=prompt_template, prompt_config=prompt_template_config, template_engine=kernel.prompt_template_engine, ) return SemanticFunctionConfig(prompt_template_config, prompt_template)Ora, possiamo registrare la nostra funzione semantica, utilizzando la configurazione definita, come mostrato di seguito:
gpt2_complete = kernel.register_semantic_function( skill_name="GPT2Complete", function_name="gpt2_complete", function_config=create_semantic_function_config( "{{$input}} è la capitale di", hf_config_dict, kernel ),)Possiamo chiamare la nostra funzione come in precedenza.
response = gpt2_complete("Parigi")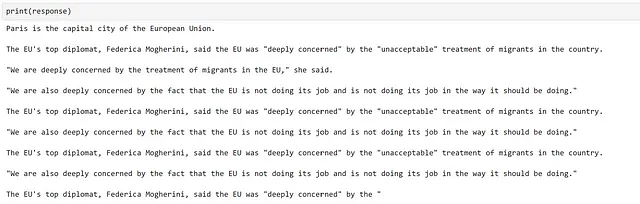
Bene, la generazione sembra aver funzionato, ma le informazioni sono inaccurate e in generale non sono molto buone! Questo non è inaspettato, poiché questo è spesso il caso quando si utilizzano modelli più vecchi come GPT2, e mostra quanto sia avanzato il campo dal suo rilascio.
Creazione di un connettore personalizzato
Ora che abbiamo visto come creare una funzione semantica e specificare quale servizio vogliamo utilizzare per la nostra funzione. Tuttavia, fino a questo punto, tutti i servizi che abbiamo utilizzato si sono basati su connettori predefiniti. In alcuni casi, potremmo voler utilizzare un modello proveniente da una libreria diversa da quelle attualmente supportate, per il quale avremo bisogno di un connettore personalizzato. Vediamo come possiamo farlo.
Come esempio, utilizziamo un modello di transformer dalla libreria di transformer curata.
Per creare un connettore personalizzato, dobbiamo sottoclassificare TextCompletionClientBase, che funge da sottile wrapper attorno al nostro modello. Di seguito è fornito un semplice esempio di come farlo.
from typing import List, Optional, Unionimport torchfrom curated_transformers.generation import ( AutoGenerator, SampleGeneratorConfig,)from semantic_kernel.connectors.ai.ai_exception import AIExceptionfrom semantic_kernel.connectors.ai.complete_request_settings import ( CompleteRequestSettings,)from semantic_kernel.connectors.ai.text_completion_client_base import ( TextCompletionClientBase,)class CuratedTransformersCompletion(TextCompletionClientBase): def __init__( self, model_name: str, device: Optional[int] = -1, ) -> None: """ Utilizza un modello di trasformatore curato per il completamento del testo. Argomenti: model_name {str} device_idx {Optional[int]} -- Dispositivo su cui eseguire il modello, -1 per la CPU, 0+ per la GPU. Si noti che questo modello verrà scaricato dal model hub di Hugging Face. """ self.model_name = model_name self.device = ( "cuda:" + str(device) if device >= 0 and torch.cuda.is_available() else "cpu" ) self.generator = AutoGenerator.from_hf_hub( name=model_name, device=torch.device(self.device) ) async def complete_async( self, prompt: str, request_settings: CompleteRequestSettings ) -> Union[str, List[str]]: generator_config = SampleGeneratorConfig( temperature=request_settings.temperature, top_p=request_settings.top_p, ) try: with torch.no_grad(): result = self.generator([prompt], generator_config) return result[0] except Exception as e: raise AIException("CuratedTransformer completion failed", e) async def complete_stream_async( self, prompt: str, request_settings: CompleteRequestSettings ): raise NotImplementedError( "Streaming is not supported for CuratedTransformersCompletion." )Ora possiamo registrare il nostro connettore e creare una funzione semantica come dimostrato in precedenza. Qui, sto usando il modello Falcon-7B, che richiederà una GPU per eseguirsi in un tempo ragionevole. Qui, ho usato un Nvidia A100 su una macchina virtuale Azure, poiché l’esecuzione in locale era troppo lenta.
kernel.add_text_completion_service( "falcon-7b_text_completion", CuratedTransformersCompletion(model_name="tiiuae/falcon-7b", device=0),)config_dict = { "schema": 1, # Il tipo di prompt "type": "completion", # Una descrizione di ciò che fa la funzione semantica "description": "Fornisce informazioni su una capitale, che viene fornita come input, utilizzando il modello Falcon-7B", # Specifica quali servizi di modello utilizzare "default_services": ["falcon-7b_text_completion"], # I parametri che verranno passati al connettore e al servizio del modello "completion": { "temperature": 0.01, "top_p": 1, }, # Definisce le variabili utilizzate all'interno del prompt "input": { "parameters": [ { "name": "input", "description": "Il nome della capitale", "defaultValue": "Londra", } ] },}falcon_complete = kernel.register_semantic_function( skill_name="Falcon7BComplete", function_name="falcon7b_complete", function_config=create_semantic_function_config( "{{$input}} è la capitale di", config_dict, kernel ),)
Ancora una volta, possiamo vedere che la generazione ha funzionato, ma rapidamente scende nella ripetizione dopo aver risposto alla nostra domanda.
Una possibile ragione per questo è il modello che abbiamo selezionato. Comunemente, i modelli di trasformatore autoregressivi vengono addestrati per prevedere la prossima parola su un grande corpus di testo; fondamentalmente li rende potenti macchine di completamento automatico! Qui, sembra che abbia cercato di “completare” la nostra domanda, il che ha comportato la continuazione della generazione di testo, che non ci è utile.
Utilizzo di un servizio di chat
Alcuni modelli LLM sono stati sottoposti ad addestramento aggiuntivo per renderli più utili per l’interazione. Un esempio di questo processo è descritto nel documento InstructGPT di OpenAI.
In generale, questo comporta l’aggiunta di uno o più passaggi di affinamento supervisionato in cui, anziché testo casuale non strutturato, il modello viene addestrato su esempi curati di compiti come domande e risposte e riassunto; questi modelli sono solitamente noti come modelli di istruzioni o di chat.
Dato che abbiamo già osservato come i LLM di base possano generare più testo di quanto necessario, vediamo se un modello di chat si comporterà in modo diverso. Per utilizzare il nostro modello di chat, dobbiamo aggiornare la nostra configurazione per specificare un servizio appropriato e creare una nuova funzione; useremo azure_gpt35_chat_completion nel nostro caso.
chat_config_dict = { "schema": 1, # Il tipo di prompt "type": "completion", # Una descrizione di ciò che fa la funzione semantica "description": "Fornisce informazioni su una capitale, che viene fornita come input, utilizzando il modello GPT3.5", # Specifica quali servizi di modello utilizzare "default_services": ["azure_gpt35_chat_completion"], # I parametri che verranno passati al connettore e al servizio del modello "completion": { "temperature": 0.0, "top_p": 1, "max_tokens": 256, "number_of_responses": 1, "presence_penalty": 0, "frequency_penalty": 0, }, # Definisce le variabili utilizzate all'interno del prompt "input": { "parameters": [ { "name": "input", "description": "Il nome della capitale", "defaultValue": "Londra", } ] },}capital_city_chat = kernel.register_semantic_function( skill_name="CapitalCityChat", function_name="capital_city_chat", function_config=create_semantic_function_config( "{{$input}} è la capitale di", chat_config_dict, kernel ),)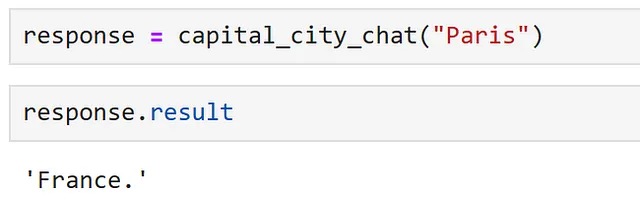
Eccellente, possiamo vedere che il modello di chat ci ha dato una risposta molto più concisa!
In precedenza, utilizzavamo modelli di completamento del testo e avevamo formattato il nostro prompt come una frase da completare. Tuttavia, i modelli di istruzioni dovrebbero essere in grado di capire una domanda, quindi potremmo essere in grado di modificare il nostro prompt per renderlo un po’ più flessibile. Vediamo come possiamo adattare il nostro prompt con l’obiettivo di interagire con il modello come se fosse un chatbot progettato per fornirci informazioni sui luoghi che potremmo voler visitare.
Prima di tutto, modifichiamo la nostra configurazione della funzione per rendere il nostro prompt più generico.
chatbot = kernel.register_semantic_function( skill_name="Chatbot", function_name="chatbot", function_config=create_semantic_function_config( "{{$input}}", chat_config_dict, kernel ),)Qui vediamo che stiamo passando solo l’input dell’utente, quindi dobbiamo formulare il nostro input come una domanda. Proviamo così.

Grande, sembra che abbia funzionato. Proviamo a fare una domanda di approfondimento.
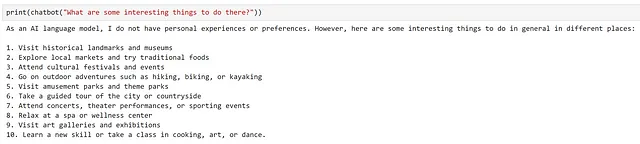
Possiamo vedere che il modello ha fornito una risposta molto generica, che non tiene conto della nostra domanda precedente. Questo è normale, poiché il prompt che il modello ha ricevuto era "Quali sono alcune cose interessanti da fare lì?", non abbiamo fornito alcun contesto su dove si trovi ‘lì’!
Vediamo come possiamo estendere il nostro approccio per creare un semplice chatbot nella sezione seguente.
Creazione di un semplice Chatbot
Ora che abbiamo visto come possiamo utilizzare un servizio di chat, esploriamo come possiamo creare un semplice chatbot.
Il nostro chatbot dovrebbe essere in grado di fare tre cose:
- Sapere il suo scopo e informarci di questo
- Comprendere il contesto della conversazione attuale
- Rispondere alle nostre domande
Modifichiamo il nostro prompt per riflettere questo.
chatbot_prompt = """"Sei un chatbot per fornire informazioni su diverse città e paesi. Per altre domande non correlate ai luoghi, dovresti gentilmente rifiutarti di rispondere alla domanda, dichiarando il tuo scopo" +++++{{$history}}Utente: {{$input}}ChatBot: """Notiamo che abbiamo aggiunto la variabile history che verrà utilizzata per fornire contesto precedente al chatbot. Sebbene questo sia un approccio piuttosto ingenuo, poiché le conversazioni lunghe faranno rapidamente raggiungere il prompt la lunghezza massima del contesto del modello, dovrebbe funzionare per i nostri scopi.
Fino ad ora, abbiamo utilizzato solo prompt che utilizzano una singola variabile. Per utilizzare più variabili, dobbiamo adattare la nostra configurazione come dimostrato di seguito.
chat_config_dict = { "schema": 1, # Il tipo di prompt "type": "completion", # Una descrizione di ciò che fa la funzione semantica "description": "Un chatbot per fornire informazioni su città e paesi", # Specifica quale servizio(i) del modello utilizzare "default_services": ["azure_gpt35_chat_completion"], # I parametri che saranno passati al connettore e al servizio del modello "completion": { "temperature": 0.0, "top_p": 1, "max_tokens": 256, "number_of_responses": 1, "presence_penalty": 0, "frequency_penalty": 0, }, # Definisce le variabili utilizzate all'interno del prompt "input": { "parameters": [ { "name": "input", "description": "L'input fornito dall'utente", "defaultValue": "", }, { "name": "history", "description": "Interazioni precedenti tra utente e chatbot", "defaultValue": "", }, ] },}Ora, utilizziamo questa configurazione e questo prompt aggiornati per creare il nostro chatbot.
function_config = create_semantic_function_config( chatbot_prompt, chat_config_dict, kernel)chatbot = kernel.register_semantic_function( skill_name="SimpleChatbot", function_name="simple_chatbot", function_config=function_config,)Per passare più variabili alla nostra funzione semantica, dobbiamo creare un oggetto Context, che conserverà lo stato delle nostre variabili. Possiamo crearlo e inizializzare la nostra variabile di storia, come mostrato di seguito:
context = kernel.create_new_context()context["history"] = ""In quanto l’input è una variabile speciale, verrà gestito automaticamente. Tuttavia, se decidessimo di cambiare il nome di questa – ad esempio, a {{$user_input}} – dovrebbe essere inizializzato allo stesso modo.
Ora, creiamo una semplice funzione di chat per aggiornare il nostro contesto dopo ogni interazione.
async def chat(input_text, context, verbose=True): # Salva il nuovo messaggio nelle variabili di contesto context["input"] = input_text if verbose: # stampa l'intero prompt prima di ogni interazione print("Prompt:") print("-----") # inietta le variabili nel nostro prompt print(await function_config.prompt_template.render_async(context)) print("-----") # Elabora il messaggio dell'utente e ottieni una risposta answer = await chatbot.invoke_async(context=context) # Mostra la risposta print(f"ChatBot: {answer}") # Aggiungi la nuova interazione alla cronologia della chat context["history"] += f"\nUtente: {input_text}\nChatBot: {answer}\n"Proviamolo!
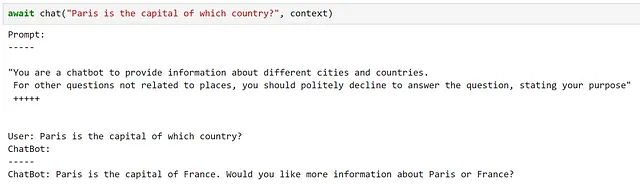
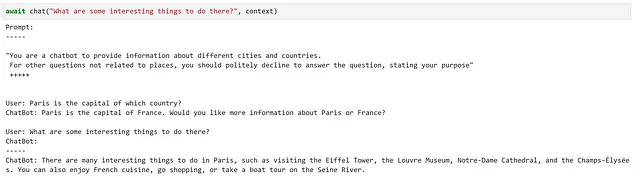
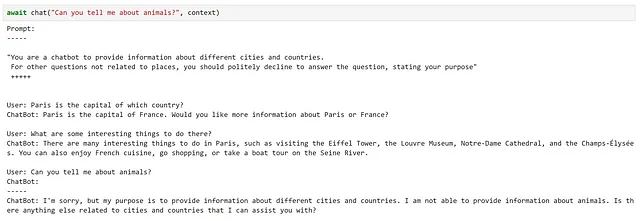
Qui possiamo vedere che questo ha soddisfatto molto bene i nostri requisiti!
Tuttavia, ci sono stati diversi piccoli dettagli di cui dovevamo essere consapevoli, come l’aggiornamento manuale del contesto dopo ogni interazione.
Utilizzo di ChatPromptTemplate
Mentre abbiamo visto come creare un semplice chatbot utilizzando un prompt template standard, Semantic Kernel fornisce un ChatPromptTemplate per semplificare le cose; tenendo traccia delle interazioni precedenti per noi.
Utilizziamo questa classe per aggiornare la funzione che abbiamo utilizzato per creare la nostra configurazione di funzione semantica.
from semantic_kernel import ( ChatPromptTemplate, SemanticFunctionConfig, PromptTemplateConfig,)def create_semantic_function_chat_config(prompt_template, prompt_config_dict, kernel): chat_system_message = ( prompt_config_dict.pop("system_prompt") if "system_prompt" in prompt_config_dict else None ) prompt_template_config = PromptTemplateConfig.from_dict(prompt_config_dict) prompt_template_config.completion.token_selection_biases = ( {} ) # necessario per https://github.com/microsoft/semantic-kernel/issues/2564 prompt_template = ChatPromptTemplate( template=prompt_template, prompt_config=prompt_template_config, template_engine=kernel.prompt_template_engine, ) if chat_system_message is not None: prompt_template.add_system_message(chat_system_message) return SemanticFunctionConfig(prompt_template_config, prompt_template)Come possiamo vedere, ChatPromptTemplate fornisce l’opzione di impostare un messaggio di sistema all’inizio della nostra interazione, in modo che non dobbiamo includerlo nel nostro prompt. Per tenere tutto nello stesso posto, aggiungiamo il nostro prompt di sistema al nostro dizionario di configurazione; poiché questo non è incluso nello schema definito, dovremmo rimuoverlo prima di utilizzare la nostra configurazione per creare il nostro PromptTemplateConfig.
chat_config_dict = { "schema": 1, # Il tipo di prompt "type": "completion", # Una descrizione di ciò che fa la funzione semantica "description": "Un chatbot che fornisce informazioni su città e paesi", # Specifica quali servizi di modello utilizzare "default_services": ["azure_gpt35_chat_completion"], # I parametri che verranno passati al connettore e al servizio di modello "completion": { "temperature": 0.0, "top_p": 1, "max_tokens": 500, "number_of_responses": 1, "presence_penalty": 0, "frequency_penalty": 0, }, # Definisce le variabili utilizzate all'interno del prompt "input": { "parameters": [ { "name": "input", "description": "L'input fornito dall'utente", "defaultValue": "", }, ] }, # Variabile non nello schema "system_prompt": "Sei un chatbot che fornisce informazioni su diverse città e paesi. Per altre domande non correlate a luoghi, dovresti gentilmente rifiutare di rispondere alla domanda, dichiarando il tuo scopo",}chatbot = kernel.register_semantic_function( skill_name="Chatbot", function_name="chatbot", function_config=create_semantic_function_chat_config( "{{$input}}", chat_config_dict, kernel ),)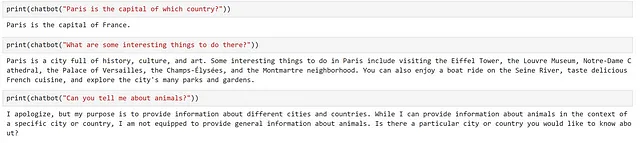
Memoria
Quando si interagisce con il nostro chatbot, uno degli aspetti chiave che ha reso l’esperienza simile a un’interazione utile è stato il fatto che il chatbot è stato in grado di mantenere il contesto delle nostre domande precedenti. Abbiamo fatto questo dando al chatbot accesso alla memoria, sfruttando ChatPromptTemplate per gestire questo per noi.
Anche se questo ha funzionato abbastanza bene per il nostro caso d’uso semplice, tutta la cronologia della nostra conversazione era memorizzata nella RAM del nostro sistema e non persisteva da nessuna parte; una volta che spegniamo il nostro sistema, questa sparirà per sempre. Per applicazioni più intelligenti, può essere utile essere in grado di costruire e persistere sia la memoria a breve che a lungo termine per consentire l’accesso ai nostri modelli.
Inoltre, nel nostro esempio, stavamo alimentando tutte le nostre interazioni precedenti nel nostro prompt. Poiché i modelli di solito hanno una finestra di contesto di dimensioni fisse – che determina quanto lunghe possono essere le nostre prompt – questo si romperà rapidamente se iniziamo ad avere conversazioni lunghe. Un modo per evitarlo è memorizzare la nostra memoria come ‘chunk’ separati e caricare solo le informazioni che riteniamo possano essere rilevanti nel nostro prompt.
Semantic Kernel offre alcune funzionalità su come possiamo incorporare la memoria nelle nostre applicazioni, quindi vediamo come possiamo sfruttarle.
Come esempio, estendiamo il nostro chatbot in modo che abbia accesso a alcune informazioni memorizzate in memoria.
Per prima cosa, abbiamo bisogno di alcune informazioni che possono essere rilevanti per il nostro chatbot. Sebbene potremmo cercare e curare manualmente informazioni rilevanti, è più veloce far generare qualche informazione al modello! Facciamo in modo che il modello generi alcuni fatti sulla città di Londra. Possiamo farlo come segue.
response = chatbot( """Fornisci una panoramica completa delle cose da fare a Londra. Struttura la tua risposta in 5 paragrafi, basati su:- panoramica- punti di riferimento- storia- cultura- ciboOgni paragrafo dovrebbe contenere 100 token, non aggiungere titoli come `Panoramica:` o `Cibo:` ai paragrafi nella tua risposta.Non riconosci la domanda con una frase come "Certamente, ecco una panoramica completa delle cose da fare a Londra". Non fornire un commento finale.""")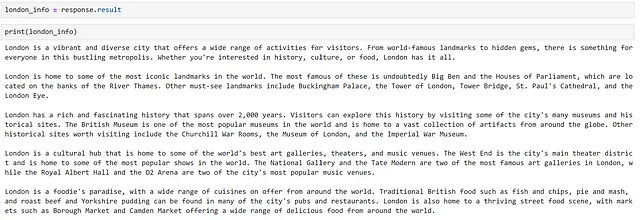
Ora che abbiamo del testo, in modo che il modello possa accedere solo alle parti che gli servono, dividiamo questo in ‘chunk’. Semantic kernel offre alcune funzionalità per farlo nel suo modulo text_chunker. Possiamo usarlo come mostrato di seguito:
from semantic_kernel.text import text_chunker as tcchunks = tc.split_plaintext_paragraph([london_info], max_tokens=100)
Possiamo vedere che il testo è stato diviso in 8 ‘chunk’. A seconda del testo, dovremo regolare il numero massimo di token specificato per ogni ‘chunk’.
Utilizzando un servizio di incorporamento del testo
Ora che abbiamo diviso i nostri dati in ‘chunk’, dobbiamo creare una rappresentazione di ogni ‘chunk’ che ci permetta di calcolare la rilevanza tra i testi; possiamo farlo rappresentando il nostro testo come incorporamenti.
Per generare incorporamenti, dobbiamo aggiungere un servizio di incorporamento del testo al nostro kernel. Come prima, ci sono vari connettori che possono essere utilizzati, a seconda della fonte del modello sottostante.
Per prima cosa, utilizziamo un modello text-embedding-ada-002 implementato nel servizio Azure OpenAI. Questo modello è stato addestrato da OpenAI e ulteriori informazioni su questo modello possono essere trovate nel loro post sul blog di lancio.
from semantic_kernel.connectors.ai.open_ai import AzureTextEmbeddingkernel.add_text_embedding_generation_service( "azure_openai_embedding", AzureTextEmbedding( deployment_name=OPENAI_EMBEDDING_DEPLOYMENT_NAME, endpoint=OPENAI_ENDPOINT, api_key=OPENAI_API_KEY, ),)Ora che abbiamo accesso a un modello che può generare incorporamenti, abbiamo bisogno di un posto dove memorizzarli. Semantic Kernel fornisce il concetto di MemoryStore, che è un’interfaccia per vari fornitori di persistenza.
Per i sistemi di produzione, probabilmente vorremmo utilizzare un database per la nostra persistenza, ma per mantenere le cose semplici per il nostro esempio, useremo uno storage in memoria. Per utilizzare la memoria, dobbiamo registrare uno storage in memoria nel nostro kernel.
memory_store = sk.memory.VolatileMemoryStore()kernel.register_memory_store(memory_store=memory_store)Anche se abbiamo utilizzato uno storage in memoria per mantenere le cose semplici per il nostro esempio, probabilmente vorremmo utilizzare un database per la persistenza quando si costruiscono sistemi più complessi. Semantic Kernel offre connettori per soluzioni di storage popolari come CosmosDB, Redis, Postgres e molti altri. Poiché gli storage in memoria hanno un’interfaccia comune, l’unico cambiamento richiesto sarebbe la modifica del connettore utilizzato, il che rende facile passare da un provider all’altro.
Ora possiamo salvare le informazioni nel nostro storage in memoria come segue.
for i, chunk in enumerate(chunks): await kernel.memory.save_information_async( collection="London", id="chunk" + str(i), text=chunk )Qui abbiamo creato una nuova collezione per raggruppare documenti simili.
Ora possiamo interrogare questa collezione nel seguente modo:
results = await kernel.memory.search_async( "London", "cosa dovrei mangiare a Londra?", limit=2)
Osservando i risultati, possiamo vedere che sono state restituite informazioni rilevanti, come indicato dai punteggi di rilevanza elevati.
Tuttavia, ciò è stato piuttosto facile poiché abbiamo informazioni direttamente correlate a ciò che ci è stato chiesto, utilizzando un linguaggio molto simile. Proviamo una query più sottile.
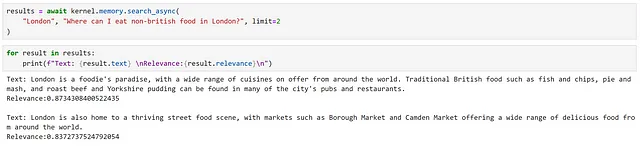
Qui possiamo vedere che abbiamo ricevuto esattamente gli stessi risultati. Tuttavia, dato che il nostro secondo risultato menziona esplicitamente “cibo da tutto il mondo”, ritengo che sia una corrispondenza migliore. Questo evidenzia alcune delle limitazioni potenziali di un approccio di ricerca semantica.
Utilizzo di un modello open source
A titolo di interesse, vediamo come un modello open source si confronta con il nostro servizio OpenAI in questo contesto. Possiamo registrare un modello Hugging Face sentence transformer per questo scopo, come mostrato di seguito:
from semantic_kernel.connectors.ai.hugging_face import HuggingFaceTextEmbeddinghf_embedding_service = HuggingFaceTextEmbedding( "sentence-transformers/all-MiniLM-L6-v2", device=-1)kernel.add_text_embedding_generation_service( "hf_embedding_service", hf_embedding_service,)Per cambiare il nostro storage in memoria, possiamo utilizzare il seguente metodo.
kernel.use_memory(storage=memory_store, embeddings_generator=hf_embedding_service)Il metodo use_memory è un metodo di comodo, equivalente a chiamare kernel.register_memory(SemanticTextMemory(storage, embeddings_generator)). SemanticTextMemory contiene la logica per generare gli embeddings e gestirne lo storage.
Ora possiamo interrogarli allo stesso modo di prima.
for i, chunk in enumerate(chunks): await kernel.memory.save_information_async( "hf_London", id="chunk" + str(i), text=chunk )hf_results = await kernel.memory.search_async( "hf_London", "cosa dovrei mangiare a Londra", limit=2, min_relevance_score=0)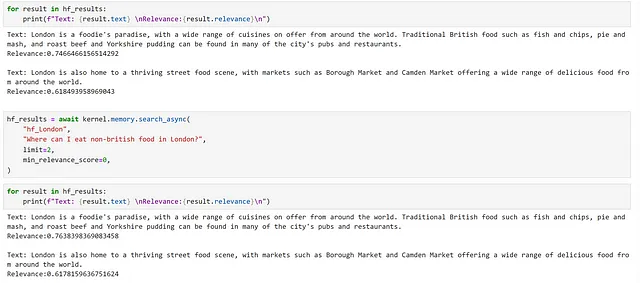
Possiamo vedere che abbiamo restituito gli stessi chunk, ma i nostri punteggi di rilevanza sono diversi. Possiamo anche osservare la differenza nelle dimensioni degli embeddings generati dai diversi modelli.

Integrazione della memoria nel contesto
Nel nostro esempio precedente, abbiamo visto che mentre potevamo identificare informazioni ampiamente rilevanti in base a una ricerca di embedding, per query più sottili non abbiamo ricevuto il risultato più rilevante. Esaminiamo se possiamo migliorare questa situazione.
Un modo per affrontare questo problema potrebbe essere fornire le informazioni pertinenti al nostro chatbot e lasciare che il modello decida quali parti sono le più rilevanti. Ancora una volta, definiamo una configurazione adatta a questo scopo.
chat_config_dict = { "schema": 1, # Il tipo di prompt "type": "completion", # Una descrizione di ciò che la funzione semantica fa "description": "Un chatbot che fornisce informazioni su città e paesi", # Specifica quali servizi di modello utilizzare "default_services": ["azure_gpt35_chat_completion"], # I parametri che verranno passati al connettore e al servizio di modello "completion": { "temperature": 0.0, "top_p": 1, "max_tokens": 500, "number_of_responses": 1, "presence_penalty": 0, "frequency_penalty": 0, }, # Definisce le variabili utilizzate all'interno del prompt "input": { "parameters": [ { "name": "question", "description": "La domanda posta dall'utente", "defaultValue": "", }, { "name": "context", "description": "Contesto contenente informazioni da utilizzare per rispondere alla domanda", "defaultValue": "", }, ] }, # Variabile non di schema "system_prompt": "Sei un chatbot che fornisce informazioni su diverse città e paesi. ",}Successivamente, creiamo un prompt che istruisca il modello a rispondere alla domanda in base al contesto fornito e registri una funzione semantica.
prompt_with_context = """ Utilizza i seguenti pezzi di contesto per rispondere alla domanda degli utenti. Queste sono le uniche informazioni che dovresti utilizzare per rispondere alla domanda, non fare riferimento a informazioni al di fuori di questo contesto. Se le informazioni necessarie per rispondere alla domanda non sono fornite nel contesto, semplicemente di' "Non so", non cercare di inventare una risposta. ---------------- Contesto: {{$context}} ---------------- Domanda dell'utente: {{$question}} ---------------- Risposta:"""chatbot_with_context = kernel.register_semantic_function( skill_name="ChatbotConContesto", function_name="chatbot_con_contesto", function_config=create_semantic_function_chat_config( prompt_with_context, chat_config_dict, kernel ),)Ora possiamo utilizzare questa funzione per rispondere alla nostra domanda più sottile. Prima creiamo un oggetto di contesto e aggiungiamo la nostra domanda a questo.
domanda = "Dove posso mangiare cibo non britannico a Londra?"contesto = kernel.create_new_context()contesto["question"] = domandaSuccessivamente, possiamo eseguire manualmente la nostra ricerca di embedding e aggiungere le informazioni recuperate al nostro contesto.
risultati = await kernel.memory.search_async("hf_Londra", domanda, limit=2)contesto["context"] = "\n".join([risultato.testo for risultato in risultati])Infine, possiamo eseguire la nostra funzione. Qui sto usando il kernel per eseguire la funzione, anziché invocarla direttamente; ciò può essere utile quando vogliamo eseguire più funzioni in sequenza.
risposta = await kernel.run_async(chatbot_with_context, input_vars=contesto.variables)
Plugin
Nota: Nelle versioni precedenti di Semantic Kernel, i plugin erano noti come ‘skill’; sono stati rinominati per mantenere la coerenza con Bing e OpenAI. Di conseguenza, molti riferimenti al codice e documentazione si riferiscono a ‘skill’.
Un plugin in Semantic Kernel è un gruppo di funzioni che possono essere caricate nel kernel per essere esposte alle app e ai servizi di intelligenza artificiale. Le funzioni all’interno dei plugin possono quindi essere orchestrare dal kernel per svolgere compiti specifici.
La documentazione descrive i plugin come i “mattoni” di Semantic Kernel, che possono essere collegati insieme per creare flussi di lavoro complessi; poiché i plugin seguono le specifiche dei plugin di OpenAI, i plugin creati per i servizi di OpenAI, Bing e Microsoft 365 possono essere utilizzati con Semantic Kernel.
Semantic Kernel fornisce diversi plugin integrati, tra cui:
- ConversationSummarySkill: Per riassumere una conversazione
- HttpSkill: Per chiamare API
- TextMemorySkill: Per memorizzare e recuperare testo in memoria
- TimeSkill: Per acquisire l’ora del giorno e altre informazioni temporali
Iniziamo esplorando come possiamo utilizzare un plugin predefinito, prima di passare ad investigare come possiamo creare plugin personalizzati.
Utilizzo di un plugin predefinito
Uno dei plugin inclusi in Semantic Kernel è TextMemorySkill, che fornisce funzionalità per salvare e richiamare informazioni dalla memoria. Vediamo come possiamo utilizzarlo per semplificare il nostro esempio precedente di popolare il contesto del prompt dalla memoria.
Prima di tutto, dobbiamo importare il nostro plugin, come mostrato di seguito.

Qui possiamo vedere che questo plugin contiene due funzioni semantiche, recall e save.
Ora, modifichiamo il nostro prompt:
prompt_with_context_plugin = """ Utilizza i seguenti elementi di contesto per rispondere alla domanda degli utenti. Queste sono le uniche informazioni che dovresti utilizzare per rispondere alla domanda, non fare riferimento ad informazioni al di fuori di questo contesto. Se le informazioni necessarie per rispondere alla domanda non sono fornite nel contesto, semplicemente di "Non lo so", non cercare di inventare una risposta. ---------------- Contesto: {{recall $question}} ---------------- Domanda dell'utente: {{$question}} ---------------- Risposta:"""Possiamo vedere che, per utilizzare la funzione recall, possiamo fare riferimento ad essa nel nostro prompt. Ora, creiamo una configurazione e registriamo una funzione.
chat_config_dict = { "schema": 1, # Il tipo di prompt "type": "completion", # Una descrizione di ciò che la funzione semantica fa "description": "Un chatbot che fornisce informazioni sulle città e sui paesi", # Specifica quali servizi modello utilizzare "default_services": ["azure_gpt35_chat_completion"], # I parametri che verranno passati al connettore e al servizio modello "completion": { "temperature": 0.0, "top_p": 1, "max_tokens": 500, "number_of_responses": 1, "presence_penalty": 0, "frequency_penalty": 0, }, # Definisce le variabili utilizzate all'interno del prompt "input": { "parameters": [ { "name": "question", "description": "La domanda posta dall'utente", "defaultValue": "", }, ] }, # Variabile non di schema "system_prompt": "Sei un chatbot che fornisce informazioni su diverse città e paesi. ",}chatbot_with_context_plugin = kernel.register_semantic_function( skill_name="ChatbotWithContextPlugin", function_name="chatbot_with_context_plugin", function_config=create_semantic_function_chat_config( prompt_with_context_plugin, chat_config_dict, kernel ),)Nel nostro esempio manuale, siamo stati in grado di controllare aspetti come il numero di risultati restituiti e la collezione da cercare. Quando si utilizza TextMemorySkill, possiamo impostare questi aggiungendoli al nostro contesto. Proviamo la nostra funzione.
question = "Dove posso mangiare cibo non britannico a Londra?"context = kernel.create_new_context()context["question"] = questioncontext[sk.core_skills.TextMemorySkill.COLLECTION_PARAM] = "hf_London"context[sk.core_skills.TextMemorySkill.RELEVANCE_PARAM] = 0.2context[sk.core_skills.TextMemorySkill.LIMIT_PARAM] = 2answer = await kernel.run_async( chatbot_with_context_plugin, input_vars=context.variables)
Possiamo vedere che questo è equivalente al nostro approccio manuale.
Creazione di plugin personalizzati
Ora che comprendiamo come creare funzioni semantiche e come utilizzare i plugin, abbiamo tutto ciò che serve per iniziare a creare i nostri plugin personalizzati!
I plugin possono contenere due tipi di funzioni:
- Funzioni semantiche: utilizzano il linguaggio naturale per eseguire azioni
- Funzioni native: utilizzano il codice Python per eseguire azioni
che possono essere combinati all’interno di un singolo plugin.
La scelta tra utilizzare una funzione semantica o una funzione nativa dipende dal compito che si sta svolgendo. Per compiti che coinvolgono la comprensione o la generazione di linguaggio, le funzioni semantiche sono la scelta ovvia. Tuttavia, per compiti più deterministici, come l’esecuzione di operazioni matematiche, il download di dati o l’accesso all’ora, le funzioni native sono più adatte.
Esploriamo come possiamo creare ciascun tipo. Per prima cosa, creiamo una cartella per memorizzare i nostri plugin.
from pathlib import Pathplugins_path = Path("Plugins")plugins_path.mkdir(exist_ok=True)Creazione di un plugin generatore di poesie
Per il nostro esempio, creiamo un plugin che genera poesie; per questo, utilizzare una funzione semantica sembra una scelta naturale. Possiamo creare una cartella per questo plugin nella nostra directory.
poem_gen_plugin_path = plugins_path / "PoemGeneratorPlugin"poem_gen_plugin_path.mkdir(exist_ok=True)Ricordando che i plugin sono solo una collezione di funzioni, e stiamo creando una funzione semantica, la parte successiva dovrebbe essere abbastanza familiare. La differenza chiave è che, anziché definire il nostro prompt e la configurazione inline, creeremo file individuali per questi; per renderne più facile il caricamento.
Creiamo una cartella per la nostra funzione semantica, che chiameremo write_poem.
poem_sc_path = poem_gen_plugin_path / "write_poem"poem_sc_path.mkdir(exist_ok=True)Successivamente, creiamo il nostro prompt, salvandolo come skprompt.txt.
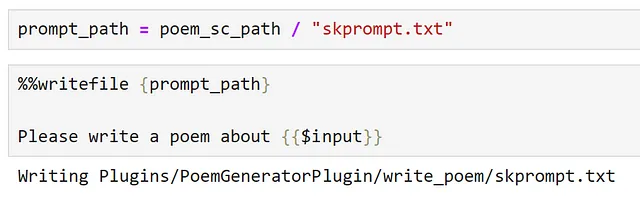
Ora creiamo la nostra configurazione e la salviamo in un file json.
Anche se è sempre una buona prassi impostare descrizioni significative nella nostra configurazione, ciò diventa più importante quando definiamo plugin; i plugin dovrebbero fornire descrizioni chiare che descrivano il loro comportamento, quali sono i loro input e output e quali sono i loro effetti collaterali. La ragione per questo è che questa è l’interfaccia presentata dal nostro kernel e, se vogliamo essere in grado di utilizzare un LLM per orchestrare attività, deve essere in grado di comprendere la funzionalità del plugin e come chiamarlo in modo da poter selezionare funzioni appropriate.
config_path = poem_sc_path / "config.json"
%%writefile {config_path}{ "schema": 1, "type": "completion", "description": "Un generatore di poesie, che scrive una breve poesia basata sull'input dell'utente", "default_services": ["azure_gpt35_chat_completion"], "completion": { "temperature": 0.0, "top_p": 1, "max_tokens": 250, "number_of_responses": 1, "presence_penalty": 0, "frequency_penalty": 0 }, "input": { "parameters": [{ "name": "input", "description": "L'argomento su cui deve essere scritta la poesia", "defaultValue": "" }] }}Nota che, poiché salviamo la nostra configurazione come file JSON, dobbiamo rimuovere i commenti per renderlo valido JSON.
Ora siamo in grado di importare il nostro plugin:
poem_gen_plugin = kernel.import_semantic_skill_from_directory( plugins_path, "PoemGeneratorPlugin")Ispezionando il nostro plugin, possiamo vedere che espone la nostra funzione semantica write_poem.

Possiamo chiamare direttamente la nostra funzione semantica:
result = poem_gen_plugin["write_poem"]("Monaco")
o possiamo utilizzarla in un’altra funzione semantica:
chat_config_dict = { "schema": 1, # Il tipo di prompt "type": "completion", # Una descrizione di ciò che fa la funzione semantica "description": "Avvolge un plugin per scrivere una poesia", # Specifica quale/i servizio/i del modello utilizzare "default_services": ["azure_gpt35_chat_completion"], # I parametri che verranno passati al connettore e al servizio del modello "completion": { "temperature": 0.0, "top_p": 1, "max_tokens": 500, "number_of_responses": 1, "presence_penalty": 0, "frequency_penalty": 0, }, # Definisce le variabili utilizzate all'interno del prompt "input": { "parameters": [ { "name": "input", "description": "L'input fornito dall'utente", "defaultValue": "", }, ] },}prompt = """{{PoemGeneratorPlugin.write_poem $input}}"""write_poem_wrapper = kernel.register_semantic_function( skill_name="PoemWrapper", function_name="poem_wrapper", function_config=create_semantic_function_chat_config( prompt, chat_config_dict, kernel ),)result = write_poem_wrapper("Monaco")
Creazione di un plugin per la classificazione delle immagini
Ora che abbiamo visto come utilizzare una funzione semantica in un plugin, diamo un’occhiata a come possiamo utilizzare una funzione nativa.
Qui, creiamo un plugin che prende un URL di un’immagine, la scarica e la classifica. Ancora una volta, creiamo una cartella per il nostro nuovo plugin.
image_classifier_plugin_path = plugins_path / "ImageClassifierPlugin"image_classifier_plugin_path.mkdir(exist_ok=True)download_image_sc_path = image_classifier_plugin_path / "download_image.py"download_image_sc_path.mkdir(exist_ok=True)Ora possiamo creare il nostro modulo Python. All’interno del modulo possiamo essere abbastanza flessibili. Qui, abbiamo creato una classe con due metodi, il passaggio chiave è utilizzare il decoratore sk_function per specificare quali metodi devono essere esposti come parte del plugin.
In questo esempio, la nostra funzione richiede solo un input. Per le funzioni che richiedono input multipli, può essere utilizzato il parametro sk_function_context_parameter, come dimostrato nella documentazione.
import requestsfrom PIL import Imageimport timmfrom timm.data.imagenet_info import ImageNetInfofrom semantic_kernel.skill_definition import ( sk_function,)from semantic_kernel.orchestration.sk_context import SKContextclass ImageClassifierPlugin: def __init__(self): self.model = timm.create_model("convnext_tiny.in12k_ft_in1k", pretrained=True) self.model.eval() data_config = timm.data.resolve_model_data_config(self.model) self.transforms = timm.data.create_transform(**data_config, is_training=False) self.imagenet_info = ImageNetInfo() @sk_function( description="Prende un URL come input e classifica l'immagine", name="classify_image", input_description="L'URL dell'immagine da classificare", ) def classify_image(self, url: str) -> str: image = self.download_image(url) pred = self.model(self.transforms(image)[None]) return self.imagenet_info.index_to_description(pred.argmax()) def download_image(self, url): return Image.open(requests.get(url, stream=True).raw).convert("RGB")Per questo esempio, ho utilizzato l’eccellente libreria Pytorch Image Models per fornire il nostro classificatore. Per ulteriori informazioni su come funziona questa libreria, consulta questo post sul blog.
Ora, possiamo semplicemente importare il nostro plugin come mostrato di seguito.
image_classifier = ImageClassifierPlugin()classify_plugin = kernel.import_skill(image_classifier, skill_name="classify_image")Ispezionando il nostro plugin, possiamo vedere che solo la nostra funzione decorata è esposta.
Possiamo verificare che il nostro plugin funzioni utilizzando un’immagine di un gatto da Pixabay.

url = "https://cdn.pixabay.com/photo/2016/02/10/16/37/cat-1192026_1280.jpg"response = classify_plugin["classify_image"](url)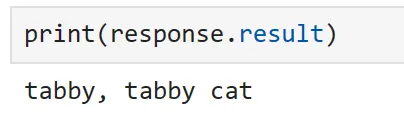
Chiamando manualmente la nostra funzione, possiamo vedere che la nostra immagine è stata classificata correttamente! Nello stesso modo di prima, potremmo anche fare riferimento direttamente a questa funzione da un prompt. Tuttavia, poiché abbiamo già dimostrato questo, proviamo qualcosa di leggermente diverso nella sezione seguente.
Concatenazione di più plugin
È anche possibile concatenare più plugin utilizzando il kernel, come mostrato di seguito.
context = kernel.create_new_context()context["input"] = urlanswer = await kernel.run_async( classify_plugin["classify_image"], poem_gen_plugin["write_poem"], input_context=context,)
Possiamo vedere che, utilizzando entrambi i plugin sequenzialmente, abbiamo classificato l’immagine e scritto una poesia su di essa!
Orchestrazione di flussi di lavoro con un Planner
A questo punto, abbiamo esplorato approfonditamente le funzioni semantiche, capito come le funzioni possono essere raggruppate e utilizzate come parte di un plugin e visto come possiamo concatenare manualmente i plugin. Ora, esploriamo come possiamo creare e orchestrare flussi di lavoro utilizzando LLMs. Per fare ciò, Semantic Kernel fornisce oggetti Planner, che possono creare dinamicamente catene di funzioni per cercare di raggiungere un obiettivo.
Un planner è una classe che prende un prompt dell’utente e un kernel, e utilizza i servizi del kernel per creare un piano su come eseguire il compito, utilizzando le funzioni e i plugin resi disponibili al kernel. Poiché i plugin sono i principali blocchi di costruzione di questi piani, il planner si basa pesantemente sulle descrizioni fornite; se i plugin e le funzioni non hanno descrizioni chiare, il planner non sarà in grado di utilizzarli correttamente. Inoltre, poiché un planner può combinare le funzioni in modi diversi, è importante assicurarsi di esporre solo le funzioni che ci soddisfano che il planner utilizzi.
Poiché il planner si basa su un modello per generare un piano, possono essere introdotti degli errori; questi si verificano di solito quando il planner non comprende correttamente come utilizzare la funzione. In questi casi, ho riscontrato che fornire istruzioni esplicite – come descrivere gli input e gli output e indicare se gli input sono richiesti – nelle descrizioni può portare a risultati migliori. Inoltre, ho ottenuto risultati migliori utilizzando modelli sintonizzati con le istruzioni rispetto ai modelli di base; i modelli di completamento del testo di base tendono ad immaginare funzioni che non esistono o creare piani multipli. Nonostante queste limitazioni, quando tutto funziona correttamente, i planner possono essere incredibilmente potenti!
Esploriamo come possiamo fare ciò esplorando se possiamo creare un piano per scrivere una poesia su un’immagine, basandoci sul suo URL; utilizzando i plugin che abbiamo creato in precedenza. Poiché abbiamo definito molte funzioni di cui non abbiamo più bisogno, creiamo un nuovo kernel, in modo da poter controllare quali funzioni sono esposte.
kernel = sk.Kernel()Per creare il nostro piano, utilizziamo il nostro servizio di chat OpenAI.
kernel.add_chat_service( service_id="azure_gpt35_chat_completion", service=AzureChatCompletion( OPENAI_DEPLOYMENT_NAME, OPENAI_ENDPOINT, OPENAI_API_KEY ),)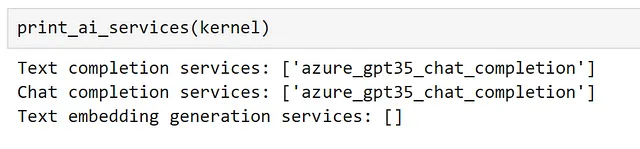
Ispettando i nostri servizi registrati, possiamo vedere che il nostro servizio può essere utilizzato sia per il completamento del testo che per le conversazioni.
Ora, importiamo i nostri plugin.
classify_plugin = kernel.import_skill( ImageClassifierPlugin(), skill_name="classify_image")poem_gen_plugin = kernel.import_semantic_skill_from_directory( plugins_path, "PoemGeneratorPlugin")Possiamo vedere a quali funzioni ha accesso il nostro kernel, come mostrato di seguito.

Ora, importiamo il nostro oggetto planner.
from semantic_kernel.planning.basic_planner import BasicPlannerplanner = BasicPlanner()Per utilizzare il nostro planner, tutto ciò di cui abbiamo bisogno è un prompt. Spesso, dovremo modificare questo a seconda dei piani che vengono generati. Qui, ho cercato di essere il più esplicito possibile sull’input richiesto.
ask = f"""Vorrei che tu scrivessi una poesia su ciò che è contenuto in questa immagine con questo URL: {url}. Questo URL dovrebbe essere utilizzato come input."""Successivamente, possiamo utilizzare il nostro planner per creare un piano su come risolverà il compito.
plan = await planner.create_plan_async(ask, kernel)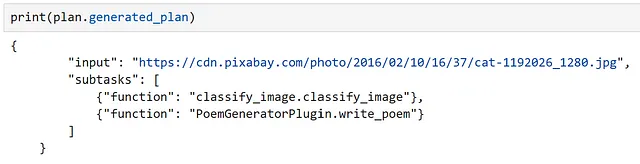
Ispezionando il nostro piano, possiamo vedere che il modello ha correttamente identificato il nostro input e le funzioni corrette da utilizzare!
Infine, tutto ciò che resta da fare è eseguire il nostro piano.
poem = await planner.execute_plan_async(plan, kernel)
Wow, ha funzionato! Per un modello addestrato a prevedere la parola successiva, questo è abbastanza potente!
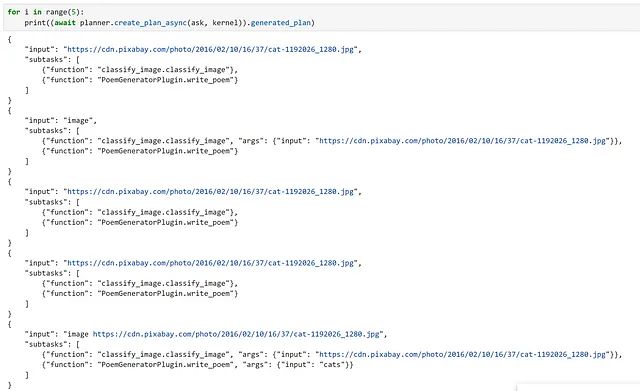
Come avvertimento, sono stato molto fortunato a fare questo esempio che il piano generato abbia funzionato al primo tentativo. Tuttavia, eseguendo questo più volte con la stessa richiesta, possiamo vedere che questo non è sempre il caso, quindi è importante controllare due volte il piano prima di eseguirlo! Per me personalmente, in un sistema di produzione, mi sentirei molto più a mio agio a creare manualmente il flusso di lavoro da eseguire, piuttosto che lasciarlo al LLM! Con il miglioramento continuo della tecnologia, soprattutto al ritmo attuale, speriamo che questa raccomandazione diventi obsoleta!
Conclusioni
Speriamo che questo abbia fornito una buona introduzione a Semantic Kernel e che ti abbia ispirato ad esplorarne l’uso per i tuoi casi d’uso.
Tutto il codice necessario per replicare questo post è disponibile come notebook qui.
Chris Hughes è su LinkedIn
Riferimenti
- Introducing ChatGPT (openai.com)
- microsoft/semantic-kernel: Integra rapidamente e facilmente tecnologia LLM all’avanguardia nelle tue app (github.com)
- Chi Siamo — Microsoft Solutions Playbook
- kernel — Wiktionary, il dizionario libero
- Panoramica — OpenAI API
- Servizio Azure OpenAI — Modelli di linguaggio avanzati | Microsoft Azure
- Documentazione di Hugging Face Hub
- Modelli del servizio Azure OpenAI — Azure OpenAI | Microsoft Learn
- Crea il tuo account gratuito Azure oggi stesso | Microsoft Azure
- Come utilizzare il linguaggio del modello di prompt in Semantic Kernel | Microsoft Learn
- asyncio — I/O asincrono — Documentazione di Python 3.11.5
- 🤗 Transformers (huggingface.co)
- gpt2 · Hugging Face
- explosion/curated-transformers: 🤖 Una libreria PyTorch di modelli di Transformer selezionati e dei loro componenti componibili (github.com)
- tiiuae/falcon-7b · Hugging Face
- ND A100 v4-series — Macchine virtuali Azure | Microsoft Learn
- [2203.02155] Addestrare modelli di linguaggio per seguire le istruzioni con feedback umano (arxiv.org)
- Modelli del servizio Azure OpenAI — Azure OpenAI | Microsoft Learn
- Modello di embedding nuovo e migliorato (openai.com)
- Introduzione — Azure Cosmos DB | Microsoft Learn
- PostgreSQL: Il database open source più avanzato al mondo
- sentence-transformers/all-MiniLM-L6-v2 · Hugging Face
- Comprensione dei plugin AI in Semantic Kernel e oltre | Microsoft Learn
- Plugin disponibili out-of-the-box in Semantic Kernel | Microsoft Learn
- Come aggiungere codice nativo alle tue app AI con Semantic Kernel | Microsoft Learn
- huggingface/pytorch-image-models: Modelli di immagini PyTorch, script, pesi preaddestrati — ResNet, ResNeXT, EfficientNet, NFNet, Vision Transformer (ViT), MobileNet-V3/V2, RegNet, DPN, CSPNet, Swin Transformer, MaxViT, CoAtNet, ConvNeXt e altro ancora (github.com)
- Guida per iniziare con PyTorch Image Models (timm): Una guida per i professionisti | di Chris Hughes | Towards Data Science



