Cinque Applicazioni Pratiche del Modello LSTM per Serie Temporali, con Codice
5 Practical Applications of LSTM Model for Time Series, with Code
Come implementare un modello di reti neurali avanzato in diversi contesti di serie storiche
Quando ho scritto Esplorazione del modello di rete neurale LSTM per serie storiche a gennaio 2022, il mio obiettivo era mostrare quanto fosse facile implementare il modello di rete neurale avanzato in Python utilizzando scalecast, una libreria di serie storiche che ho sviluppato per facilitare il mio lavoro e i miei progetti. Non pensavo che sarebbe stato visualizzato oltre decine di migliaia di volte e comparisse come primo risultato su Google quando si cercava “lstm forecasting python” per oltre un anno dopo la pubblicazione (quando ho controllato oggi, era ancora al secondo posto).
Non ho cercato di attirare molta attenzione su quell’articolo perché non ho mai pensato, e tuttora non penso, che sia molto buono. Non era mai stato concepito come una guida per implementare al meglio il modello LSTM, ma piuttosto come una semplice esplorazione della sua utilità per la previsione di serie storiche. Ho cercato di rispondere a domande come: cosa succede quando si esegue il modello con i parametri predefiniti, cosa succede quando si regolano i parametri in questo modo o in quello, quanto facilmente può essere battuto da altri modelli su determinati set di dati, ecc. Tuttavia, a giudicare dagli articoli del blog, dai notebook di Kaggle e persino dal corso Udemy che continuo a vedere con il codice copiato integralmente da quell’articolo, è chiaro che molte persone stavano prendendo l’articolo per il suo valore iniziale, non l’ultimo. Ora capisco che non ho chiarito chiaramente le mie intenzioni.
Oggi, per ampliare quell’articolo, voglio mostrare come si dovrebbe applicare il modello di rete neurale LSTM, o almeno come lo applicherei io, per realizzare appieno il suo valore per i problemi di previsione di serie storiche. Dopo la scrittura del primo articolo, siamo stati in grado di aggiungere molte nuove e innovative caratteristiche alla libreria scalecast che rendono l’utilizzo del modello LSTM molto più fluido e in questo spazio esplorerò alcune delle mie preferite. Ci sono cinque applicazioni per LSTM che penso funzioneranno tutte in modo fantastico utilizzando la libreria: previsione univariata, previsione multivariata, previsione probabilistica, previsione probabilistica dinamica e apprendimento di trasferimento.
Prima di iniziare, assicurarsi di eseguire da terminale o da linea di comando:
- I budget dell’IA aumentano di oltre l’80%, rivela il rapporto ABBYY sullo stato dell’automazione intelligente.
- XGBoost Come il Deep Learning può sostituire il Gradient Boosting e gli Alberi di Decisione – Parte 2 Addestramento
- Provocatoriamente, i ricercatori di Microsoft affermano di aver trovato scintille di intelligenza artificiale in GPT-4.
pip install --upgrade scalecastIl notebook completo sviluppato per questo articolo si trova qui.
Un’ultima nota: in ogni esempio, potrei utilizzare i termini “RNN” e “LSTM” in modo intercambiabile. In alternativa, RNN può essere visualizzato su un grafico di una previsione LSTM. La rete neurale a memoria a breve termine (LSTM) è un tipo di rete neurale ricorrente (RNN) con parametri aggiuntivi legati alla memoria. In scalecast, la classe del modello rnn può essere utilizzata per adattare sia celle RNN semplici che celle LSTM in modelli portati da tensorflow.
1. Previsione univariata
Il modo più comune e più ovvio per utilizzare il modello LSTM è quando si affronta un semplice problema di previsione univariata. Sebbene il modello si adatti a molti parametri che dovrebbero renderlo sufficientemente sofisticato per apprendere tendenze, stagionalità e dinamiche a breve termine in qualsiasi serie storica, ho scoperto che funziona molto meglio con dati stazionari (dati che non mostrano tendenze o stagionalità). Quindi, con il dataset dei passeggeri aerei – disponibile su Kaggle con una licenza Open Database – possiamo facilmente creare una previsione accurata e affidabile utilizzando iperparametri piuttosto semplici, semplicemente applicando una trasformazione per rimuovere la tendenza e la stagionalità:
transformer = Transformer( transformers = [ ('DetrendTransform',{'poly_order':2}), 'DeseasonTransform', ],)Vogliamo anche assicurarci di ripristinare i risultati al loro livello originale quando abbiamo finito:
reverter = Reverter( reverters = [ 'DeseasonRevert', 'DetrendRevert', ], base_transformer = transformer,)Ora possiamo specificare i parametri della rete. Per questo esempio, utilizzeremo 18 ritardi, un solo strato, una funzione di attivazione tangente iperbolica e 200 epoche. Sentiti libero di esplorare i tuoi parametri migliori!
def forecaster(f): f.set_estimator('rnn') f.manual_forecast( lags = 18, layers_struct = [ ('LSTM',{'units':36,'activation':'tanh'}), ], epochs=200, call_me = 'lstm', )Combina tutto in un pipeline, esegui il modello e visualizza i risultati in modo visuale:
pipeline = Pipeline( steps = [ ('Transform',transformer), ('Forecast',forecaster), ('Revert',reverter), ])f = pipeline.fit_predict(f)f.plot()plt.show()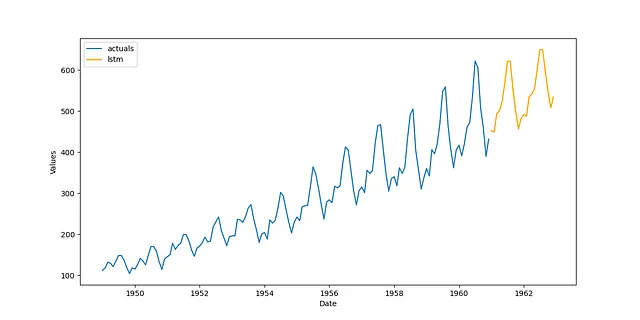
Abbastanza buono e molto meglio di quanto ho dimostrato nell’altro articolo. Per estendere questa applicazione, puoi provare a utilizzare diversi ordini di ritardo, aggiungere la stagionalità al modello sotto forma di termini di Fourier, trovare migliori trasformazioni delle serie e tarare gli iperparametri del modello con la cross-validazione. Alcuni di questi aspetti saranno dimostrati nelle sezioni successive.
2. Previsione multivariata
Supponiamo di avere due serie che ci aspettiamo si muovano insieme. Possiamo creare un modello LSTM che tenga conto di entrambe le serie quando effettua previsioni con la speranza di migliorare l’accuratezza complessiva del modello. Questa è, naturalmente, una previsione multivariata.
In questo esempio, userò il dataset degli Avocado, disponibile su Kaggle con una licenza Open Database. Misura il prezzo e la quantità venduta di avocado su base settimanale in diverse regioni degli Stati Uniti. Sappiamo dalla teoria economica che il prezzo e la domanda sono strettamente correlati, quindi utilizzando il prezzo come indicatore principale, potremmo essere in grado di prevedere in modo più accurato la quantità di avocado venduta rispetto all’utilizzo della sola domanda storica in un contesto univariato.
La prima cosa che faremo è trasformare ciascuna serie. Possiamo cercare un insieme “ottimale” di trasformazioni (cioè trasformazioni che sono valutate fuori campione) eseguendo il seguente codice:
data = pd.read_csv('avocado.csv')# demandvol = data.groupby('Date')['Total Volume'].sum()# priceprice = data.groupby('Date')['AveragePrice'].sum()fvol = Forecaster( y = vol, current_dates = vol.index, test_length = 13, validation_length = 13, future_dates = 13, metrics = ['rmse','r2'],)transformer, reverter = find_optimal_transformation( fvol, set_aside_test_set=True, # previene la contaminazione per poter valutare in modo imparziale i modelli risultanti return_train_only = True, # previene la contaminazione per poter valutare in modo imparziale i modelli risultanti verbose=True, detrend_kwargs=[ {'loess':True}, {'poly_order':1}, {'ln_trend':True}, ], m = 52, # cosa fa un ciclo stagionale? test_length = 4,)La trasformazione consigliata da questo processo è un’aggiustamento stagionale, assumendo che 52 periodi facciano una stagione, così come una scala robusta (una scala robusta agli outlier). Possiamo quindi adattare quella trasformazione alla serie e chiamare un modello LSTM univariato per confrontare il modello multivariato. Questa volta, useremo un processo di taratura degli iperparametri generando una griglia di possibili funzioni di attivazione, dimensioni dei layer e valori di dropout:
rnn_grid = gen_rnn_grid( layer_tries = 10, min_layer_size = 3, max_layer_size = 5, units_pool = [100], epochs = [25,50], dropout_pool = [0,0.05], callbacks=EarlyStopping( monitor='val_loss', patience=3, ), random_seed = 20,) # crea una griglia di valori iperparametrici per tarare il modello LSTMQuesta funzione fornisce un modo efficace per inserire una griglia gestibile nel nostro oggetto ma con abbastanza casualità per avere una buona selezione di parametri tra cui scegliere. Ora adattiamo il modello univariato:
fvol.add_ar_terms(13) # il modello utilizzerà 13 ritardi delle seriefvol.set_estimator('rnn')fvol.ingest_grid(rnn_grid)fvol.tune() # utilizza un set di validazione di 13 periodifvol.auto_forecast(call_me='lstm_univariato')Per estendere ciò in un contesto multivariato, possiamo trasformare la serie temporale del prezzo con lo stesso insieme di trasformazioni utilizzate per l’altra serie. Quindi, inseriamo 13 ritardi del prezzo nell’oggetto Forecaster e adattiamo un nuovo modello LSTM:
fprice = Forecaster( y = price, current_dates = price.index, future_dates = 13,)fprice = transformer.fit_transform(fprice)fvol.add_series(fprice.y,called='prezzo')fvol.add_lagged_terms('prezzo',lags=13,drop=True)fvol.ingest_grid(rnn_grid)fvol.tune()fvol.auto_forecast(call_me='lstm_multivariato')Possiamo anche confrontare un modello ingenuo e tracciare i risultati a livello della serie originale, insieme al set di test fuori campione:
# previsione ingenua per il benchmarkfvol.set_estimator('ingenuo')fvol.manual_forecast()fvol = reverter.fit_transform(fvol)fvol.plot_test_set(order_by='TestSetRMSE')plt.show()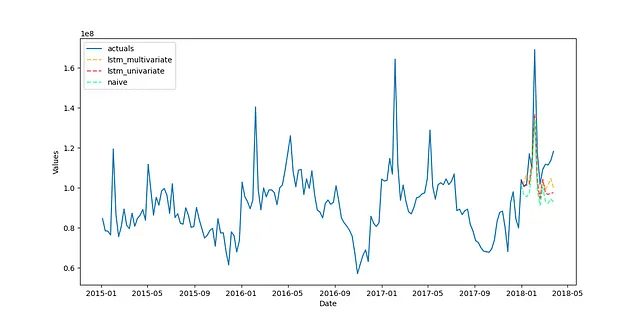
Dal modo in cui tutti e tre i modelli si sono raggruppati insieme visivamente, la maggior parte dell’accuratezza in questa particolare serie è stata ottenuta grazie alle trasformazioni applicate: è così che il modello ingenuo è risultato così comparabile ai modelli LSTM. Tuttavia, i modelli LSTM rappresentano un miglioramento, con il modello multivariato che ha ottenuto un punteggio di 38.37% per l’indice di varianza spiegata (r-squared) e il modello univariato che ha ottenuto un punteggio di 26.35%, rispetto alla base di -6.46%.
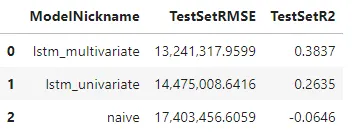
Una delle cose che potrebbe aver impedito ai modelli LSTM di ottenere risultati migliori in questa serie è la sua brevità. Con soli 169 osservazioni, potrebbe non esserci abbastanza storia per il modello per imparare sufficientemente i pattern. Tuttavia, qualsiasi miglioramento rispetto a un modello ingenuo o semplice può essere considerato un successo.
3. Previsione probabilistica
La previsione probabilistica si riferisce alla capacità di un modello di fornire non solo previsioni puntuali, ma anche stime di quanto le previsioni potrebbero deviare in entrambe le direzioni. La previsione probabilistica è simile alla previsione con intervalli di confidenza, un concetto che esiste da molto tempo. Un modo emergente per produrre previsioni probabilistiche consiste nell’applicare un intervallo di confidenza conforme al modello, utilizzando un set di calibrazione per determinare la probabile dispersione dei punti futuri effettivi. Questo approccio ha il vantaggio di poter essere applicato a qualsiasi modello di apprendimento automatico, indipendentemente dalle assunzioni che il modello fa sulla distribuzione dei suoi input o dei suoi residui. Fornisce inoltre determinate garanzie di copertura che sono estremamente utili per qualsiasi professionista di machine learning. Possiamo applicare l’intervallo di confidenza conforme al modello LSTM per produrre previsioni probabilistiche.
Per questo esempio, utilizzeremo il dataset degli inizi delle costruzioni residenziali mensili disponibile su FRED, un database open source di serie temporali economiche. Utilizzerò i dati da gennaio 1959 a dicembre 2022 (768 osservazioni). Per prima cosa, cercheremo nuovamente l’insieme ottimale di trasformazioni, ma questa volta utilizzando un modello LSTM con 10 epoche per valutare ogni tentativo di trasformazione:
trasformatore, revertitore = find_optimal_transformation( f, estimatore = 'lstm', epoche = 10, test_set_ignorato=True, # evita il leakage per poter confrontare in modo equo i modelli risultanti ritorna_solo_allenamento=True, # evita il leakage per poter confrontare in modo equo i modelli risultanti verbose=True, m = 52, # cosa rappresenta un ciclo stagionale? lunghezza_test = 24, numero_set_test = 3, spazio_tra_set = 12, detrend_kwargs=[ {'loess':True}, {'poly_order':1}, {'ln_trend':True}, ],)Creeremo di nuovo casualmente una griglia di iperparametri, ma questa volta possiamo renderne lo spazio di ricerca molto ampio, per poi limitarlo manualmente a 10 tentativi quando il modello viene addestrato successivamente, in modo da poter validare incrociatamente i parametri in un tempo ragionevole:
rnn_grid = gen_rnn_grid( tentativi_strato = 100, dimensione_minima_strato = 1, dimensione_massima_strato = 5, units_pool = [100], epoche = [100], dropout_pool = [0,0.05], validation_split=.2, callbacks=EarlyStopping( monitor='val_loss', patience=3, ), random_seed = 20,) # crea una griglia molto grande e limitala manualmenteOra possiamo costruire e addestrare il pipeline:
def previsionista(f,griglia): f.auto_Xvar_select( try_trend=False, try_seasonalities=False, max_ar=100 ) f.set_estimator('rnn') f.ingest_grid(griglia) f.limit_grid_size(10) # riduci casualmente la griglia grande a 10 f.cross_validate(k=3,lunghezza_test=24) # validazione incrociata a tre fold f.auto_forecast()pipeline = Pipeline( steps = [ ('Transform',trasformatore), ('Forecast',previsionista), ('Revert',revertitore), ])f = pipeline.fit_predict(f,griglia=rnn_grid)Perché abbiamo messo da parte un set di test di dimensioni sufficienti nell’oggetto Forecaster, i risultati ci forniscono automaticamente le distribuzioni probabilistiche al 90% per ogni stima:
f.plot(ci=True)plt.show()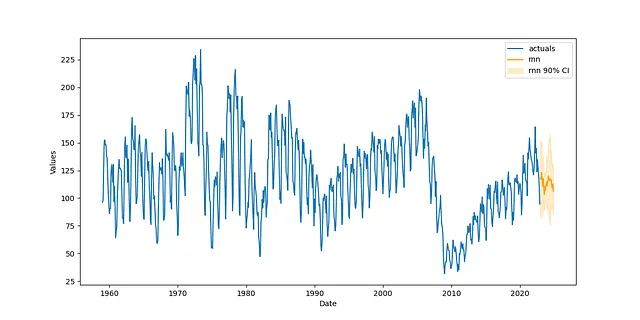
4. Previsione probabilistica dinamica
Gli esempi precedenti forniscono una previsione probabilistica statica, in cui ogni limite superiore e inferiore lungo la previsione è equidistante dalla stima puntata come qualsiasi altro limite superiore e inferiore collegato a qualsiasi altro punto. Quando si prevede il futuro, è intuitivo che più ci si spinge nella previsione, più l’errore si disperderà – un dettaglio non catturato con l’intervallo statico. C’è un modo per ottenere una previsione probabilistica più dinamica con il modello LSTM utilizzando il backtesting.
Il backtesting è il processo di refitting iterativo del modello, prevedendolo su diversi orizzonti di previsione e testandone le prestazioni in ogni iterazione. Prendiamo il pipeline specificato nell’ultimo esempio e testiamolo 10 volte. Abbiamo bisogno di almeno 10 iterazioni di backtest per costruire intervalli di confidenza al livello del 90%:
backtest_results = backtest_for_resid_matrix( f, pipeline=pipeline, alpha = .1, jump_back = 12, params = f.best_params,)backtest_resid_matrix = get_backtest_resid_matrix(backtest_results)Possiamo analizzare i valori assoluti dei residui in ogni iterazione visivamente:
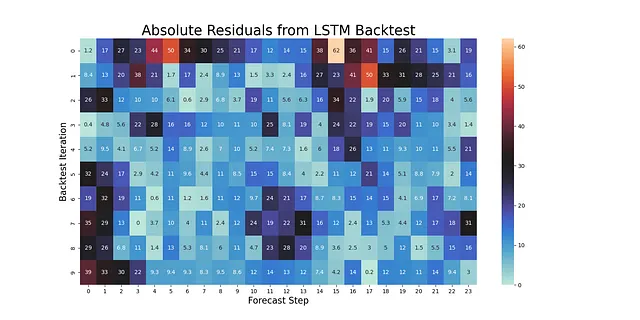
Ciò che è interessante in questo particolare esempio è che gli errori più grandi di solito non si verificano negli ultimi passaggi della previsione, ma effettivamente nei passaggi 14-17. Questo può accadere con serie che hanno modelli stagionali dispari. La presenza di outlier può anche influenzare questo pattern. In ogni caso, possiamo utilizzare questi risultati per ora sostituire gli intervalli di confidenza statici con intervalli dinamici conformi ad ogni passaggio:
overwrite_forecast_intervals( f, backtest_resid_matrix=backtest_resid_matrix, alpha=.1, # intervalli al 90% f.plot(ci=True)plt.show()5. Trasferimento di apprendimento
Il trasferimento di apprendimento è utile quando desideriamo utilizzare un modello al di fuori del contesto in cui è stato addestrato. Ci sono due scenari specifici in cui dimostrerò la sua utilità: fare previsioni quando sono disponibili nuovi dati in una determinata serie temporale e fare previsioni su una serie temporale correlata con tendenze e stagionalità simili.
Scenario 1: Nuovi dati dalla stessa serie
Possiamo utilizzare lo stesso dataset immobiliare degli ultimi due esempi, ma diciamo che è passato del tempo e ora abbiamo dati disponibili fino a giugno 2023.
df = pdr.get_data_fred( 'CANWSCNDW01STSAM', start = '2010-01-01', end = '2023-06-30',)f_new = Forecaster( y = df.iloc[:,0], current_dates = df.index, future_dates = 24, # orizzonte di previsione di 2 anni)Rifaremo il nostro pipeline con le stesse trasformazioni, ma questa volta useremo una previsione di trasferimento invece della procedura di previsione di scala normale, che adatta anche il modello:
def transfer_forecast(f_new,transfer_from): f_new = infer_apply_Xvar_selection(infer_from=transfer_from,apply_to=f_new) f_new.transfer_predict(transfer_from=transfer_from,model='rnn',model_type='tf')pipeline_can = Pipeline( steps = [ ('Trasforma',transformer), ('Previsione di trasferimento',transfer_forecast), ('Riporta',reverter), ])f_new = pipeline_can.fit_predict(f_new,transfer_from=f)Anche se il nome della funzione rilevante è ancora fit_predict(), in realtà non c’è alcun fitting e solo la previsione nella pipeline come è scritta. Questo riduce notevolmente il tempo necessario per riadattare e riottimizzare un modello. Visualizziamo quindi i risultati:
f_new.plot()plt.show('Previsione iniziale degli alloggi fino a giugno 2023')plt.show()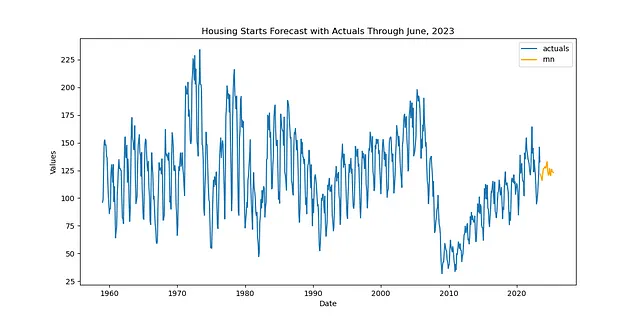
Scenario 2: Un nuovo time series con caratteristiche simili
Per il secondo scenario, possiamo utilizzare la situazione ipotetica di voler utilizzare il modello addestrato sulle dinamiche degli alloggi negli Stati Uniti per prevedere l’inizio degli alloggi in Canada. Avviso: non so se questa sia effettivamente una buona idea — è solo uno scenario che ho pensato per dimostrare come sarebbe fatto. Ma immagino che potrebbe essere utile e il codice coinvolto può essere trasferito ad altre situazioni (forse per situazioni in cui si dispone di serie brevi che presentano dinamiche simili a una serie più lunga a cui si è già adattato un modello ben performante). In quel caso, il codice è in realtà esattamente lo stesso del codice del Scenario 1; l’unica differenza è il dato che carichiamo nell’oggetto:
df = pdr.get_data_fred( 'CANWSCNDW01STSAM', start = '2010-01-01', end = '2023-06-30',)f_new = Forecaster( y = df.iloc[:,0], current_dates = df.index, future_dates = 24, # orizzonte di previsione di 2 anni)def trasferisci_previsione(f_new,trasferisci_da): f_new = infer_apply_Xvar_selection(infer_from=trasferisci_da,apply_to=f_new) f_new.transfer_predict(transfer_from=trasferisci_da,model='rnn',model_type='tf')pipeline_can = Pipeline( steps = [ ('Trasforma',trasformatore), ('Trasferisci Previsione',trasferisci_previsione), ('Ripristina',ripristinatore), ])f_new = pipeline_can.fit_predict(f_new,transfer_from=f)f_new.plot()plt.show('Previsione degli Alloggi in Canada')plt.show()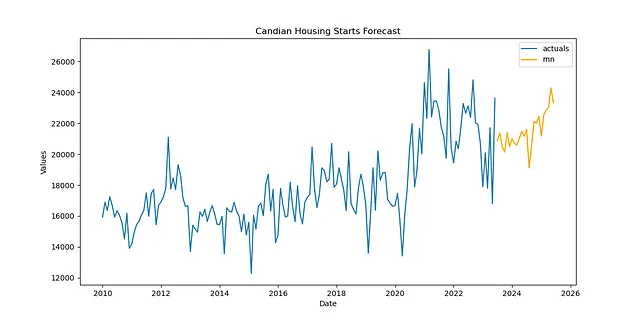
Credo che la previsione sembri abbastanza realistica per poter essere una interessante applicazione del trasferimento di apprendimento LSTM.
Conclusione
Per molti casi d’uso di previsione, il modello LSTM può essere una soluzione interessante. In questo post, ho dimostrato come applicare il modello LSTM per cinque scopi diversi con il codice Python. Se ti è stato utile, dai una stella a scalecast su GitHub e assicurati di seguirmi qui su VoAGI per essere aggiornato sulle ultime novità con il pacchetto. Per fornire feedback, critiche costruttive o se hai domande su questo codice, sentiti libero di inviarmi un’email: [email protected].



