Wild Wild RAG… (Parte 1)
Wild Wild RAG... (Parte 1)' -> 'Wild Wild RAG... (Pt. 1)
Iniziamo con la comprensione di cosa esattamente sia un’applicazione RAG, un termine che ha attirato molta attenzione negli ultimi mesi.
RAG (Retrieval-Augmented Generation) è un framework di intelligenza artificiale che migliora la qualità delle risposte generate dal Modello Linguistico incorporando fonti di conoscenza esterne. Colma il divario tra i modelli linguistici e le informazioni del mondo reale, ottenendo una generazione di testo più informata e affidabile dal punto di vista contestuale. Per illustrare, dai un’occhiata all’immagine qui sotto, che fornisce un esempio convincente.
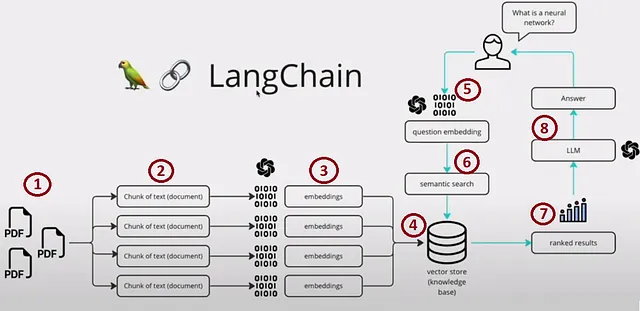
Possiamo suddividere il processo in quattro sezioni principali:
- Passi 1, 2, 3 e 4 — Indicizzazione
- Passo 5 — Prompting
- Passi 6 e 7 — Ricerca e Recupero
- Passo 8 — Generazione
Bene, creare un prototipo per un’applicazione RAG è semplice, ma ottimizzarlo per prestazioni elevate, durata e scalabilità quando si tratta di un vasto database di conoscenze presenta sfide significative.
Questo blog approfondirà le caratteristiche distintive che differenziano le applicazioni RAG dalle applicazioni di base del Modello Linguistico (LLM), concentrandosi sull’importanza delle scelte degli embedding e dei vettori nello store in questo contesto. Fondamentalmente, le sezioni di Indicizzazione e Ricerca e Recupero.
- Microsoft Research presenta non uno, non due, ma quattro nuovi compilatori di intelligenza artificiale
- Apprendimento automatico comprendere i fini del centratura e della scalatura
- Aumentare l’efficienza matematica Navigare nelle operazioni degli array Numpy
Iniziamo.

Per costruire il ‘contesto’ associato al tuo prompt e alla tua query, dobbiamo prima generare degli embedding da frammenti di dati segmentati. Questi embedding vengono memorizzati come indice vettoriale, fungendo da base per ricerche approssimative del vicinato più vicino (ANN) basate su query dell’utente. Sebbene il concetto sembri semplice, approfondire le complessità del passaggio di questo processo in un ambiente di produzione rivela una serie di sfide interessanti da esplorare.
Costo dell’Indicizzazione, Ricerca e Recupero Vettoriale
Ora, approfondiamo una delle considerazioni centrali — il costo dell’indicizzazione. È fondamentale capire che, quando si tratta di costruire un’applicazione pronta per la produzione, affidarsi esclusivamente a opzioni gratuite in memoria non è consigliabile.
Procediamo con una stima conservativa per la generazione di embedding da una base di conoscenza interna che comprende 3,5 milioni di pagine o un milione di PDF con una media di 3,5 pagine ciascuno. Per semplicità, supponiamo che ogni pagina sia composta solo da contenuto testuale, privo di immagini. Ogni pagina, quindi, corrisponde approssimativamente a 1000 token. Se suddividiamo questo in frammenti di 1000 token ciascuno, otteniamo 3,5 milioni di frammenti, che si traducono successivamente in 3,5 milioni di embedding.
Per i calcoli dei costi, consideriamo due opzioni leader in questo ambito — Weaviate e Pinecone. Manteniamo le cose semplici e valutiamo le spese mensili in tre sezioni chiave:
- Costo di Conversione degli Embedding una Tantum: Per elaborare 3,5 milioni di embedding, il costo approssimativo ammonta a $350, a un tasso di $0.0001 per conversione.
- Pinecone Performance-Optimized Vector Database (Standard): Per una singola replica, questa opzione costerebbe circa $650. Ciò include sia i costi di indicizzazione che di recupero. È importante notare che i costi aumentano linearmente man mano che le tue esigenze crescono. Weviate, un’altra scelta valida, probabilmente avrà una struttura di prezzi simile.
- Costo per la Conversione dell’Embedding della Query: Supponendo che 1000 utenti facciano in media 25 query al giorno, con ogni query e prompt che totalizzano 100 token, il costo per questa sezione si aggira intorno a $10.
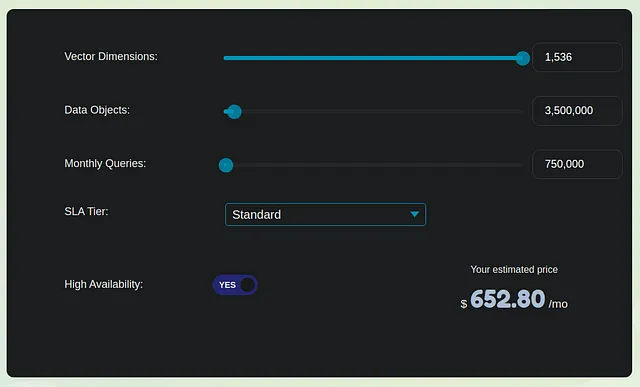
Il costo mensile totale per l’indicizzazione, a un livello moderato, si aggira intorno a $1.000. Si tenga presente che questa cifra non include le spese associate alla generazione delle risposte OpenAI LLM e all’hosting dell’applicazione, che possono essere stimate essere circa 5-7 volte superiori al costo menzionato o anche di più. Pertanto, il costo del vector store costituisce una parte significativa, rappresentando circa il 15-20% della spesa complessiva.
Per ridurre i costi, è possibile considerare l’hosting dei modelli di embedding principali, che riduce anche le spese di vector store optando per una dimensione di embedding inferiore a 1536.
Ma si dovrà comunque pagare per un vector store.

In casi in cui la funzionalità di ricerca di similarità e l’indice rimangono costanti, quali altri fattori dovrebbero essere considerati nella scelta di un vector store tra oltre 100 opzioni?
Bilanciamento tra Latenza, Scalabilità e Recall
In base alla prospettiva di scala e costo, consideriamo l’architettura client-server per i nostri vector store. È possibile scegliere di ospitarli nel cloud o in locale in base a fattori come il volume dei dati, la privacy e il denaro.
Quando si tratta di vector store, ci sono due tipi significativi di latenza da considerare: la latenza di indicizzazione e la latenza di recupero. In molti casi di utilizzo, la latenza di recupero ha la precedenza sulla latenza di indicizzazione. Questa preferenza deriva dal fatto che le operazioni di indicizzazione sono tipicamente sporadiche o compiti occasionali, mentre il recupero di chunk simili alle query degli utenti avviene molto più frequentemente, spesso in tempo reale e su larga scala attraverso interfacce utente. La recall, d’altra parte, quantifica la proporzione di veri vicini più prossimi trovati, mediata tra tutte le query. La maggior parte dei fornitori in questo campo utilizza una metodologia di ricerca di vettori ibrida che combina tecniche di ricerca di parole chiave e vettoriali in vari modi. Da notare che i diversi fornitori di database fanno scelte e compromessi distinti quando si tratta di ottimizzare la recall o la latenza.
Esaminiamo i benchmark di Recall vs Queries/sec ANN su un dataset standard per la metrica del coseno:
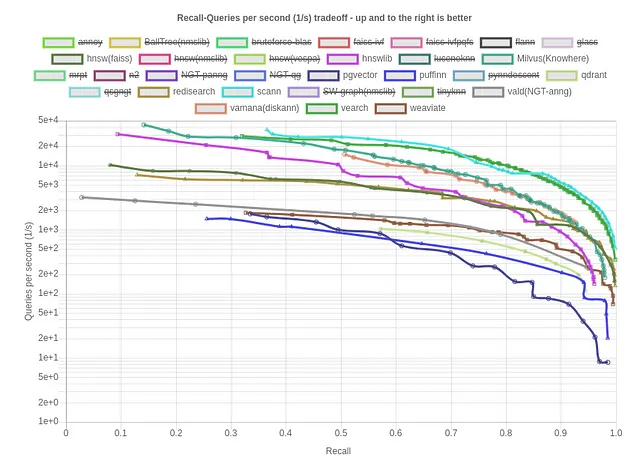
Scann, Vamana (DiskANN) e HNSW emergono come alcune delle migliori opzioni per l’indicizzazione. Ora esaminiamo i benchmark di Recall vs Dimensione dell’indice (kB)/Queries per secondo per gli stessi, che è una metrica importante per valutare l’efficienza e il consumo di risorse di un database di vettori. Un valore più basso indica una maggiore efficienza della memoria, ottimizzando le prestazioni e la scalabilità del database di vettori.

In questo contesto, Qdrant, Weviate e Redisearch emergono come alcune delle migliori opzioni per l’efficienza della memoria.
Tuttavia, è possibile fare riferimento all’immagine seguente per conoscere l’indice di vettori sottostante utilizzato da ciascun database.

È evidente che un numero significativo di fornitori di database ha scelto di sviluppare le proprie implementazioni proprietarie di HNSW basate su grafi. Queste implementazioni personalizzate spesso incorporano ottimizzazioni volte a ridurre il consumo di memoria, come la combinazione di Product Quantization (PQ) con HNSW. Tuttavia, è da notare che pochi hanno adottato DiskANN, che sembra offrire prestazioni comparabili a HNSW offrendo il vantaggio unico di scalare a indici più grandi della memoria, memorizzati interamente su disco.
Nella nostra valutazione, evitiamo di fare affidamento su benchmark forniti dai fornitori, in quanto potrebbero introdurre un bias nel processo di valutazione.
Inelasticità e Nessun Apprendimento Continuo
In uno scenario futuro, in cui potresti dover aggiornare il tuo Large Language Model (LLM) o il modello di embedding tramite il fine-tuning, iscriverti a un modello aggiornato, espandere le dimensioni dell’embedding o adattarti ai cambiamenti dei dati, la necessità di reindicizzare e i costi associati possono essere veri incubi. Questa rigidità può ostacolare significativamente l’agilità e la convenienza economica dell’evoluzione del tuo sistema.
Oltre a queste sfide, approfondiamo alcune complessità intrinseche nel processo di ricerca e recupero vettoriale.
Gestione degli errori di indicizzazione e maledizione della dimensionalità
Quando ci si trova di fronte a una situazione in cui una query di testo non riesce a recuperare il contesto pertinente e invece restituisce informazioni non correlate o senza senso, le cause di questo fallimento possono generalmente essere attribuite a uno dei tre fattori seguenti:
a) Mancanza di testo rilevante: In alcuni casi, il frammento di testo rilevante semplicemente non esiste nel database. Questo risultato è accettabile in quanto suggerisce che la query potrebbe non essere correlata ai contenuti dell’insieme di dati.
b) Embedding di bassa qualità: Un’altra possibile causa è la scarsa qualità degli embedding stessi. In tali casi, gli embedding non riescono a corrispondere efficacemente a due testi rilevanti utilizzando la similarità coseno.
c) Distribuzione degli embedding: In alternativa, gli embedding stessi potrebbero essere di buona qualità, ma a causa della distribuzione di questi embedding all’interno dell’indice, l’algoritmo ANN fatica a recuperare l’embedding corretto.
Mentre è in generale accettabile scartare la ragione (a) come l’irrilevanza della query rispetto all’insieme di dati, distinguere tra le ragioni (b) e (c) può essere un processo di debug complesso e lungo. Questo comportamento diventa sempre più evidente nel caso degli algoritmi ANN che gestiscono un grande numero di vettori ad alta dimensionalità, un fenomeno spesso definito “Maledizione della dimensionalità”.
Rivalutazione dei metodi di ricerca e recupero vettoriale
Se l’obiettivo principale dell’ecosistema di ricerca vettoriale è recuperare “testo rilevante” in risposta a una query, perché mantenere due processi separati? Invece, perché non stabilire un sistema unificato e appreso che, quando presentato con un testo di domanda, fornisce il testo “più rilevante” come output diretto?
La presunzione fondamentale che sottende l’intero ecosistema è la dipendenza dalle misure di similarità tra gli embedding vettoriali per recuperare il testo rilevante. Tuttavia, è importante riconoscere che potrebbero esserci alternative potenzialmente superiori a questo approccio. I Large Language Models (LLM) non sono intrinsecamente ottimizzati per il recupero di similarità, ed è del tutto plausibile che altri metodi di recupero possano produrre risultati più efficaci.
Fonte: Twitter
La rivoluzione del deep learning ha insegnato una lezione preziosa: un sistema di recupero ottimizzato in modo congiunto tende a superare un processo separato in cui l’embedding e le operazioni di Approximate Nearest Neighbors (ANN) sono indipendenti l’uno dall’altro. In un sistema di recupero ottimizzato, il processo di embedding e il componente ANN sono intimamente collegati e consapevoli delle reciproche complessità, portando a un recupero delle informazioni più coerente ed efficiente. Questo sottolinea l’importanza di approcci olistici e integrati nella progettazione di sistemi per il recupero delle informazioni e l’abbinamento del contesto.
Conclusioni
Nel campo delle applicazioni di Retrieval-Augmented Generation (RAG) pronte per la produzione e della ricerca vettoriale, abbiamo scoperto le sfide e le opportunità nel collegare modelli di linguaggio con la conoscenza del mondo reale. Dalle considerazioni sui costi dell’indicizzazione all’equilibrio delicato tra latenza, scala e richiamo, è evidente che l’ottimizzazione di questi sistemi per la produzione richiede una pianificazione attenta. L’inflessibilità dei modelli sottolinea l’importanza dell’adattabilità di fronte al cambiamento. Mentre rivalutiamo la ricerca vettoriale e il recupero per gli ambienti di produzione, scopriamo che un sistema unificato e ottimizzato in modo congiunto offre promesse. In questo panorama in continua evoluzione, siamo sull’orlo di creare sistemi AI più consapevoli del contesto che ridefiniscono i confini della generazione di testo e del recupero delle informazioni.
Il viaggio continua…
Grazie per la lettura. Connettiti con me su LinkedIn.






