Flamingo e DALL-E si capiscono? Esplorando la simbiosi tra i modelli di didascalia delle immagini e la sintesi di testo-immagine
Flamingo e DALL-E simbiosi tra modelli di didascalia delle immagini e sintesi di testo-immagine


La ricerca multimodale che potenzia la comprensione informatica di testo e immagini ha fatto grandi progressi di recente. Descrizioni verbali complesse di contesti reali possono essere tradotte in immagini ad alta fedeltà utilizzando modelli di generazione testo-immagine come DALL-E e Stable Diffusion (SD). D’altra parte, modelli di generazione immagine-testo come Flamingo e BLIP dimostrano la capacità di comprendere le complesse semantica presenti nelle immagini e fornire descrizioni coerenti. Nonostante la vicinanza tra la generazione testo-immagine e la generazione di didascalie per immagini, queste vengono spesso studiate in modo indipendente, il che significa che l’interazione tra questi modelli deve essere esplorata. Il tema se i modelli di generazione testo-immagine e i modelli di generazione immagine-testo possano capirsi a vicenda è un tema interessante.
Per affrontare questa problematica, viene utilizzato un modello di generazione immagine-testo chiamato BLIP per creare una descrizione testuale per una determinata immagine. Questa descrizione testuale viene poi alimentata in un modello di generazione testo-immagine chiamato SD, che crea una nuova immagine. Si sostiene che BLIP e SD possano comunicare se l’immagine creata assomiglia all’immagine di origine. La capacità di ogni parte di comprendere le idee sottostanti può essere migliorata dalla loro comprensione condivisa, portando a una migliore creazione di didascalie e sintesi delle immagini. Questo concetto è illustrato nella Figura 1, dove la didascalia superiore porta a una ricostruzione più accurata dell’immagine originale e rappresenta meglio l’immagine di input rispetto alla didascalia inferiore.
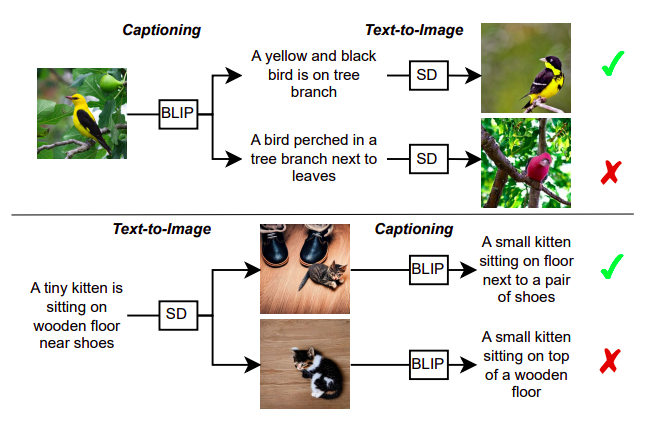
Ricercatori provenienti da LMU Monaco, Siemens AG e University of Oxford hanno sviluppato un progetto di ricostruzione in cui DALL-E sintetizza una nuova immagine utilizzando la descrizione che Flamingo produce per un’immagine data. Creano due task di ricostruzione testo-immagine e immagine-testo-immagine per testare questa supposizione (vedi Figura 1). Per il primo task di ricostruzione, calcolano la distanza tra le caratteristiche dell’immagine estratte con un encoder di immagini CLIP preaddestrato per determinare quanto simili sono le semantica dell’immagine ricostruita e dell’immagine di input. Successivamente, confrontano la qualità del testo prodotto con le didascalie annotate dall’uomo. La loro ricerca mostra che la qualità del testo creato influisce sulle prestazioni della ricostruzione. Questo porta alla loro prima scoperta: la descrizione che consente al modello generativo di ricostruire l’immagine originale è la migliore descrizione per un’immagine.
- Come possono i punti vendita automatici riconoscere i prodotti non etichettati? Scopri l’approccio di PseudoAugment alla visione artificiale.
- Ricercatori UCSC e TU Monaco propongono RECAST un nuovo modello basato su deep learning per prevedere le scosse di assestamento
- Domande, spalle alzate e cosa succede dopo Un quarto di secolo di cambiamenti
Allo stesso modo, viene creato il task opposto, in cui SD crea un’immagine da un input di testo, e poi BLIP crea un testo dall’immagine creata. Scoprono che l’immagine che ha prodotto il testo originale è l’illustrazione migliore per il testo. Ipotizzano che le informazioni dall’immagine di input siano mantenute accuratamente nella descrizione testuale durante il processo di ricostruzione. Questa descrizione significativa porta a un fedele ripristino alla modalità di immagine. La loro ricerca suggerisce un framework unico per il fine-tuning che facilita la comunicazione tra modelli di generazione testo-immagine e immagine-testo.
In particolare, nel loro paradigma, un modello generativo riceve segnali di addestramento da una perdita di ricostruzione e informazioni da etichette umane. Un modello crea prima una rappresentazione dell’input per una specifica immagine o testo nell’altra modalità, e il modello diverso traduce questa rappresentazione di nuovo alla modalità di input. Il componente di ricostruzione crea una perdita di regolarizzazione per guidare il fine-tuning del modello iniziale. In questo modo, ottengono supervisione umana e autonoma, aumentando la probabilità che la generazione porti a una ricostruzione più accurata. Ad esempio, il modello di didascalie delle immagini deve preferire didascalie che non solo corrispondano alle coppie immagine-testo etichettate, ma anche a quelle che possono portare a ricostruzioni affidabili.
La comunicazione tra agenti è strettamente legata al loro lavoro. La modalità primaria di scambio di informazioni tra agenti è il linguaggio. Ma come possono essere certi che il primo e il secondo agente abbiano la stessa definizione di un gatto o di un cane? In questo studio, si chiede al primo agente di esaminare un’immagine e generare una frase che la descriva. Dopo aver ottenuto il testo, il secondo agente simula un’immagine basata su di esso. Questa fase successiva è un processo di incarnazione. Secondo la loro ipotesi, la comunicazione è efficace se la simulazione dell’immagine da parte del secondo agente è vicina all’immagine di input ricevuta dal primo agente. In sostanza, viene valutata l’utilità del linguaggio, che serve come mezzo primario di comunicazione umana. In particolare, vengono utilizzati modelli di creazione di didascalie per immagini preaddestrati su larga scala e modelli di generazione di immagini nella loro ricerca. Diversi studi hanno dimostrato i vantaggi del loro framework proposto per diversi modelli generativi sia in situazioni di addestramento libero che di fine-tuning. In particolare, il loro approccio ha notevolmente migliorato la creazione di didascalie e immagini nel paradigma di addestramento libero, mentre per il fine-tuning hanno ottenuto risultati migliori per entrambi i modelli generativi.
Ecco di seguito un riassunto dei loro principali contributi:
• Framework: Secondo la loro conoscenza, sono i primi a indagare su come modelli generativi convenzionali sia solo immagine-testo che solo testo-immagine possano essere comunicati tramite rappresentazioni testuali e immagini facilmente comprensibili. Al contrario, lavori simili integrano implicitamente la creazione di testo e immagini tramite uno spazio di embedding.
• Risultati: Hanno scoperto che valutare la ricostruzione dell’immagine creata da un modello testo-immagine può aiutare a determinare la qualità di una didascalia. La didascalia che consente la ricostruzione più accurata dell’immagine originale è quella che dovrebbe essere utilizzata per quella immagine. Allo stesso modo, la migliore immagine didascalia è quella che consente la ricostruzione più accurata del testo originale.
• Miglioramenti: Alla luce della loro ricerca, hanno proposto un framework completo per migliorare sia i modelli testo-immagine che immagine-testo. Una perdita di ricostruzione calcolata da un modello testo-immagine verrà utilizzata come regolarizzazione per affinare il modello immagine-testo, mentre una perdita di ricostruzione calcolata da un modello immagine-testo verrà utilizzata per affinare il modello testo-immagine. Hanno indagato e confermato la fattibilità del loro approccio.



