Microsoft Research presenta non uno, non due, ma quattro nuovi compilatori di intelligenza artificiale
Microsoft Research presenta quattro nuovi compilatori di intelligenza artificiale.
Parallelismo, calcolo, memoria, accelerazione hardware e flusso di controllo sono alcune delle capacità affrontate dai nuovi compilatori.

Di recente ho avviato una newsletter educativa focalizzata sull’IA, che conta già oltre 160.000 abbonati. TheSequence è una newsletter orientata all’apprendimento automatico (ML) che richiede 5 minuti di lettura e non contiene esagerazioni o notizie. L’obiettivo è tenerti aggiornato sui progetti di apprendimento automatico, sugli articoli di ricerca e sui concetti. Prova ad iscriverti qui di seguito:
TheSequence | Jesus Rodriguez | Substack
La migliore fonte per rimanere aggiornato sugli sviluppi nell’apprendimento automatico, nell’intelligenza artificiale e nei dati…
thesequence.substack.com
I compilatori stanno vivendo una rinascita nell’era dell’IA generativa. Nel contesto dell’IA, un compilatore è responsabile della traduzione di un’architettura di rete neurale in codice eseguibile in una specifica topologia hardware. Queste due aree: le architetture di modelli e hardware, hanno visto un’esplosione di innovazione, rendendo regolarmente obsoleti i compilatori per l’IA.
Le sfide nella compilazione dell’IA sono molte, dall’accelerazione hardware all’efficienza di calcolo e memoria. Microsoft Research è stata in prima linea nella ricerca sui compilatori per l’IA e di recente ha presentato una serie di compilatori di IA all’avanguardia, ognuno progettato per affrontare sfide specifiche nel campo delle reti neurali profonde (DNN). L’elenco include i seguenti compilatori:
- Apprendimento automatico comprendere i fini del centratura e della scalatura
- Aumentare l’efficienza matematica Navigare nelle operazioni degli array Numpy
- Può l’IA veramente ripristinare i dettagli del viso da immagini di bassa qualità? Incontra DAEFR un framework a doppio ramo per una qualità migliorata
· Rammer: Per il parallelismo
· Roller: Per il calcolo
· Welder: Per la memoria
· Grinder: Per il flusso di controllo e l’accelerazione hardware
Approfondiamo ognuno di essi.
Rammer: Pionieristica utilizzazione dell’hardware parallelo
Le reti neurali profonde (DNN) sono diventate parte integrante di varie attività di intelligenza, che vanno dalla classificazione delle immagini all’elaborazione del linguaggio naturale. Per sfruttarne la potenza, vengono impiegati numerosi dispositivi di calcolo, tra cui CPU, GPU e acceleratori DNN specializzati. Un fattore critico che influenza l’efficienza del calcolo delle DNN è la pianificazione, il processo che determina l’ordine delle attività di calcolo sull’hardware. I compilatori tradizionali per l’IA rappresentano spesso il calcolo delle DNN come un grafo di flusso di dati con nodi che simboleggiano gli operatori DNN, pianificati per essere eseguiti sugli acceleratori in modo indipendente. Tuttavia, questa metodologia introduce un significativo overhead di pianificazione e sfrutta in modo inefficace le risorse hardware.
Entra in scena Rammer, un compilatore DNN che immagina lo spazio di pianificazione come un piano bidimensionale. Qui, le attività di calcolo sono simili a mattoni, con forme e dimensioni varie. La missione di Rammer è quella di disporre questi mattoni in modo preciso sul piano bidimensionale, come nella costruzione di un muro uniforme. Non sono ammessi spazi vuoti per ottimizzare l’utilizzo dell’hardware e la velocità di esecuzione. Rammer agisce efficacemente come un compattatore all’interno di questo dominio spaziale, posizionando in modo efficiente i mattoni del programma DNN su diverse unità di calcolo dell’acceleratore, riducendo così l’overhead di pianificazione durante l’esecuzione. Inoltre, Rammer introduce nuove astrazioni indipendenti dall’hardware per le attività di calcolo e gli acceleratori hardware, ampliando lo spazio di pianificazione e consentendo pianificazioni più efficienti.
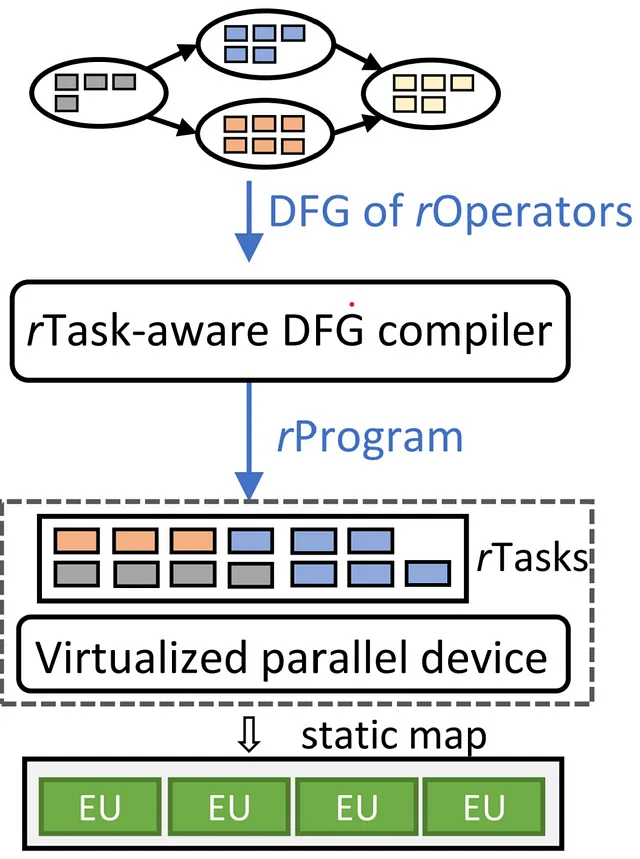
Roller: Migliorare l’efficienza di calcolo
Gli acceleratori che vantano unità di calcolo parallele e gerarchie di memoria intricate richiedono un approccio sistematico al trasferimento dei dati. I dati devono salire attraverso i livelli di memoria, suddivisi in mattoni più piccoli ad ogni passaggio, prima di raggiungere il processore di livello superiore per il calcolo. La sfida sta nel suddividere e riempire lo spazio di memoria con grandi mattoni per ottimizzare l’utilizzo e l’efficienza della memoria. L’approccio attuale utilizza l’apprendimento automatico per le strategie di suddivisione dei mattoni, richiedendo numerosi passi di ricerca valutati sull’acceleratore. Questo lungo processo può richiedere giorni o settimane per compilare un modello di IA completo.
Roller accelera la compilazione mantenendo un’efficienza computazionale ottimale. Al suo nucleo, Roller incarna un concetto unico simile al funzionamento di un rullo stradale. Questo sistema innovativo deposita in modo fluido dati tensoriali ad alta dimensionalità su una struttura di memoria bidimensionale, come la posa abile di un pavimento. Lo fa con precisione, discernendo le dimensioni ideali delle piastrelle in base alle specifiche caratteristiche di memoria. Allo stesso tempo, Roller racchiude intelligentemente la forma del tensore per armonizzare con le sfumature hardware dell’acceleratore sottostante. Questo allineamento strategico semplifica significativamente il processo di compilazione limitando la gamma di opzioni di forma, portando infine a risultati altamente efficienti.
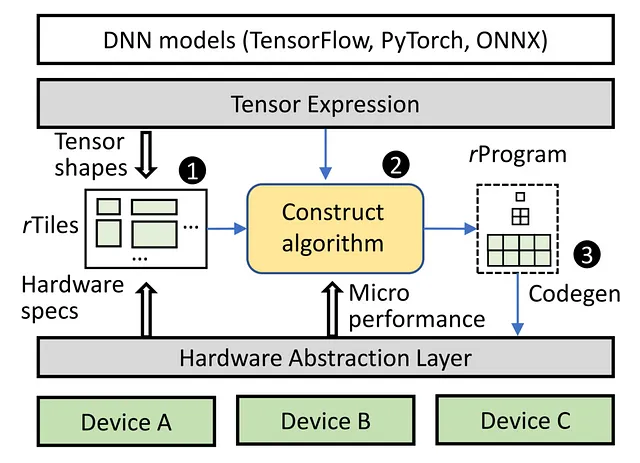
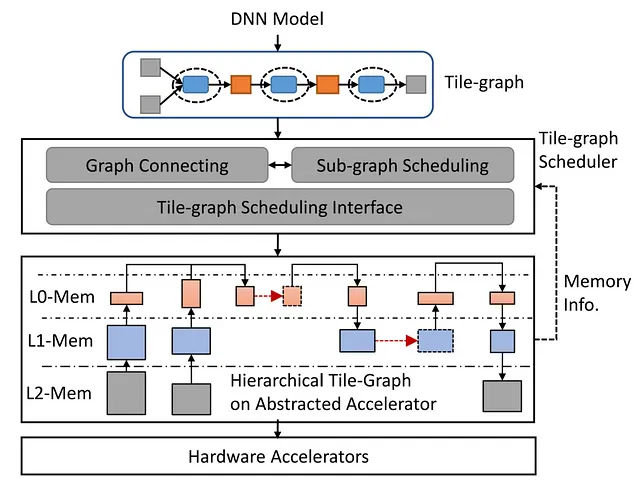
Welder: Ottimizzazione dell’Accesso alla Memoria
Con l’aumento della richiesta di modelli DNN con dati ad alta fedeltà e core di calcolo più veloci negli acceleratori hardware moderni, si sono manifestati dei colli di bottiglia nella larghezza di banda della memoria. Per contrastare ciò, Welder, il compilatore di deep learning, ottimizza in modo completo l’efficienza di accesso alla memoria nel modello DNN end-to-end. Il processo coinvolge diverse fasi, in cui i dati di input vengono divisi in blocchi che attraversano diversi operatori e livelli di memoria. Welder trasforma questo processo in una linea di assemblaggio efficiente, saldando insieme diversi operatori e blocchi di dati, riducendo il traffico di accesso alla memoria nei livelli di memoria di basso livello.
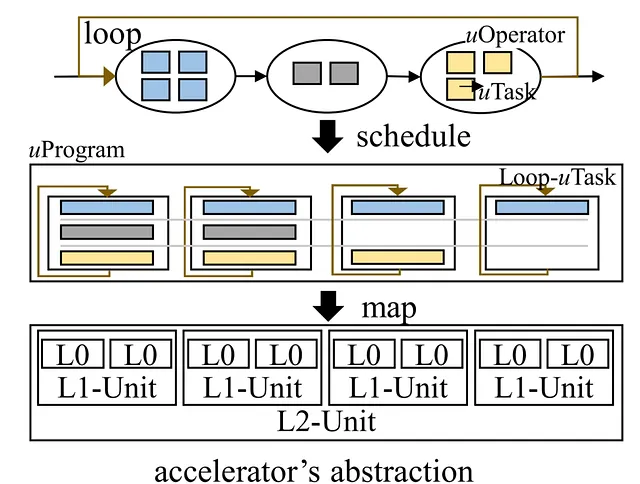
Grinder: Padronanza dell’Esecuzione del Flusso di Controllo
Nella computazione AI, la logica di controllo complessa a volte accompagna lo spostamento del blocco di dati. I compilatori AI attuali si concentrano principalmente sull’efficienza dell’esecuzione del flusso di dati, trascurando il supporto efficiente per il flusso di controllo. Grinder colma questa lacuna integrando in modo fluido il flusso di controllo nel flusso di dati, consentendo un’efficace esecuzione sugli acceleratori. Unifica la rappresentazione dei modelli AI attraverso uTask, una nuova astrazione, e sfrutta strategie euristiche per ottimizzare l’esecuzione del flusso di controllo su diversi livelli di parallelismo hardware. Grinder sposta in modo efficiente il flusso di controllo nei kernel del dispositivo, ottimizzando così le prestazioni oltre i limiti del flusso di controllo.
In sintesi, il quartetto di compilatori AI di Microsoft Research – Rammer, Roller, Welder e Grinder – aprono la strada all’ottimizzazione dei carichi di lavoro DNN, all’efficienza di accesso alla memoria e all’esecuzione del flusso di controllo sugli acceleratori hardware, segnando un significativo passo avanti nella tecnologia dei compilatori AI.






