Linguaggio per ricompense per la sintesi di abilità robotiche
Robot Skill Synthesis Reward Language
Pubblicato da Wenhao Yu e Fei Xia, Scienziati della Ricerca, Google
Dotare gli utenti finali della capacità di insegnare in modo interattivo ai robot di svolgere nuove attività è una capacità cruciale per la loro integrazione di successo nelle applicazioni del mondo reale. Ad esempio, un utente potrebbe voler insegnare a un cane robot a fare un nuovo trucco, o insegnare a un robot manipolatore come organizzare una scatola pranzo in base alle preferenze dell’utente. I recenti progressi nei modelli linguistici di grandi dimensioni (LLM) pre-addestrati su dati Internet estesi hanno mostrato una via promettente per raggiungere questo obiettivo. Infatti, i ricercatori hanno esplorato diverse modalità di sfruttamento dei LLM per la robotica, dalla pianificazione passo-passo e dal dialogo orientato agli obiettivi fino agli agenti di scrittura del codice robot.
Pur impartendo nuove modalità di generalizzazione compositiva, questi metodi si concentrano sull’utilizzo del linguaggio per collegare nuovi comportamenti da una libreria esistente di primitive di controllo che sono state progettate manualmente o apprese a priori. Nonostante abbiano conoscenze interne sui movimenti del robot, i LLM faticano a produrre direttamente comandi di robot a basso livello a causa della limitata disponibilità di dati di addestramento pertinenti. Di conseguenza, l’espressione di questi metodi è limitata dalla vastità delle primitive disponibili, la cui progettazione richiede spesso una vasta conoscenza esperta o una massiccia raccolta di dati.
In “Language to Rewards for Robotic Skill Synthesis”, proponiamo un approccio per consentire agli utenti di insegnare ai robot nuove azioni attraverso l’input del linguaggio naturale. Per farlo, sfruttiamo le funzioni di ricompensa come interfaccia che colma il divario tra il linguaggio e le azioni di robot a basso livello. Sosteniamo che le funzioni di ricompensa forniscono un’interfaccia ideale per compiti di questo tipo, data la loro ricchezza di semantica, modularità e interpretabilità. Forniscono anche una connessione diretta alle politiche a basso livello attraverso l’ottimizzazione a scatola nera o l’apprendimento per rinforzo (RL). Abbiamo sviluppato un sistema di traduzione del linguaggio in ricompense che sfrutta i LLM per tradurre le istruzioni degli utenti nel linguaggio naturale in codice che specifica la ricompensa e quindi applica MuJoCo MPC per trovare azioni di robot a basso livello ottimali che massimizzano la funzione di ricompensa generata. Dimostriamo il nostro sistema di traduzione del linguaggio in ricompense su una varietà di compiti di controllo robotico in simulazione utilizzando un robot quadrupede e un robot manipolatore abile. Convalidiamo ulteriormente il nostro metodo su un manipolatore robotico fisico.
- Insegnare ai modelli di linguaggio a ragionare in modo algoritmico
- L’algoritmo di Google rende l’encryption FIDO al sicuro dai computer quantistici
- Rendere sfocato lo schermo del tuo telefono potrebbe fermare lo spiare
Il sistema di traduzione del linguaggio in ricompense è composto da due componenti principali: (1) un Traduttore di Ricompense e (2) un Controllore di Movimento. Il Traduttore di Ricompense mappa le istruzioni in linguaggio naturale degli utenti in funzioni di ricompensa rappresentate come codice Python. Il Controllore di Movimento ottimizza la funzione di ricompensa data utilizzando l’ottimizzazione all’orizzonte emergente per trovare le azioni ottimali dei robot a basso livello, come ad esempio la quantità di coppia che dovrebbe essere applicata a ciascun motore del robot.
 |
| I LLM non possono generare direttamente azioni robotiche a basso livello a causa della mancanza di dati nel set di dati di pre-addestramento. Proponiamo di utilizzare funzioni di ricompensa per colmare il divario tra il linguaggio e le azioni robotiche a basso livello e consentire nuovi movimenti complessi dei robot a partire da istruzioni in linguaggio naturale. |
Traduttore di Ricompense: Traduzione delle istruzioni degli utenti in funzioni di ricompensa
Il modulo Traduttore di Ricompense è stato creato con l’obiettivo di mappare le istruzioni degli utenti in linguaggio naturale in funzioni di ricompensa. La messa a punto delle ricompense è altamente specifica del dominio e richiede conoscenze esperte, quindi non ci ha sorpreso quando abbiamo scoperto che i LLM addestrati su set di dati di linguaggio generici non sono in grado di generare direttamente una funzione di ricompensa per un hardware specifico. Per affrontare questo problema, applichiamo la capacità di apprendimento in contesto dei LLM. Inoltre, suddividiamo il Traduttore di Ricompense in due sottomoduli: Descrittore di Movimento e Codificatore di Ricompensa.
Descrittore di Movimento
In primo luogo, progettiamo un Descrittore di Movimento che interpreta l’input di un utente e lo espande in una descrizione in linguaggio naturale del movimento desiderato del robot seguendo un modello predefinito. Questo Descrittore di Movimento trasforma istruzioni potenzialmente ambigue o vaghe degli utenti in movimenti del robot più specifici e descrittivi, rendendo il compito di codifica della ricompensa più stabile. Inoltre, gli utenti interagiscono con il sistema tramite il campo di descrizione del movimento, quindi questo fornisce anche un’interfaccia più interpretabile per gli utenti rispetto alla visualizzazione diretta della funzione di ricompensa.
Per creare il Descrittore di Movimento, utilizziamo un LLM per tradurre l’input dell’utente in una descrizione dettagliata del movimento desiderato del robot. Progettiamo suggerimenti che guidano i LLM a produrre la descrizione del movimento con la giusta quantità di dettagli e formato. Traducendo un’istruzione vaga dell’utente in una descrizione più dettagliata, siamo in grado di generare in modo più affidabile la funzione di ricompensa con il nostro sistema. Questa idea può anche essere potenzialmente applicata in modo più generale oltre ai compiti di robotica ed è pertinente per la Monologo Interno e il prompting di catena di pensiero.
Reward Coder
Nella seconda fase, utilizziamo lo stesso LLM del Descrittore di Movimento per il Reward Coder, che traduce la descrizione del movimento generata nella funzione di ricompensa. Le funzioni di ricompensa sono rappresentate utilizzando codice Python per beneficiare della conoscenza dei LLM su ricompensa, codifica e struttura del codice.
Idealemente, vorremmo utilizzare un LLM per generare direttamente una funzione di ricompensa R (s, t) che mappa lo stato del robot s e il tempo t in un valore di ricompensa scalare. Tuttavia, generare la corretta funzione di ricompensa da zero è ancora un problema difficile per i LLM e correggere gli errori richiede all’utente di capire il codice generato per fornire il giusto feedback. Pertanto, predefiniamo un insieme di termini di ricompensa comunemente usati per il robot di interesse e consentiamo ai LLM di comporre diversi termini di ricompensa per formulare la funzione di ricompensa finale. Per raggiungere questo obiettivo, progettiamo un suggerimento che specifica i termini di ricompensa e guida il LLM a generare la corretta funzione di ricompensa per il compito.
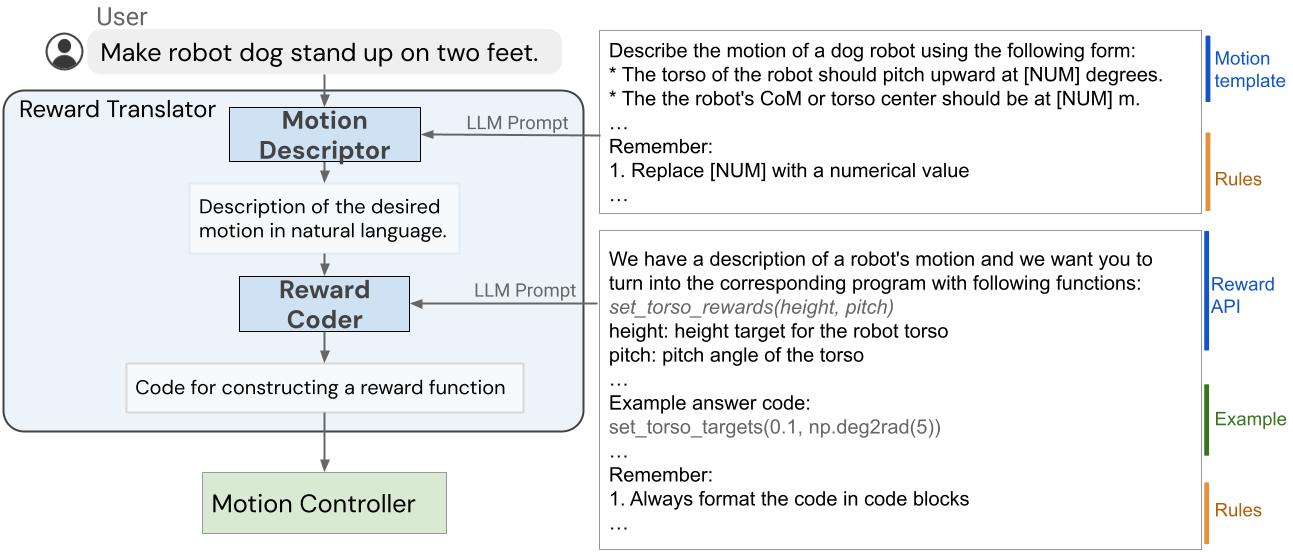 |
| La struttura interna del Traduttore di Ricompensa, che ha il compito di mappare gli input dell’utente alle funzioni di ricompensa. |
Motion Controller: Traduzione delle funzioni di ricompensa in azioni del robot
Il Motion Controller prende la funzione di ricompensa generata dal Traduttore di Ricompensa e sintetizza un controller che mappa l’osservazione del robot in azioni del robot a basso livello. Per fare ciò, formuliamo il problema di sintesi del controller come un processo decisionale di Markov (MDP), che può essere risolto utilizzando diverse strategie, inclusi RL, ottimizzazione della traiettoria offline o controllo predittivo del modello (MPC). In particolare, utilizziamo un’implementazione open-source basata su MuJoCo MPC (MJPC).
MJPC ha dimostrato la creazione interattiva di comportamenti diversi, come la locomozione a quattro zampe, la presa e il movimento delle dita, supportando anche più algoritmi di pianificazione, come il linear-quadratic-Gaussian iterativo (iLQG) e il campionamento predittivo. Inoltre, la pianificazione frequente in MJPC conferisce robustezza alle incertezze nel sistema e consente un sistema di sintesi e correzione del movimento interattivo quando combinato con i LLM.
Esempi
Robot cane
Nel primo esempio, applichiamo il sistema di linguaggio-a-ricompensa a un robot quadrupede simulato e lo insegniamo a eseguire varie abilità. Per ogni abilità, l’utente fornirà un’istruzione concisa al sistema, che sintetizzerà quindi il movimento del robot utilizzando le funzioni di ricompensa come interfaccia intermedia.
Manipolatore destro
Successivamente, applichiamo il sistema di linguaggio-a-ricompensa a un manipolatore destro per eseguire una varietà di compiti di manipolazione. Il manipolatore destro ha 27 gradi di libertà, il che rende molto difficile da controllare. Molti di questi compiti richiedono abilità di manipolazione oltre alla semplice presa, rendendo difficile il funzionamento di primitive predefinite. Includiamo anche un esempio in cui l’utente può istruire interattivamente il robot a mettere una mela dentro un cassetto.
Convalida su robot reali
Convalidiamo anche il metodo di linguaggio-a-ricompensa utilizzando un robot di manipolazione del mondo reale per eseguire compiti come raccogliere oggetti e aprire un cassetto. Per eseguire l’ottimizzazione nel Motion Controller, utilizziamo AprilTag, un sistema di marcatori fiduciali, e F-VLM, un tool di rilevamento oggetti ad ampio vocabolario, per identificare la posizione del tavolo e degli oggetti manipolati.
Conclusione
In questo lavoro, descriviamo un nuovo paradigma per l’interfacciamento di un LLM con un robot attraverso funzioni di ricompensa, alimentate da uno strumento di controllo predittivo a basso livello, MuJoCo MPC. Utilizzare le funzioni di ricompensa come interfaccia consente ai LLM di lavorare in uno spazio semanticamente ricco che sfrutta i punti di forza dei LLM, garantendo al contempo l’espressività del controller risultante. Per migliorare ulteriormente le prestazioni del sistema, proponiamo di utilizzare un template strutturato di descrizione del movimento per estrarre meglio le conoscenze interne sui movimenti del robot dai LLM. Dimostriamo il nostro sistema proposto su due piattaforme robotiche simulate e un robot reale per compiti di locomozione e manipolazione.
Ringraziamenti
Vorremmo ringraziare i nostri coautori Nimrod Gileadi, Chuyuan Fu, Sean Kirmani, Kuang-Huei Lee, Montse Gonzalez Arenas, Hao-Tien Lewis Chiang, Tom Erez, Leonard Hasenclever, Brian Ichter, Ted Xiao, Peng Xu, Andy Zeng, Tingnan Zhang, Nicolas Heess, Dorsa Sadigh, Jie Tan e Yuval Tassa per il loro aiuto e supporto in vari aspetti del progetto. Vorremmo anche ringraziare Ken Caluwaerts, Kristian Hartikainen, Steven Bohez, Carolina Parada, Marc Toussaint e i team di Google DeepMind per il loro feedback e contributi.