Annunciamo l’anteprima di Amazon SageMaker Profiler Monitora e visualizza i dettagliati dati sulle prestazioni hardware per i tuoi carichi di lavoro di addestramento del modello
Annunciamo l'anteprima di Amazon SageMaker Profiler monitora e visualizza i dettagli delle prestazioni hardware per i carichi di lavoro di addestramento del modello.
Oggi siamo lieti di annunciare l’anteprima di Amazon SageMaker Profiler, una funzionalità di Amazon SageMaker che fornisce una vista dettagliata delle risorse di calcolo AWS allocate durante l’addestramento di modelli di deep learning su SageMaker. Con SageMaker Profiler, è possibile monitorare tutte le attività su CPU e GPU, come l’utilizzo di CPU e GPU, le esecuzioni del kernel su GPU, i lanci del kernel su CPU, le operazioni di sincronizzazione, le operazioni di memoria su GPU, le latenze tra i lanci del kernel e le relative esecuzioni e il trasferimento dei dati tra CPU e GPU. In questo post, ti illustreremo le funzionalità di SageMaker Profiler.
SageMaker Profiler fornisce moduli Python per annotare gli script di addestramento di PyTorch o TensorFlow e attivare SageMaker Profiler. Offre anche un’interfaccia utente (UI) che visualizza il profilo, un riepilogo statistico degli eventi profilati e la timeline di un job di addestramento per tracciare e comprendere la relazione temporale degli eventi tra GPU e CPU.
La necessità di profilare i job di addestramento
Con l’avvento del deep learning (DL), l’apprendimento automatico (ML) è diventato intensivo in termini di calcolo e dati, richiedendo tipicamente cluster multi-nodo e multi-GPU. Man mano che i modelli all’avanguardia aumentano di dimensioni nell’ordine dei trilioni di parametri, la loro complessità computazionale e il costo aumentano rapidamente. Gli specialisti di ML devono affrontare sfide comuni di utilizzo efficiente delle risorse durante l’addestramento di modelli così grandi. Questo è particolarmente evidente nei grandi modelli di linguaggio (LLM), che hanno tipicamente miliardi di parametri e quindi richiedono grandi cluster multi-nodo GPU per addestrarli in modo efficiente.
Quando si addestrano questi modelli su cluster di calcolo di grandi dimensioni, possono sorgere sfide di ottimizzazione delle risorse di calcolo come colli di bottiglia di I/O, latenze di avvio dei kernel, limiti di memoria e utilizzo ridotto delle risorse. Se la configurazione del job di addestramento non è ottimizzata, queste sfide possono comportare un utilizzo inefficiente dell’hardware, tempi di addestramento più lunghi o esecuzioni di addestramento incomplete, aumentando i costi e i tempi complessivi del progetto.
- Linguaggio per ricompense per la sintesi di abilità robotiche
- Insegnare ai modelli di linguaggio a ragionare in modo algoritmico
- L’algoritmo di Google rende l’encryption FIDO al sicuro dai computer quantistici
Prerequisiti
I seguenti sono i prerequisiti per iniziare a utilizzare SageMaker Profiler:
- Un dominio SageMaker nel tuo account AWS – Per istruzioni su come configurare un dominio, consulta la guida Onboard to Amazon SageMaker Domain using quick setup. È inoltre necessario aggiungere profili utente di dominio per consentire agli utenti individuali di accedere all’applicazione UI di SageMaker Profiler. Per ulteriori informazioni, consulta la guida Add and remove SageMaker Domain user profiles.
- Permessi – Di seguito è riportato l’elenco minimo di permessi che devono essere assegnati al ruolo di esecuzione per utilizzare l’applicazione UI di SageMaker Profiler:
sagemaker:CreateAppsagemaker:DeleteAppsagemaker:DescribeTrainingJobsagemaker:SearchTrainingJobss3:GetObjects3:ListBucket
Preparare ed eseguire un job di addestramento con SageMaker Profiler
Per iniziare a catturare le esecuzioni del kernel su GPU durante l’esecuzione del job di addestramento, modifica il tuo script di addestramento utilizzando i moduli Python di SageMaker Profiler. Importa la libreria e aggiungi i metodi start_profiling() e stop_profiling() per definire l’inizio e la fine del profiling. Puoi anche utilizzare annotazioni personalizzate opzionali per aggiungere marker nello script di addestramento per visualizzare le attività dell’hardware durante operazioni specifiche in ogni passaggio.
Puoi adottare due approcci per profilare i tuoi script di addestramento con SageMaker Profiler. Il primo approccio si basa sul profiling di funzioni complete; il secondo approccio si basa sul profiling di linee di codice specifiche nelle funzioni.
Per profilare per funzioni, utilizza il context manager smppy.annotate per annotare funzioni complete. Lo script di esempio seguente mostra come implementare il context manager per avvolgere il ciclo di addestramento e le funzioni complete in ogni iterazione:
import smppy
sm_prof = smppy.SMProfiler.instance()
config = smppy.Config()
config.profiler = {
"EnableCuda": "1",
}
sm_prof.configure(config)
sm_prof.start_profiling()
for epoch in range(args.epochs):
if world_size > 1:
sampler.set_epoch(epoch)
tstart = time.perf_counter()
for i, data in enumerate(trainloader, 0):
with smppy.annotate("step_"+str(i)):
inputs, labels = data
inputs = inputs.to("cuda", non_blocking=True)
labels = labels.to("cuda", non_blocking=True)
optimizer.zero_grad()
with smppy.annotate("Forward"):
outputs = net(inputs)
with smppy.annotate("Loss"):
loss = criterion(outputs, labels)
with smppy.annotate("Backward"):
loss.backward()
with smppy.annotate("Optimizer"):
optimizer.step()
sm_prof.stop_profiling()Puoi anche utilizzare smppy.annotation_begin() e smppy.annotation_end() per annotare linee specifiche di codice nelle funzioni. Per ulteriori informazioni, consulta la documentazione.
Configura il lanciatore del job di addestramento SageMaker
Dopo aver finito di annotare e configurare i moduli di inizializzazione del profiler, salva lo script di addestramento e prepara il framework estimator di SageMaker per l’addestramento utilizzando il SageMaker Python SDK.
-
Configura un oggetto
profiler_configutilizzando i moduliProfilerConfigeProfilercome segue:from sagemaker import ProfilerConfig, Profiler profiler_config = ProfilerConfig( profiler_params = Profiler(cpu_profiling_duration=3600)) -
Crea un estimator di SageMaker con l’oggetto
profiler_configcreato nel passaggio precedente. Il codice seguente mostra un esempio di creazione di un estimator PyTorch:import sagemaker from sagemaker.pytorch import PyTorch estimator = PyTorch( framework_version="2.0.0", image_uri="763104351884.dkr.ecr.<region>.amazonaws.com/pytorch-training:2.0.0-gpu-py310-cu118-ubuntu20.04-sagemaker", role=sagemaker.get_execution_role(), entry_point="train_with_profiler_demo.py", # il punto di ingresso del tuo job di addestramento source_dir=source_dir, # directory sorgente per lo script di addestramento output_path=output_path, base_job_name="sagemaker-profiler-demo", hyperparameters=hyperparameters, # se presenti instance_count=1, instance_type=ml.p4d.24xlarge, profiler_config=profiler_config )
Se desideri creare un estimator TensorFlow, dovresti importare sagemaker.tensorflow.TensorFlow e specificare una delle versioni di TensorFlow supportate da SageMaker Profiler. Per ulteriori informazioni sui framework supportati e sui tipi di istanze, consulta i framework supportati.
-
Avvia il job di addestramento eseguendo il metodo fit:
estimator.fit(wait=False)
Avvia l’interfaccia utente del Profiler SageMaker
Quando il job di addestramento è completo, puoi avviare l’interfaccia utente del Profiler SageMaker per visualizzare ed esplorare il profilo del job di addestramento. Puoi accedere all’applicazione dell’interfaccia utente del Profiler SageMaker attraverso la pagina principale del Profiler SageMaker nella console di SageMaker o attraverso il dominio di SageMaker.
Per avviare l’applicazione dell’interfaccia utente del Profiler SageMaker nella console di SageMaker, segui questi passaggi:
- Sulla console di SageMaker, scegli Profiler nel riquadro di navigazione.
- Sotto Inizia, seleziona il dominio in cui desideri avviare l’applicazione dell’interfaccia utente del Profiler SageMaker.
Se il tuo profilo utente appartiene solo a un dominio, non vedrai l’opzione per selezionare un dominio.
- Seleziona il profilo utente per il quale desideri avviare l’applicazione dell’interfaccia utente del Profiler SageMaker.
Se non esiste un profilo utente nel dominio, scegli Crea profilo utente. Per ulteriori informazioni sulla creazione di un nuovo profilo utente, consulta Aggiungi e Rimuovi Profili Utente.
- Scegli Apri Profiler.
Puoi anche avviare l’interfaccia utente del Profiler SageMaker dalla pagina dei dettagli del dominio.
Ottieni informazioni dal Profiler SageMaker
Quando apri l’interfaccia utente del Profiler SageMaker, viene aperta la pagina Seleziona e carica un profilo, come mostrato nella seguente schermata.
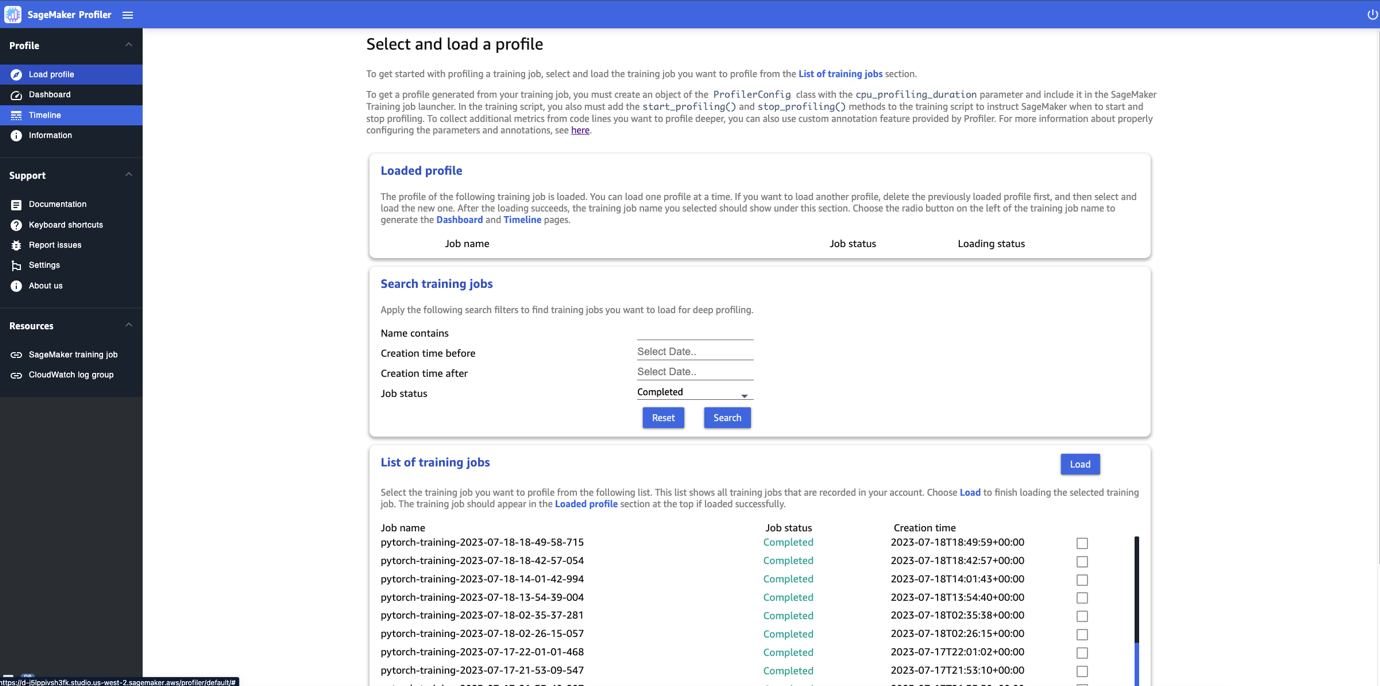
È possibile visualizzare un elenco di tutti i job di training che sono stati inviati a SageMaker Profiler e cercare un determinato job di training per nome, ora di creazione e stato di esecuzione (In corso, Completato, Fallito, Interrotto o In fase di interruzione). Per caricare un profilo, seleziona il job di training che desideri visualizzare e scegli Carica. Il nome del job dovrebbe apparire nella sezione Profilo caricato in alto.
Seleziona il nome del job per generare il pannello di controllo e la timeline. Nota che quando scegli il job, l’interfaccia utente apre automaticamente il pannello di controllo. Puoi caricare e visualizzare un solo profilo alla volta. Per caricare un altro profilo, devi prima scaricare il profilo caricato in precedenza. Per scaricare un profilo, scegli l’icona del cestino nella sezione Profilo caricato.
In questo post, visualizziamo il profilo di un job di training di ALBEF su due istanze ml.p4d.24xlarge.
Dopo aver terminato di caricare e selezionare il job di training, l’interfaccia utente apre la pagina Pannello di controllo, come mostrato nella seguente immagine.
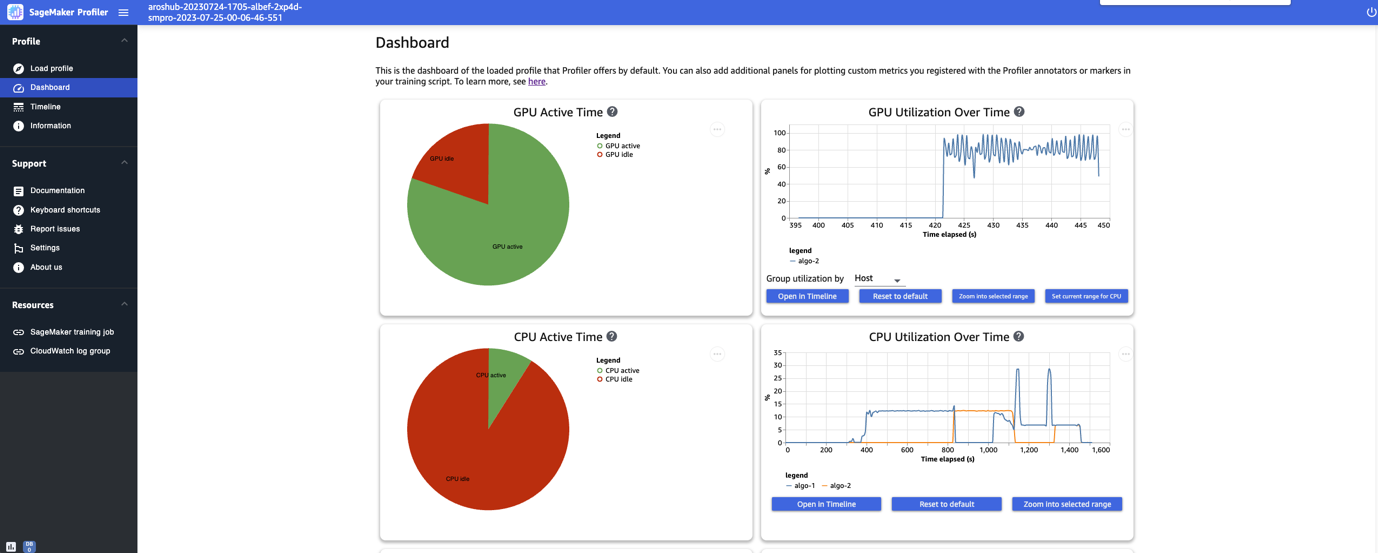
Puoi vedere i grafici per le metriche chiave, ovvero il tempo attivo della GPU, l’utilizzo della GPU nel tempo, il tempo attivo della CPU e l’utilizzo della CPU nel tempo. Il grafico a torta del tempo attivo della GPU mostra la percentuale di tempo attivo della GPU rispetto al tempo di inattività della GPU, che ci consente di verificare se le GPU sono più attive che inattive durante l’intero job di training. La timeline dell’utilizzo della GPU nel tempo mostra il tasso medio di utilizzo della GPU nel tempo per nodo, aggregando tutti i nodi in un singolo grafico. Puoi verificare se le GPU hanno un carico di lavoro sbilanciato, problemi di sottoutilizzazione, collo di bottiglia o problemi di inattività durante determinati intervalli di tempo. Per ulteriori dettagli sull’interpretazione di queste metriche, fare riferimento alla documentazione.
Il pannello di controllo fornisce anche altri grafici, tra cui il tempo trascorso da tutti i kernel della GPU, il tempo trascorso dai primi 15 kernel della GPU, il conteggio di avvio di tutti i kernel della GPU e il conteggio di avvio dei primi 15 kernel della GPU, come mostrato nella seguente immagine.
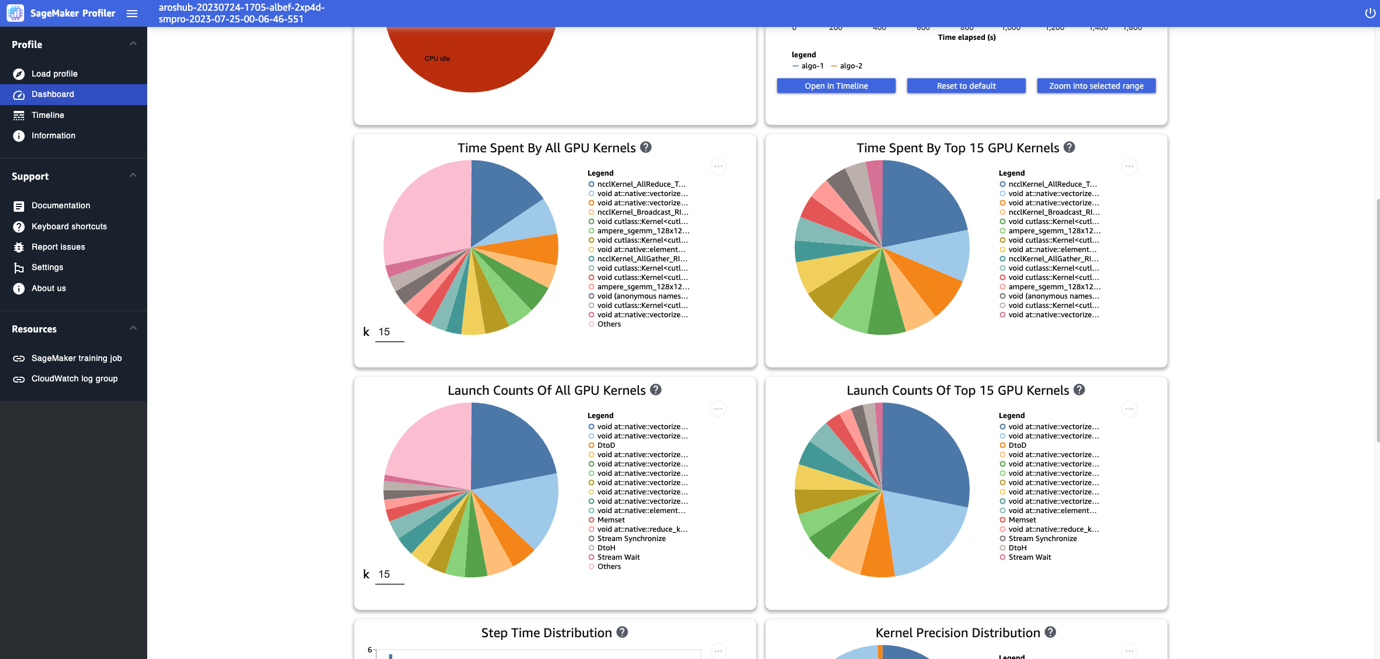
Infine, il pannello di controllo consente di visualizzare metriche aggiuntive, come la distribuzione del tempo di esecuzione delle operazioni, che è un istogramma che mostra la distribuzione delle durate delle operazioni sulle GPU, e il grafico a torta della distribuzione della precisione del kernel, che mostra la percentuale di tempo trascorso nell’esecuzione dei kernel in diversi tipi di dati come FP32, FP16, INT32 e INT8.
Puoi anche ottenere un grafico a torta sulla distribuzione delle attività della GPU che mostra la percentuale di tempo trascorso nelle attività della GPU, come l’esecuzione dei kernel, la memoria (memcpy e memset) e la sincronizzazione (sync). Puoi visualizzare la percentuale di tempo trascorso nelle operazioni di memoria della GPU dal grafico a torta della distribuzione delle operazioni di memoria della GPU.
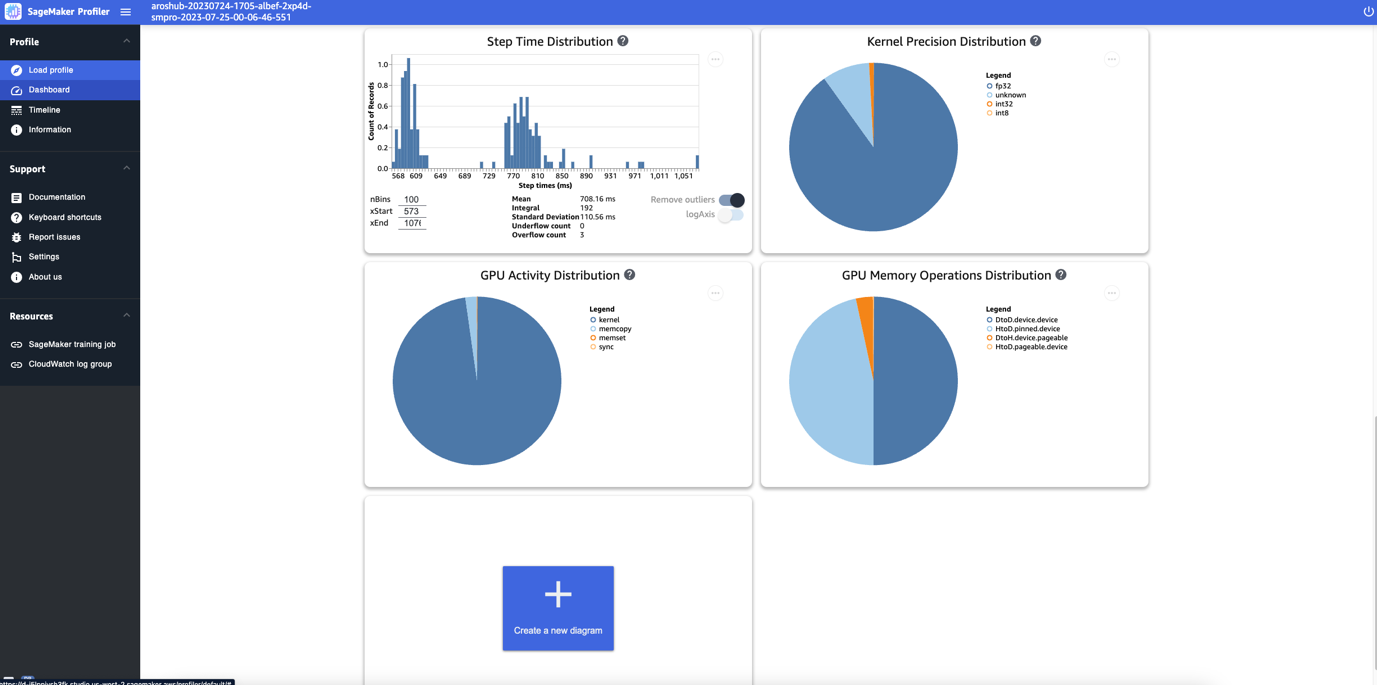
Puoi anche creare i tuoi istogrammi basati su una metrica personalizzata che hai annotato manualmente come descritto in precedenza in questo post. Quando aggiungi un’annotazione personalizzata a un nuovo istogramma, seleziona o inserisci il nome dell’annotazione che hai aggiunto nello script di training.
Interfaccia della timeline
L’interfaccia di SageMaker Profiler include anche una timeline, che fornisce una vista dettagliata delle risorse di calcolo a livello di operazioni e kernel pianificati sulle CPU ed eseguiti sulle GPU. La timeline è organizzata in una struttura ad albero, fornendo informazioni dal livello host al livello dispositivo, come mostrato nella seguente immagine.
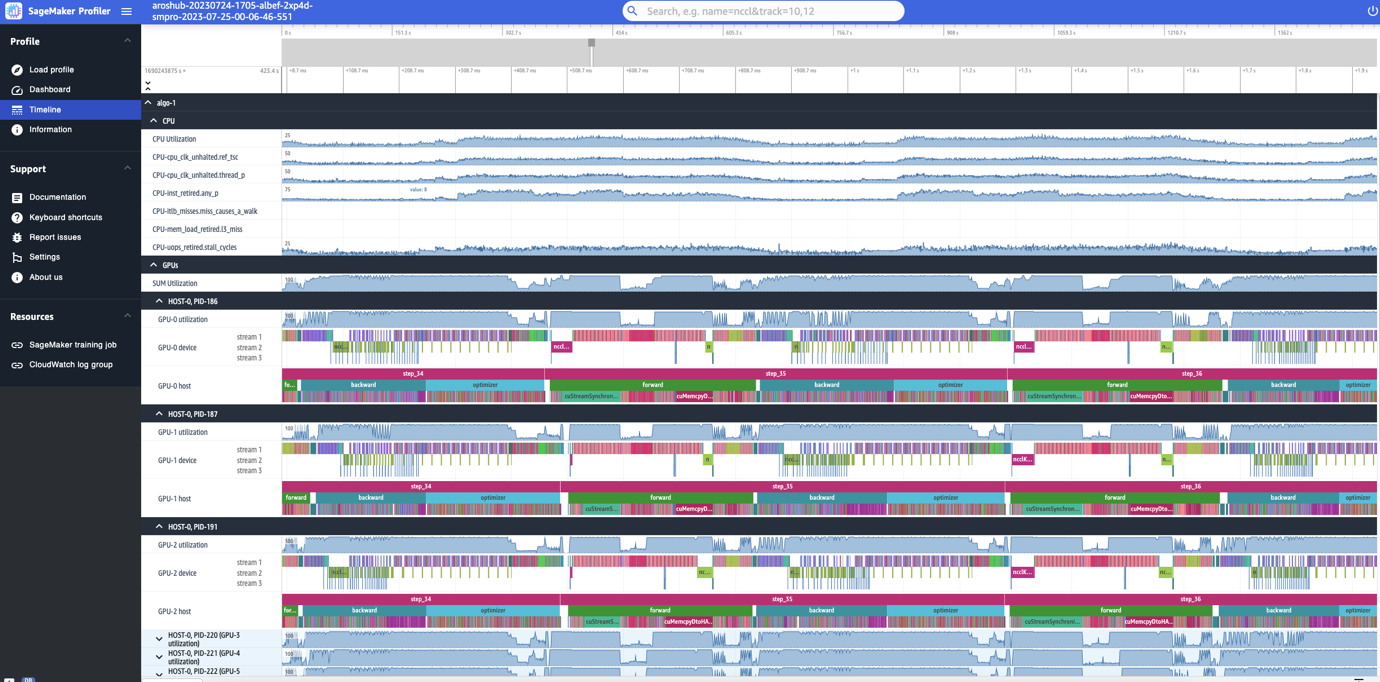
Per ogni CPU, è possibile monitorare i contatori di prestazioni della CPU, come clk_unhalted_ref.tsc e itlb_misses.miss_causes_a_walk. Per ogni GPU sull’istanza p4d.24xlarge 2x, è possibile visualizzare una timeline dell’host e una timeline del dispositivo. I lanci dei kernel sono sulla timeline dell’host e le esecuzioni dei kernel sono sulla timeline del dispositivo.
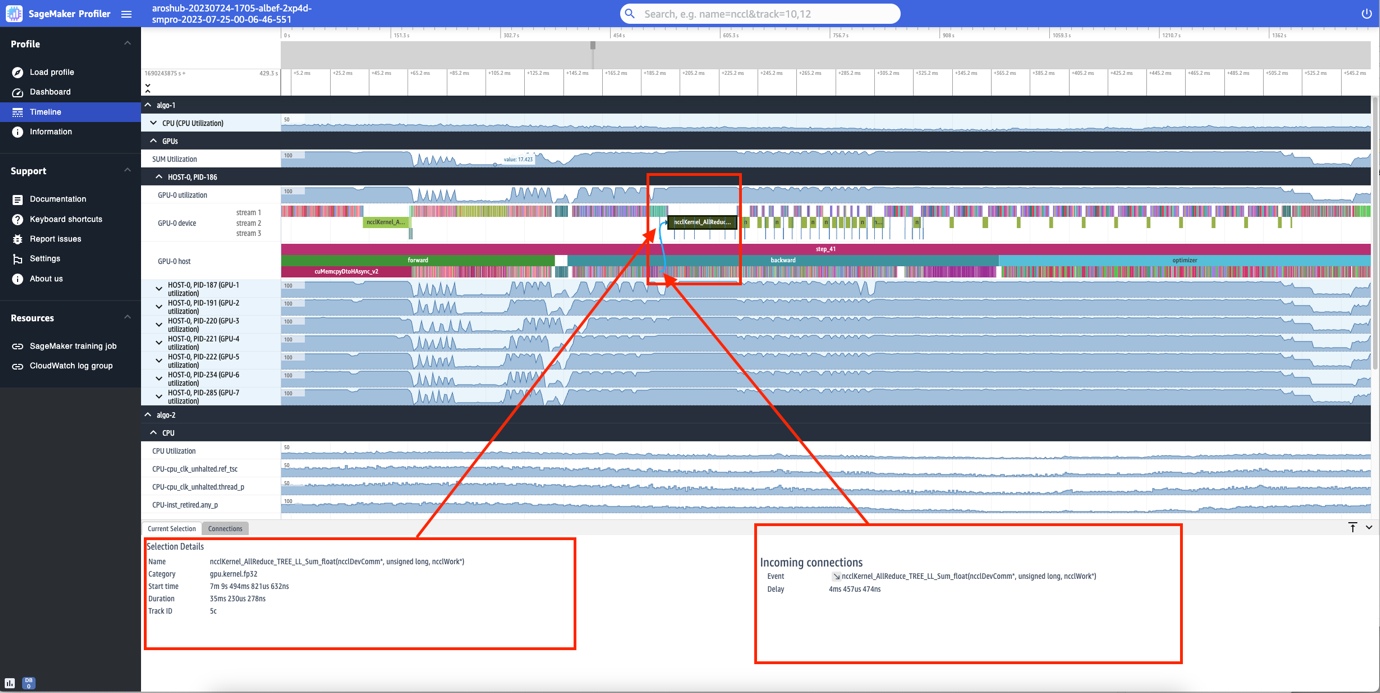
Puoi anche zoomare nei singoli passaggi. Nella seguente schermata, abbiamo ingrandito il passaggio_41. La striscia temporale selezionata nella seguente schermata è l’operazione AllReduce, un passaggio essenziale di comunicazione e sincronizzazione nell’allenamento distribuito, eseguito su GPU-0. Nella schermata, nota che il lancio del kernel nell’host GPU-0 si collega all’esecuzione del kernel nel flusso del dispositivo GPU-0 1, indicato dalla freccia in ciano.
Disponibilità e considerazioni
SageMaker Profiler è disponibile in PyTorch (versione 2.0.0 e 1.13.1) e TensorFlow (versione 2.12.0 e 2.11.1). La seguente tabella fornisce i link ai AWS Deep Learning Containers supportati per SageMaker.
| Framework | Versione | URI immagine AWS DLC |
| PyTorch | 2.0.0 | 763104351884.dkr.ecr.<region>.amazonaws.com/pytorch-training:2.0.0-gpu-py310-cu118-ubuntu20.04-sagemaker |
| PyTorch | 1.13.1 | 763104351884.dkr.ecr.<region>.amazonaws.com/pytorch-training:1.13.1-gpu-py39-cu117-ubuntu20.04-sagemaker |
| TensorFlow | 2.12.0 | 763104351884.dkr.ecr.<region>.amazonaws.com/tensorflow-training:2.12.0-gpu-py310-cu118-ubuntu20.04-sagemaker |
| TensorFlow | 2.11.1 | 763104351884.dkr.ecr.<region>.amazonaws.com/tensorflow-training:2.11.1-gpu-py39-cu112-ubuntu20.04-sagemaker |
SageMaker Profiler è attualmente disponibile nelle seguenti regioni: US East (Ohio, N. Virginia), US West (Oregon) e Europa (Francoforte, Irlanda).
SageMaker Profiler è disponibile nei tipi di istanza di training ml.p4d.24xlarge, ml.p3dn.24xlarge e ml.g4dn.12xlarge.
Per l’elenco completo dei framework e delle versioni supportate, consulta la documentazione.
SageMaker Profiler comporta costi dopo la versione gratuita di SageMaker o il periodo di prova gratuito della funzionalità. Per ulteriori informazioni, consulta il listino prezzi di Amazon SageMaker.
Prestazioni di SageMaker Profiler
Abbiamo confrontato l’impatto di SageMaker Profiler con vari profiler open-source. La base utilizzata per il confronto è stata ottenuta dall’esecuzione del job di training senza un profiler.
La nostra principale scoperta ha rivelato che SageMaker Profiler ha generalmente comportato una durata di addestramento fatturabile più breve perché aveva meno tempo di overhead nell’intero processo di addestramento. Ha anche generato meno dati di profilazione (fino a 10 volte meno) rispetto alle alternative open-source. Gli artefatti di profilazione più piccoli generati da SageMaker Profiler richiedono meno spazio di archiviazione, risparmiando anche sui costi.
Conclusioni
SageMaker Profiler ti consente di ottenere dettagliate informazioni sull’utilizzo delle risorse di calcolo durante l’addestramento dei tuoi modelli di deep learning. Ciò ti permette di risolvere i punti critici delle prestazioni e i colli di bottiglia per garantire un efficiente utilizzo delle risorse che alla fine ridurrà i costi di addestramento e la durata complessiva dell’addestramento.
Per iniziare con SageMaker Profiler, consulta la documentazione.