Insegnare ai modelli di linguaggio a ragionare in modo algoritmico
Insegnare l'algoritmo ai modelli di linguaggio
Pubblicato da Hattie Zhou, studente laureato presso MILA, Hanie Sedghi, ricercatore scientifico presso Google
I grandi modelli di linguaggio (LLM), come GPT-3 e PaLM, hanno mostrato un notevole progresso negli ultimi anni, che è stato favorito dall’aumento delle dimensioni dei modelli e dei dati di addestramento. Tuttavia, c’è stato un dibattito duraturo sul fatto che i LLM possano ragionare in modo simbolico (cioè manipolare simboli basandosi su regole logiche). Ad esempio, i LLM sono in grado di eseguire operazioni aritmetiche semplici quando i numeri sono piccoli, ma faticano ad eseguirle con numeri grandi. Ciò suggerisce che i LLM non hanno imparato le regole sottostanti necessarie per eseguire queste operazioni aritmetiche.
Anche se le reti neurali hanno potenti capacità di riconoscimento dei pattern, sono inclini a sovradattarsi ai pattern statistici spurii nei dati. Questo non ostacola le buone prestazioni quando i dati di addestramento sono numerosi e diversificati e la valutazione è in-distribuzione. Tuttavia, per compiti che richiedono un ragionamento basato su regole (come l’addizione), i LLM faticano a generalizzare fuori distribuzione poiché le correlazioni spurie nei dati di addestramento sono spesso molto più facili da sfruttare rispetto alla vera soluzione basata su regole. Di conseguenza, nonostante significativi progressi in una varietà di compiti di elaborazione del linguaggio naturale, le prestazioni in compiti aritmetici semplici come l’addizione sono rimaste una sfida. Anche con un modesto miglioramento di GPT-4 sul dataset MATH, gli errori sono ancora in gran parte dovuti a errori aritmetici e di calcolo. Pertanto, una domanda importante è se i LLM siano in grado di ragionamento algoritmico, che implica la risoluzione di un compito mediante l’applicazione di un insieme di regole astratte che definiscono l’algoritmo.
In “Insegnare il ragionamento algoritmico tramite apprendimento in contesto”, descriviamo un approccio che sfrutta l’apprendimento in contesto per abilitare i LLM a ragionare in modo algoritmico. L’apprendimento in contesto si riferisce alla capacità di un modello di eseguire un compito dopo aver visto alcuni esempi di esso all’interno del contesto del modello. Il compito viene specificato al modello utilizzando un prompt, senza la necessità di aggiornamenti dei pesi. Presentiamo anche una nuova tecnica di prompt algoritmico che consente ai modelli di linguaggio a uso generale di ottenere una forte generalizzazione su problemi di aritmetica più difficili rispetto a quelli presenti nel prompt. Infine, dimostriamo che un modello può eseguire in modo affidabile algoritmi su esempi fuori distribuzione con una scelta appropriata di strategia di prompting.
- L’algoritmo di Google rende l’encryption FIDO al sicuro dai computer quantistici
- Rendere sfocato lo schermo del tuo telefono potrebbe fermare lo spiare
- Gli annunci di YouTube potrebbero aver portato al tracciamento online dei bambini, secondo una ricerca
 |
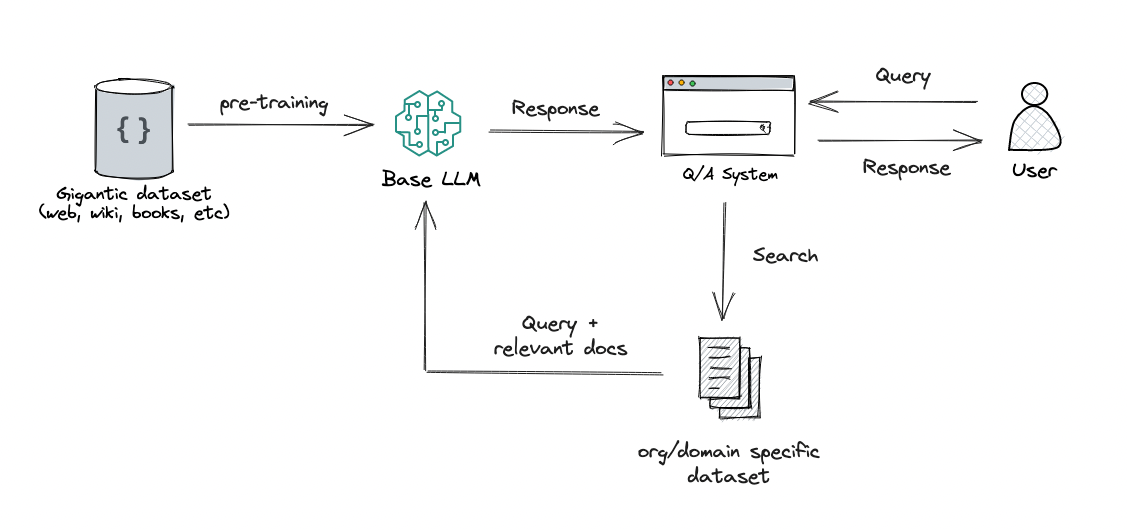
| Fornendo prompt algoritmici, possiamo insegnare a un modello le regole dell’aritmetica tramite apprendimento in contesto. In questo esempio, il LLM (predittore di parole) restituisce la risposta corretta quando sollecitato con una semplice domanda di addizione (ad esempio, 267+197), ma fallisce quando viene posta una domanda di addizione simile con cifre più lunghe. Tuttavia, quando la domanda più difficile viene completata con un prompt algoritmico per l’addizione (casella blu con il segno + mostrato sotto il predittore di parole), il modello è in grado di rispondere correttamente. Inoltre, il modello è in grado di simulare l’algoritmo di moltiplicazione (X) componendo una serie di calcoli di addizione. |
Insegnare un algoritmo come una competenza
Per insegnare a un modello un algoritmo come una competenza, sviluppiamo il prompting algoritmico, che si basa su altri approcci potenziati dalla ragione (ad esempio, taccuino e catena di pensiero). Il prompting algoritmico estrae capacità di ragionamento algoritmico dai LLM e presenta due distinzioni notevoli rispetto ad altri approcci di prompting: (1) risolve i compiti producendo le fasi necessarie per una soluzione algoritmica e (2) spiega ogni passaggio algoritmico con dettagli sufficienti in modo da non lasciare spazio a interpretazioni errate da parte del LLM.
Per acquisire intuizioni sul prompting algoritmico, consideriamo il compito dell’addizione di due numeri. In un prompt di tipo taccuino, elaboriamo ogni cifra da destra a sinistra e teniamo traccia del valore di trasporto (ovvero aggiungiamo un 1 alla cifra successiva se la cifra corrente è maggiore di 9) ad ogni passo. Tuttavia, la regola del trasporto è ambigua dopo aver visto solo alcuni esempi di valori di trasporto. Abbiamo scoperto che includere equazioni esplicite per descrivere la regola del trasporto aiuta il modello a concentrarsi sui dettagli rilevanti e a interpretare il prompt in modo più preciso. Utilizziamo questa intuizione per sviluppare un prompt algoritmico per l’addizione di due numeri, in cui forniamo equazioni esplicite per ogni passaggio di calcolo e descriviamo varie operazioni di indicizzazione in formati non ambigui.
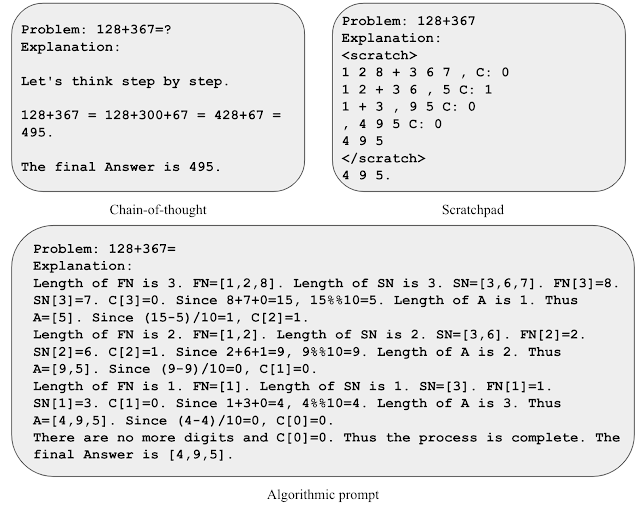 |
| Illustrazione di varie strategie di prompt per l’addizione. |
Utilizzando solo tre esempi di prompt per l’addizione con una lunghezza di risposta di fino a cinque cifre, valutiamo le prestazioni su addizioni di fino a 19 cifre. L’accuratezza viene misurata su 2.000 esempi totali campionati uniformemente sulla lunghezza della risposta. Come mostrato di seguito, l’uso di prompt algoritmici mantiene un’alta accuratezza per domande significativamente più lunghe rispetto a quelle presenti nel prompt, il che dimostra che il modello sta effettivamente risolvendo il compito eseguendo un algoritmo indipendente dall’input.
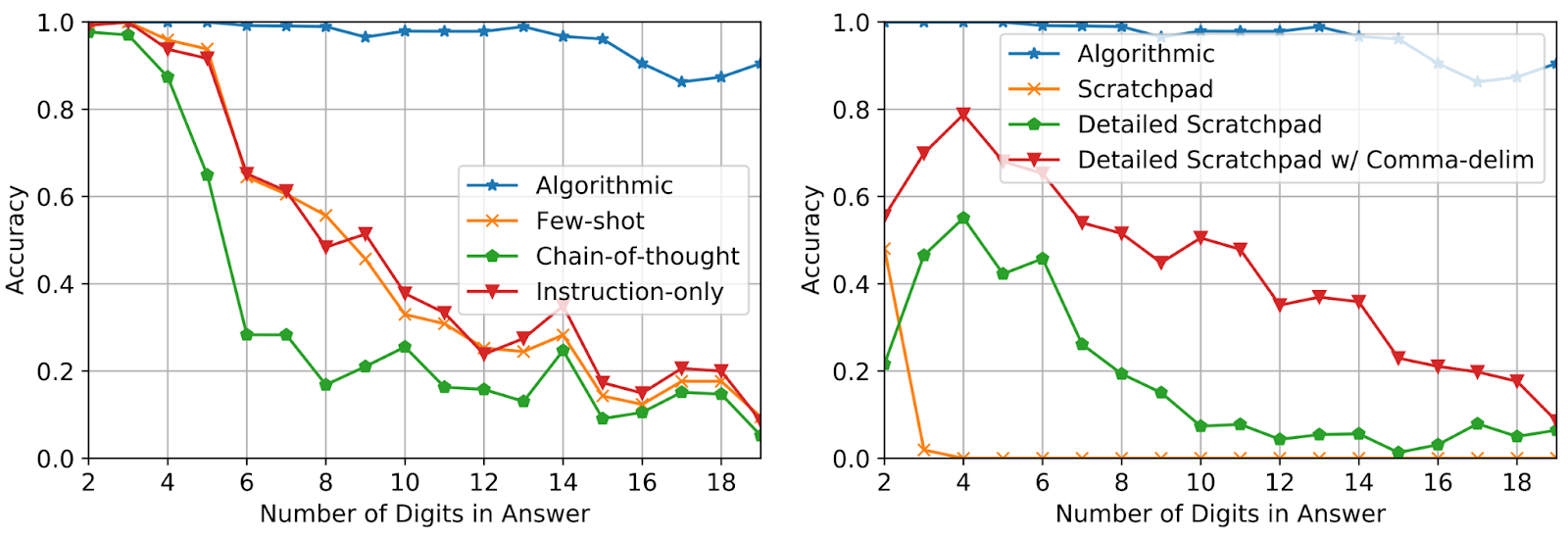 |
| Precisione del test su domande di addizione di lunghezza crescente per diversi metodi di prompt. |
Sfruttare le competenze algoritmiche come strumento
Per valutare se il modello può sfruttare il ragionamento algoritmico in un processo di ragionamento più ampio, valutiamo le prestazioni utilizzando problemi di matematica delle scuole medie (GSM8k). In particolare, cerchiamo di sostituire i calcoli di addizione da GSM8k con una soluzione algoritmica.
Motivati dalle limitazioni della lunghezza del contesto e dalle possibili interferenze tra algoritmi diversi, esploriamo una strategia in cui modelli con prompt diversi interagiscono tra loro per risolvere compiti complessi. Nel contesto di GSM8k, abbiamo un modello specializzato nel ragionamento matematico informale che utilizza il prompt di catena di pensiero e un secondo modello specializzato nell’addizione che utilizza il prompt algoritmico. Il modello di ragionamento matematico informale viene sollecitato a produrre token specializzati per chiamare il modello sollecitato dall’addizione per eseguire i passaggi aritmetici. Estrarriamo le query tra i token, le inviamo al modello di addizione e restituiamo la risposta al primo modello, dopodiché il primo modello continua la sua uscita. Valutiamo il nostro approccio utilizzando un problema difficile del GSM8k (GSM8k-Hard), in cui selezioniamo casualmente 50 domande solo di addizione e aumentiamo i valori numerici nelle domande.
 |
| Un esempio dal dataset GSM8k-Hard. Il prompt di catena di pensiero è ampliato con parentesi per indicare quando deve essere eseguita una chiamata algoritmica. |
Troviamo che utilizzare contesti e modelli separati con prompt specializzati sia un modo efficace per affrontare GSM8k-Hard. Di seguito, osserviamo che le prestazioni del modello con chiamata algoritmica per l’addizione sono 2,3 volte superiori alla linea guida del ragionamento a catena di pensiero. Infine, questa strategia presenta un esempio di risoluzione di compiti complessi facilitando le interazioni tra LLM specializzati in diverse competenze tramite l’apprendimento in contesto.
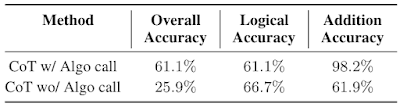 |
| Prestazioni del ragionamento a catena di pensiero (CoT) su GSM8k-Hard con o senza chiamata algoritmica. |
Conclusioni
Presentiamo un approccio che sfrutta l’apprendimento in contesto e una nuova tecnica di sollecitazione algoritmica per sbloccare le capacità di ragionamento algoritmico nelle LLM. I nostri risultati suggeriscono che potrebbe essere possibile trasformare un contesto più lungo in prestazioni di ragionamento migliori fornendo spiegazioni più dettagliate. Pertanto, queste scoperte indicano la capacità di utilizzare o altrimenti simulare contesti lunghi e generare razionali più informativi come promettenti direzioni di ricerca.
Riconoscimenti
Ringraziamo i nostri co-autori Behnam Neyshabur, Azade Nova, Hugo Larochelle e Aaron Courville per i loro preziosi contributi al paper e i preziosi feedback sul blog. Ringraziamo Tom Small per la creazione delle animazioni in questo post. Questo lavoro è stato svolto durante lo stage di Hattie Zhou presso Google Research.