Rileva il linguaggio dannoso nelle conversazioni parlate con Amazon Transcribe Toxicity Detection
Rileva linguaggio dannoso con Amazon Transcribe Toxicity Detection
L’aumento delle attività sociali online come i social network o i giochi online è spesso caratterizzato da comportamenti ostili o aggressivi che possono portare a manifestazioni non richieste di discorsi di odio, cyberbullismo o molestie. Ad esempio, molte comunità di giochi online offrono funzionalità di chat vocale per facilitare la comunicazione tra gli utenti. Sebbene la chat vocale spesso supporti scambi amichevoli e “trash talking”, può anche causare problemi come discorsi di odio, cyberbullismo, molestie e truffe. Segnalare linguaggio nocivo aiuta le organizzazioni a mantenere conversazioni civili e a mantenere un ambiente online sicuro e inclusivo in cui gli utenti possono creare, condividere e partecipare liberamente. Oggi molte aziende si affidano esclusivamente a moderatori umani per revisionare i contenuti tossici. Tuttavia, scalare i moderatori umani per soddisfare queste esigenze con una qualità e velocità sufficienti è costoso. Di conseguenza, molte organizzazioni rischiano alti tassi di disaffezione degli utenti, danni alla reputazione e multe regolamentari. Inoltre, i moderatori sono spesso colpiti psicologicamente dalla revisione dei contenuti tossici.
Amazon Transcribe è un servizio di riconoscimento automatico del parlato (ASR) che facilita ai programmatori l’aggiunta della capacità di conversione del parlato in testo alle loro applicazioni. Oggi siamo entusiasti di annunciare Amazon Transcribe Toxicity Detection, una funzionalità basata sull’apprendimento automatico (ML) che utilizza segnali audio e testuali per identificare e classificare i contenuti tossici basati sulla voce in sette categorie, tra cui molestie sessuali, discorsi di odio, minacce, abusi, volgarità, insulti e linguaggio grafico. Oltre al testo, Toxicity Detection utilizza segnali vocali come toni e intonazioni per individuare l’intento tossico nella voce.
Questo è un miglioramento rispetto ai sistemi standard di moderazione dei contenuti che sono progettati per concentrarsi solo su termini specifici, senza considerare l’intenzione. La maggior parte delle aziende ha un SLA di 7-15 giorni per la revisione dei contenuti segnalati dagli utenti perché i moderatori devono ascoltare lunghi file audio per valutare se e quando la conversazione è diventata tossica. Con Amazon Transcribe Toxicity Detection, i moderatori revisionano solo la parte specifica del file audio segnalato come contenuto tossico (rispetto all’intero file audio). Il contenuto che i moderatori umani devono revisionare viene ridotto del 95%, consentendo ai clienti di ridurre il loro SLA a poche ore, nonché di consentire loro di moderare in modo proattivo più contenuti oltre a quelli segnalati dagli utenti. Consentirà alle aziende di rilevare e moderare automaticamente i contenuti su larga scala, fornire un ambiente online sicuro e inclusivo e agire prima che possa causare un’alta disaffezione degli utenti o danni alla reputazione. I modelli utilizzati per la rilevazione dei contenuti tossici sono gestiti da Amazon Transcribe e aggiornati periodicamente per mantenere accuratezza e pertinenza.
In questo post, imparerai come:
- GPU NVIDIA H100 ora disponibili su AWS Cloud
- I creativi stanno reagendo all’IA con azioni legali
- Il futuro della guerra, totalmente autonomo e alimentato dall’IA, è qui
- Identificare contenuti dannosi nel parlato con Amazon Transcribe Toxicity Detection
- Utilizzare la console di Amazon Transcribe per la rilevazione della tossicità
- Creare un lavoro di trascrizione con rilevazione della tossicità utilizzando l’interfaccia della riga di comando di AWS (AWS CLI) e l’SDK Python
- Utilizzare la risposta dell’API di rilevamento della tossicità di Amazon Transcribe
Rilevare la tossicità nella chat vocale con Amazon Transcribe Toxicity Detection
Amazon Transcribe offre ora una soluzione semplice basata su ML per individuare linguaggio dannoso nelle conversazioni verbali. Questa funzionalità è particolarmente utile per i social media, i giochi e le esigenze generali, eliminando la necessità per i clienti di fornire i propri dati per addestrare il modello di ML. Toxicity Detection classifica i contenuti audio tossici nelle seguenti sette categorie e fornisce un punteggio di confidenza (0-1) per ogni categoria:
- Volgarità – Discorsi che contengono parole, frasi o acronimi sgarbati, volgari o offensivi.
- Discorsi di odio – Discorsi che criticano, insultano, denunciano o deumanizzano una persona o un gruppo sulla base di un’identità (come razza, etnia, genere, religione, orientamento sessuale, abilità e origine nazionale).
- Sessualità – Discorsi che indicano interesse sessuale, attività o eccitazione utilizzando riferimenti diretti o indiretti a parti del corpo, caratteristiche fisiche o sesso.
- Insulti – Discorsi che includono un linguaggio denigratorio, umiliante, beffardo, insultante o umiliante. Questo tipo di linguaggio viene anche etichettato come bullismo.
- Violenza o minaccia – Discorsi che includono minacce volte a infliggere dolore, lesioni o ostilità verso una persona o un gruppo.
- Grafico – Discorsi che utilizzano immagini descrittive e vivide in modo spiacevole. Questo tipo di linguaggio è spesso volutamente prolisso per amplificare il disagio del destinatario.
- Molestie o abuso – Discorsi intesi a influire sul benessere psicologico del destinatario, incluso l’utilizzo di termini denigratori e oggettificanti.
Puoi accedere alla rilevazione di tossicità sia tramite la console di Amazon Transcribe che chiamando direttamente le API utilizzando AWS CLI o gli SDK di AWS. Sulla console di Amazon Transcribe, puoi caricare i file audio che desideri testare per la tossicità e ottenere i risultati con pochi clic. Amazon Transcribe identificherà e categorizzerà contenuti tossici, come molestie, discorsi di odio, contenuti sessuali, violenza, insulti e volgarità. Amazon Transcribe fornisce anche un punteggio di fiducia per ogni categoria, offrendo preziosi insight sul livello di tossicità del contenuto. La rilevazione di tossicità è attualmente disponibile nella standard API di Amazon Transcribe per l’elaborazione batch e supporta la lingua inglese degli Stati Uniti.
Guida alla console di Amazon Transcribe
Per iniziare, accedi alla Console di Gestione AWS e vai su Amazon Transcribe. Per creare un nuovo lavoro di trascrizione, devi caricare i tuoi file registrati in un bucket di Amazon Simple Storage Service (Amazon S3) prima che possano essere elaborati. Nella pagina delle impostazioni audio, come mostrato nella seguente schermata, abilita Rilevazione di tossicità e procedi a creare il nuovo lavoro. Amazon Transcribe elaborerà il lavoro di trascrizione in background. Man mano che il lavoro progredisce, puoi aspettarti che lo stato cambi in COMPLETATO quando il processo è terminato.
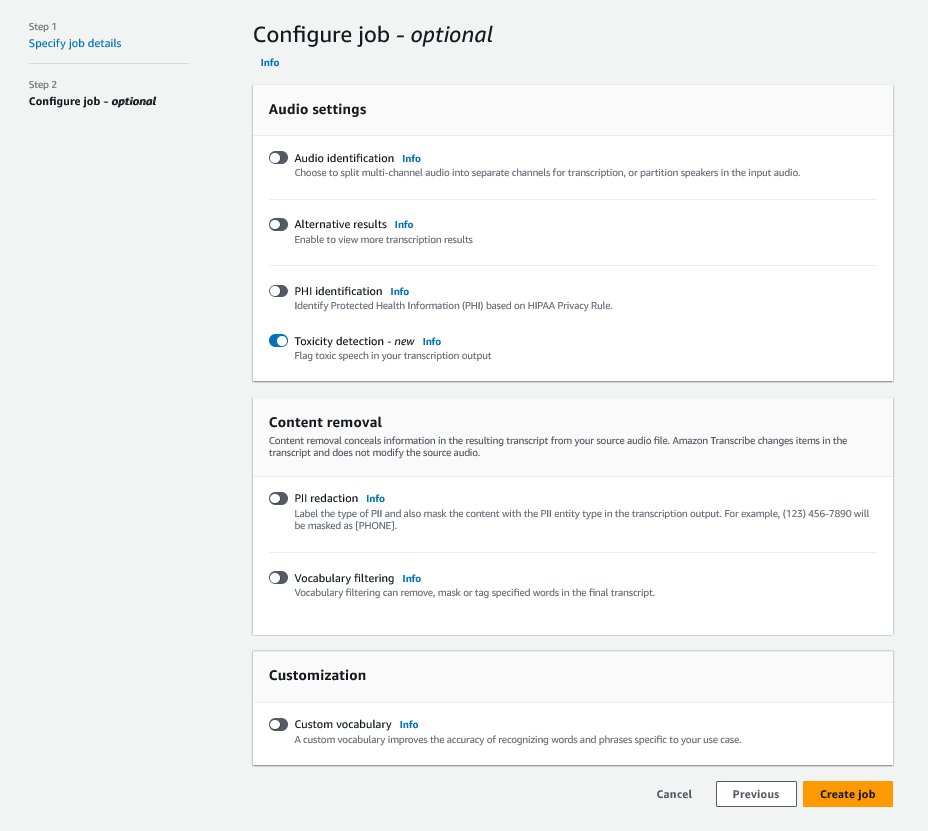
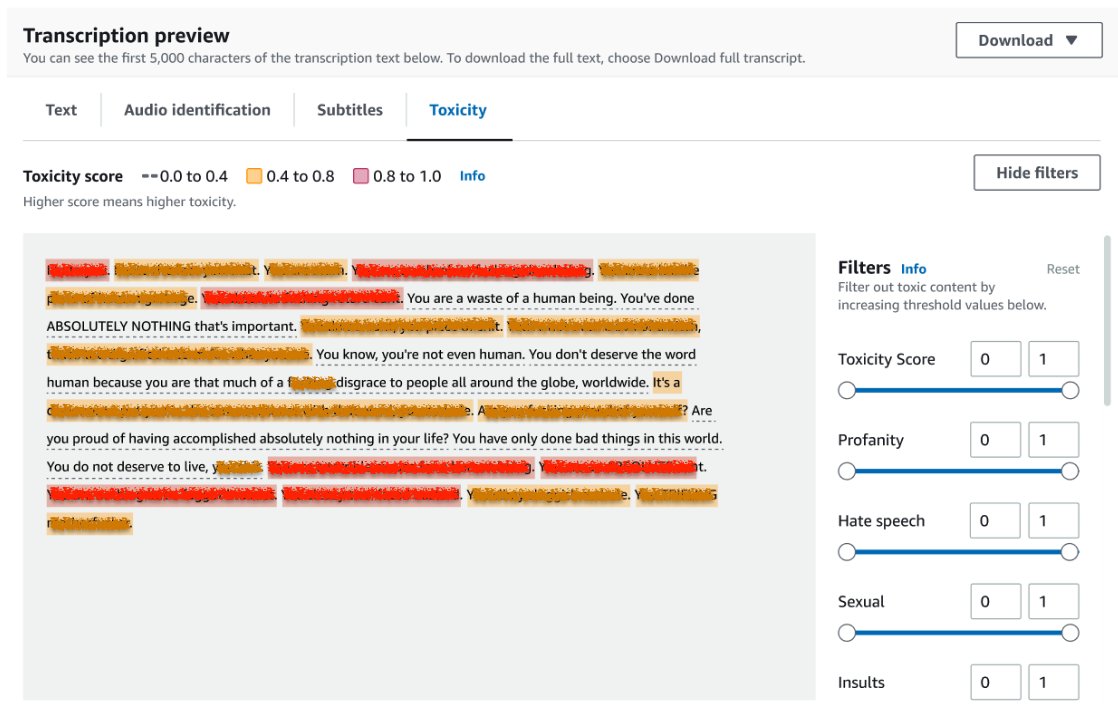
Per visualizzare i risultati di un lavoro di trascrizione, scegli il lavoro dalla lista dei lavori per aprirlo. Scorri verso il basso fino alla sezione Anteprima trascrizione per controllare i risultati sulla scheda Tossicità. L’interfaccia utente mostra segmenti di trascrizione colorati per indicare il livello di tossicità, determinato dal punteggio di fiducia. Per personalizzare la visualizzazione, puoi utilizzare le barre di commutazione nel pannello Filtri. Queste barre ti consentono di regolare le soglie e filtrare le categorie di tossicità di conseguenza.
La seguente schermata ha coperto porzioni del testo di trascrizione a causa della presenza di informazioni sensibili o tossiche.
API di trascrizione con richiesta di rilevazione di tossicità
In questa sezione, ti guidiamo attraverso la creazione di un lavoro di trascrizione con rilevazione di tossicità utilizzando le interfacce di programmazione. Se il file audio non è già in un bucket S3, caricalo per garantire l’accesso da parte di Amazon Transcribe. Similmente alla creazione di un lavoro di trascrizione sulla console, quando richiami il lavoro, devi fornire i seguenti parametri:
- TranscriptionJobName – Specifica un nome univoco per il lavoro.
- MediaFileUri – Inserisci l’URI del percorso del file audio su Amazon S3. Amazon Transcribe supporta i seguenti formati audio: MP3, MP4, WAV, FLAC, AMR, OGG o WebM
- LanguageCode – Impostato su
en-US. Al momento della scrittura, la rilevazione di tossicità supporta solo la lingua inglese degli Stati Uniti. - ToxicityCategories – Passa il valore
ALLper includere tutte le categorie di rilevazione di tossicità supportate.
I seguenti sono esempi per avviare un lavoro di trascrizione con rilevazione di tossicità abilitata utilizzando Python3:
import time
import boto3
transcribe = boto3.client('transcribe', 'us-east-1')
job_name = "demo-rilevazione-tossicità"
job_uri = "s3://il-mio-bucket/la-mia-cartella/il-mio-file.wav"
# avvia un lavoro di trascrizione
transcribe.start_transcription_job(
TranscriptionJobName = job_name,
Media = { 'MediaFileUri': job_uri },
OutputBucketName = 'esempio-bucket-documentazione',
OutputKey = 'miei-file-output/',
LanguageCode = 'en-US',
ToxicityDetection = [{'ToxicityCategories': ['ALL']}]
)
# attendi il completamento del lavoro di trascrizione
while True:
status = transcribe.get_transcription_job(TranscriptionJobName = job_name)
if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']:
break
print("Non ancora pronto...")
time.sleep(5)
print(status)Puoi richiamare lo stesso lavoro di trascrizione con rilevamento della tossicità utilizzando il seguente comando AWS CLI:
aws transcribe start-transcription-job \
--region us-east-1 \
--transcription-job-name toxicity-detection-demo \
--media MediaFileUri=s3://my-bucket/my-folder/my-file.wav \
--output-bucket-name doc-example-bucket \
--output-key my-output-files/ \
--language-code en-US \
--toxicity-detection ToxicityCategories=ALLRisposta dell’API di trascrizione con rilevamento della tossicità
L’output JSON del rilevamento della tossicità di Amazon Transcribe includerà i risultati della trascrizione nel campo dei risultati. L’abilitazione del rilevamento della tossicità aggiunge un campo extra chiamato toxicityDetection sotto il campo dei risultati. toxicityDetection include un elenco di elementi trascritti con i seguenti parametri:
- text – Il testo trascritto grezzo
- toxicity – Un punteggio di confidenza del rilevamento (un valore compreso tra 0 e 1)
- categories – Un punteggio di confidenza per ogni categoria del linguaggio tossico
- start_time – La posizione di inizio del rilevamento nel file audio (secondi)
- end_time – La posizione di fine del rilevamento nel file audio (secondi)
Di seguito è riportata una risposta abbreviata di rilevamento della tossicità di esempio che puoi scaricare dalla console:
{
"results":{
"transcripts": [...],
"items":[...],
"toxicityDetection": [
{
"text": "UN SEGMENTO DI TRASCRIZIONE TOSSICA VA QUI.",
"toxicity": 0.8419,
"categories": {
"PROFANITÀ": 0.7041,
"DISCORSO_ODIATOSO": 0.0163,
"SESSUALE": 0.0097,
"INSULTO": 0.8532,
"VIOLENZA_O_MINACCIA": 0.0031,
"GRAFICO": 0.0017,
"MOLESTIA_O_ABUSO": 0.0497
},
"start_time": 16.298,
"end_time": 20.35
},
...
]
},
"status": "COMPLETATO"
}Sommario
In questo post, abbiamo fornito una panoramica della nuova funzionalità di rilevamento della tossicità di Amazon Transcribe. Abbiamo anche descritto come è possibile analizzare l’output JSON del rilevamento della tossicità. Per ulteriori informazioni, visita la console di Amazon Transcribe e prova l’API di trascrizione con rilevamento della tossicità.
Amazon Transcribe Toxicity Detection è ora disponibile nelle seguenti regioni AWS: US East (Ohio), US East (N. Virginia), US West (Oregon), Asia Pacific (Sydney), Europe (Ireland) e Europe (London). Per saperne di più, visita Amazon Transcribe.
Scopri di più sulla moderazione dei contenuti su AWS e sui nostri casi d’uso di moderazione dei contenuti basati su ML. Fai il primo passo per ottimizzare le tue operazioni di moderazione dei contenuti con AWS.





