Migliorare i modelli linguistici recuperando da trilioni di token
Recuperare modelli linguistici da trilioni di token per migliorarli.
Negli ultimi anni, significativi miglioramenti delle prestazioni nella modellazione autoregressiva del linguaggio sono stati ottenuti aumentando il numero di parametri nei modelli Transformer. Ciò ha portato ad un enorme aumento dei costi energetici di addestramento e ha generato densi “Large Language Models” (LLM) con oltre 100 miliardi di parametri. Allo stesso tempo, sono stati raccolti grandi dataset contenenti trilioni di parole per facilitare l’addestramento di questi LLM.
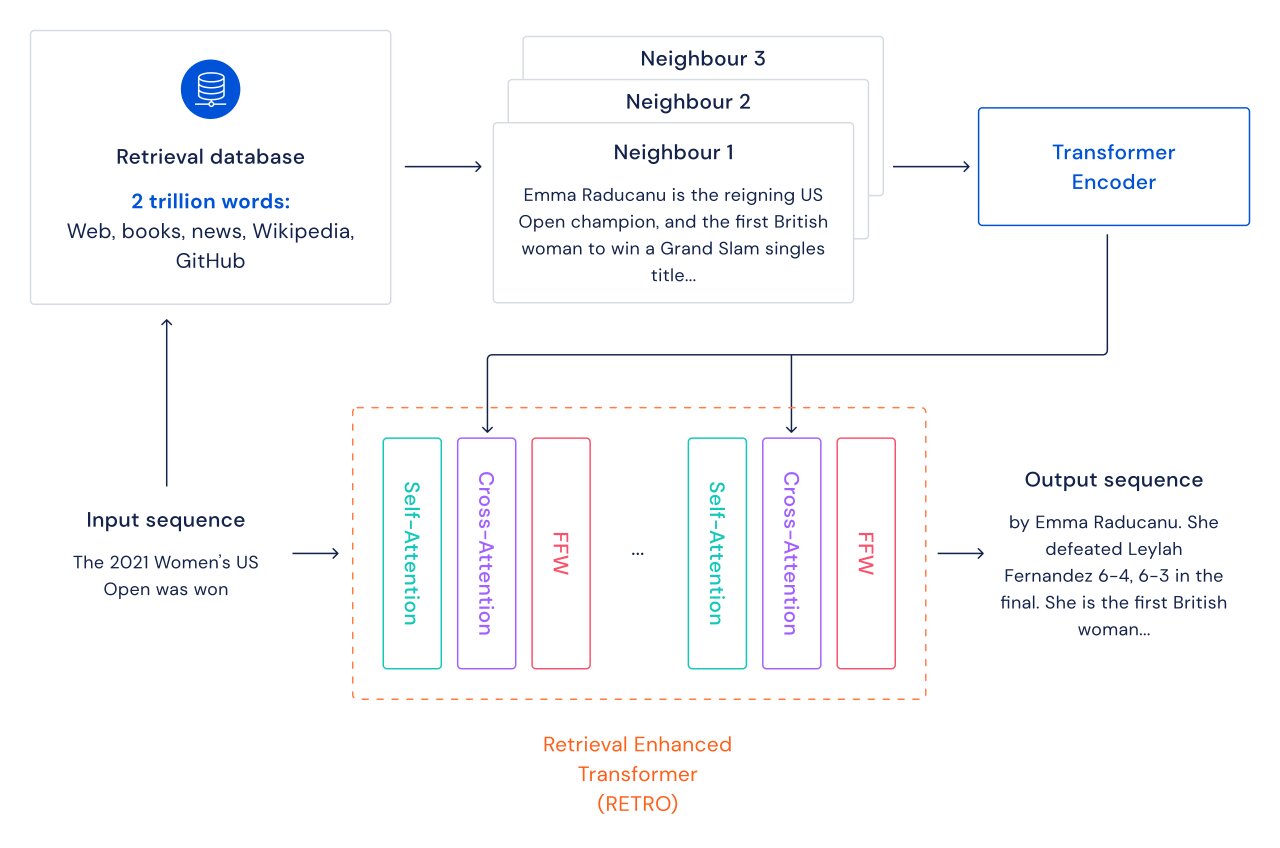
Esploriamo un percorso alternativo per migliorare i modelli di linguaggio: integriamo i transformer con il recupero di passaggi di testo da un database che include pagine web, libri, notizie e codice. Chiamiamo il nostro metodo RETRO, per “Retrieval Enhanced TRansfOrmers”.
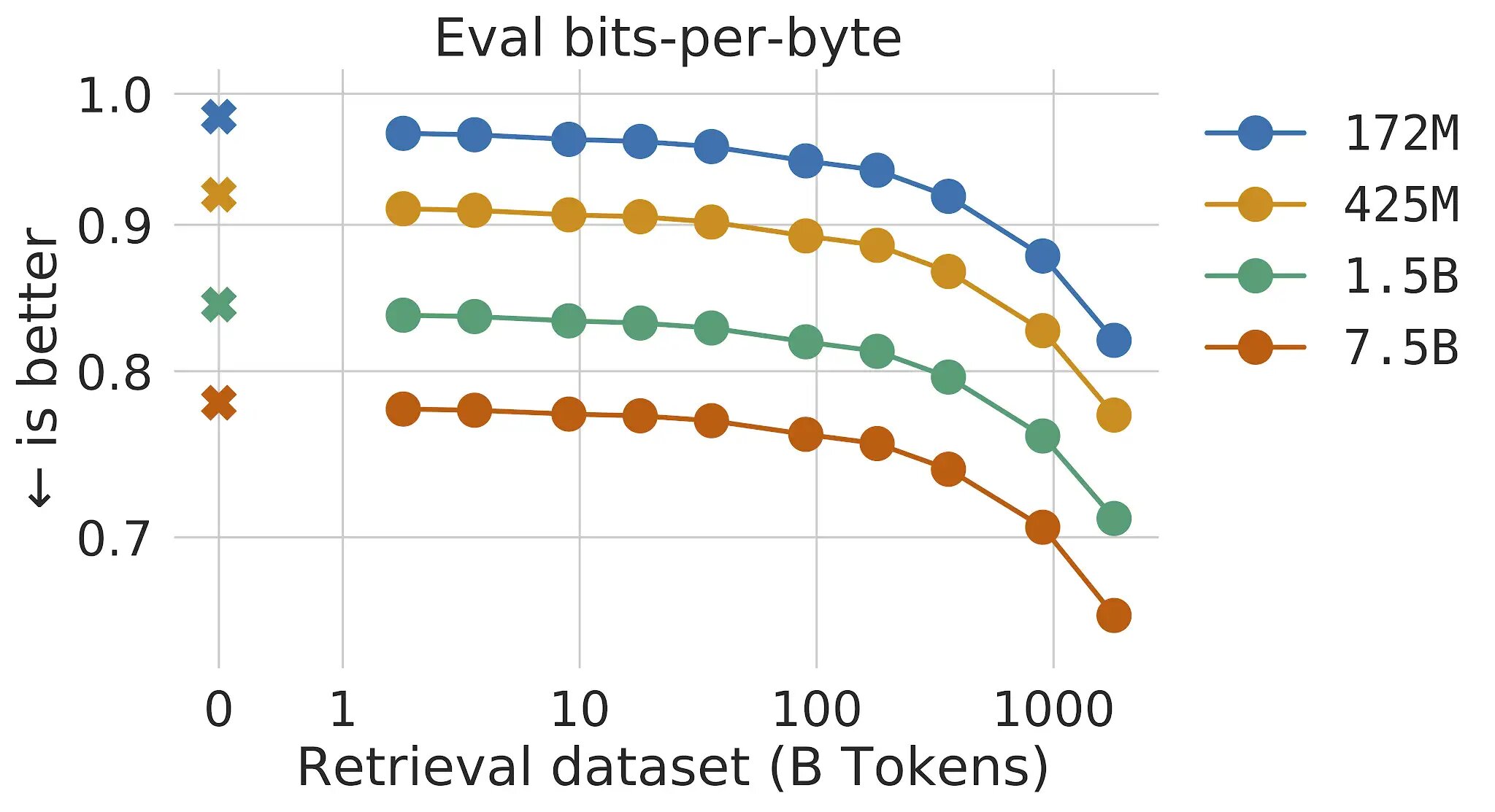
Nelle tradizionali modelli di linguaggio basati su transformer, i vantaggi delle dimensioni del modello e delle dimensioni del dataset sono correlati: fintanto che il dataset è abbastanza grande, le prestazioni della modellazione del linguaggio sono limitate dalle dimensioni del modello. Tuttavia, con RETRO il modello non è limitato ai dati visti durante l’addestramento: ha accesso all’intero dataset di addestramento tramite il meccanismo di recupero. Ciò comporta significativi miglioramenti delle prestazioni rispetto a un Transformer standard con lo stesso numero di parametri. Dimostriamo che la modellazione del linguaggio migliora continuamente all’aumentare delle dimensioni del database di recupero, almeno fino a 2 trilioni di token – 175 intere vite di lettura continua.
Per ogni passaggio di testo (approssimativamente un paragrafo di un documento), viene eseguita una ricerca del vicino più vicino che restituisce sequenze simili trovate nel database di addestramento e la loro continuazione. Queste sequenze aiutano a prevedere la continuazione del testo di input. L’architettura RETRO intercala l’auto-attenzione regolare a livello di documento e l’attenzione incrociata con i vicini recuperati a livello di passaggio più fine. Ciò porta a continuità più accurate e factuali. Inoltre, RETRO aumenta l’interpretabilità delle previsioni del modello e fornisce una via per interventi diretti attraverso il database di recupero per migliorare la sicurezza della continuazione del testo. Nei nostri esperimenti su Pile, un benchmark standard per la modellazione del linguaggio, un modello RETRO con 7.5 miliardi di parametri supera il Jurassic-1 con 175 miliardi di parametri su 10 dei 16 dataset e supera il Gopher con 280B su 9 dei 16 dataset.
- Modellizzazione del linguaggio su larga scala Gopher, considerazioni etiche e recupero
- Simulazione della materia su scala quantistica con l’IA
- La normatività spuria potenzia l’apprendimento del comportamento di conformità e di applicazione in agenti artificiali.
In seguito, mostriamo due esempi dal nostro modello di base 7B e dal nostro modello RETRO 7.5B che evidenziano come i campioni di RETRO siano più factuali e rimangano più sul tema rispetto al campione di base.








