La normatività spuria potenzia l’apprendimento del comportamento di conformità e di applicazione in agenti artificiali.
Spurious norms enhance the learning of compliance and application behavior in artificial agents.
Nel nostro recente articolo esploriamo come l’apprendimento profondo del rinforzo multi-agente possa servire come modello di interazioni sociali complesse, come la formazione di norme sociali. Questa nuova classe di modelli potrebbe fornire un percorso per creare simulazioni più ricche e dettagliate del mondo.
Gli esseri umani sono una specie estremamente sociale. Rispetto ad altri mammiferi, traiamo maggiori benefici dalla cooperazione, ma siamo anche più dipendenti da essa e affrontiamo sfide di cooperazione più grandi. Oggi, l’umanità si trova di fronte a numerose sfide di cooperazione, tra cui la prevenzione dei conflitti sulle risorse, garantire a tutti l’accesso a aria pulita e acqua potabile, eliminare la povertà estrema e contrastare il cambiamento climatico. Molti dei problemi di cooperazione che affrontiamo sono difficili da risolvere perché coinvolgono complessi intrecci di interazioni sociali e biologiche chiamati sistemi socio-ecologici. Tuttavia, gli esseri umani possono imparare collettivamente a superare le sfide di cooperazione che affrontiamo. Riusciamo a farlo attraverso una cultura in continua evoluzione, comprensiva di norme e istituzioni che organizzano le nostre interazioni con l’ambiente e tra di noi.
Tuttavia, le norme e le istituzioni a volte non riescono a risolvere le sfide di cooperazione. Ad esempio, gli individui possono sfruttare eccessivamente risorse come foreste e pesca, causandone il collasso. In tali casi, i responsabili delle politiche possono scrivere leggi per cambiare le regole istituzionali o sviluppare altre intenzioni per cercare di cambiare le norme nella speranza di ottenere un cambiamento positivo. Ma le intenzioni delle politiche non sempre funzionano come previsto. Questo perché i sistemi socio-ecologici del mondo reale sono considerevolmente più complessi rispetto ai modelli che solitamente utilizziamo per cercare di prevedere gli effetti delle politiche candidate.
I modelli basati sulla teoria dei giochi sono spesso applicati allo studio dell’evoluzione culturale. Nella maggior parte di questi modelli, le interazioni chiave che gli agenti hanno tra loro sono espresse in una “matrice dei pagamenti”. In un gioco con due partecipanti e due azioni A e B, una matrice dei pagamenti definisce il valore dei quattro possibili risultati: (1) entrambi scegliamo A, (2) entrambi scegliamo B, (3) io scelgo A mentre tu scegli B e (4) io scelgo B mentre tu scegli A. L’esempio più famoso è il “dilemma del prigioniero”, in cui le azioni sono interpretate come “cooperare” e “defezione”. Gli agenti razionali che agiscono secondo il loro egoistico interesse personale sono destinati a defezionare nel dilemma del prigioniero, anche se il risultato migliore della cooperazione reciproca è disponibile.
- DeepMind Il podcast torna per la seconda stagione
- Testare le Modelli di Linguaggio con i Modelli di Linguaggio
- Il primo passo di MuZero dalla ricerca al mondo reale
I modelli basati sulla teoria dei giochi sono stati ampiamente applicati. Ricercatori in diversi campi li hanno utilizzati per studiare una vasta gamma di fenomeni diversi, tra cui economia e evoluzione della cultura umana. Tuttavia, la teoria dei giochi non è uno strumento neutrale, ma è un linguaggio di modellazione profondamente opinabile. Impone un rigoroso requisito che tutto deve infine tradursi nella matrice dei pagamenti (o rappresentazione equivalente). Ciò significa che il modellatore deve conoscere, o essere disposto ad assumere, tutto su come gli effetti delle azioni individuali si combinano per generare incentivi. Ciò è talvolta appropriato e l’approccio della teoria dei giochi ha avuto molti successi notevoli, come nella modellazione del comportamento delle aziende oligopolistiche e delle relazioni internazionali dell’era della guerra fredda. Tuttavia, il principale punto debole della teoria dei giochi come linguaggio di modellazione si manifesta nelle situazioni in cui il modellatore non comprende pienamente come le scelte degli individui si combinino per generare pagamenti. Purtroppo, questo tende ad essere il caso dei sistemi socio-ecologici perché le loro parti sociali ed ecologiche interagiscono in modi complessi che non comprendiamo appieno.
Il lavoro che presentiamo qui è un esempio all’interno di un programma di ricerca che cerca di stabilire un framework di modellazione alternativo, diverso dalla teoria dei giochi, da utilizzare nello studio dei sistemi socio-ecologici. Il nostro approccio può essere visto formalmente come una varietà di modellazione basata sugli agenti. Tuttavia, la sua caratteristica distintiva è l’incorporazione di elementi algoritmici provenienti dall’intelligenza artificiale, in particolare l’apprendimento profondo del rinforzo multi-agente.
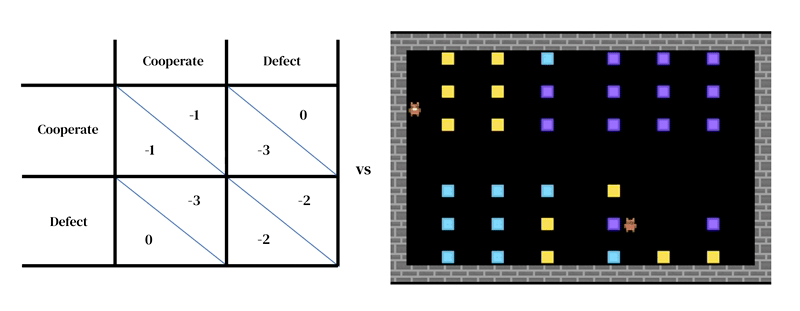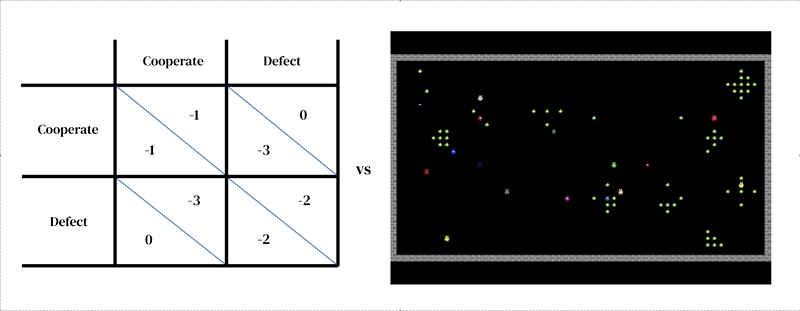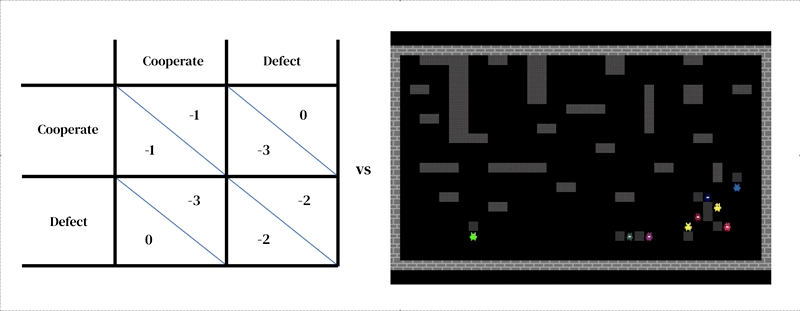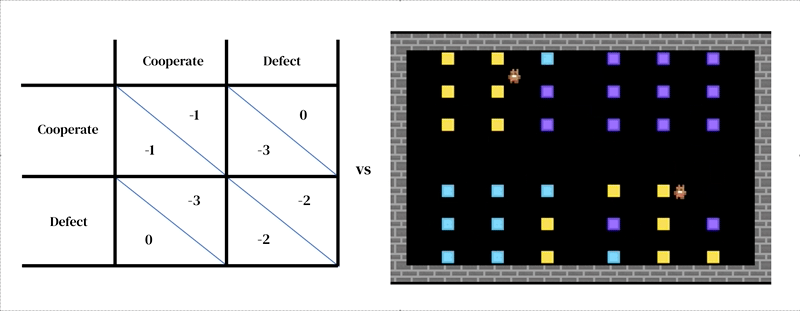
L’idea centrale di questo approccio è che ogni modello consiste di due parti interconnesse: (1) un modello dinamico e ricco dell’ambiente e (2) un modello di processo decisionale individuale.
Il primo assume la forma di un simulatore progettato dal ricercatore: un programma interattivo che prende uno stato ambientale attuale e le azioni degli agenti e restituisce lo stato ambientale successivo, nonché le osservazioni di tutti gli agenti e le loro ricompense istantanee. Anche il modello di processo decisionale individuale è condizionato allo stato dell’ambiente. È un agente che apprende dalla propria esperienza passata, facendo una forma di tentativi ed errori. Un agente interagisce con un ambiente assumendo osservazioni e restituendo azioni. Ogni agente seleziona le azioni in base alla propria politica comportamentale, una mappatura dalle osservazioni alle azioni. Gli agenti imparano cambiando la loro politica per migliorarla in qualsiasi dimensione desiderata, di solito per ottenere maggiori ricompense. La politica è memorizzata in una rete neurale. Gli agenti imparano “da zero”, dalla propria esperienza, come funziona il mondo e cosa possono fare per ottenere più ricompense. Ciò avviene regolando i pesi della loro rete in modo che i pixel che ricevono come osservazioni vengano gradualmente trasformati in azioni competenti. Più agenti di apprendimento possono coesistere nello stesso ambiente. In questo caso, gli agenti diventano interdipendenti perché le loro azioni si influenzano a vicenda.
Come altri approcci di modellizzazione basati sugli agenti, il multi-agent deep reinforcement learning rende più semplice specificare modelli che attraversano livelli di analisi che sarebbero difficili da trattare con la teoria dei giochi. Ad esempio, le azioni possono essere molto più vicine alle primitive motorie a basso livello (ad esempio, ‘cammina avanti’; ‘gira a destra’) rispetto alle decisioni strategiche ad alto livello della teoria dei giochi (ad esempio, ‘cooperare’). Questa è una caratteristica importante necessaria per catturare situazioni in cui gli agenti devono praticare per imparare efficacemente come implementare le loro scelte strategiche. Ad esempio, in uno studio, gli agenti hanno imparato a cooperare alternandosi nella pulizia di un fiume. Questa soluzione era possibile solo perché l’ambiente aveva dimensioni spaziali e temporali in cui gli agenti hanno grande libertà nel modo in cui strutturano il loro comportamento l’uno verso l’altro. Interessante, mentre l’ambiente consentiva molte soluzioni diverse (come la territorialità), gli agenti hanno convergito sulla stessa soluzione di alternanza come i giocatori umani.
Nel nostro ultimo studio, abbiamo applicato questo tipo di modello a una domanda aperta nella ricerca sull’evoluzione culturale: come spiegare l’esistenza di norme sociali spurie e arbitrarie che sembrano non avere conseguenze materiali immediate per la loro violazione oltre quelle imposte socialmente. Ad esempio, in alcune società si aspetta che gli uomini indossino pantaloni anziché gonne; in molte ci sono parole o gesti che non dovrebbero essere usati in compagnia educata; e nella maggior parte ci sono regole su come si deve pettinare i capelli o cosa si deve indossare in testa. Chiamiamo queste norme sociali “regole sciocche”. È importante sottolineare che nel nostro quadro teorico sia l’applicazione che il rispetto delle norme sociali devono essere appresi. Avere un ambiente sociale che include una “regola sciocca” significa che gli agenti hanno più opportunità per imparare a far rispettare le norme in generale. Questa pratica aggiuntiva consente loro poi di far rispettare le regole importanti in modo più efficace. Nel complesso, la “regola sciocca” può essere vantaggiosa per la popolazione – un risultato sorprendente. Questo risultato è possibile solo perché la nostra simulazione si concentra sull’apprendimento: far rispettare e rispettare le regole sono abilità complesse che richiedono allenamento per svilupparsi.
Una delle ragioni per cui troviamo così entusiasmante questo risultato sulle regole sciocche è che dimostra l’utilità del multi-agent deep reinforcement learning nella modellizzazione dell’evoluzione culturale. La cultura contribuisce al successo o al fallimento delle interventi politici per i sistemi socio-ecologici. Ad esempio, rafforzare le norme sociali intorno al riciclaggio fa parte della soluzione a alcuni problemi ambientali. Seguendo questa traiettoria, simulazioni più ricche potrebbero portare a una comprensione più approfondita di come progettare interventi per i sistemi socio-ecologici. Se le simulazioni diventano abbastanza realistiche, potrebbe persino essere possibile testare l’impatto degli interventi, ad esempio cercando di progettare un codice fiscale che favorisca la produttività e l’equità.
Questo approccio fornisce agli studiosi strumenti per specificare modelli dettagliati dei fenomeni che li interessano. Naturalmente, come tutte le metodologie di ricerca, ci si dovrebbe aspettare che abbia i suoi punti di forza e di debolezza. Speriamo di scoprire di più su quando questo stile di modellazione possa essere applicato in modo proficuo in futuro. Sebbene non esistano panacee per la modellazione, riteniamo che ci siano ragioni convincenti per guardare al multi-agent deep reinforcement learning quando si costruiscono modelli di fenomeni sociali, specialmente quando implicano l’apprendimento.






