Creazione di agenti interattivi con apprendimento per imitazione
'Creazione di agenti interattivi con apprendimento per imitazione' (Creation of interactive agents with imitation learning)
Gli esseri umani sono una specie interattiva. Interagiamo con il mondo fisico e tra di noi. Perché l’intelligenza artificiale (IA) sia utilmente generale, deve essere in grado di interagire in modo adeguato con gli esseri umani e il loro ambiente. In questo lavoro presentiamo l’Agente Interattivo Multimodale (MIA), che combina percezione visiva, comprensione e produzione del linguaggio, navigazione e manipolazione per impegnarsi in interazioni fisiche e linguistiche estese e spesso sorprendenti con gli esseri umani.

Ci basiamo sull’approccio introdotto da Abramson et al. (2020), che utilizza principalmente l’apprendimento per imitazione per addestrare gli agenti. Dopo l’addestramento, MIA mostra alcuni comportamenti intelligenti rudimentali che speriamo di perfezionare in seguito utilizzando il feedback umano. Questo lavoro si concentra sulla creazione di questa precedenza comportamentale intelligente e lasciamo ulteriori apprendimenti basati sul feedback per lavori futuri.
Abbiamo creato l’ambiente Playhouse, un ambiente virtuale 3D composto da un insieme casuale di stanze e un gran numero di oggetti domestici interattivi, per fornire uno spazio e un contesto in cui gli esseri umani e gli agenti possono interagire insieme. Gli esseri umani e gli agenti possono interagire nel Playhouse controllando robot virtuali che si spostano, manipolano oggetti e comunicano tramite testo. Questo ambiente virtuale permette una vasta gamma di dialoghi situati, che vanno dalle istruzioni semplici (ad esempio, “Per favore prendi il libro da terra e mettilo sulla libreria blu”) al gioco creativo (ad esempio, “Porta il cibo sul tavolo così possiamo mangiare”).
- Migliorare i modelli linguistici recuperando da trilioni di token
- Modellizzazione del linguaggio su larga scala Gopher, considerazioni etiche e recupero
- Simulazione della materia su scala quantistica con l’IA
Abbiamo raccolto esempi umani di interazioni nel Playhouse utilizzando giochi linguistici, una collezione di indizi che spingono gli esseri umani a improvvisare determinati comportamenti. In un gioco linguistico, un giocatore (il setter) riceve un prompt predefinito che indica un tipo di compito da proporre all’altro giocatore (il solver). Ad esempio, il setter potrebbe ricevere il prompt “Fai una domanda all’altro giocatore sull’esistenza di un oggetto” e, dopo un po’ di esplorazione, il setter potrebbe chiedere: “Per favore dimmi se c’è una papera blu in una stanza che non ha nemmeno mobili”. Per garantire una sufficiente diversità comportamentale, abbiamo incluso anche prompt a forma libera, che concedono ai setter la libertà di improvvisare interazioni (ad esempio, “Ora prendi qualsiasi oggetto che ti piace e colpisci la palla da tennis dallo sgabello in modo che rotoli vicino all’orologio, o da qualche parte vicino ad esso”). In totale, abbiamo raccolto 2,94 anni di interazioni umane in tempo reale nel Playhouse.
.jpg)
La nostra strategia di addestramento è una combinazione di previsione supervisionata delle azioni umane (clonazione comportamentale) e apprendimento auto-supervisionato. Nella previsione delle azioni umane, abbiamo scoperto che l’utilizzo di una strategia di controllo gerarchico migliora significativamente le prestazioni dell’agente. In questo contesto, l’agente riceve nuove osservazioni circa 4 volte al secondo. Per ogni osservazione, produce una sequenza di azioni di movimento a ciclo aperto e opzionalmente emette una sequenza di azioni linguistiche. Oltre alla clonazione comportamentale, utilizziamo una forma di apprendimento auto-supervisionato, che chiede agli agenti di classificare se determinati input visivi e linguistici appartengono agli stessi episodi o a episodi diversi.
Per valutare le prestazioni dell’agente, abbiamo chiesto ai partecipanti umani di interagire con gli agenti e fornire un feedback binario che indica se l’agente ha eseguito con successo un’istruzione. MIA raggiunge un tasso di successo superiore al 70% nelle interazioni online valutate dagli umani, che rappresenta il 75% del tasso di successo che gli umani stessi raggiungono quando giocano come solver. Per comprendere meglio il ruolo dei vari componenti in MIA, abbiamo effettuato una serie di ablation, rimuovendo ad esempio input visivi o linguistici, la perdita auto-supervisionata o il controllo gerarchico.
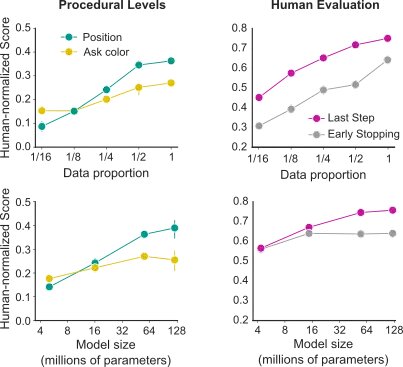
La ricerca contemporanea sull’apprendimento automatico ha scoperto notevoli regolarità delle prestazioni rispetto a diversi parametri di scala; in particolare, le prestazioni del modello aumentano come una legge di potenza con la dimensione del dataset, la dimensione del modello e il calcolo. Questi effetti sono stati osservati in modo più nitido nel dominio del linguaggio, che è caratterizzato da dimensioni di dataset massicce e architetture altamente evolute e protocolli di addestramento. In questo lavoro, tuttavia, ci troviamo in un regime decisamente diverso, con dataset relativamente piccoli e funzioni obiettivo multimodali e multitask che addestrano architetture eterogenee. Tuttavia, dimostriamo chiari effetti di scalabilità: aumentando la dimensione del dataset e del modello, le prestazioni aumentano in modo apprezzabile.
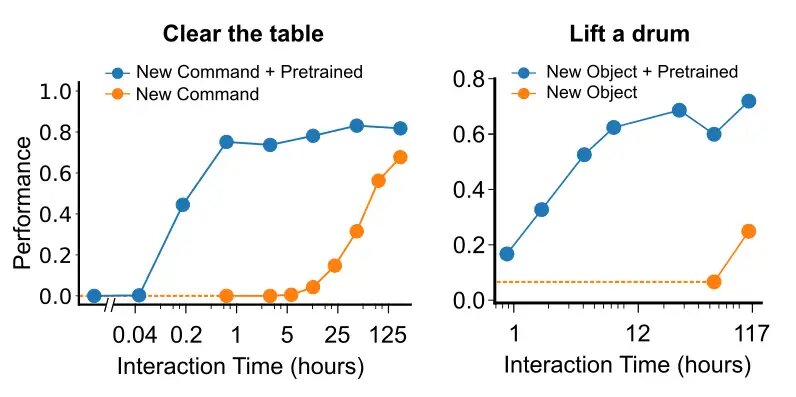
In un caso ideale, l’addestramento diventa più efficiente data un dataset ragionevolmente grande, poiché la conoscenza viene trasferita tra le esperienze. Per indagare quanto siano ideali le nostre circostanze, abbiamo esaminato quanti dati sono necessari per imparare a interagire con un nuovo oggetto, precedentemente mai visto, e per imparare come seguire un nuovo comando / verbo precedentemente mai sentito. Abbiamo suddiviso i nostri dati in dati di background e dati che coinvolgono un’istruzione linguistica relativa all’oggetto o al verbo. Quando abbiamo reintrodotto i dati relativi al nuovo oggetto, abbiamo scoperto che meno di 12 ore di interazione umana erano sufficienti per acquisire le prestazioni massime. Analogamente, quando abbiamo introdotto il nuovo comando o verbo “to clear” (ovvero rimuovere tutti gli oggetti da una superficie), abbiamo scoperto che solo 1 ora di dimostrazioni umane era sufficiente per raggiungere le prestazioni massime nelle attività che coinvolgono questa parola.
MIA mostra un comportamento sorprendentemente ricco, comprese una varietà di comportamenti che non erano stati preconcepiti dai ricercatori, come mettere in ordine una stanza, trovare più oggetti specificati e fare domande di chiarimento quando un’istruzione è ambigua. Queste interazioni ci ispirano continuamente. Tuttavia, l’apertura del comportamento di MIA presenta immense sfide per la valutazione quantitativa. Lo sviluppo di metodologie complete per catturare e analizzare il comportamento aperto nelle interazioni tra umani e agenti sarà un importante focus dei nostri futuri lavori.
Per una descrizione più dettagliata del nostro lavoro, consultare il nostro articolo .






