Diverse modi di addestrare LLMs
Modi addestramento LLMs
E perché la richiesta non è nessuna di queste
Nel campo dei grandi modelli di linguaggio (LLM), esistono vari meccanismi di addestramento con diversi scopi, requisiti e obiettivi. Poiché servono a scopi diversi, è importante non confonderli tra loro e essere consapevoli dei diversi scenari a cui si applicano.
In questo articolo, voglio fornire una panoramica di alcuni dei meccanismi di addestramento più importanti, tra cui il pre-addestramento, il fine-tuning, il reinforcement learning a partire dai feedback umani (RLHF) e gli adapter. Inoltre, discuterò il ruolo delle richieste, che non è considerato un vero e proprio meccanismo di apprendimento, e farò luce sul concetto di sintonizzazione delle richieste, che crea un collegamento tra le richieste stesse e l’addestramento effettivo.
Pre-addestramento
Il pre-addestramento è il modo più fondamentale di addestramento ed è equivalente a ciò che potresti conoscere come addestramento in altri domini di apprendimento automatico. Qui si parte da un modello non addestrato (cioè con pesi inizializzati casualmente) e lo si addestra a predire il token successivo dato una sequenza di token precedenti. A tal fine, viene raccolto un ampio corpus di frasi da varie fonti e viene fornito al modello in piccoli frammenti.
La modalità di addestramento utilizzata qui è chiamata auto-supervisione. Dal punto di vista del modello in fase di addestramento, si può parlare di un approccio di apprendimento supervisionato, perché il modello ottiene sempre la risposta corretta dopo aver fatto una previsione. Ad esempio, dato la sequenza “Mi piace il gelato …”, il modello potrebbe prevedere “cono” come parola successiva e potrebbe quindi venire informato che la risposta è sbagliata perché la parola successiva effettiva era “panna”. Alla fine, è possibile calcolare la perdita e adattare i pesi del modello per migliorare le previsioni in futuro. Il motivo per cui viene chiamato auto-supervisione (anziché semplicemente supervisione) è che non è necessario raccogliere preventivamente le etichette in una procedura costosa, ma sono già incluse nei dati. Dato la frase “Mi piace il gelato”, possiamo suddividerla automaticamente in “Mi piace il gelato” come input e “panna” come etichetta, senza richiedere alcuno sforzo umano. Anche se non è il modello stesso a farlo, viene comunque eseguito automaticamente dalla macchina, da qui l’idea di un’intelligenza artificiale che supervisiona se stessa nel processo di apprendimento.
- Come migliorare il codice generato da ChatGPT con l’ingegneria delle prompt
- Incontra StyleAvatar3D un nuovo metodo di intelligenza artificiale per generare avatar 3D stilizzati utilizzando modelli di diffusione immagine-testo e una rete di generazione 3D basata su GAN.
- Risultati della Open Source AI Game Jam
Con il tempo, addestrandosi su grandi quantità di testo, il modello impara a codificare la struttura del linguaggio in generale (ad esempio, impara che “Mi piace” potrebbe essere seguito da un sostantivo o un participio) così come le conoscenze incluse nei testi che ha visto. Ad esempio, ha imparato che la frase “Joe Biden è …” è spesso seguita dal “presidente degli Stati Uniti” e quindi ha una rappresentazione di quella conoscenza.
Questo pre-addestramento è già stato fatto da altri e puoi utilizzare modelli come GPT direttamente. Ma perché dovresti mai addestrare un modello simile? Addestrare un modello da zero può diventare necessario se lavori con dati che hanno proprietà simili al linguaggio, ma che non sono il linguaggio comune stesso. La notazione musicale potrebbe essere un esempio, che è in qualche modo strutturata come un linguaggio. Ci sono regole e schemi specifici su quali pezzi possono seguire l’altro, ma un LLM addestrato sul linguaggio naturale non può gestire quel tipo di dati, quindi dovresti addestrare un nuovo modello. Tuttavia, l’architettura dei LLM potrebbe essere adatta, grazie alle numerose somiglianze tra le notazioni musicali e il linguaggio naturale.
Fine-tuning
Anche se un LLM pre-addestrato, grazie alle conoscenze che codifica, è in grado di svolgere un numero variabile di compiti, presenta due principali limitazioni, ovvero la struttura del suo output e l’assenza di conoscenze non codificate nei dati iniziali.
Come sai, un LLM prevede sempre i token successivi dati una sequenza di token precedenti. Per continuare una storia data, potrebbe essere sufficiente, ma ci sono altri scenari in cui questo non è ciò che si desidera. Se hai bisogno di una struttura di output diversa, ci sono due modi principali per renderlo possibile. Puoi scrivere le tue richieste in modo tale che la capacità intrinseca del modello di prevedere i token successivi risolva il tuo compito (che viene chiamato ingegneria delle richieste), oppure puoi modificare l’output dell’ultimo strato in modo che rifletta il tuo compito come faresti con qualsiasi altro modello di apprendimento automatico. Pensiamo a un compito di classificazione, in cui hai N classi. Con l’ingegneria delle richieste, potresti istruire il modello a produrre sempre l’etichetta di classificazione dopo un determinato input. Con il fine-tuning, potresti modificare gli ultimi strati in modo che abbiano N neuroni di output e derivare la classe prevista dal neurone con l’attivazione più alta.
L’altro limite del LLM risiede nei dati con cui è stato addestrato. Poiché le fonti di dati sono piuttosto ricche, i LLM più conosciuti codificano una vasta varietà di conoscenze comuni. Pertanto, possono dirti, tra le altre cose, chi è il presidente degli Stati Uniti, le principali opere di Beethoven, i fondamenti della fisica quantistica e le principali teorie di Sigmund Freud. Tuttavia, ci sono domini di cui i modelli non sono a conoscenza e se hai bisogno di lavorare con tali domini, il fine-tuning potrebbe essere rilevante per te.
L’idea del fine-tuning consiste nel prendere un modello già preaddestrato e continuare il suo addestramento con dati diversi, modificando solo i pesi negli ultimi strati durante l’addestramento. Ciò richiede solo una frazione delle risorse necessarie nell’addestramento iniziale e quindi può essere eseguito molto più velocemente. D’altra parte, le strutture apprese dal modello durante il preaddestramento sono ancora codificate nei primi strati e possono essere utilizzate. Supponiamo che tu voglia insegnare al tuo modello dei romanzi fantasy meno conosciuti ma preferiti, che non fanno parte dei dati di addestramento. Con il fine-tuning, sfrutti la conoscenza del modello sul linguaggio naturale in generale per farlo comprendere il nuovo dominio dei romanzi fantasy.
Fine-tuning RLHF
Un caso particolare di fine-tuning del modello è il reinforcement learning from human feedback (RLHF), che rappresenta una delle principali differenze tra un modello GPT e un chatbot come Chat-GPT. Con questo tipo di fine-tuning, il modello viene addestrato a produrre output che un umano trova più utili durante la conversazione con il modello.
L’idea principale è la seguente: dato un prompt arbitrario, vengono generati più output dal modello per quel prompt. Un umano classifica tali output in base a quanto li trova utili o appropriati. Dati quattro campioni A, B, C e D, l’umano potrebbe decidere che C è il miglior output, B è un po’ peggiore ma uguale a D, e A è il peggiore per quel prompt. Ciò comporterebbe un ordine C > B = D > A. Successivamente, questi dati vengono utilizzati per addestrare un modello di ricompensa. Si tratta di un modello completamente nuovo che impara a valutare gli output di un LLM attribuendo una ricompensa che riflette le preferenze dell’umano. Una volta addestrato il modello di ricompensa, può sostituire l’umano in quella produzione. Ora gli output del modello vengono valutati dal modello di ricompensa e quella ricompensa viene data come feedback al LLM che viene quindi adattato per massimizzare la ricompensa; un’idea molto simile a quella dei GAN.
Come puoi vedere, per questo tipo di addestramento sono necessari dati etichettati dagli umani, il che richiede un certo sforzo. Tuttavia, la quantità di dati necessaria è finita, poiché l’idea del modello di ricompensa è quella di generalizzare a partire da quei dati in modo che possa valutare il LLM autonomamente, una volta che ne ha appreso la sua parte. RLHF viene spesso utilizzato per rendere gli output del LLM più simili a una conversazione o per evitare comportamenti indesiderati come un modello che sia cattivo, invadente o insultante.
Adattatori
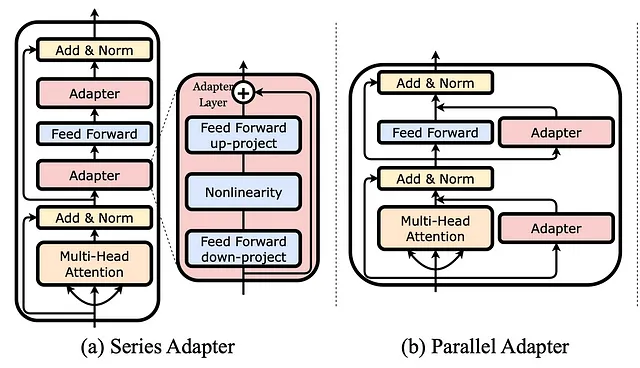
Nel già citato fine-tuning, si adattano alcuni dei parametri del modello negli ultimi strati, mentre gli altri parametri dei livelli precedenti rimangono come sono. Esiste però un’alternativa a ciò, che promette maggiore efficienza con un minor numero di parametri richiesti per l’addestramento, chiamata adattatori.
Utilizzare gli adattatori significa aggiungere strati aggiuntivi a un modello già addestrato. Durante il fine-tuning, vengono addestrati solo questi adattatori, mentre il resto dei parametri del modello non viene modificato affatto. Tuttavia, questi strati sono molto più piccoli rispetto agli strati forniti dal modello, il che rende più facile regolarli. Inoltre, possono essere inseriti in diverse posizioni nel modello, non solo alla fine. Nell’immagine sopra vengono mostrati due esempi: uno in cui un adattatore viene aggiunto come strato in modo seriale e uno in cui viene aggiunto in parallelo a uno strato già esistente.
Prompting
Potresti chiederti se il prompting conti come un altro modo per addestrare un modello. Il prompting significa costruire le istruzioni che precedono l’input effettivo del modello e, specialmente se si utilizza il few-shot-prompting, si forniscono esempi al LLM all’interno del prompt, molto simile all’addestramento, che consiste anche di esempi presentati al modello. Tuttavia, ci sono ragioni per cui il prompting è qualcosa di diverso dall’addestramento di un modello. Prima di tutto, dalla semplice definizione, parliamo solo di addestramento se i pesi vengono aggiornati, e ciò non avviene durante il prompting. Quando si crea un prompt, non si modifica alcun modello, non si cambiano i pesi, non si produce un nuovo modello e non si modifica neanche la conoscenza o la rappresentazione codificata nel modello. Il prompting dovrebbe piuttosto essere visto come un modo per istruire un LLM e dirgli cosa si vuole da lui. Considera il seguente prompt come esempio:
"""Classifica un testo dato in base al suo sentiment.Testo: Mi piace il gelato.Sentiment: negativoTesto: Odio davvero i nuovi AirPods.Sentiment: positivoTesto: Donald è la persona più odiosa sulla terra. Lo odio così tanto!Sentiment: neutraleTesto: {user_input}Sentiment:"""Ho istruito il modello a fare una classificazione del sentiment e, come avrai notato, gli esempi che ho dato al modello sono tutti errati! Se un modello fosse stato addestrato con tali dati, mescolerebbe le etichette positive, negative e neutrali. Cosa succede ora, se chiedo al modello di classificare la frase Mi piace il gelato, che faceva parte dei miei esempi? Curiosamente, lo classifica come positivo, il che è contrario al prompt, ma corretto a livello semantico. Questo perché il prompt non ha addestrato il modello e non ha cambiato la rappresentazione di ciò che ha imparato. Il prompt semplicemente informa il modello sulla struttura che mi aspetto, ovvero che mi aspetto l’etichetta di sentiment (che può essere positiva, negativa o neutra) a seguire i due punti.
Prompt tuning
Anche se un prompt di per sé non addestra l’LLM, esiste un meccanismo chiamato prompt tuning (anche chiamato soft prompting), che è correlato al prompting e può essere visto come una sorta di addestramento.
Nell’esempio precedente, abbiamo considerato il prompt come un testo in linguaggio naturale che viene fornito al modello per dirgli cosa fare e che precede l’input effettivo. Quindi, l’input del modello diventa <prompt><istanza>, ad esempio, <etichetta il seguente come positivo, negativo o neutrale:> <Mi piace il gelato>. Quando creiamo il prompt noi stessi, parliamo di hard prompting. Nel soft prompting, il formato <prompt><istanza> viene mantenuto, ma il prompt stesso non è progettato da noi ma viene appreso con i dati. In dettaglio, il prompt è costituito da parametri in uno spazio vettoriale, e quei parametri possono essere regolati durante l’addestramento per ottenere una perdita minore e quindi risposte migliori. Cioè, dopo l’addestramento, il prompt sarà quella sequenza di caratteri che porta alle migliori risposte per i nostri dati. I parametri del modello, tuttavia, non vengono affatto addestrati.
Un grande vantaggio del prompt tuning è che puoi addestrare più prompt per diverse attività ma comunque usarli con lo stesso modello. Proprio come nell’hard prompting, dove potresti costruire un prompt per la sintesi del testo, uno per l’analisi del sentiment e uno per la classificazione del testo, ma usarli tutti con lo stesso modello, puoi regolare tre prompt per questi scopi e comunque utilizzare lo stesso modello. Se avessi utilizzato il fine-tuning, al contrario, avresti ottenuto tre modelli che servono solo per il loro compito specifico ognuno.
Sommario
Avevamo appena visto una varietà di meccanismi di addestramento diversi, quindi facciamo un breve riassunto alla fine.
- Preallenare un LLM significa insegnargli a prevedere il token successivo in modo auto-supervisionato.
- Il fine-tuning consiste nell’adattare i pesi di un LLM preaddestrato negli ultimi strati e può essere utilizzato per adattare il modello a un contesto specifico.
- RLHF mira ad adattare il comportamento di un modello per soddisfare le aspettative umane e richiede uno sforzo di etichettatura aggiuntivo.
- Gli adattatori consentono un modo più efficiente di fine-tuning grazie a piccoli strati che vengono aggiunti al LLM preaddestrato.
- Il prompting non viene considerato un addestramento vero e proprio, perché non modifica la rappresentazione interna del modello.
- Il prompt tuning è una tecnica per regolare i pesi che producono un prompt ma non influisce sui pesi del modello stesso.
Certo, ci sono molti altri meccanismi di addestramento disponibili, con nuovi che vengono inventati ogni giorno. I LLM possono fare molto di più che prevedere il testo e insegnar loro a farlo richiede una varietà di competenze e tecniche, alcune delle quali ho appena presentato a voi.
Approfondimenti
Instruct-GPT è uno dei più famosi esempi di RLHF:
- https://openai.com/research/instruction-following
- Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., … & Lowe, R. (2022). Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35, 27730–27744.
Un’overview delle forme comuni di adattatori può essere trovata nel progetto LLM-Adapters:
- https://github.com/AGI-Edgerunners/LLM-Adapters
- Hu, Z., Lan, Y., Wang, L., Xu, W., Lim, E. P., Lee, R. K. W., … & Poria, S. (2023). LLM-Adapters: An Adapter Family for Parameter-Efficient Fine-Tuning of Large Language Models. arXiv preprint arXiv:2304.01933.
Il prompt tuning è stato esplorato qui:
- Lester, B., Al-Rfou, R., & Constant, N. (2021). The power of scale for parameter-efficient prompt tuning. arXiv preprint arXiv:2104.08691.
Alcune belle spiegazioni del prompt tuning possono essere trovate qui:
- https://huggingface.co/docs/peft/conceptual_guides/prompting
- https://ai.googleblog.com/2022/02/guiding-frozen-language-models-with.html
Ti è piaciuto questo articolo? Seguimi per essere notificato dei miei futuri post.





