Dai dati ai dollari utilizzo della regressione lineare
Linear regression from data to dollars
Svelando la magia dietro l’analisi predittiva
La presa di decisioni basata sui dati è diventata un elemento fondamentale per le imprese di ogni settore. Dall’ottimizzazione delle strategie di marketing alla previsione del comportamento dei clienti, i dati sono la chiave per sbloccare opportunità inespresse. In questo articolo, esploreremo l’incredibile potenziale dell’utilizzo della regressione lineare come potente strumento per convertire le intuizioni dei dati in guadagni finanziari tangibili e la matematica che vi sta dietro.
La regressione lineare è un metodo di apprendimento automatico supervisionato per prevedere la relazione tra variabili dipendenti (Y) e variabili indipendenti (X). Ad esempio, la previsione del prezzo delle azioni
Tipi di regressione lineare
- Regressione lineare semplice: qui si ha una colonna di input e una colonna di output.
- Regressione lineare multipla: qui si hanno più colonne di input e una colonna di output.
- Regressione lineare polinomiale: se i dati non sono lineari, la si utilizza.
Assunzioni nella regressione lineare
- La relazione tra la variabile dipendente e la variabile indipendente è lineare
- Non c’è o c’è poca multicollinearità tra le variabili
- Si presume che sia nella forma di una distribuzione normale.
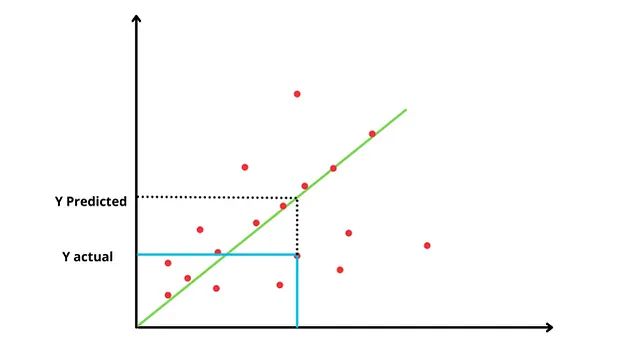
Lo scopo principale è trovare la linea migliore che descriverà la relazione tra la variabile indipendente e la variabile dipendente, ottenendo la linea con l’errore minimo.
Linea migliore: È la linea che attraversa il maggior numero di punti e la distanza tra i punti reali e la linea è minima.
- Perché la Silicon Valley è il luogo di riferimento per l’Intelligenza Artificiale
- Creare e addestrare modelli di visione artificiale per rilevare la posizione delle auto nelle immagini utilizzando Amazon SageMaker e Amazon Rekognition
- Accelerare i risultati aziendali con miglioramenti del 70% delle prestazioni nel processo dei dati, nell’addestramento e nell’inferenza con Amazon SageMaker Canvas
Ma come troveremo quale è la linea migliore da utilizzare?
Iniziamo con una linea orizzontale che attraversa la media del valore dei dati, probabilmente la peggiore adattabilità di tutte, ma ci fornisce un punto di partenza per parlare di come trovare una linea ottimale per i dati. Per questa linea orizzontale, x = 0Poiché y = mx + c e x = 0. Quindi y = c (caso peggiore perché qui y non dipende dalla nostra variabile dipendente)Nel passo successivo, troveremo la somma dei residui quadrati (SSR) per questa linea.
Somma dei residui quadrati (SSR) = È la distanza tra la linea e i dati, che viene elevata al quadrato e poi sommata per trovare il valore SSR. Residuo è un altro termine per “errore”.

Aimiamo a trovare il SSR minimo. Quindi ruoteremo la nostra linea orizzontale e, in relazione alla nuova linea, troveremo il SSR. E continueremo a farlo per diverse rotazioni.
Tra tutti questi SSR che abbiamo ottenuto, considereremo il minimo e useremo quella linea per adattare i nostri dati. Quindi la linea con il minimo quadrato è impostata sui dati, per questo il metodo è noto come minimi quadrati.
Algoritmi differenti di regressione lineare
- Minimi quadrati ordinari (OLS)
- Discesa del gradiente: questa è una tecnica di ottimizzazione
Metriche di valutazione per la regressione lineare
- Errore medio assoluto (MAE): Non è differenziabile. Mantiene l’unità invariata quando si cerca di trovare l’errore medio assoluto, il che facilita l’interpretazione dei dati ed è robusto agli outlier.
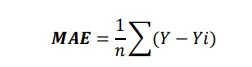
- Errore quadratico medio (MSE): È differenziabile ma l’interpretazione viene influenzata dal cambio di unità poiché qui stiamo elevando al quadrato l’unità.

- Errore quadratico medio radice (RMSE):

Interpretabilità : MAE>RMSE>MSESensibile agli Outlier: MSE>RMSE>MAE
- R-quadrato (R2): È il coefficiente di determinazione o bontà di adattamento. Verifica quanto è buona la nostra linea di regressione rispetto alla linea peggiore. Il valore di R2 varia da 0 a 1. Più il tuo modello si avvicina alla perfezione, più il valore di R2 si avvicinerà a 1 e più si avvicinerà al peggiore, il valore di R2 si avvicinerà a 0. Ci dice quanto della variazione della variabile y può essere spiegata dalla variabile x.
R2 = Variazione Spiegata/Variazione TotaleR2 = (Variazione Totale — Variazione Non Spiegata)/ Variazione Totale R2 = 1- (variazione non spiegata/variazione totale)Qui, Variazione Totale = Variazione(media) : (dati-media)²/nVariazione non spiegata = Variazione(adattata) : (dati-linea)²/n
Ad esempio, vuoi prevedere la perdita di peso e hai la variabile di assunzione di calorie. Se ottieni R2 come 70%, significa che il 70% della variazione della variabile dei voti può essere spiegata con l’aiuto della variabile delle ore di studio. Ha un’accuratezza del 70%, che è una bontà di adattamento.Ora, se aggiungiamo una nuova caratteristica, come le ore di sonno, e questa non ha molto impatto sulla variabile target, cioè non è correlata alla perdita di peso. Ma se calcoliamo nuovamente R2, aumenterà anche se la nuova caratteristica che abbiamo aggiunto non è correlata. Ma questo non è corretto perché sta aumentando l’accuratezza del modello quando in realtà non lo fa e stiamo anche aumentando la potenza di calcolo poiché dobbiamo allenare una colonna in più che non è nemmeno necessaria.
Problema con R2: Anche se le caratteristiche coinvolte nel modello non saranno così importanti, il valore di R2 aumenterà anche se aumenta di poco, non diminuirà mai. Quindi, anche se R2 non dovrebbe essere aumentato perché la caratteristica aggiunta non è importante, dobbiamo addestrare il modello inutilmente. Quindi dobbiamo penalizzare questo e quindi abbiamo ‘R2 corretto’
- R2 corretto: Immagina ora di aggiungere più caratteristiche al tuo modello, quindi il valore di R2 aumenterà perché il valore di SS(res) sarà sempre in diminuzione. Quindi, il R2 corretto entra in gioco e penalizza fondamentalmente gli attributi non correlati. Quindi, se le mie caratteristiche non sono correlate, solo in quel caso il valore del mio R2 diminuirà altrimenti aumenterà.
R2 corretto = 1- ((1-R2)(N-1)/N-P-1)N = numero di punti dati P = numero di caratteristiche indipendenti
Pertanto, il R2 corretto aumenta solo quando la variabile indipendente è significativa e influenza la variabile dipendente. Inoltre, non si verificherà l’overfitting perché stiamo penalizzando il valore qui.
Grazie per aver letto! Se hai apprezzato questo articolo e desideri leggere altro del mio lavoro, considera di seguirmi su VoAGI. Non vedo l’ora di condividere di più con te in futuro.






