Questa ricerca sull’IA presenta l’integrazione di Lucene per una potente ricerca vettoriale con gli embeddings di OpenAI
La ricerca sull'IA integra Lucene per una potente ricerca vettoriale con gli embeddings di OpenAI


Ultimamente ci sono stati passi significativi nell’applicazione delle reti neurali profonde nel campo della ricerca nell’apprendimento automatico, con un’enfasi specifica sull’apprendimento della rappresentazione all’interno dell’architettura del bi-encoder. In questo framework, vari tipi di contenuti, inclusi le query, i passaggi e persino i media, come le immagini, vengono trasformati in “embeddings” compatti e significativi rappresentati come vettori densi. Questi modelli di recupero densi, costruiti su questa architettura, fungono da base per migliorare i processi di recupero all’interno dei grandi modelli di linguaggio (LLM). Questo approccio ha guadagnato popolarità e si è rivelato estremamente efficace nel potenziare le capacità complessive dei LLM nel campo più ampio dell’IA generativa oggi.
Il racconto suggerisce che a causa della necessità di gestire numerosi vettori densi, le aziende dovrebbero incorporare un “archivio di vettori” o un “database di vettori” dedicato nel loro “stack di IA”. Un mercato di nicchia di startup sta promuovendo attivamente questi archivi di vettori come componenti innovativi ed essenziali dell’architettura aziendale contemporanea. Esempi notevoli includono Pinecone, Weaviate, Chroma, Milvus e Qdrant, tra gli altri. Alcuni sostenitori sono persino arrivati a proporre che questi database di vettori potrebbero alla fine sostituire i tradizionali database relazionali.
Questo articolo presenta un punto di vista opposto a questo racconto. Gli argomenti ruotano attorno a un’analisi dei costi e dei benefici, considerando che la ricerca rappresenta un’applicazione esistente e consolidata in molte organizzazioni, che ha portato a investimenti significativi in queste capacità. L’infrastruttura di produzione è dominata dall’ampio ecosistema incentrato sulla libreria di ricerca open-source Lucene, guidato soprattutto da piattaforme come Elasticsearch, OpenSearch e Solr.
- Introduzione a Numpy e Pandas
- Incontra Modular Diffusion una libreria Python per la progettazione e l’addestramento di modelli di diffusione con PyTorch
- Migliora ChatGPT come sviluppatore software SoTaNa è un assistente AI open-source per lo sviluppo software
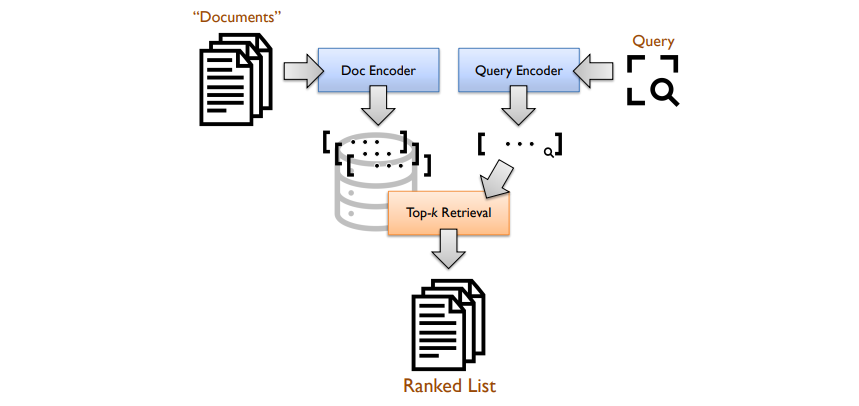
L’immagine sopra mostra un’architettura standard del bi-encoder, in cui gli encoder generano rappresentazioni vettoriali dense (embeddings) da query e documenti (passaggi). Il recupero viene impostato come una ricerca dei k-vicini più prossimi nello spazio vettoriale. Gli esperimenti si sono concentrati sulla raccolta di test di classificazione dei passaggi MS MARCO, costruita su un corpus di circa 8,8 milioni di passaggi estratti dal web. Per l’valutazione sono state utilizzate le query di sviluppo standard e le query dalle tracce di apprendimento profondo TREC 2019 e TREC 2020.
I risultati suggeriscono che oggi è possibile costruire un prototipo di ricerca vettoriale utilizzando direttamente gli embeddings di OpenAI con Lucene. La crescente popolarità delle API di embedding supporta le nostre argomentazioni. Queste API semplificano il complesso processo di generazione di vettori densi da contenuti, rendendolo più accessibile ai professionisti. Infatti, Lucene è tutto ciò di cui hai bisogno quando stai costruendo ecosistemi di ricerca oggi. Ma come sempre, solo il tempo dirà se hai ragione. Infine, questo ci ricorda che pesare i costi rispetto ai benefici rimarrà una mentalità primaria, anche nel mondo dell’IA in rapida evoluzione.