Incontra TR0N un metodo semplice ed efficiente per aggiungere qualsiasi tipo di condizionamento ai modelli generativi preaddestrati
Incontra TR0N, un metodo semplice ed efficiente per aggiungere condizionamento ai modelli generativi preaddestrati


Recentemente, modelli di apprendimento automatico di grandi dimensioni si sono distinti in una varietà di compiti. Tuttavia, addestrare tali modelli richiede molta potenza di calcolo. Pertanto, è fondamentale sfruttare correttamente ed efficacemente i modelli pre-addestrati attualmente disponibili. Tuttavia, la sfida di combinare in modo plug-and-play le capacità di vari modelli deve ancora essere risolta. I meccanismi per svolgere questo compito dovrebbero preferibilmente essere modulari e neutrali rispetto al modello, consentendo la semplice sostituzione dei componenti del modello (ad esempio, sostituendo CLIP con un nuovo modello di testo/immagine all’avanguardia con un VAE).
In questo lavoro, i ricercatori di Layer 6 AI, dell’Università di Toronto e del Vector Institute indagano sulla generazione condizionale mescolando modelli pre-addestrati precedentemente. Dato una variabile di condizionamento c, i modelli generativi condizionali cercano di apprendere una distribuzione di dati condizionale. Di solito vengono addestrati da zero su coppie di dati con c corrispondente, come immagini x con etichette di classe corrispondenti o prompt di testo forniti tramite un modello di linguaggio c. Vogliono trasformare qualsiasi modello generativo pushforward incondizionato pre-addestrato in un modello condizionale utilizzando un modello G che converte le variabili latenti z campionate da una distribuzione p(z) in campioni di dati x = G(z). Per fare ciò, forniscono TR0N, un ampio framework per addestrare modelli generativi incondizionati pre-addestrati condizionalmente.
TR0N presuppone l’accesso a un modello ausiliario addestrato f, un classificatore o un encoder CLIP per mappare ciascun punto dati x alla sua condizione associata c = f(x). TR0N si aspetta inoltre l’accesso a una funzione E(z, c) che assegna valori inferiori ai latenti z per i quali G(z) “soddisfa meglio” un criterio c. Utilizzando questa funzione, TR0N minimizza il gradiente di E(z, c) rispetto a z in T passi per un dato c per individuare i latenti che, quando applicati a G, fornirebbero i necessari campioni di dati condizionali. Tuttavia, dimostrano che ottimizzare inizialmente E in modo ingenuo potrebbe essere molto migliore. Alla luce di ciò, TR0N inizia studiando una rete che impiegano per ottimizzare in modo più efficace il processo di ottimizzazione.
- Un metodo più semplice per imparare a controllare un robot
- AWS conferma il suo impegno verso l’IA generativa responsabile
- Le didascalie sintetiche sono utili per l’addestramento multimodale? Questo articolo scientifico dimostra l’efficacia delle didascalie sintetiche nel migliorare la qualità delle didascalie per l’addestramento multimodale
Dal momento che “traduce” da una condizione c a un latente corrispondente z tale che E(z, c) sia minimo, questa rete è nota come rete traduttrice in quanto essenzialmente ammortizza il problema di ottimizzazione. La rete di traduzione viene addestrata senza modificare G o utilizzare un dataset predefinito, il che è importante. TR0N è un approccio zero-shot, con una rete di traduzione leggera come unica parte addestrabile. La capacità di TR0N di utilizzare qualsiasi G e qualsiasi f rende anche facile l’aggiornamento di una di queste componenti ogni volta che diventa disponibile una nuova versione all’avanguardia. Questo è importante perché evita l’addestramento estremamente costoso di un modello condizionale da zero.
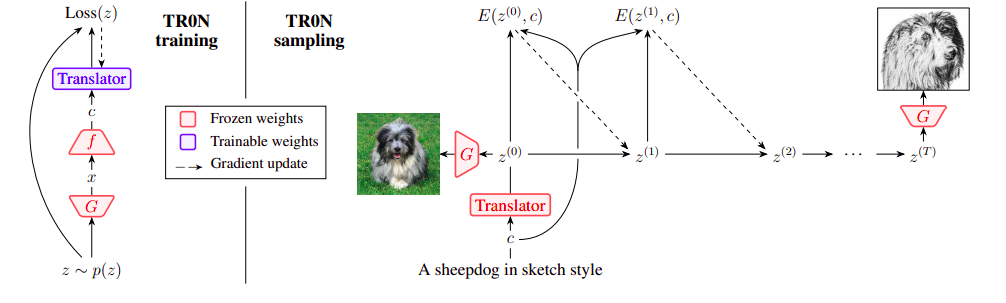
Nel pannello sinistro della Figura 1, descrivono come addestrare la rete traduttrice. Dopo aver addestrato la rete di traduzione, viene avviata l’ottimizzazione di E utilizzando il suo output. Rispetto all’inizializzazione ingenua, questo recupera qualsiasi prestazione persa a causa del divario di ammortizzazione, producendo migliori ottimi locali e convergenza più veloce. È possibile interpretare TR0N come un campionamento con dinamica di Langevin utilizzando una strategia di inizializzazione efficace perché TR0N è un metodo stocastico. La rete traduttrice è una distribuzione condizionale q(z|c) che assegna alta densità ai latenti z in modo che E(z, c) sia piccolo. Aggiungono anche rumore durante l’ottimizzazione del gradiente di E. Nel pannello destro della Figura 1, mostrano come campionare con TR0N.
Fanno tre contributi: (i) introducono reti traduttrici e una parametrizzazione particolarmente efficace di esse, consentendo diverse modalità di inizializzazione della dinamica di Langevin; (ii) presentano TR0N come un framework molto generale, mentre i lavori correlati precedenti si concentrano principalmente su un singolo compito con scelte specifiche di G e f; e (iii) dimostrano che TR0N supera empiricamente le alternative concorrenti in termini di qualità dell’immagine e praticità computazionale, producendo anche campioni diversi. Una demo è disponibile su HuggingFace.