Masterizzare le GPU Una guida per principianti ai DataFrame accelerati da GPU in Python
Masterizzare le GPU Guida ai DataFrame accelerati da GPU in Python
Articolo sulla partnership
Se stai lavorando in Python con grandi set di dati, forse di diverse gigabyte di dimensione, probabilmente puoi capire la frustrazione di dover aspettare ore affinché le tue query finiscano mentre il tuo DataFrame di pandas basato su CPU fatica a eseguire le operazioni. Questa situazione precisa è dove un utente di pandas dovrebbe considerare di sfruttare la potenza delle GPU per l’elaborazione dei dati con RAPIDS cuDF.
RAPIDS cuDF, con la sua API simile a pandas, consente ai data scientist e agli ingegneri di sfruttare rapidamente l’immensa potenzialità del calcolo parallelo su GPU, con solo poche modifiche alle linee di codice.
- Incontra LogAI una libreria open-source progettata per l’analisi e l’intelligenza dei log
- L’ESRB vuole iniziare a utilizzare la tecnologia di scansione facciale per verificare l’età delle persone
- Un certo pericolo si nasconde lì’ Come l’inventore del primo chatbot si è rivoltato contro l’IA
Se non sei familiare con l’accelerazione GPU, questo articolo è una facile introduzione all’ecosistema RAPIDS e mostra le funzionalità più comuni di cuDF, il controparte di pandas basato su GPU.
Vuoi un pratico riepilogo di questi consigli? Segui la scheda di riferimento scaricabile di cuDF.
Sfruttare le GPU con cuDF DataFrame
cuDF è un mattoncino per la scienza dei dati della suite di librerie RAPIDS accelerate da GPU. È un cavallo di battaglia per l’EDA che puoi usare per costruire pipeline di dati che elaborano i dati e generano nuove caratteristiche. Come componente fondamentale all’interno della suite RAPIDS, cuDF è alla base delle altre librerie, consolidando il suo ruolo come mattoncino comune. Come tutti i componenti della suite RAPIDS, cuDF utilizza il backend CUDA per alimentare i calcoli su GPU.
Tuttavia, con un’interfaccia Python semplice e familiare, gli utenti di cuDF non hanno bisogno di interagire direttamente con quel livello.
Come cuDF può rendere più veloce il tuo lavoro di scienza dei dati
Sei stanco di guardare l’orologio mentre il tuo script viene eseguito? Che tu stia gestendo dati di tipo stringa o lavorando con serie temporali, ci sono molti modi in cui puoi utilizzare cuDF per far progredire il tuo lavoro sui dati.
- Analisi delle serie temporali: Che tu stia campionando i dati, estrarre caratteristiche o effettuare calcoli complessi, cuDF offre un notevole aumento di velocità, potenzialmente fino a 880 volte più veloce di pandas per l’analisi delle serie temporali.
- Esplorazione dei dati in tempo reale (EDA): Sfogliare grandi set di dati può essere un compito noioso con gli strumenti tradizionali, ma la potenza di elaborazione GPU di cuDF rende possibile l’esplorazione in tempo reale anche dei più grandi set di dati.
- Preparazione dei dati per l’apprendimento automatico (ML): Accelerare le attività di trasformazione dei dati e preparare i dati per gli algoritmi di ML comunemente utilizzati, come regressione, classificazione e clustering, grazie alle capacità di accelerazione di cuDF. Un’elaborazione efficiente significa uno sviluppo più rapido del modello e ti permette di avvicinarti più velocemente alla distribuzione.
- Visualizzazione dei dati su larga scala: Che tu stia creando mappe termiche per dati geografici o visualizzando tendenze finanziarie complesse, i programmatori possono utilizzare librerie di visualizzazione dei dati ad alte prestazioni e alta frequenza di frame utilizzando cuDF e cuxfilter. Questa integrazione consente all’interattività in tempo reale di diventare un componente vitale del tuo ciclo di analisi.
- Filtraggio e trasformazione dei dati su larga scala: Per grandi set di dati di diverse gigabyte, puoi eseguire operazioni di filtraggio e trasformazione utilizzando cuDF in una frazione del tempo richiesto da pandas.
- Elaborazione di dati di tipo stringa: Tradizionalmente, l’elaborazione di dati di tipo stringa è stata un compito difficile e lento a causa della complessità dei dati testuali. Queste operazioni diventano semplici con l’accelerazione GPU.
- Operazioni GroupBy: Le operazioni GroupBy sono uno strumento fondamentale nell’analisi dei dati ma possono richiedere molte risorse. cuDF velocizza notevolmente queste operazioni, consentendoti di ottenere risultati più rapidamente durante la suddivisione e l’aggregazione dei dati.

Interfaccia familiare per l’elaborazione GPU
La premessa principale di RAPIDS è quella di fornire un’esperienza utente familiare per gli strumenti popolari di scienza dei dati in modo che la potenza delle GPU NVIDIA sia facilmente accessibile a tutti gli operatori. Se conosci pandas, NumPy, scikit-learn o NetworkX, ti sentirai a casa quando utilizzi RAPIDS.
Passare dalla stack di scienza dei dati CPU a quella GPU non è mai stato così facile: con una piccola modifica, importando cuDF invece di pandas, puoi sfruttare l’enorme potenza delle GPU NVIDIA, accelerando i carichi di lavoro da 10 a 100 volte (al minimo) e ottenendo una maggiore produttività, il tutto utilizzando i tuoi strumenti preferiti.
Controlla il codice di esempio di seguito che mostra quanto familiare sia l’API di cuDF per chiunque utilizzi pandas.
import pandas as pd
import cudf
df_cpu = pd.read_csv('/data/sample.csv')
df_gpu = cudf.read_csv('/data/sample.csv')
Caricamento dati dalle tue fonti di dati preferite
Le capacità di lettura e scrittura di cuDF sono cresciute notevolmente dalla prima versione di RAPIDS nel 2018. I dati possono essere locali su una macchina, archiviati in un cluster in loco o nel cloud. cuDF utilizza la libreria fsspec per astrarre la maggior parte delle operazioni legate al file system, in modo da poterti concentrare su ciò che conta di più: creare funzionalità e costruire il tuo modello.
Grazie a fsspec, la lettura dei dati da file system locali o cloud richiede solo di fornire le credenziali per quest’ultimo. L’esempio seguente legge lo stesso file da due posizioni diverse:
import cudf
df_locale = cudf.read_csv('/data/sample.csv')
df_remoto = cudf.read_csv(
's3://<bucket>/sample.csv'
, storage_options = {'anon': True})
cuDF supporta diversi formati di file: formati basati su testo come CSV/TSV o JSON, formati orientati alle colonne come Parquet o ORC, o formati orientati alle righe come Avro. Per quanto riguarda il supporto del file system, cuDF può leggere file da file system locali, provider cloud come AWS S3, Google GS o Azure Blob/Data Lake, file system Hadoop in loco o in remoto, e anche direttamente da server web HTTP o (S)FTP, Dropbox o Google Drive, o file system Jupyter.
Creazione e salvataggio di DataFrames con facilità
La lettura dei file non è l’unico modo per creare DataFrames cuDF. In realtà, ci sono almeno 4 modi per farlo:
Da una lista di valori puoi creare un DataFrame con una colonna:
cudf.DataFrame([1,2,3,4], columns=['foo'])
Passando un dizionario se vuoi creare un DataFrame con più colonne:
cudf.DataFrame({
'foo': [1,2,3,4]
, 'bar': ['a','b','c',None]
})
Creando un DataFrame vuoto e assegnando colonne ad esso:
df_esempio = cudf.DataFrame()
df_esempio['foo'] = [1,2,3,4]
df_esempio['bar'] = ['a','b','c',None]
Passando una lista di tuple:
cudf.DataFrame([
(1, 'a')
, (2, 'b')
, (3, 'c')
, (4, None)
], columns=['ints', 'strings'])
Puoi anche convertire da e verso altre rappresentazioni di memoria:
- Da una matrice GPU interna rappresentata come DeviceNDArray,
- Attraverso oggetti di memoria DLPack utilizzati per condividere tensori tra framework di deep learning e il formato Apache Arrow che facilita un modo molto più comodo per manipolare oggetti di memoria da vari linguaggi di programmazione,
- Per la conversione in e da DataFrame e Series di pandas.
Inoltre, cuDF supporta il salvataggio dei dati memorizzati in un DataFrame in diversi formati e file system. Infatti, cuDF può archiviare dati in tutti i formati che può leggere.
Tutte queste funzionalità consentono di iniziare e lavorare rapidamente, indipendentemente dal compito o dalla posizione dei dati.
Estrazione, trasformazione e sintesi dei dati
Il compito fondamentale della scienza dei dati, e quello di cui tutti i data scientist si lamentano, è la pulizia, la creazione delle caratteristiche e la familiarizzazione con il dataset. Spendiamo l’80% del nostro tempo a farlo. Perché richiede così tanto tempo?
Una delle ragioni è che le domande che facciamo al dataset richiedono troppo tempo per essere risposte. Chiunque abbia provato a leggere e processare un dataset di 2 GB su una CPU sa di cosa stiamo parlando.
Inoltre, dato che siamo umani e facciamo errori, rieseguire un’intera pipeline potrebbe rapidamente trasformarsi in un’intera giornata di lavoro. Ciò comporta una perdita di produttività e, molto probabilmente, una dipendenza dal caffè se guardiamo il grafico qui sotto.
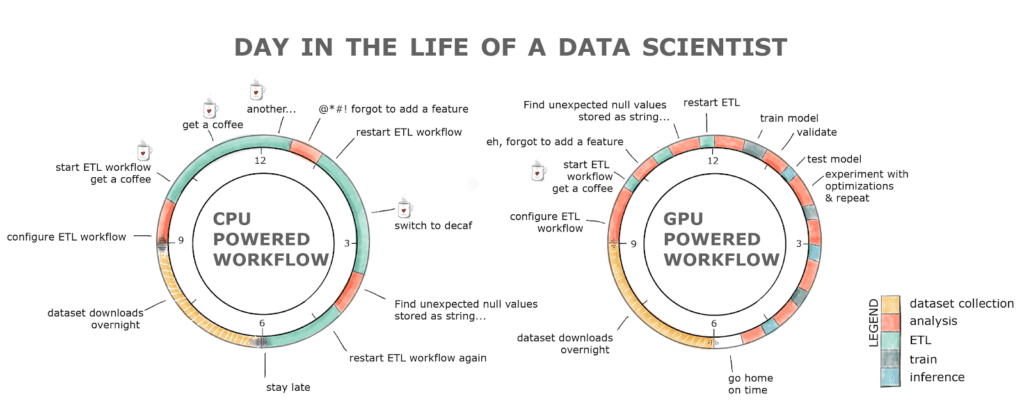
RAPIDS con il flusso di lavoro alimentato da GPU allevia tutti questi ostacoli. Lo stadio ETL è normalmente da 8 a 20 volte più veloce, quindi caricare quel dataset di 2 GB richiede secondi rispetto a minuti su una CPU, la pulizia e la trasformazione dei dati sono anche molto più veloci! Tutto questo con un’interfaccia familiare e poche modifiche al codice.
Lavorare con stringhe e date su GPU
Non più di 5 anni fa lavorare con stringhe e date su GPU era considerato quasi impossibile e al di là della portata dei linguaggi di programmazione di basso livello come CUDA. Dopotutto, le GPU sono state progettate per elaborare grafica, ossia manipolare grandi array e matrici di interi e float, non stringhe o date.
RAPIDS consente non solo di leggere le stringhe nella memoria GPU, ma anche di estrarre caratteristiche, elaborarle e manipolarle. Se conosci Regex, quindi estrarre informazioni utili da un documento su una GPU è ora un compito banale grazie a cuDF. Ad esempio, se vuoi trovare ed estrarre tutte le parole nel tuo documento che corrispondono al modello [a-z]*flow (come dataflow, workflow o flow) tutto quello che devi fare è,
df['string'].str.findall('([a-z]*flow)')
L’estrazione di funzionalità utili dalle date o la query dei dati per un periodo di tempo specifico è diventata più facile e veloce anche grazie a RAPIDS.
dt_to = dt.datetime.strptime("2020-10-03", "%Y-%m-%d")
df.query('dttm <= @dt_to')
Potenziare gli utenti di Pandas con l’accelerazione GPU
La transizione da uno stack di data science CPU a uno stack di data science GPU è semplice con RAPIDS. Importare cuDF invece di pandas è un piccolo cambiamento che può offrire immensi vantaggi. Che tu stia lavorando su una GPU locale o scalando fino a centri di dati completi, la potenza GPU accelerata di RAPIDS offre miglioramenti di velocità da 10 a 100 volte superiori (nella parte bassa). Ciò non solo porta a un aumento della produttività, ma consente anche un utilizzo efficiente dei tuoi strumenti preferiti, anche nei casi più impegnativi e su larga scala.
RAPIDS ha veramente rivoluzionato il panorama dell’elaborazione dei dati, consentendo ai data scientist di completare attività in minuti che un tempo richiedevano ore o addirittura giorni, portando a un aumento della produttività e a costi complessivi inferiori.
Per iniziare ad applicare queste tecniche al tuo dataset, leggi la serie di analisi dei dati accelerate su NVIDIA Technical Blog.
Nota dell’editore: Questo post è stato aggiornato con il permesso e originariamente adattato da NVIDIA Technical Blog.




