Sopravvivenza del più adatto i modelli AI generativi compatti sono il futuro per una AI a basso costo su larga scala
AI generative models compactness for low-cost, large-scale AI is the future of survival of the fittest

Il caso per modelli agili, mirati e basati sul recupero come la migliore soluzione per le applicazioni AI generative implementate su larga scala.
Dopo un decennio di rapida crescita nella complessità dei modelli di intelligenza artificiale (AI) e di calcolo, il 2023 segna uno spostamento dell’attenzione verso l’efficienza e l’applicazione diffusa dell’AI generativa (GenAI). Di conseguenza, una nuova generazione di modelli con meno di 15 miliardi di parametri, definiti AI agili, può avvicinarsi alle capacità dei modelli giganti di tipo ChatGPT che contengono più di 100 miliardi di parametri, soprattutto quando vengono mirati a specifici domini. Mentre la GenAI viene già implementata in diverse industrie per una vasta gamma di utilizzi commerciali, l’uso di modelli compatti ma altamente intelligenti sta aumentando. In futuro, mi aspetto che ci saranno un piccolo numero di modelli giganti e un numero enorme di modelli AI agili incorporati in innumerevoli applicazioni.
Nonostante ci sia stato un grande progresso con modelli più grandi, il concetto che “più è meglio” non si applica certamente in termini di costi di formazione e ambientali. TrendForce stima che solo la formazione del ChatGPT-4 costi più di 100 milioni di dollari, mentre i costi di preformazione dei modelli agili sono di diverse ordini di grandezza inferiori (ad esempio, si stimano circa 200.000 dollari per l’MPT-7B di MosaicML). La maggior parte dei costi di calcolo si verifica durante l’esecuzione continua delle inferenze, ma questo rappresenta una sfida simile per i modelli più grandi, che richiedono un calcolo costoso. Inoltre, i modelli giganti ospitati su ambienti di terze parti sollevano problemi di sicurezza e privacy. I modelli agili sono notevolmente più economici da eseguire e offrono numerosi vantaggi aggiuntivi come adattabilità, flessibilità hardware, integrazione all’interno di applicazioni più grandi, sicurezza e privacy, spiegabilità e altro ancora (vedi Figura 1). La percezione che i modelli più piccoli non siano altrettanto performanti dei modelli più grandi sta cambiando. I modelli più piccoli e mirati non sono meno intelligenti: possono offrire prestazioni equivalenti o superiori per i domini aziendali, dei consumatori e scientifici, aumentando il loro valore e riducendo tempo e costi di investimento.
Un numero crescente di questi modelli agili corrisponde approssimativamente alle prestazioni dei modelli giganti di livello ChatGPT-3.5 e continua a migliorare rapidamente in termini di prestazioni e portata. E quando i modelli agili sono dotati di recupero in tempo reale di dati privati specifici del dominio e di recupero mirato di contenuti web basati su una query, diventano più accurati e più economici dei modelli giganti che memorizzano un ampio set di dati.

Mentre i modelli GenAI agili open source avanzano per guidare la rapida progressione del campo, questo “momento iPhone”, in cui una tecnologia rivoluzionaria diventa mainstream, viene sfidato da una “rivoluzione Android” in cui una forte comunità di ricercatori e sviluppatori si basa sugli sforzi open source reciproci per creare modelli agili sempre più capaci.
- Perfeziona il tuo modello Llama 2 personalizzato in un notebook di Colab
- Top Computer Vision Papers durante la settimana dal 17/7 al 23/7
- Trasformazione non convenzionale delle date resa facile utilizzando la libreria Pandas di Python
Pensare, Fare, Conoscere: I modelli agili con domini mirati possono avere prestazioni simili ai modelli giganti
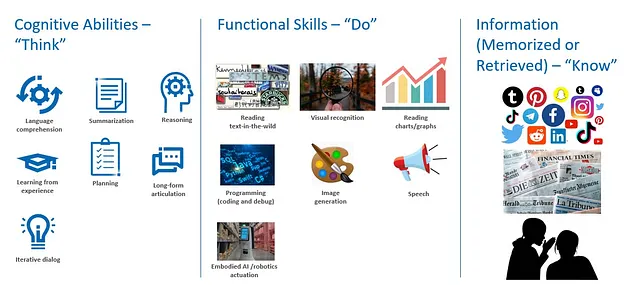
Per capire meglio quando e come un modello più piccolo può fornire risultati altamente competitivi per l’IA generativa, è importante osservare che sia i modelli GenAI agili che quelli giganti necessitano di tre classi di competenze per funzionare:
- Abilità cognitive per pensare: comprensione del linguaggio, sintesi, ragionamento, pianificazione, apprendimento dall’esperienza, articolazione di lunga durata e dialogo interattivo.
- Competenze funzionali per fare: ad esempio – leggere testo in condizioni reali, leggere grafici/tabelle, riconoscimento visivo, programmazione (codifica e debug), generazione di immagini e sintesi vocale.
- Informazioni (memorizzate o recuperate) da conoscere: contenuti web, compresi social media, notizie, ricerca e altri contenuti generali, e/o contenuti specifici del dominio selezionato come dati medici, finanziari e aziendali.
Abilità cognitive di pensare. Sulla base delle sue capacità cognitive, il modello può “pensare” e comprendere, riassumere, sintetizzare, ragionare e comporre il linguaggio e altre rappresentazioni simboliche. Sia i modelli agili che quelli giganti possono svolgere bene queste attività cognitive e non è chiaro se queste capacità principali richiedano dimensioni di modello massicce. Ad esempio, modelli agili come Orca di Microsoft Research stanno dimostrando capacità di comprensione, logica e ragionamento che già corrispondono o superano quelle di ChatGPT su diversi benchmark. Inoltre, Orca dimostra anche che le capacità di ragionamento possono essere distillate da modelli più grandi utilizzati come insegnanti. Tuttavia, i benchmark attuali utilizzati per valutare le capacità cognitive dei modelli sono ancora rudimentali. Sono necessarie ulteriori ricerche e valutazioni per validare che i modelli agili possano essere preaddestrati o adattati per corrispondere pienamente alla “forza di pensiero” dei modelli giganti.
Abilità funzionali per fare. È probabile che i modelli più grandi abbiano più abilità funzionali e informazioni date il loro focus generale come modelli completi. Tuttavia, per la maggior parte degli utilizzi aziendali, c’è una particolare gamma di abilità funzionali necessarie per qualsiasi applicazione in uso. Un modello utilizzato in un’applicazione aziendale dovrebbe avere flessibilità e spazio per la crescita e la variazione dell’uso, ma raramente ha bisogno di un insieme illimitato di abilità funzionali. GPT-4 può generare testo, codice e immagini in molte lingue, ma parlare centinaia di lingue non significa necessariamente che quei modelli giganti abbiano competenze cognitive sottostanti intrinsecamente più ampie: offre principalmente al modello abilità funzionali aggiuntive per “fare” di più. Inoltre, motori funzionalmente specializzati saranno collegati ai modelli GenAI e utilizzati quando è necessaria quella funzionalità, ad esempio l’aggiunta di “superpoteri Wolfram” matematici a ChatGPT in modo modulare potrebbe fornire funzionalità di prim’ordine senza appesantire il modello con una scala inutile. Ad esempio, GPT-4 sta distribuendo plugin che utilizzano essenzialmente modelli più piccoli per funzioni aggiuntive. Si vocifera anche che il modello GPT-4 stesso sia una collezione di più modelli giganti (meno di 100 miliardi di parametri) “mixture of experts” addestrati su dati e distribuzioni di compiti diversi anziché un unico modello denso monolitico come GPT-3.5. Per ottenere la migliore combinazione di capacità ed efficienze di modello, è probabile che i futuri modelli multifunzionali possano utilizzare modelli “mixture of experts” più piccoli e più focalizzati, ognuno dei quali con meno di 15 miliardi di parametri.
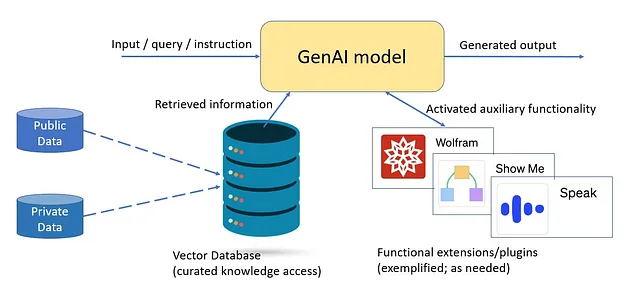
Informazioni (memorizzate o recuperate) da conoscere. I modelli giganti “conoscono” di più memorizzando vaste quantità di dati nella memoria parametrica, ma ciò non li rende necessariamente più intelligenti. Sono semplicemente più generalmente informati rispetto ai modelli più piccoli. I modelli giganti hanno un alto valore in ambienti di utilizzo zero-shot per nuovi casi d’uso, offrendo una base di consumatori generale quando non c’è bisogno di mirare e agendo come modello insegnante quando si distillano e si adattano modelli agili come Orca. Tuttavia, i modelli agili mirati possono essere addestrati e/o adattati per determinati domini, fornendo abilità più precise per le capacità necessarie.
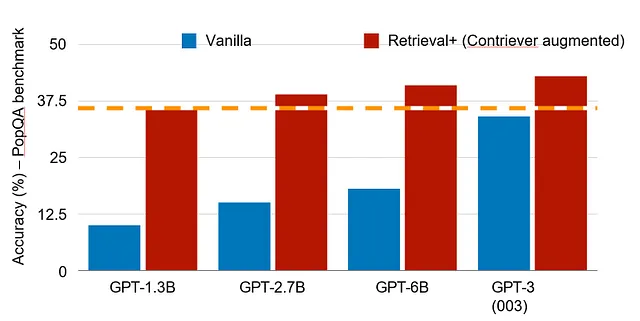
Ad esempio, un modello mirato alla programmazione può concentrarsi su un diverso insieme di capacità rispetto a un sistema di intelligenza artificiale nel settore sanitario. Inoltre, utilizzando il recupero su un insieme curato di dati interni ed esterni, si può migliorare notevolmente l’accuratezza e la tempestività del modello. Uno studio recente ha dimostrato che sul benchmark PopQA, modelli di dimensioni ridotte come 1,3 miliardi di parametri con il recupero possono ottenere prestazioni pari a un modello più di cento volte più grande con 175 miliardi di parametri (vedi Figura 4). In questo senso, la conoscenza rilevante di un sistema mirato con dati accessibili indicizzati di alta qualità può essere molto più estesa rispetto a un sistema generico completo. Questo può essere più importante per la maggior parte delle applicazioni aziendali che richiedono dati specifici del caso d’uso o dell’applicazione e, in molti casi, conoscenze locali anziché una vasta conoscenza generale. Qui è dove sarà realizzato il valore dei modelli agili in futuro.
Tre Aspetti che Contribuiscono all’Esplosiva Crescita dei Modelli Agili
Ci sono tre aspetti da considerare quando si valutano i benefici e il valore dei modelli agili:
- Alta efficienza a dimensioni di modello moderate.
- Licenza come open source o proprietaria.
- Specializzazione del modello come scopo generale o mirato, compresa la ricerca.
Per quanto riguarda le dimensioni, i modelli agili a scopo generale, come LLaMA-7B e -13B di Meta o i modelli open source Falcon 7B dell’Istituto di Innovazione Tecnologica, e i modelli proprietari come MPT-7B di MosaicML, Orca-13B di Microsoft Research e XGen-7B di Saleforce AI Research, stanno migliorando rapidamente (vedi Figura 6). Avere la scelta di modelli di piccole dimensioni ad alte prestazioni ha implicazioni significative per il costo di funzionamento e per la scelta degli ambienti di calcolo. Il modello con 175 miliardi di parametri di ChatGPT e gli stimati 1,8 trilioni di parametri per GPT-4 richiedono un’installazione massiccia di acceleratori come le GPU con abbastanza potenza di calcolo per gestire il carico di lavoro di formazione e messa a punto. Al contrario, i modelli agili possono eseguire generalmente l’elaborazione su qualsiasi hardware, da una singola CPU a socket, attraverso GPU di fascia bassa, fino ai più grandi rack di accelerazione. La definizione di intelligenza artificiale agile è attualmente fissata a 15 miliardi di parametri basati empiricamente sui risultati eccezionali dei modelli di dimensioni pari o inferiori a 13 miliardi di parametri. Nel complesso, i modelli agili offrono un approccio più conveniente e scalabile per gestire nuovi casi d’uso (vedi la sezione sui vantaggi e svantaggi dei modelli agili).
Il secondo aspetto della licenza open source consente a università e aziende di lavorare sui modelli degli altri, stimolando un boom di innovazioni creative. I modelli open source consentono un incredibile progresso delle capacità dei modelli di piccole dimensioni, come dimostrato nella Figura 5.
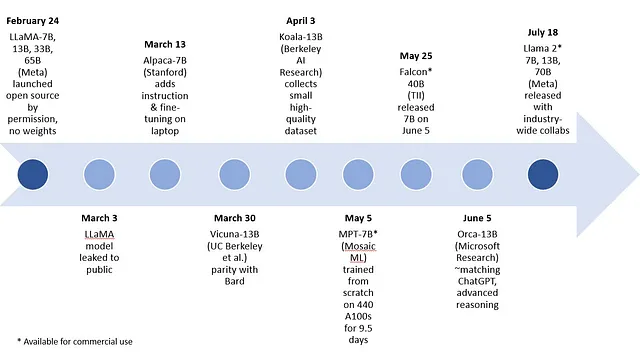
Ci sono numerosi esempi dell’inizio del 2023 di modelli agili di intelligenza artificiale generativa, a partire da LLaMA di Meta, che ha modelli con 7 miliardi, 13 miliardi, 33 miliardi e 65 miliardi di parametri. I seguenti modelli nell’intervallo di parametri 7B e 13B sono stati creati tramite messa a punto di LLaMA: Alpaca dell’Università di Stanford, Koala della Berkeley AI Research e Vicuna creato da ricercatori di UC Berkeley, Carnegie Mellon University, Stanford, UC San Diego e MBZUAI. Di recente, Microsoft Research ha pubblicato un articolo su Orca, un modello basato su LLaMA con 13 miliardi di parametri non ancora rilasciato, che imita il processo di ragionamento dei modelli giganti con risultati impressionanti prima di essere indirizzato o messo a punto per un particolare dominio.
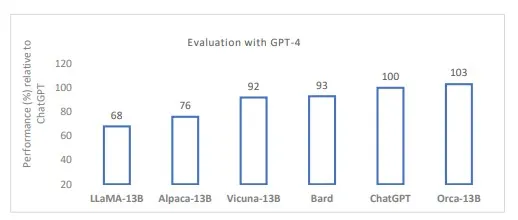
Vicuna potrebbe essere un buon proxy per i recenti modelli agili open source derivati da LLaMA come modello di base. Vicuna-13B è un chatbot creato da una collaborazione universitaria che è stato “sviluppato per affrontare la mancanza di dettagli di formazione e architettura nei modelli esistenti come ChatGPT”. Dopo essere stato messo a punto su conversazioni condivise dagli utenti di ShareGPT, la qualità delle risposte di Vicuna è superiore al 90% rispetto a ChatGPT e Google Bard quando viene utilizzato GPT-4 come giudice. Tuttavia, questi primi modelli open source non sono disponibili per uso commerciale. I modelli open source utilizzabili commercialmente MPT-7B di MosaicML e Falcon 7B dell’Istituto di Innovazione Tecnologica sono riportati essere di pari qualità a LLaMA-7B.
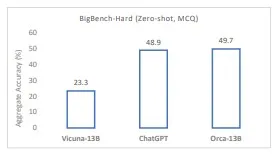
Orca “supera i modelli di istruzione convenzionali come Vicuna-13B di oltre il 100% nei benchmark di ragionamento complesso a zero-shot come Big-Bench Hard (BBH). Raggiunge la parità con ChatGPT-3.5 sul benchmark BBH”, secondo i ricercatori. La migliore performance di Orca-13B rispetto ad altri modelli generali rafforza l’idea che la grande dimensione dei modelli giganti possa derivare da modelli iniziali basati sulla forza bruta. La scala dei modelli fondamentali giganti può essere importante per alcuni modelli più piccoli come Orca-13B per distillare conoscenze e metodi, ma la dimensione non è necessariamente richiesta per l’inferenza, nemmeno nel caso generale. Una parola di cautela: una valutazione completa delle capacità cognitive, delle competenze funzionali e della memorizzazione delle conoscenze del modello sarà possibile solo quando sarà ampiamente distribuito ed esercitato.
Alla data di scrittura di questo blog, Meta ha rilasciato il loro modello Llama 2 con 7B, 13B e 70B di parametri. Arrivato solo quattro mesi dopo la prima generazione, il modello offre miglioramenti significativi. Nel grafico di confronto, un agile Llama 2 13B ottiene risultati simili a modelli più grandi della precedente generazione LLaMA, nonché a MPT-30B e Falcon 40B. Llama 2 è open source e gratuito per la ricerca e l’uso commerciale. È stato introdotto in stretta collaborazione con Microsoft e diversi altri partner, tra cui Intel. L’impegno di Meta verso i modelli open source e la sua ampia collaborazione daranno sicuramente un impulso aggiuntivo ai cicli rapidi di miglioramento interindustriale/accademico che stiamo vedendo per modelli di questo tipo.
Il terzo aspetto dei modelli agili riguarda la specializzazione. Molti dei nuovi modelli agili sono di uso generale, come LLaMA, Vicuna e Orca. I modelli agili generali possono fare affidamento esclusivamente sulla loro memoria parametrica, utilizzando aggiornamenti a basso costo attraverso metodi di adattamento come LoRA: Low-Rank Adaptation of Large Language Models, nonché la generazione potenziata dal recupero, che estrae conoscenze rilevanti da una corpora curata al volo durante il tempo di inferenza. Le soluzioni di recupero potenziate sono in via di definizione e miglioramento continuo con framework di GenAI come LangChain e Haystack. Questi framework consentono l’integrazione facile e flessibile dell’indicizzazione e l’accesso efficace a grandi corpora per il recupero basato sulla semantica.
La maggior parte degli utenti business preferisce modelli mirati che siano tarati per il loro particolare dominio di interesse. Questi modelli mirati tendono anche ad essere basati sul recupero per utilizzare tutti gli asset di informazione chiave. Ad esempio, gli utenti del settore sanitario potrebbero voler automatizzare le comunicazioni con i pazienti.
I modelli mirati utilizzano due metodi:
- Specializzazione del modello stesso per i compiti e il tipo di dati richiesti per i casi d’uso mirati. Ciò potrebbe essere fatto in modi diversi, tra cui il pre-training di un modello su conoscenze specifiche del dominio (come nel caso di phi-1 pre-trainato su dati di qualità da libri provenienti dal web), il fine-tuning di un modello di base ad uso generale della stessa dimensione (come nel caso di Clinical Camel che ha eseguito il fine-tuning su LLaMA-13B) o la distillazione e l’apprendimento di un modello gigante in un modello agile di tipo studente (come nel caso di come Orca ha imparato a imitare il processo di ragionamento di GPT-4, compresi i percorsi di spiegazione, i processi di pensiero passo-passo e altre istruzioni complesse).
- Curare e indicizzare i dati pertinenti per il recupero al volo, che potrebbe essere un volume elevato, ma comunque all’interno del campo/sistema dei casi d’uso mirati. I modelli possono recuperare contenuti web pubblici e dati privati aziendali o dei consumatori che vengono continuamente aggiornati. Gli utenti determinano quali fonti indicizzare, consentendo la scelta di risorse di alta qualità provenienti dal web oltre a risorse più complete come i dati privati di un individuo o i dati aziendali di un’azienda. Sebbene il recupero sia ora integrato sia nei sistemi giganti che agili, svolge un ruolo cruciale nei modelli più piccoli poiché fornisce tutte le informazioni necessarie per le prestazioni del modello. Consente anche alle aziende di rendere disponibili tutte le informazioni private e locali a un modello agile che viene eseguito all’interno del proprio ambiente di calcolo.
Vantaggi e Svantaggi dei Modelli di Intelligenza Artificiale Generativa Agili
In futuro, la dimensione dei modelli compatti potrebbe raggiungere fino a 20B o 25B di parametri, ma rimarrà comunque molto al di sotto dei 100B di parametri. Esistono anche una varietà di modelli di dimensioni intermedie come MPT-30B, Falcon 40B e Llama 2 70B. Sebbene si preveda che si comportino meglio dei modelli più piccoli a zero-shot, non mi aspetterei che si comportino materialmente meglio per qualsiasi insieme definito di funzionalità rispetto ai modelli agili, mirati e basati sul recupero.
Rispetto ai modelli giganti, i modelli agili presentano molti vantaggi, che vengono ulteriormente potenziati quando il modello è mirato e basato sul recupero. Questi benefici includono:
- Modelli sostenibili e a costo inferiore: Modelli con costi notevolmente inferiori per l’addestramento e il calcolo dell’inferenza. I costi di calcolo dell’inferenza in tempo reale potrebbero essere il fattore determinante per la fattibilità dei modelli orientati al business integrati in utilizzi 24×7, e l’impatto ambientale molto ridotto è significativo anche se preso in considerazione in modo aggregato su ampie distribuzioni. Infine, con i loro sistemi sostenibili, specifici e orientati funzionalmente, i modelli agili non cercano di affrontare ambiziosi obiettivi di intelligenza artificiale generale (AGI) e quindi sono meno coinvolti nel dibattito pubblico e normativo relativo a quest’ultimo.
- Iterazioni di fine-tuning più veloci: I modelli più piccoli possono essere sottoposti a fine-tuning in poche ore (o meno), aggiungendo nuove informazioni o funzionalità al modello tramite metodi di adattamento come LoRA, che sono molto efficaci nei modelli agili. Ciò consente cicli di miglioramento più frequenti, mantenendo il modello costantemente aggiornato in base alle sue esigenze di utilizzo.
- Vantaggi dei modelli basati sul recupero: I sistemi di recupero rifattorizzano le conoscenze, facendo riferimento alla maggior parte delle informazioni dalle fonti dirette anziché dalla memoria parametrica del modello. Ciò migliora quanto segue: – Spiegabilità: I modelli di recupero utilizzano l’attribuzione delle fonti, fornendo la provenienza o la possibilità di risalire alla fonte delle informazioni per fornire credibilità. – Tempestività: Una volta che una fonte aggiornata è indicizzata, è immediatamente disponibile per l’uso da parte del modello senza bisogno di addestramento o fine-tuning. Ciò consente di aggiungere o aggiornare continuamente informazioni rilevanti in quasi tempo reale. – Scopo dei dati: Le informazioni indicizzate per il recupero su richiesta possono essere molto ampie e dettagliate. Quando si concentra sui suoi domini di destinazione, il modello può coprire un’ampia portata e profondità di dati privati e pubblici. Può includere un volume e dettagli maggiori nel suo spazio di destinazione rispetto a un dataset di addestramento di modelli fondamentali giganti. – Accuratezza: L’accesso diretto ai dati nella loro forma originale, dettaglio e contesto può ridurre le allucinazioni e le approssimazioni dei dati. Può fornire risposte affidabili e complete purché siano nello spazio di recupero. Con modelli più piccoli, c’è anche meno conflitto tra le informazioni curate tracciabili recuperate su richiesta e le informazioni memorizzate (come nei modelli giganti) che potrebbero essere datate, parziali e non attribuite alle fonti.
- Scelta dell’hardware: L’inferenza dei modelli agili può essere effett
Alcune sfide dei modelli agili sono ancora degne di menzione:
- Ridotta gamma di compiti: I modelli giganti ad uso generico hanno una versatilità eccezionale e si distinguono soprattutto nell’utilizzo di nuovi compiti in zero-shot che non erano stati considerati in precedenza. La portata e l’ambito che possono essere raggiunti con i sistemi agili sono ancora in fase di valutazione, ma sembra migliorino con i modelli recenti. I modelli mirati presuppongono che la gamma di compiti sia nota e definita durante la pre-formazione e/o il raffinamento, quindi la riduzione dell’ambito non dovrebbe influire sulle capacità rilevanti. I modelli mirati non sono monocompetenza, ma piuttosto una famiglia di capacità correlate. Ciò può portare alla frammentazione come risultato dei modelli agili specifici per compiti o aziende.
- Potrebbero essere migliorati con il raffinamento a poche iterazioni: Affinché un modello possa affrontare efficacemente uno spazio mirato, non è sempre necessario il raffinamento, ma può aiutare l’efficacia dell’IA adattando il modello ai compiti e alle informazioni necessarie per l’applicazione. Le tecniche moderne consentono di eseguire questo processo con un piccolo numero di esempi e senza la necessità di competenze approfondite in scienze dei dati.
- I modelli di recupero richiedono l’indicizzazione di tutti i dati di origine: I modelli recuperano le informazioni necessarie durante l’inferenza attraverso la mappatura degli indici, ma c’è il rischio di perdere una fonte di informazioni, rendendola non disponibile per il modello. Per garantire la provenienza, la spiegabilità e altre proprietà, i modelli di recupero mirati non dovrebbero fare affidamento su informazioni dettagliate memorizzate nella memoria parametrica, ma dovrebbero invece fare affidamento principalmente su informazioni indicizzate disponibili per l’estrazione quando necessario.
Riassunto
Il grande balzo nell’IA generativa sta consentendo nuove capacità come agenti di intelligenza artificiale che conversano in linguaggio naturale, la sintesi e la generazione di testi convincenti, la creazione di immagini, l’utilizzo del contesto delle iterazioni precedenti e molto altro. Questo blog introduce il termine “IA agile” e sostiene il motivo per cui sarà il metodo predominante nella distribuzione della GenAI su larga scala. In poche parole, i modelli di IA agili sono più veloci nell’esecuzione, più rapidi nel rinfresco attraverso il raffinamento continuo e più adatti ai cicli rapidi di miglioramento tecnologico grazie all’innovazione collettiva della comunità open source.
Come dimostrato attraverso numerosi esempi, le prestazioni eccezionali che sono emerse attraverso l’evoluzione dei modelli più grandi mostrano che i modelli agili non richiedono la stessa mole massiccia dei modelli giganti. Una volta che le capacità cognitive sottostanti sono state acquisite, la funzionalità richiesta è stata ottimizzata e i dati resi disponibili al bisogno, i modelli agili forniscono il valore più elevato per il mondo degli affari.
Detto questo, i modelli agili non renderanno estinti i modelli giganti. Si prevede ancora che i modelli giganti si comportino meglio in un ambiente istantaneo, pronto all’uso. Questi modelli di grandi dimensioni potrebbero anche essere utilizzati come sorgente (modello di insegnante) per la distillazione in modelli più piccoli e agili. Sebbene i modelli giganti abbiano un’enorme quantità di informazioni memorizzate aggiuntive per affrontare qualsiasi possibile utilizzo e siano dotati di molteplici competenze, questa generalità non è prevista essere richiesta per la maggior parte delle applicazioni GenAI. Al contrario, la capacità di raffinare un modello alle informazioni e alle competenze rilevanti per il dominio, oltre alla capacità di recuperare informazioni recenti da fonti locali e globali curate, sarebbe una proposta di valore molto migliore per molte applicazioni.
Considerare i modelli di intelligenza artificiale agili e mirati come moduli che possono essere incorporati in qualsiasi applicazione esistente offre una proposta di





