Incontra Rodin un nuovo framework di intelligenza artificiale (AI) per generare avatar digitali 3D da diverse fonti di input
Incontra Rodin, un nuovo framework di IA per generare avatar digitali 3D da diverse fonti di input.


I modelli generativi stanno diventando la soluzione di fatto per molte sfide in campo informatico. Rappresentano uno dei modi più promettenti per analizzare e sintetizzare dati visivi. Stable Diffusion è il modello generativo più conosciuto per la produzione di immagini belle e realistiche da un input complesso. L’architettura si basa sui Modelli di Diffusione (DM), che hanno dimostrato un potere generativo fenomenale per immagini e video. I progressi rapidi nella diffusione e nella modellazione generativa stanno alimentando una rivoluzione nella creazione di contenuti 2D. Il mantra è piuttosto semplice: “Se puoi descriverlo, puoi visualizzarlo”, o meglio, “se puoi descriverlo, il modello può dipingerlo per te”. È davvero incredibile ciò di cui i modelli generativi sono capaci.
Mentre i contenuti 2D sono stati utilizzati come test di stress per i DM, i contenuti 3D presentano diverse sfide dovute, ma non solo, alla dimensione aggiuntiva. Generare contenuti 3D, come avatar, con la stessa qualità dei contenuti 2D è un compito difficile data la memoria e i costi di elaborazione, che possono essere proibitivi per produrre i dettagli ricchi richiesti per avatar di alta qualità.
Con la tecnologia che spinge l’uso di avatar digitali nei film, nei giochi, nel metaverso e nell’industria 3D, consentire a chiunque di creare un avatar digitale può essere vantaggioso. Questa è la motivazione che guida lo sviluppo di questo lavoro.
- Dove sono tutte le donne?
- Potenziare l’IA su dispositivo Qualcomm e Meta collaborano con la tecnologia Llama 2
- CatBoost Una soluzione per costruire modelli con dati categorici
Gli autori propongono la Roll-out diffusion network (Rodin) per affrontare il problema della creazione di un avatar digitale. Una panoramica del modello è riportata nella figura sottostante.
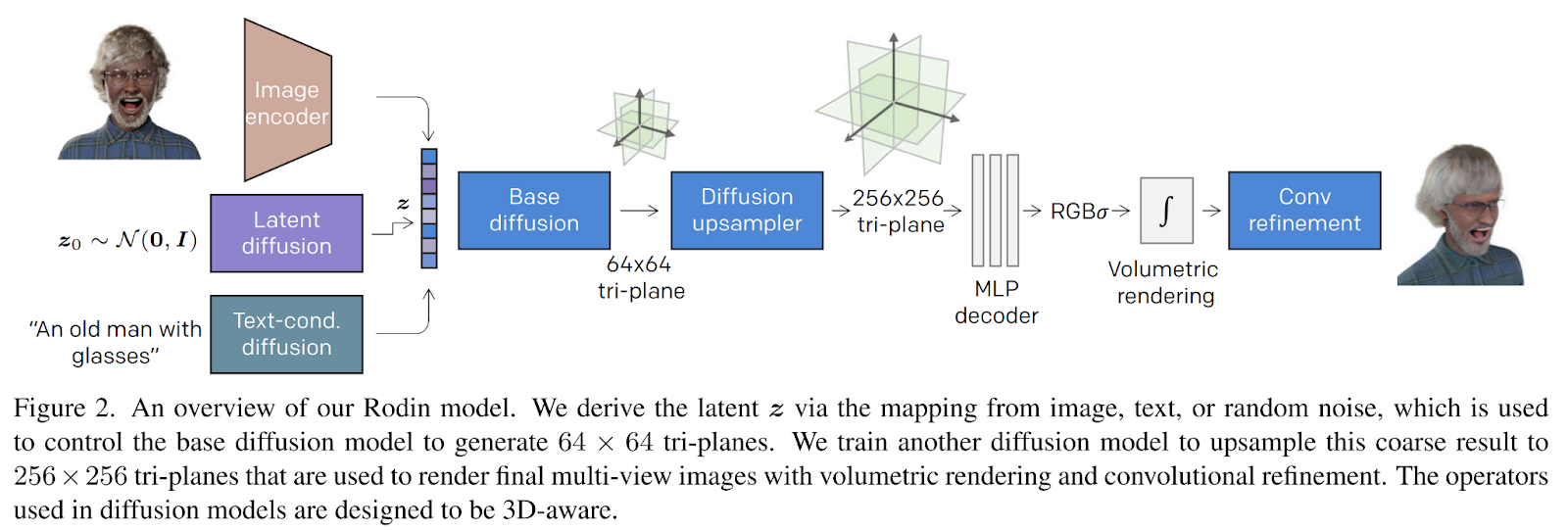

L’input per il modello può essere un’immagine, un rumore casuale o una descrizione testuale dell’avatar desiderato. Il vettore latente z viene successivamente derivato dall’input fornito e utilizzato nella diffusione. Il processo di diffusione consiste in diversi passaggi di aggiunta di rumore e denoising. Innanzitutto, viene aggiunto rumore casuale allo stato iniziale o all’immagine e denoised per ottenere un’immagine molto più nitida.
La differenza qui risiede nella natura 3D del contenuto desiderato. Il processo di diffusione viene eseguito come al solito, ma invece di mirare a un’immagine 2D, il modello di diffusione genera la geometria approssimativa dell’avatar, seguita da un upsampler di diffusione per la sintesi dei dettagli.
L’efficienza computazionale e di memoria è uno degli obiettivi di questo lavoro. Per raggiungere questo obiettivo, gli autori hanno sfruttato la rappresentazione tri-piano (tre assi) di un campo di radianza neurale, che, rispetto alle griglie voxel, offre una memoria considerevolmente più ridotta senza sacrificare l’espressività.
Successivamente, viene addestrato un altro modello di diffusione per aumentare la rappresentazione tri-piano prodotta fino a raggiungere la risoluzione desiderata. Infine, viene sfruttato un decoder MLP leggero composto da 4 strati completamente connessi per generare un’immagine volumetrica RGB.
Di seguito sono riportati alcuni risultati.

Confrontato con gli approcci state-of-the-art menzionati, Rodin fornisce gli avatar digitali più nitidi. Per il modello, non sono visibili artefatti nei campioni condivisi, a differenza delle altre tecniche.
Questo è stato il riassunto di Rodin, un nuovo framework per generare facilmente avatar digitali 3D da varie fonti di input. Se sei interessato, puoi trovare ulteriori informazioni ai link sottostanti.





