Generare automaticamente immagini a partire dalle conclusioni dei rapporti di radiologia utilizzando l’Intelligenza Artificiale generativa su AWS
Generazione automatica di immagini radiologiche tramite IA generativa su AWS
I rapporti radiologici sono documenti completi e lunghi che descrivono e interpretano i risultati di un esame di imaging radiologico. In un flusso di lavoro tipico, il radiologo supervisiona, legge e interpreta le immagini, per poi riassumere in modo conciso le principali scoperte. La sintesi (o impressione) è la parte più importante del rapporto perché aiuta i clinici e i pazienti a concentrarsi sui contenuti critici del rapporto che contengono informazioni utili per la presa di decisioni cliniche. Creare un’impressione chiara e incisiva richiede molto più impegno che semplicemente ripetere le scoperte. L’intero processo è quindi laborioso, richiede molto tempo e è soggetto a errori. Spesso sono necessari anni di formazione per i medici per accumulare sufficiente competenza nella scrittura di sintesi concise e informative dei rapporti radiologici, mettendo ancora più in evidenza l’importanza dell’automazione del processo. Inoltre, la generazione automatica della sintesi dei risultati del rapporto è fondamentale per la segnalazione radiologica. Consente di tradurre i rapporti in un linguaggio comprensibile all’essere umano, alleviando così il peso per i pazienti di leggere rapporti lunghi e oscuri.
Per risolvere questo problema, proponiamo l’uso dell’IA generativa, un tipo di IA in grado di creare nuovo contenuto e idee, inclusi conversazioni, storie, immagini, video e musica. L’IA generativa è alimentata da modelli di apprendimento automatico (ML) – modelli molto grandi preaddestrati su vaste quantità di dati e comunemente definiti come modelli di base (FMs). Recenti avanzamenti nell’ML (in particolare l’invenzione dell’architettura di rete neurale basata su trasformatori) hanno portato alla nascita di modelli che contengono miliardi di parametri o variabili. La soluzione proposta in questo post utilizza il fine-tuning di ampi modelli linguistici preaddestrati (LLMs) per aiutare a generare sintesi basate su scoperte nei rapporti radiologici.
Questo post illustra una strategia per il fine-tuning di LLM pubblicamente disponibili per il compito di sintesi dei rapporti radiologici utilizzando i servizi AWS. Gli LLM hanno dimostrato notevoli capacità nella comprensione e generazione del linguaggio naturale, servendo da modelli di base che possono essere adattati a vari domini e compiti. Ci sono significativi vantaggi nell’utilizzare un modello preaddestrato. Riduce i costi di calcolo, riduce l’impronta di carbonio e consente di utilizzare modelli all’avanguardia senza doverne addestrare uno da zero.
La nostra soluzione utilizza il modello FLAN-T5 XL FM, utilizzando Amazon SageMaker JumpStart, che è un hub di ML che offre algoritmi, modelli e soluzioni di ML. Illustreremo come fare questo utilizzando un notebook in Amazon SageMaker Studio. Il fine-tuning di un modello preaddestrato comporta ulteriori addestramenti su dati specifici per migliorare le prestazioni su un compito diverso ma correlato. Questa soluzione prevede il fine-tuning del modello FLAN-T5 XL, che è una versione migliorata di T5 (Text-to-Text Transfer Transformer) LLM di uso generale. T5 riformula i compiti di elaborazione del linguaggio naturale (NLP) in un formato unificato di testo-testo, a differenza dei modelli di tipo BERT che possono outputtare solo una classe o un intervallo dell’input. Viene sottoposto a fine-tuning per un compito di sintesi su 91.544 rapporti radiologici di testo libero ottenuti dal dataset MIMIC-CXR.
- Perché gli scienziati si stanno immergendo nel mondo virtuale
- Dodici nazioni esortano i giganti dei social media a combattere lo scraping illegale dei dati
- Il ruolo dell’IA nell’emergente economia blu
Panoramica della soluzione
In questa sezione, discutiamo dei componenti chiave della nostra soluzione: la scelta della strategia per il compito, il fine-tuning di un LLM e la valutazione dei risultati. Illustreremo anche l’architettura della soluzione e i passaggi per implementarla.
Identificare la strategia per il compito
Esistono diverse strategie per affrontare il compito di automatizzare la sintesi dei rapporti clinici. Ad esempio, potremmo utilizzare un modello di linguaggio specializzato preaddestrato su rapporti clinici da zero. In alternativa, potremmo eseguire direttamente il fine-tuning di un modello di linguaggio di uso generale disponibile pubblicamente per svolgere il compito clinico. L’utilizzo di un modello di dominio agnostico sottoposto a fine-tuning può essere necessario in contesti in cui l’addestramento di un modello di linguaggio da zero è troppo costoso. In questa soluzione, dimostriamo l’approccio di quest’ultimo tipo utilizzando un modello FLAN-T5 XL, che sottoponiamo a fine-tuning per il compito clinico di sintesi dei rapporti radiologici. Il diagramma seguente illustra il flusso di lavoro del modello.

Un tipico rapporto radiologico è ben organizzato e succinto. Tali rapporti presentano spesso tre sezioni chiave:
- Sfondo – Fornisce informazioni generali sulle caratteristiche demografiche del paziente con informazioni essenziali sul paziente, anamnesi clinica, anamnesi medica rilevante e dettagli delle procedure dell’esame
- Scoperte – Presenta diagnosi e risultati dettagliati dell’esame
- Impressioni – Riassume in modo conciso le scoperte più salienti o l’interpretazione delle scoperte con una valutazione della loro importanza e una diagnosi potenziale basata sulle anomalie osservate
Utilizzando la sezione dei risultati nei referti di radiologia, la soluzione genera la sezione delle impressioni, che corrisponde alla riassunzione dei medici. La seguente figura è un esempio di un referto di radiologia.

Affinare un modello LLM a scopo generale per un compito clinico
In questa soluzione, affiniamo un modello FLAN-T5 XL (ottimizzando tutti i parametri del modello per il compito). Affiniamo il modello utilizzando il dataset clinico MIMIC-CXR, che è un dataset di radiografie del torace disponibile pubblicamente. Per affinare questo modello tramite SageMaker Jumpstart, devono essere forniti esempi etichettati nel formato di coppie {prompt, completamento}. In questo caso, utilizziamo coppie di {Risultati, Impressioni} dai referti originali nel dataset MIMIC-CXR. Per l’inferenza, utilizziamo un prompt come mostrato nell’esempio seguente:

Il modello viene affinato su un’istanza di calcolo accelerato ml.p3.16xlarge con 64 CPU virtuali e 488 GiB di memoria. Per la convalida, è stato selezionato casualmente il 5% del dataset. Il tempo trascorso del job di addestramento di SageMaker con l’affinamento è stato di 38.468 secondi (circa 11 ore).
Valutare i risultati
Quando l’addestramento è completo, è fondamentale valutare i risultati. Per un’analisi quantitativa dell’impressione generata, utilizziamo ROUGE (Recall-Oriented Understudy for Gisting Evaluation), la metrica più comunemente utilizzata per valutare la riassunzione. Questa metrica confronta un riassunto prodotto automaticamente con un riassunto o una traduzione di riferimento (prodotta dall’uomo). ROUGE1 si riferisce all’overlap di unigrammi (ogni parola) tra il candidato (l’output del modello) e i riassunti di riferimento. ROUGE2 si riferisce all’overlap di bigrammi (due parole) tra il candidato e i riassunti di riferimento. ROUGEL è una metrica a livello di frasi e si riferisce alla sottosequenza comune più lunga (LCS) tra due pezzi di testo. Ignora le righe vuote nel testo. ROUGELsum è una metrica a livello di riassunto. Per questa metrica, le righe vuote nel testo non vengono ignorate ma vengono interpretate come limiti di frase. Viene quindi calcolato il LCS tra ciascuna coppia di frasi di riferimento e candidato, e quindi viene calcolato il union-LCS. Per l’aggregazione di questi punteggi su un dato insieme di frasi di riferimento e candidato, viene calcolata la media.
Guida e architettura
L’architettura complessiva della soluzione, come mostrato nella figura seguente, consiste principalmente in un ambiente di sviluppo del modello che utilizza SageMaker Studio, il rilascio del modello con un endpoint SageMaker e un cruscotto di reporting che utilizza Amazon QuickSight.
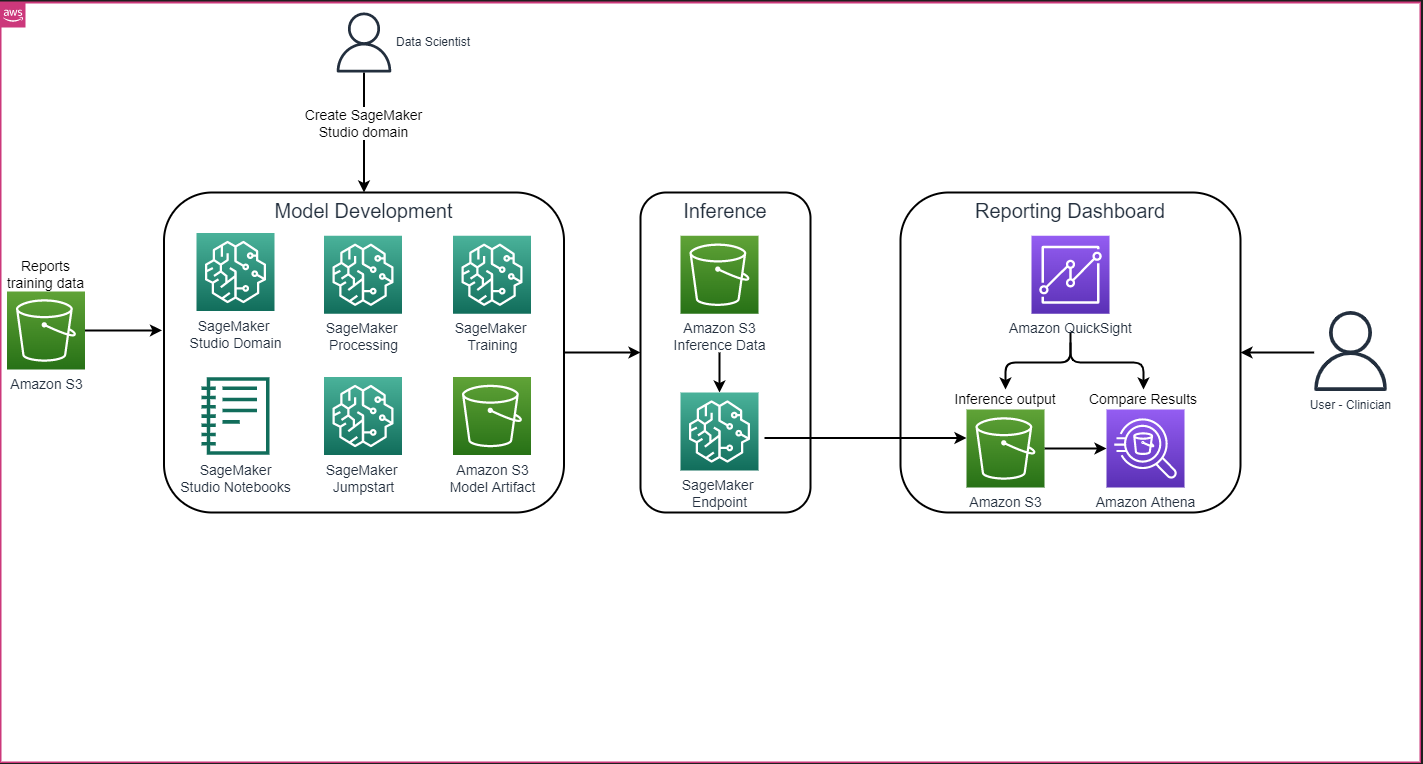
Nelle sezioni seguenti, demostreremo l’affinamento di un LLM disponibile in SageMaker JumpStart per la riassunzione di un compito specifico del dominio tramite il SDK Python di SageMaker. In particolare, discutiamo i seguenti argomenti:
- Passaggi per configurare l’ambiente di sviluppo
- Una panoramica dei dataset dei referti di radiologia su cui il modello viene affinato e valutato
- Una dimostrazione dell’affinamento del modello FLAN-T5 XL utilizzando SageMaker JumpStart in modo programmabile con il SDK Python di SageMaker
- Inferenza e valutazione dei modelli pre-addestrati e affinati
- Confronto dei risultati tra modello pre-addestrato e modelli affinati
La soluzione è disponibile nel repository GitHub Generating Radiology Report Impression using generative AI with Large Language Model on AWS.
Prerequisiti
Per iniziare, è necessario un account AWS in cui è possibile utilizzare SageMaker Studio. È necessario creare un profilo utente per SageMaker Studio se non ne si dispone già.
Il tipo di istanza di addestramento utilizzato in questo post è ml.p3.16xlarge. Nota che il tipo di istanza p3 richiede un aumento del limite di quota del servizio.
Il dataset MIMIC CXR può essere accessibile tramite un accordo di utilizzo dei dati, che richiede la registrazione dell’utente e il completamento di un processo di accreditamento.
Configurazione dell’ambiente di sviluppo
Per configurare il tuo ambiente di sviluppo, crea un bucket S3, configura un notebook, crea endpoint e distribuisci i modelli, e crea un dashboard QuickSight.
Crea un bucket S3
Crea un bucket S3 chiamato llm-radiology-bucket per ospitare i dataset di addestramento e valutazione. Verrà utilizzato anche per archiviare l’artefatto del modello durante lo sviluppo del modello.
Configura un notebook
Completa i seguenti passaggi:
- Avvia SageMaker Studio sia dalla console di SageMaker che dall’interfaccia della riga di comando di AWS (AWS CLI).
Per ulteriori informazioni su come aderire a un dominio, consulta la guida Onboard to Amazon SageMaker Domain.
- Crea un nuovo notebook di SageMaker Studio per pulire i dati del report e per il raffinamento del modello. Utilizziamo un’istanza di notebook ml.t3.medium 2vCPU+4GiB con un kernel Python 3.
- All’interno del notebook, installa i pacchetti pertinenti come
nest-asyncio,IPyWidgets(per i widget interattivi per il notebook Jupyter) e il SageMaker Python SDK:
!pip install nest-asyncio==1.5.5 --quiet
!pip install ipywidgets==8.0.4 --quiet
!pip install sagemaker==2.148.0 --quietCrea endpoint e distribuisci i modelli per l’inferenza
Per effettuare l’inferenza sui modelli pre-addestrati e raffinati, crea un endpoint e distribuisci ogni modello nel notebook come segue:
- Crea un oggetto modello dalla classe Model che può essere distribuito su un endpoint HTTPS.
- Crea un endpoint HTTPS con il metodo predefinito
deploy()dell’oggetto modello:
from sagemaker import model_uris, script_uris
from sagemaker.model import Model
from sagemaker.predictor import Predictor
from sagemaker.utils import name_from_base
# Recupera l'URI del modello pre-addestrato
pre_trained_model_uri =model_uris.retrieve(model_id=model_id, model_version=model_version, model_scope="inference")
large_model_env = {"SAGEMAKER_MODEL_SERVER_WORKERS": "1", "TS_DEFAULT_WORKERS_PER_MODEL": "1"}
pre_trained_name = name_from_base(f"jumpstart-demo-pre-trained-{model_id}")
# Crea l'istanza del modello SageMaker del modello pre-addestrato
if ("small" in model_id) or ("base" in model_id):
deploy_source_uri = script_uris.retrieve(
model_id=model_id, model_version=model_version, script_scope="inference"
)
pre_trained_model = Model(
image_uri=deploy_image_uri,
source_dir=deploy_source_uri,
entry_point="inference.py",
model_data=pre_trained_model_uri,
role=aws_role,
predictor_cls=Predictor,
name=pre_trained_name,
)
else:
# Per quei modelli larghi, abbiamo già riorganizzato lo script di inferenza e il modello
# artefatti per te, quindi l'argomento `source_dir` per Model non è richiesto.
pre_trained_model = Model(
image_uri=deploy_image_uri,
model_data=pre_trained_model_uri,
role=aws_role,
predictor_cls=Predictor,
name=pre_trained_name,
env=large_model_env,
)
# Distribuisci il modello pre-addestrato. Nota che è necessario passare la classe Predictor quando si distribuisce il modello
# attraverso la classe Model, per poter eseguire l'inferenza tramite l'API di SageMaker
pre_trained_predictor = pre_trained_model.deploy(
initial_instance_count=1,
instance_type=inference_instance_type,
predictor_cls=Predictor,
endpoint_name=pre_trained_name,
)Crea un dashboard QuickSight
Crea un dashboard QuickSight con una sorgente dati Athena con i risultati di inferenza in Amazon Simple Storage Service (Amazon S3) per confrontare i risultati di inferenza con la verità di riferimento. La seguente schermata mostra il nostro esempio di dashboard. 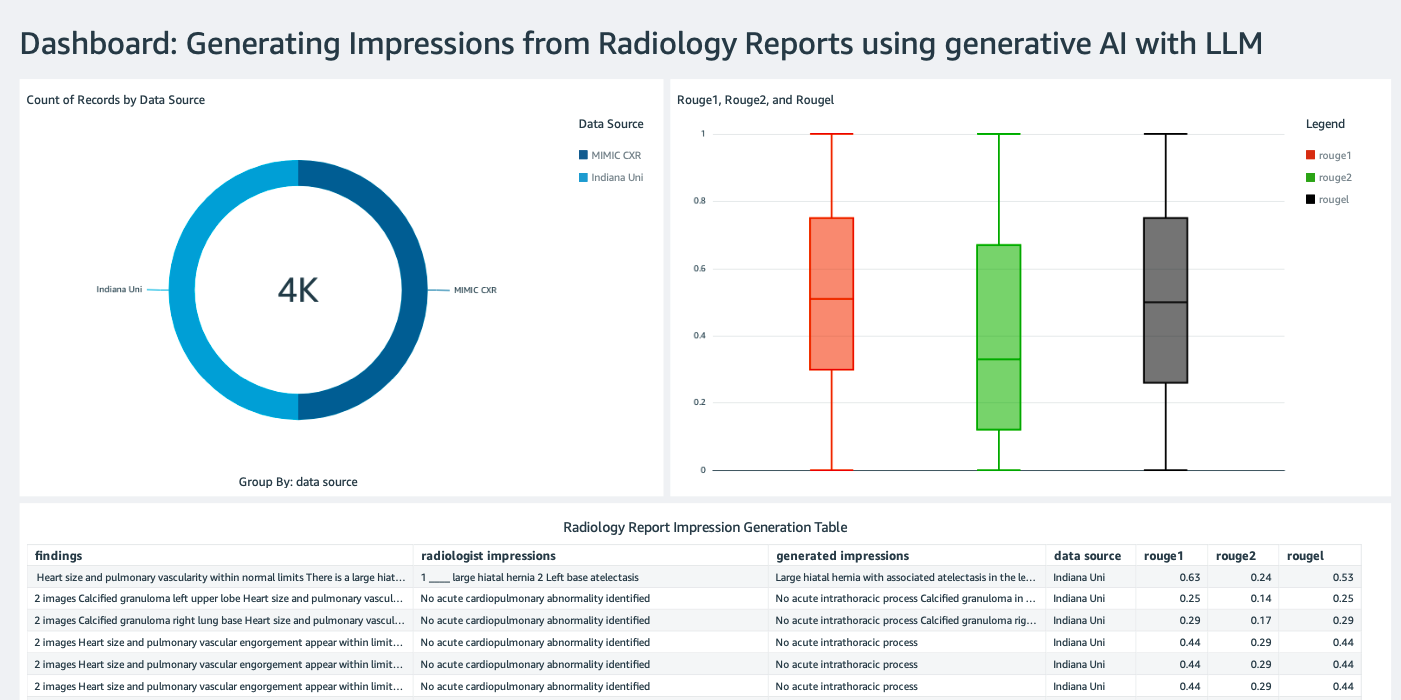
Dataset dei report di radiologia
Il modello è ora ottimizzato, tutti i parametri del modello sono stati ottimizzati su 91.544 report scaricati dal dataset MIMIC-CXR v2.0. Poiché abbiamo utilizzato solo i dati di testo dei report di radiologia, abbiamo scaricato solo un file di report compresso (mimic-cxr-reports.zip) dal sito web MIMIC-CXR. Ora valutiamo il modello ottimizzato su 2.000 report (denominati dataset dev1) provenienti da un sottoinsieme separato di questo dataset. Utilizziamo altri 2.000 report di radiologia (denominati dev2) per valutare il modello ottimizzato dalla raccolta di radiografie del torace della rete ospedaliera dell’Università dell’Indiana. Tutti i dataset vengono letti come file JSON e caricati nel bucket S3 appena creato llm-radiology-bucket. Si noti che tutti i dataset di default non contengono alcuna informazione sanitaria protetta (PHI); tutte le informazioni sensibili vengono sostituite da tre underscore consecutivi (___) dai fornitori.
Ottimizzazione con il SageMaker Python SDK
Per l’ottimizzazione, il parametro model_id è specificato come huggingface-text2text-flan-t5-xl dall’elenco di modelli di SageMaker JumpStart. Il parametro training_instance_type viene impostato come ml.p3.16xlarge e il parametro inference_instance_type come ml.g5.2xlarge. I dati di addestramento in formato JSON vengono letti dal bucket S3. Il passaggio successivo consiste nell’utilizzare il model_id selezionato per estrarre gli URI delle risorse di SageMaker JumpStart, inclusi image_uri (l’URI del Registro dei contenitori elastici di Amazon (Amazon ECR) per l’immagine Docker), model_uri (l’URI dell’artefatto del modello pre-addestrato su Amazon S3) e script_uri (lo script di addestramento):
from sagemaker import image_uris, model_uris, script_uris
# L'istanza di addestramento utilizzerà questa immagine
train_image_uri = image_uris.retrieve(
region=aws_region,
framework=None, # automaticamente inferito da model_id
model_id=model_id,
model_version=model_version,
image_scope="training",
instance_type=training_instance_type,
)
# Modello pre-addestrato
train_model_uri = model_uris.retrieve(
model_id=model_id, model_version=model_version, model_scope="training"
)
# Script da eseguire sull'istanza di addestramento
train_script_uri = script_uris.retrieve(
model_id=model_id, model_version=model_version, script_scope="training"
)
output_location = f"s3://{output_bucket}/demo-llm-rad-fine-tune-flan-t5/"Inoltre, viene configurata una posizione di output come una cartella all’interno del bucket S3.
Viene modificato solo un iperparametro, epochs, impostandolo a 3, mentre tutti gli altri sono impostati su default:
from sagemaker import hyperparameters
# Recupera gli iperparametri predefiniti per l'ottimizzazione del modello
hyperparameters = hyperparameters.retrieve_default(model_id=model_id, model_version=model_version)
# Sovrascriviamo alcuni iperparametri predefiniti con valori personalizzati
hyperparameters["epochs"] = "3"
print(hyperparameters)Vengono definite e elencate le metriche di addestramento come eval_loss (per la perdita di validazione), loss (per la perdita di addestramento) e epoch:
from sagemaker.estimator import Estimator
from sagemaker.utils import name_from_base
model_name = "-".join(model_id.split("-")[2:]) # ottieni la parte più informativa dell'ID
training_job_name = name_from_base(f"js-demo-{model_name}-{hyperparameters['epochs']}")
print(f"{bold}nome del job:{unbold} {training_job_name}")
training_metric_definitions = [
{"Name": "val_loss", "Regex": "'eval_loss': ([0-9\\.]+)"},
{"Name": "train_loss", "Regex": "'loss': ([0-9\\.]+)"},
{"Name": "epoch", "Regex": "'epoch': ([0-9\\.]+)"},
]Utilizziamo gli URI delle risorse di SageMaker JumpStart (image_uri, model_uri, script_uri) identificati in precedenza per creare un estimatore e ottimizzarlo sul dataset di addestramento specificando il percorso S3 del dataset. La classe Estimator richiede un parametro entry_point. In questo caso, JumpStart utilizza transfer_learning.py. L’attività di addestramento non riesce ad avviarsi se questo valore non è impostato.
# Crea un'istanza di Estimator di SageMaker
sm_estimator = Estimator(
role=aws_role,
image_uri=train_image_uri,
model_uri=train_model_uri,
source_dir=train_script_uri,
entry_point="transfer_learning.py",
instance_count=1,
instance_type=training_instance_type,
volume_size=300,
max_run=360000,
hyperparameters=hyperparameters,
output_path=output_location,
metric_definitions=training_metric_definitions,
)
# Avvia un job di addestramento di SageMaker sui dati situati nel percorso S3 indicato
# I job di addestramento possono richiedere ore, è consigliabile impostare wait=False,
# e monitorare lo stato del job tramite la console di SageMaker
sm_estimator.fit({"training": train_data_location}, job_name=training_job_name, wait=True)Questo job di addestramento può richiedere ore per completarsi; pertanto, è consigliabile impostare il parametro wait su False e monitorare lo stato del job di addestramento sulla console di SageMaker. Utilizzare la funzione TrainingJobAnalytics per tenere traccia delle metriche di addestramento in diversi timestamp:
from sagemaker import TrainingJobAnalytics
# Attendere un paio di minuti affinché il job inizi prima di eseguire questa cella
# Questo può essere chiamato mentre il job è ancora in esecuzione
df = TrainingJobAnalytics(training_job_name=training_job_name).dataframe()Deploy degli endpoint di inferenza
Per effettuare confronti, vengono deployati gli endpoint di inferenza sia per il modello pre-addestrato che per il modello fine-tuned.
Prima di tutto, recuperare l’URI dell’immagine Docker di inferenza utilizzando model_id, e utilizzare questo URI per creare un’istanza di modello di SageMaker per il modello pre-addestrato. Deployare il modello pre-addestrato creando un endpoint HTTPS con il metodo predefinito deploy() dell’oggetto modello. Per eseguire l’inferenza tramite l’API di SageMaker, assicurarsi di passare la classe Predictor.
from sagemaker import image_uris
# Recuperare l'URI dell'immagine Docker di inferenza. Questa è l'immagine di base di HuggingFace
deploy_image_uri = image_uris.retrieve(
region=aws_region,
framework=None, # automaticamente dedotto da model_id
model_id=model_id,
model_version=model_version,
image_scope="inference",
instance_type=inference_instance_type,
)
# Recuperare l'URI del modello pre-addestrato
pre_trained_model_uri = model_uris.retrieve(
model_id=model_id, model_version=model_version, model_scope="inference"
)
pre_trained_model = Model(
image_uri=deploy_image_uri,
model_data=pre_trained_model_uri,
role=aws_role,
predictor_cls=Predictor,
name=pre_trained_name,
env=large_model_env,
)
# Deployare il modello pre-addestrato. Notare che è necessario passare la classe Predictor quando si deploya il modello
# tramite la classe Model, per poter eseguire l'inferenza tramite l'API di SageMaker
pre_trained_predictor = pre_trained_model.deploy(
initial_instance_count=1,
instance_type=inference_instance_type,
predictor_cls=Predictor,
endpoint_name=pre_trained_name,
)Ripetere il passaggio precedente per creare un’istanza di modello di SageMaker per il modello fine-tuned e creare un endpoint per deployare il modello.
Valutare i modelli
Prima di tutto, impostare la lunghezza del testo riassunto, il numero di output del modello (dovrebbe essere maggiore di 1 se è necessario generare più riassunti) e il numero di beam per la ricerca beam.
Costruire la richiesta di inferenza come payload JSON e utilizzarla per interrogare gli endpoint per i modelli pre-addestrato e fine-tuned.
Calcolare i punteggi aggregati ROUGE (ROUGE1, ROUGE2, ROUGEL, ROUGELsum) come descritto in precedenza.
Confrontare i risultati
La seguente tabella mostra i risultati della valutazione per i dataset dev1 e dev2. Il risultato della valutazione su dev1 (2.000 risultati dal report di radiologia MIMIC CXR) mostra un miglioramento di circa 38 punti percentuali nei punteggi aggregati ROUGE1 e ROUGE2 rispetto al modello pre-addestrato. Per dev2, si osserva un miglioramento di 31 punti percentuali e 25 punti percentuali nei punteggi ROUGE1 e ROUGE2. Nel complesso, il fine-tuning ha portato a un miglioramento di 38,2 punti percentuali e 31,3 punti percentuali nei punteggi ROUGELsum per i dataset dev1 e dev2, rispettivamente.
|
Evaluazione Dataset |
Modello Pre-allenato | Modello Fine-tuned | ||||||
| R OUGE1 | R OUGE2 | R OUGEL | ROUG ELsum | R OUGE1 | R OUGE2 | R OUGEL | ROUG ELsum | |
dev1 |
0 .2239 | 0 .1134 | 0 .1891 | 0 .1891 | 0 .6040 | 0 .4800 | 0 .5705 | 0 .5708 |
dev2 |
0 .1583 | 0 .0599 | 0 .1391 | 0 .1393 | 0 .4660 | 0 .3125 | 0 .4525 | 0 .4525 |
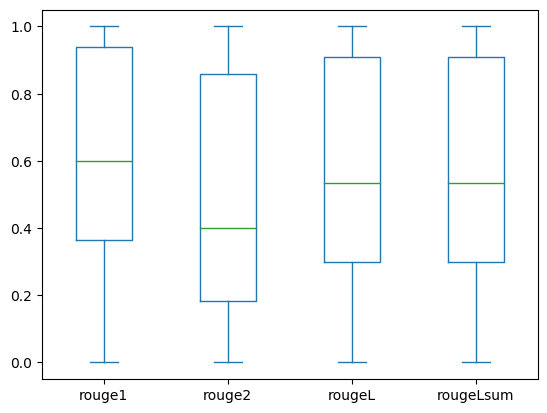
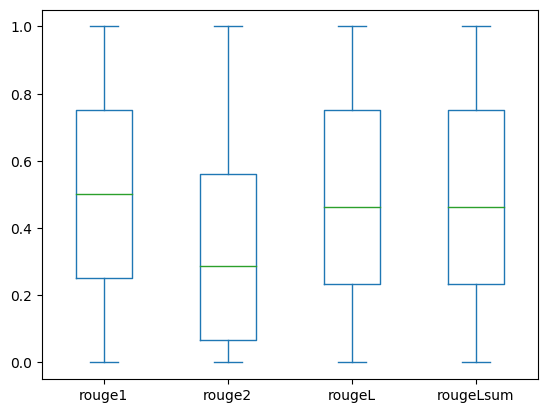
I seguenti box plot rappresentano la distribuzione dei punteggi ROUGE per i dataset dev1 e dev2 valutati utilizzando il modello fine-tuned.
 |
 |
(a): dev1 |
(b): dev2 |
La seguente tabella mostra che i punteggi ROUGE per i dataset di valutazione hanno approssimativamente la stessa mediana e media e quindi sono distribuiti simmetricamente.
| Dataset | Punteggi | Conteggio | Media | Deviazione standard | Minimo | 25° percentile | 50° percentile | 75° percentile | Massimo |
dev1 |
ROUGE1 | 2000.00 | 0.6038 | 0.3065 | 0.0000 | 0.3653 | 0.6000 | 0.9384 | 1.0000 |
| ROUGE 2 | 2000.00 | 0.4798 | 0.3578 | 0.0000 | 0.1818 | 0.4000 | 0.8571 | 1.0000 | |
| ROUGE L | 2000.00 | 0.5706 | 0.3194 | 0.0000 | 0.3000 | 0.5345 | 0.9101 | 1.0000 | |
| ROUGELsum | 2000.00 | 0.5706 | 0.3194 | 0.0000 | 0.3000 | 0.5345 | 0.9101 | 1.0000 | |
dev2 |
ROUGE 1 | 2000.00 | 0.4659 | 0.2525 | 0.0000 | 0.2500 | 0.5000 | 0.7500 | 1.0000 |
| ROUGE 2 | 2000.00 | 0.3123 | 0.2645 | 0.0000 | 0.0664 | 0.2857 | 0.5610 | 1.0000 | |
| ROUGE L | 2000.00 | 0.4529 | 0.2554 | 0.0000 | 0.2349 | 0.4615 | 0.7500 | 1.0000 | |






