Immergendosi nella piscina Svelando la magia del livello di pooling di CNN
Immergendosi nella piscina Rivelando la magia del max pooling di CNN
Motivazione
Le layer di pooling sono comuni nelle architetture CNN utilizzate in tutti i modelli di deep learning all’avanguardia. Sono diffuse nei compiti di visione artificiale, compresi la classificazione, la segmentazione, il rilevamento degli oggetti, gli autoencoder e molti altri, semplicemente utilizzati ovunque ci siano layer di convoluzione.
In questo articolo, approfondiremo la matematica che rende funzionanti i layer di pooling e impareremo quando utilizzare diversi tipi. Scopriremo anche cosa rende ogni tipo speciale e come si differenziano gli uni dagli altri.
- Synapse CoR ChatGPT con una rivoluzione intrigante
- Un’analisi comparativa dei primi 10 strumenti open source di data science nel 2023
- Introduzione al Cloud Computing per la Data Science
Perché utilizzare i layer di Pooling
I layer di pooling offrono vari benefici che li rendono una scelta comune per le architetture CNN. Svolgono un ruolo fondamentale nella gestione delle dimensioni spaziali e consentono ai modelli di apprendere diverse caratteristiche dall’insieme di dati.
Ecco alcuni benefici nell’utilizzare i layer di pooling nei tuoi modelli:
- Riduzione della dimensionalità
Tutte le operazioni di pooling selezionano un sottocampionamento dei valori da una griglia di output convoluzionale completa. Questo riduce la dimensione degli output con una conseguente riduzione dei parametri e del calcolo per i layer successivi, che è un beneficio vitale delle architetture convoluzionali rispetto ai modelli completamente connessi.
- Invarianza rispetto alla traduzione
I layer di pooling rendono i modelli di apprendimento automatico invariati rispetto a piccoli cambiamenti nell’input come rotazioni, traslazioni o aumenti. Ciò rende il modello adatto per compiti di base di visione artificiale, consentendo di identificare schemi di immagini simili.
Adesso, vediamo i vari metodi di pooling comunemente utilizzati nella pratica.
Esempio comune
Per facilitare il confronto, utilizziamo una semplice matrice bidimensionale e applichiamo diverse tecniche con gli stessi parametri.
I layer di pooling ereditano la stessa terminologia dei layer convoluzionali, e si conserva il concetto di dimensione del kernel, passo e padding.
Quindi, definiamo una matrice 2D con quattro righe e quattro colonne. Per utilizzare il pooling, useremo una dimensione del kernel di due e un passo di due senza padding. La nostra matrice avrà il seguente aspetto.
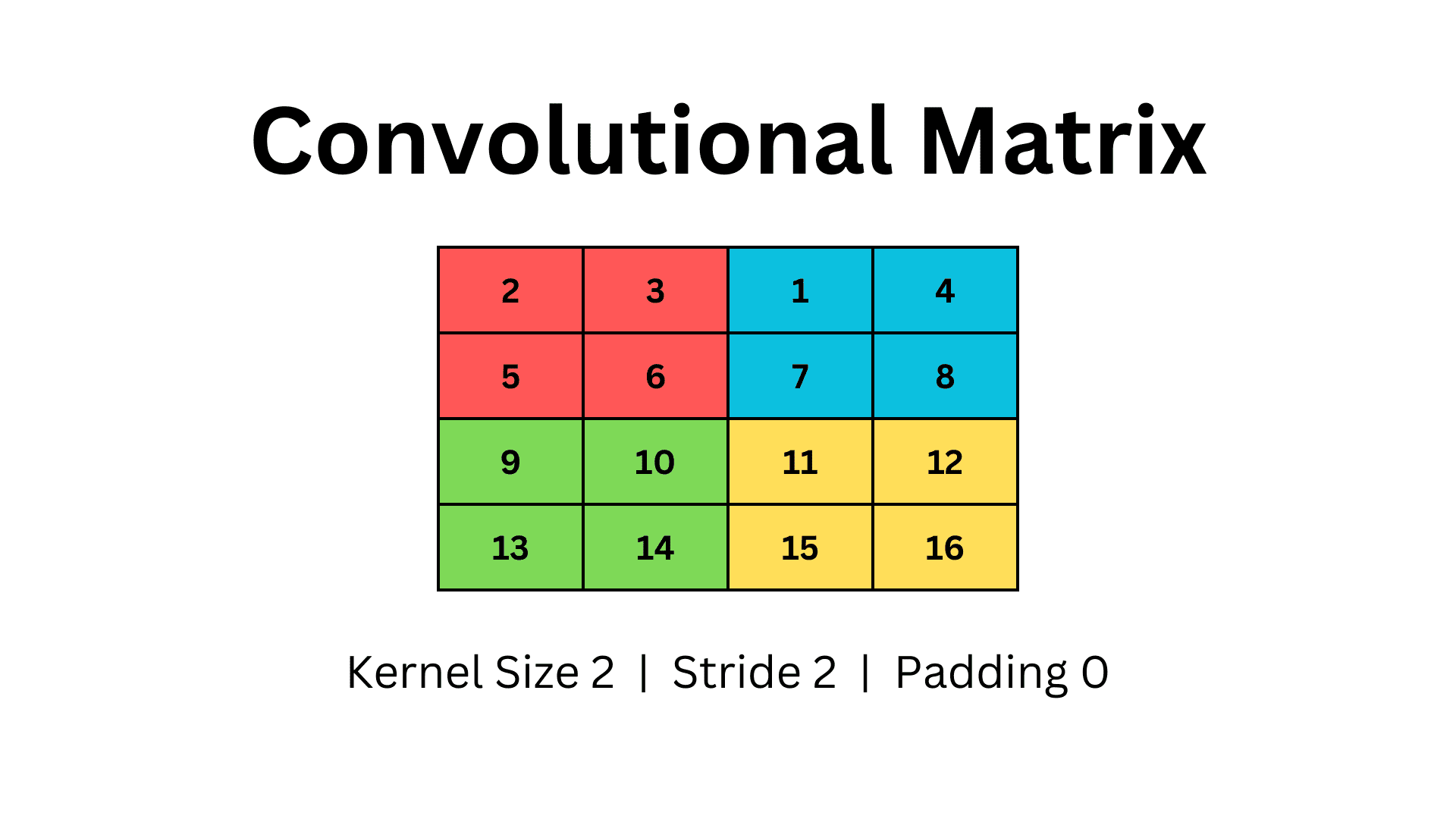
È importante notare che il pooling viene applicato per canale. Quindi, le stesse operazioni di pooling vengono ripetute per ogni canale in una mappa di caratteristiche. Il numero di canali rimane invariato, anche se la mappa delle caratteristiche di input viene sottocampionata.
Max Pooling
<p.Iteriamo il kernel sulla matrice e selezioniamo il valore massimo da ogni finestra. Nell'esempio precedente, utilizziamo un kernel 2×2 con passo due e iteriamo la matrice formando quattro finestre diverse, indicate con colori diversi.
Nel Max Pooling, conserviamo solo il valore più grande di ogni finestra. Questo riduce la dimensione della matrice e otteniamo una griglia più piccola 2×2 come output del max pooling.

Benefici del Max Pooling
- Preservazione dei valori di attivazione elevati
Quando viene applicato agli output di attivazione di un layer convoluzionale, stiamo effettivamente catturando solo i valori di attivazione più elevati. È utile in compiti in cui sono essenziali attivazioni più elevate, come il rilevamento degli oggetti. Effettivamente, stiamo sottocampionando la nostra matrice, ma possiamo ancora preservare le informazioni critiche nei nostri dati.
- Mantenimento delle caratteristiche dominanti
I valori massimi spesso indicano le caratteristiche importanti dei nostri dati. Quando manteniamo tali valori, conserviamo le informazioni che il modello considera importanti.
- Resistenza al rumore
Dato che basiamo la nostra decisione su un singolo valore in una finestra, piccole variazioni in altri valori possono essere ignorate, rendendola più robusta al rumore.
Svantaggi
- Possibile perdita di informazioni
Basare la nostra decisione sul valore massimale ignora gli altri valori di attivazione nella finestra. Ignorando tali informazioni, si può perdere informazione preziosa, irrecuperabile nei layer successivi.
- Insensibile ai piccoli spostamenti
Nel Max Pooling, le piccole variazioni nei valori non massimali verranno ignorate. Questa insensibilità ai piccoli cambiamenti può essere problematica e può influenzare i risultati.
- Sensibile all’alto rumore
Anche se piccole variazioni nei valori verranno ignorate, un alto rumore o errori in un singolo valore di attivazione possono portare alla selezione di un valore anomalo. Questo può alterare significativamente il risultato del max pooling, causando un degrado dei risultati.
Average Pooling
Nell’average pooling, iteriamo in modo simile su finestre. Tuttavia, consideriamo tutti i valori nella finestra, ne facciamo la media e lo usiamo come risultato.

Vantaggi dell’Average Pooling
- Conservazione dell’informazione spaziale
In teoria, conserviamo un po’ di informazione da tutti i valori nella finestra, per catturare la tendenza centrale dei valori di attivazione. In effetti, perdiamo meno informazioni e possiamo preservare più informazioni spaziali dai valori di attivazione convoluzionali.
- Robustezza agli Outlier
La media di tutti i valori rende questo metodo più robusto agli outlier rispetto al Max Pooling, poiché un singolo valore estremo non può alterare significativamente i risultati del layer di pooling.
- Transizioni più fluide
Prendendo la media dei valori, otteniamo transizioni meno marcate tra le nostre uscite. Questo fornisce una rappresentazione generalizzata dei nostri dati, consentendo un contrasto ridotto tra i layer successivi.
Svantaggi
- Incapacità di catturare caratteristiche salienti
Tutti i valori in una finestra vengono trattati allo stesso modo quando il layer di Average Pooling viene applicato. Questo non riesce a catturare le caratteristiche dominanti di un layer convoluzionale, il che può essere problematico per alcuni domini di problemi.
- Ridotta discriminazione tra feature maps
Quando tutti i valori vengono mediati, possiamo catturare solo le caratteristiche comuni tra regioni. Di conseguenza, possiamo perdere le distinzioni tra determinate caratteristiche e pattern di un’immagine, il che è sicuramente un problema per compiti come la rilevazione degli oggetti.
Global Average Pooling
Il Global Pooling è diverso dai normali layer di pooling. Non ha concetti di finestre, dimensione del kernel o passo. Consideriamo la matrice completa come un’unica entità e consideriamo tutti i valori nella griglia. Nel contesto dell’esempio sopra, prendiamo la media di tutti i valori nella matrice 4×4 e otteniamo un singolo valore come risultato.

Quando usarlo
Il Global Average Pooling permette di creare architetture di reti neurali convoluzionali semplici e robuste. Con l’uso del Global Pooling, possiamo implementare modelli generalizzabili, applicabili a immagini di qualsiasi dimensione. I layer di Global Pooling vengono utilizzati direttamente prima dei layer densi.
I layer convoluzionali riducono la dimensione di ogni immagine, a seconda delle iterazioni del kernel e dei passi. Tuttavia, applicare le stesse convoluzioni a immagini di dimensioni diverse genererà output di forme diverse. Tutte le immagini vengono ridotte in proporzione, quindi le immagini più grandi avranno output di dimensioni maggiori. Questo può causare problemi quando vengono passate ai layer densi per la classificazione, poiché le discrepanze di dimensione possono causare eccezioni durante l’esecuzione.
Senza modifiche negli iperparametri o nell’architettura del modello, implementare un modello applicabile a tutte le forme di immagine può essere difficile. Questo problema viene mitigato utilizzando il Global Average Pooling.
Quando il Global Pooling viene applicato prima dei layer densi, tutte le dimensioni di input verranno ridotte ad una dimensione 1×1. Quindi, un input di dimensioni (5,5) o (50,50) verrà ridotto a dimensione 1×1. Possono quindi essere appiattiti ed inviati ai layer densi senza preoccuparsi delle discrepanze di dimensione.
Punti principali
Abbiamo coperto alcuni metodi fondamentali di pooling e gli scenari in cui ciascuno è applicabile. È fondamentale scegliere quello adatto alle nostre specifiche attività.
È essenziale chiarire che non sono presenti parametri apprendibili nei livelli di pooling. Sono semplicemente finestre scorrevoli che eseguono operazioni matematiche di base. I livelli di pooling non sono addestrabili, ma potenziano notevolmente le architetture CNN consentendo una computazione più veloce e una maggiore robustezza nell’apprendimento delle caratteristiche di input. Muhammad Arham è un ingegnere di Deep Learning che lavora in Visione Artificiale e Elaborazione del Linguaggio Naturale. Ha lavorato sullo sviluppo e l’ottimizzazione di diverse applicazioni AI generative che hanno raggiunto le vette internazionali presso Vyro.AI. È interessato alla costruzione e all’ottimizzazione di modelli di apprendimento automatico per sistemi intelligenti e crede nel miglioramento continuo.






