Spiegare le decisioni mediche in contesti clinici utilizzando Amazon SageMaker Clarify
Explaining medical decisions in clinical contexts using Amazon SageMaker Clarify
La spiegabilità dei modelli di apprendimento automatico (ML) utilizzati nel settore medico sta diventando sempre più importante perché i modelli devono essere spiegati da diverse prospettive al fine di essere adottati. Queste prospettive vanno dalla prospettiva medica, tecnologica, legale e la prospettiva più importante: quella del paziente. I modelli sviluppati sul testo nel campo medico sono diventati accurati statisticamente, ma i clinici sono eticamente tenuti a valutare gli aspetti deboli legati a queste previsioni al fine di fornire la migliore cura per i singoli pazienti. La spiegabilità di queste previsioni è necessaria affinché i clinici possano prendere le scelte corrette caso per caso.
In questo post, mostriamo come migliorare la spiegabilità del modello in contesti clinici utilizzando Amazon SageMaker Clarify.
Contesto
Una specifica applicazione degli algoritmi di ML nel campo medico, che utilizza grandi quantità di testo, sono i sistemi di supporto decisionale clinico (CDSS) per il triage. Ogni giorno, i pazienti vengono ammessi negli ospedali e vengono presi appunti di ammissione. Dopo che questi appunti sono presi, viene avviato il processo di triage e i modelli di ML possono assistere i clinici nell’effettuare stime sugli esiti clinici. Questo può aiutare a ridurre i costi operativi e fornire la migliore cura per i pazienti. Comprendere perché questi modelli di ML suggeriscono determinate decisioni è estremamente importante per la presa di decisioni legate ai singoli pazienti.
Lo scopo di questo post è illustrare come è possibile distribuire modelli di previsione con Amazon SageMaker per scopi di triage all’interno delle strutture ospedaliere e utilizzare SageMaker Clarify per spiegare queste previsioni. L’intento è offrire un percorso accelerato per l’adozione delle tecniche di previsione all’interno dei CDSS per molte organizzazioni sanitarie.
- Questo articolo sull’IA introduce un dataset RDF completo con oltre 26 miliardi di triple che coprono dati accademici in tutte le discipline scientifiche.
- Stanco del tuo ruolo di Ingegnere dei Dati?
- Informazione ed Entropia
Il notebook e il codice di questo post sono disponibili su GitHub. Per eseguirlo, clonare il repository GitHub e aprire il file del notebook Jupyter.
Contesto tecnico
Un grande asset per qualsiasi organizzazione sanitaria acuta sono le note cliniche. All’atto dell’ingresso in ospedale, vengono prese le note di ammissione. Diversi studi recenti hanno dimostrato la prevedibilità di indicatori chiave come diagnosi, procedure, durata del ricovero e mortalità in ospedale. Le previsioni di questi indicatori sono ora altamente realizzabili solo dalle note di ammissione, attraverso l’uso di algoritmi di elaborazione del linguaggio naturale (NLP) [1].
I progressi nei modelli di NLP, come le rappresentazioni bidirezionali degli encoder dalle trasformazioni (BERT), hanno consentito previsioni altamente accurate su un corpus di testo, come le note di ammissione, che in precedenza era difficile ottenere valore. La loro previsione degli indicatori clinici è altamente applicabile per l’uso in un CDSS.
Tuttavia, per utilizzare efficacemente le nuove previsioni, è ancora necessario spiegare come i modelli accurati di BERT raggiungono le loro previsioni. Ci sono diverse tecniche per spiegare le previsioni di tali modelli. Una di queste tecniche è SHAP (SHapley Additive exPlanations), che è una tecnica indipendente dal modello per spiegare l’output dei modelli di ML.
Cosa è SHAP
I valori SHAP sono una tecnica per spiegare l’output dei modelli di ML. Fornisce un modo per scomporre la previsione di un modello di ML e capire quanto contribuisce ciascuna caratteristica di input alla previsione finale.
I valori SHAP si basano sulla teoria dei giochi, in particolare sul concetto di valori di Shapley, proposto originariamente per allocare il pagamento di un gioco cooperativo tra i suoi giocatori [2]. Nel contesto dell’ML, ogni caratteristica nello spazio di input è considerata un giocatore in un gioco cooperativo e la previsione del modello è il pagamento. I valori SHAP vengono calcolati esaminando il contributo di ciascuna caratteristica alla previsione del modello per ogni possibile combinazione di caratteristiche. Si calcola quindi la media del contributo di ciascuna caratteristica su tutte le possibili combinazioni di caratteristiche e questo diventa il valore SHAP per quella caratteristica.
SHAP consente ai modelli di spiegare le previsioni senza comprendere il funzionamento interno del modello. Inoltre, ci sono tecniche per visualizzare queste spiegazioni SHAP nel testo, in modo che la prospettiva medica e quella del paziente possano avere una visibilità intuitiva su come gli algoritmi arrivano alle loro previsioni.
Con le nuove aggiunte a SageMaker Clarify e l’uso di modelli pre-addestrati di Hugging Face che possono essere facilmente implementati in SageMaker, l’addestramento del modello e la spiegabilità possono essere facilmente realizzati in AWS.
A scopo di esempio end-to-end, prendiamo l’esito clinico della mortalità in ospedale e mostriamo come questo processo può essere facilmente implementato in AWS utilizzando un modello BERT pre-addestrato di Hugging Face e le previsioni saranno spiegate utilizzando SageMaker Clarify.
Scelte del modello Hugging Face
Hugging Face offre una varietà di modelli BERT pre-addestrati che sono stati specializzati per l’uso nelle note cliniche. Per questo post, utilizziamo il modello bigbird-base-mimic-mortality. Questo modello è una versione ottimizzata del modello BigBird di Google, appositamente adattato per prevedere la mortalità utilizzando le note di ammissione ICU di MIMIC. Il compito del modello è determinare la probabilità che un paziente non sopravviva a un particolare soggiorno in ICU basandosi sulle note di ammissione. Uno dei vantaggi significativi nell’utilizzare questo modello BigBird è la sua capacità di elaborare lunghezze di contesto più ampie, il che significa che possiamo inserire le note di ammissione complete senza la necessità di troncamento.
I nostri passaggi prevedono il deploy di questo modello ottimizzato su SageMaker. Successivamente, incorporiamo questo modello in un ambiente che consente una spiegazione in tempo reale delle sue previsioni. Per raggiungere questo livello di spiegabilità, utilizziamo SageMaker Clarify.
Panoramica della soluzione
SageMaker Clarify fornisce agli sviluppatori di ML strumenti appositamente progettati per ottenere una maggiore comprensione dei dati di addestramento e dei modelli di ML. SageMaker Clarify spiega sia le previsioni globali che locali e spiega le decisioni prese dai modelli di computer visione (CV) e NLP.
Il diagramma seguente mostra l’architettura di SageMaker per l’hosting di un endpoint che serve le richieste di spiegazione. Include le interazioni tra un endpoint, il contenitore del modello e l’esploratore di SageMaker Clarify.
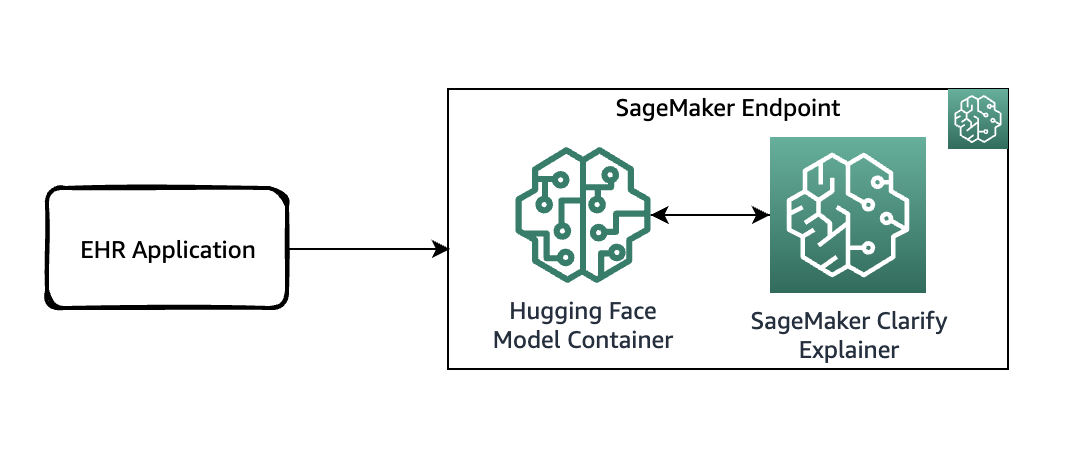
Nel codice di esempio, utilizziamo un notebook Jupyter per mostrare la funzionalità. Tuttavia, in un caso d’uso del mondo reale, i record sanitari elettronici (EHR) o altre applicazioni di cure ospedaliere invocherebbero direttamente l’endpoint di SageMaker per ottenere la stessa risposta. Nel notebook Jupyter, effettuiamo il deploy di un contenitore del modello Hugging Face su un endpoint di SageMaker. Successivamente, utilizziamo SageMaker Clarify per spiegare i risultati ottenuti dal modello deployato.
Prerequisiti
Hai bisogno dei seguenti prerequisiti:
- Un account AWS
- Un’istanza di notebook SageMaker
Accedi al codice dal repository GitHub e caricalo nella tua istanza di notebook. Puoi anche eseguire il notebook in un ambiente di Amazon SageMaker Studio, che è un ambiente di sviluppo integrato (IDE) per lo sviluppo di ML. Consigliamo di utilizzare un kernel Python 3 (Data Science) su SageMaker Studio o un kernel conda_python3 su un’istanza di notebook SageMaker.
Deploy del modello abilitato per SageMaker Clarify
Come primo passaggio, scarica il modello da Hugging Face e caricalo in un bucket Amazon Simple Storage Service (Amazon S3). Quindi crea un oggetto modello utilizzando la classe HuggingFaceModel. Questo utilizza un contenitore predefinito per semplificare il processo di deploy dei modelli Hugging Face su SageMaker. Utilizziamo anche uno script di inferenza personalizzato per effettuare le previsioni all’interno del contenitore. Il codice seguente illustra lo script che viene passato come argomento alla classe HuggingFaceModel:
from sagemaker.huggingface import HuggingFaceModel
# crea la classe del modello Hugging Face
huggingface_model = HuggingFaceModel(
model_data = model_path_s3,
transformers_version='4.6.1',
pytorch_version='1.7.1',
py_version='py36',
role=role,
source_dir = "./{}/code".format(model_id),
entry_point = "inference.py"
)Poi puoi definire il tipo di istanza su cui distribuire questo modello:
instance_type = "ml.g4dn.xlarge"
container_def = huggingface_model.prepare_container_def(instance_type=instance_type)
container_defSuccessivamente popoliamo i campi ExecutionRoleArn, ModelName e PrimaryContainer per creare un Modello.
model_name = "modello-di-triage-ospedaliero"
sagemaker_client.create_model(
ExecutionRoleArn=role,
ModelName=model_name,
PrimaryContainer=container_def,
)
print(f"Modello creato: {model_name}")Successivamente, crea una configurazione dell’endpoint chiamando l’API create_endpoint_config. Qui, fornisci lo stesso model_name utilizzato nella chiamata API create_model. La chiamata API create_endpoint_config supporta ora il parametro aggiuntivo ClarifyExplainerConfig per abilitare l’esploratore di SageMaker Clarify. La baseline SHAP è obbligatoria; puoi fornirla sia come dati di baseline in linea (il parametro ShapBaseline) che tramite un file di baseline S3 (il parametro ShapBaselineUri). Per i parametri opzionali, consulta la guida per gli sviluppatori.
Nel codice seguente, utilizziamo un token speciale come baseline:
baseline = [["<UNK>"]]
print(f"Baseline SHAP: {baseline}")La TextConfig è configurata con una granularità a livello di frase (ogni frase è una caratteristica e abbiamo bisogno di alcune frasi per recensione per una buona visualizzazione) e la lingua è l’inglese:
endpoint_config_name = "hospital-triage-model-ep-config"
csv_serializer = sagemaker.serializers.CSVSerializer()
json_deserializer = sagemaker.deserializers.JSONDeserializer()
sagemaker_client.create_endpoint_config(
EndpointConfigName=endpoint_config_name,
ProductionVariants=[
{
"VariantName": "MainVariant",
"ModelName": model_name,
"InitialInstanceCount": 1,
"InstanceType": instance_type,
}
],
ExplainerConfig={
"ClarifyExplainerConfig": {
"InferenceConfig": {"FeatureTypes": ["text"]},
"ShapConfig": {
"ShapBaselineConfig": {"ShapBaseline": csv_serializer.serialize(baseline)},
"TextConfig": {"Granularity": "sentence", "Language": "en"},
},
}
},
)Infine, dopo aver preparato il modello e la configurazione del punto di accesso, utilizzare l’API create_endpoint per creare il punto di accesso. Il parametro endpoint_name deve essere univoco all’interno di una regione nel tuo account AWS. L’API create_endpoint è sincrona per natura e restituisce una risposta immediata con lo stato del punto di accesso in fase di creazione.
endpoint_name = "hospital-triage-prediction-endpoint"
sagemaker_client.create_endpoint(
EndpointName=endpoint_name,
EndpointConfigName=endpoint_config_name,
)Spiega la previsione
Ora che hai distribuito il punto di accesso con l’abilitazione all’esplicabilità online, puoi provare alcuni esempi. Puoi invocare il punto di accesso in tempo reale utilizzando il metodo invoke_endpoint fornendo il payload serializzato, che in questo caso sono alcune note di ammissione di esempio:
response = sagemaker_runtime_client.invoke_endpoint(
EndpointName=endpoint_name,
ContentType="text/csv",
Accept="text/csv",
Body=csv_serializer.serialize(sample_admission_note.iloc[:1, :].to_numpy())
)
result = json_deserializer.deserialize(response["Body"], content_type=response["ContentType"])
pprint.pprint(result)Nel primo scenario, supponiamo che la seguente nota di ammissione medica sia stata presa da un operatore sanitario:
“Il paziente è un uomo di 25 anni con un dolore toracico acuto come sintomo principale. Il paziente riferisce che il dolore è iniziato improvvisamente mentre era al lavoro ed è costante da allora. Il paziente valuta il dolore come 8/10 in termini di gravità. Il paziente nega la presenza di irradiazione del dolore, dispnea, nausea o vomito. Il paziente non ha precedenti episodi di dolore toracico. I segni vitali sono i seguenti: pressione arteriosa 140/90 mmH. Frequenza cardiaca 92 battiti al minuto. Frequenza respiratoria 18 respiri al minuto. Saturazione di ossigeno 96% in aria ambiente. All'esame obiettivo si riscontra una leggera dolenzia alla palpazione del precordio e polmoni chiari. L'ECG mostra una tachicardia sinusale senza elevazioni o depressioni del tratto ST.”La seguente immagine mostra i risultati del modello.

Dopo aver inoltrato tutto ciò al punto di accesso di SageMaker, l’etichetta è stata prevista come 0, il che indica che il rischio di mortalità è basso. In altre parole, 0 significa che il paziente ricoverato è in condizioni non acute secondo il modello. Tuttavia, abbiamo bisogno della motivazione dietro quella previsione. Per questo, puoi utilizzare i valori SHAP come risposta. La risposta include i valori SHAP corrispondenti alle frasi della nota di input, che possono essere ulteriormente colorate in verde o rosso in base al contributo dei valori SHAP alla previsione. In questo caso, vediamo più frasi in verde, come “Il paziente nega la presenza di precedenti episodi di dolore toracico” e “L’ECG mostra una tachicardia sinusale senza elevazioni o depressioni del tratto ST”, rispetto a quelle rosse, in linea con la previsione di mortalità pari a 0.
Nel secondo scenario, supponiamo che la seguente nota di ammissione medica sia stata presa da un operatore sanitario:
“La paziente è una donna di 72 anni con grave sepsi e shock settico come sintomi principali. La paziente riferisce febbre, brividi e debolezza negli ultimi 3 giorni, oltre a diminuzione della diuresi e confusione. La paziente ha una storia di broncopneumopatia cronica ostruttiva (BPCO) e una recente ospedalizzazione per polmonite. I segni vitali sono i seguenti: pressione arteriosa 80/40 mmHg. Frequenza cardiaca 130 battiti al minuto. Frequenza respiratoria 30 respiri al minuto. Saturazione di ossigeno 82% con 4L di ossigeno tramite cannula nasale. All'esame obiettivo si riscontra eritema diffuso e calore agli arti inferiori e risultati positivi per la sepsi come stato mentale alterato, tachicardia e tachipnea. Sono stati effettuati prelievi ematici per le colture e si è iniziata la terapia antibiotica con la copertura appropriata.”La seguente immagine mostra i nostri risultati.
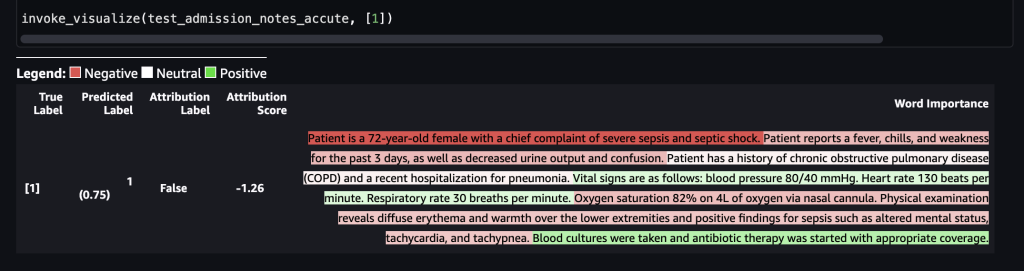
Dopo che ciò è stato inviato al punto finale di SageMaker, l’etichetta è stata prevista come 1, il che indica che il rischio di mortalità è elevato. Ciò implica che il paziente ammesso si trova in condizioni acute secondo il modello. Tuttavia, abbiamo bisogno della motivazione dietro tale previsione. Di nuovo, è possibile utilizzare i valori SHAP come risposta. La risposta include i valori SHAP corrispondenti alle frasi della nota di input, che possono essere ulteriormente colorate a codice. In questo caso, vediamo più frasi in rosso, come “Il paziente riferisce febbre, brividi e debolezza negli ultimi 3 giorni, oltre a una diminuzione della produzione di urina e confusione” e “Il paziente è una donna di 72 anni con una lamentela principale di shock settico grave”, rispetto al verde, allineandosi con la previsione di mortalità di 1.
Il team di assistenza clinica può utilizzare queste spiegazioni per assistere nelle decisioni sul processo di cura per ogni singolo paziente.
Pulizia
Per pulire le risorse che sono state create come parte di questa soluzione, eseguire le seguenti istruzioni:
huggingface_model.delete_model()
predictor = sagemaker.Predictor(endpoint_name="triage-prediction-endpoint")
predictor.delete_endpoint()Conclusioni
Questo post ti ha mostrato come utilizzare SageMaker Clarify per spiegare le decisioni in un caso di utilizzo sanitario basato sulle note mediche acquisite durante varie fasi del processo di triage. Questa soluzione può essere integrata nei sistemi di supporto decisionale esistenti per fornire un altro punto dati ai clinici mentre valutano i pazienti per l’ammissione in terapia intensiva. Per saperne di più sull’utilizzo dei servizi AWS nell’industria sanitaria, consulta i seguenti articoli del blog:
- Introduzione alla lente per l’industria sanitaria per il framework AWS Well-Architected
- Come Telescope Health semplifica l’assistenza virtuale nel cloud
- Il percorso verso una migliore assistenza chirurgica con analisi della sala operatoria su AWS
- Previsione del ricovero dei pazienti diabetici mediante addestramento multi-modello su Amazon SageMaker Pipelines
- Come Pieces Technologies sfrutta i servizi AWS per prevedere gli esiti dei pazienti
Riferimenti
[1] https://aclanthology.org/2021.eacl-main.75/
[2] https://arxiv.org/pdf/1705.07874.pdf






