Applica controlli di accesso ai dati dettagliati con AWS Lake Formation in Amazon SageMaker Data Wrangler
Applica controlli di accesso ai dati con AWS Lake Formation in Amazon SageMaker Data Wrangler
Amazon SageMaker Data Wrangler riduce il tempo necessario per raccogliere e preparare i dati per il machine learning (ML) da settimane a minuti. Puoi ottimizzare il processo di feature engineering e preparazione dei dati con SageMaker Data Wrangler e completare ogni fase del flusso di lavoro di preparazione dei dati (inclusa la selezione dei dati, la purificazione, l’esplorazione, la visualizzazione e l’elaborazione su larga scala) all’interno di un’unica interfaccia visuale. I dati vengono frequentemente conservati in data lake che possono essere gestiti da AWS Lake Formation, offrendoti la possibilità di implementare un controllo degli accessi dettagliato utilizzando una procedura di concessione o revoca semplice. SageMaker Data Wrangler supporta il controllo dettagliato degli accessi ai dati con Lake Formation e connessioni Amazon Athena.
Siamo lieti di annunciare che SageMaker Data Wrangler supporta ora l’utilizzo di Lake Formation con Amazon EMR per fornire questa restrizione dettagliata degli accessi ai dati.
I professionisti dei dati come i data scientist vogliono utilizzare la potenza di Apache Spark, Hive e Presto in esecuzione su Amazon EMR per una rapida preparazione dei dati; tuttavia, la curva di apprendimento è ripida. I nostri clienti desideravano la possibilità di connettersi ad Amazon EMR per eseguire query SQL ad hoc su Hive o Presto per interrogare i dati nel metastore interno o nel metastore esterno (come l’AWS Glue Data Catalog) e preparare i dati con pochi clic.
In questo post mostriamo come utilizzare Lake Formation come capacità centrale di governance dei dati e Amazon EMR come motore di query per big data per abilitare l’accesso a SageMaker Data Wrangler. Le funzionalità di Lake Formation semplificano la sicurezza e la gestione dei data lake distribuiti su più account attraverso un approccio centralizzato, fornendo un controllo dettagliato degli accessi.
- Spiegare le decisioni mediche in contesti clinici utilizzando Amazon SageMaker Clarify
- Questo articolo sull’IA introduce un dataset RDF completo con oltre 26 miliardi di triple che coprono dati accademici in tutte le discipline scientifiche.
- Stanco del tuo ruolo di Ingegnere dei Dati?
Panoramica della soluzione
Dimostriamo questa soluzione con un caso d’uso end-to-end utilizzando un set di dati di esempio, il modello di dati TPC. Questi dati rappresentano dati di transazione per prodotti e includono informazioni come demografia dei clienti, inventario, vendite web e promozioni. Per dimostrare le autorizzazioni di accesso ai dati dettagliate, consideriamo i seguenti due utenti:
- David, un data scientist nel team di marketing. È incaricato di costruire un modello sulla segmentazione dei clienti e ha il permesso di accedere solo ai dati non sensibili dei clienti.
- Tina, un data scientist nel team delle vendite. È incaricata di costruire il modello di previsione delle vendite e ha bisogno di accedere ai dati di vendita per la regione specifica. Sta anche aiutando il team dei prodotti con l’innovazione e quindi ha bisogno di accedere anche ai dati dei prodotti.
L’architettura è implementata come segue:
- Lake Formation gestisce il data lake e i dati grezzi sono disponibili in bucket Amazon Simple Storage Service (Amazon S3)
- Amazon EMR viene utilizzato per interrogare i dati dal data lake e eseguire la preparazione dei dati utilizzando Spark
- Vengono utilizzati ruoli IAM (Identity and Access Management) per gestire l’accesso ai dati utilizzando Lake Formation
- SageMaker Data Wrangler viene utilizzato come unica interfaccia visuale per interrogare e preparare interattivamente i dati
Il diagramma seguente illustra questa architettura. L’account A è l’account del data lake che ospita tutti i dati pronti per il ML ottenuti attraverso processi di estrazione, trasformazione e caricamento (ETL). L’account B è l’account della scienza dei dati in cui un gruppo di data scientist compilano ed eseguono trasformazioni dei dati utilizzando SageMaker Data Wrangler. Affinché SageMaker Data Wrangler nell’account B possa accedere alle tabelle dei dati nel data lake dell’account A tramite le autorizzazioni di Lake Formation, è necessario attivare i diritti necessari.
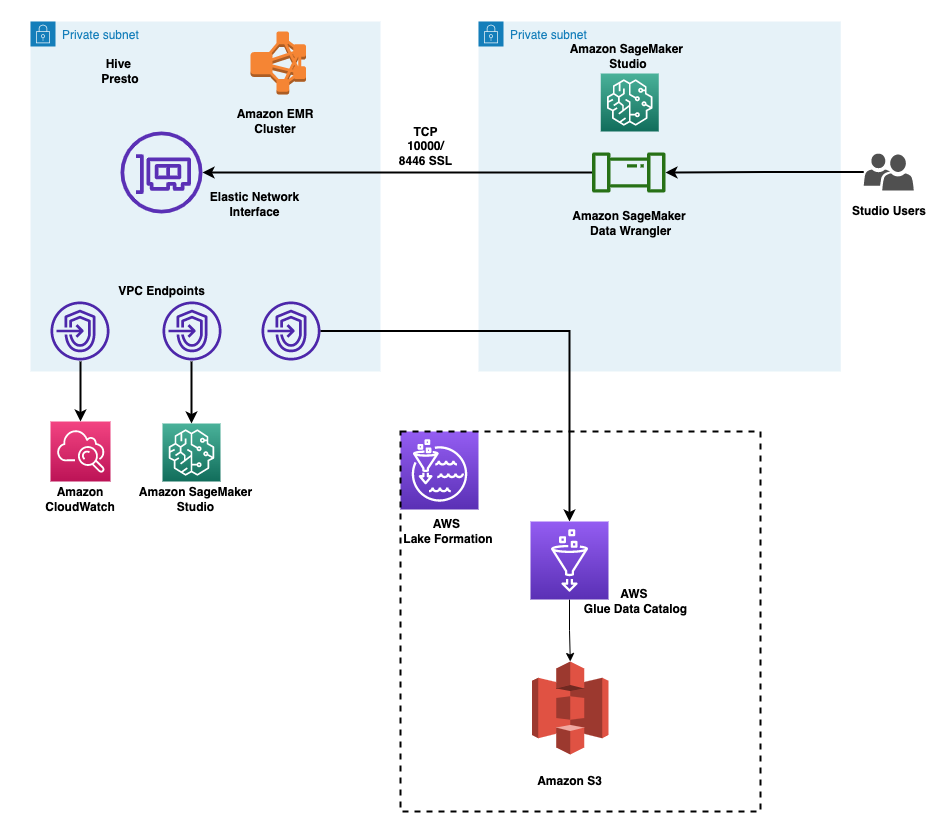
Puoi utilizzare lo stack AWS CloudFormation fornito per configurare i componenti architetturali per questa soluzione.
Prerequisiti
Prima di iniziare, assicurati di avere i seguenti prerequisiti:
- Un account AWS
- Un utente IAM con accesso amministrativo
- Un bucket S3
Provisione delle risorse con AWS CloudFormation
Forniamo un modello CloudFormation che distribuisce i servizi nell’architettura per i test end-to-end e per facilitare le distribuzioni ripetute. I risultati di questo modello sono i seguenti:
- Un bucket S3 per il data lake.
- Un cluster EMR con ruoli di runtime EMR abilitati. Per ulteriori dettagli sull’utilizzo dei ruoli di runtime con Amazon EMR, consulta “Configurazione dei ruoli di runtime per i passaggi di Amazon EMR”. L’associazione dei ruoli di runtime con i cluster EMR è supportata in Amazon EMR 6.9. Assicurati che la seguente configurazione sia in atto:
- Crea una configurazione di sicurezza in Amazon EMR.
- La politica di trust del ruolo di runtime EMR dovrebbe consentire all’istanza del profilo EC2 EMR di assumere il ruolo.
- Il ruolo del profilo EC2 EMR dovrebbe essere in grado di assumere i ruoli di runtime EMR.
- Il cluster EMR dovrebbe essere creato con la crittografia in transito.
- Ruoli IAM per l’accesso ai dati nel data lake, con autorizzazioni dettagliate:
- Ruolo di accesso ai dati di marketing
- Ruolo di accesso ai dati delle vendite
- Un dominio di Amazon SageMaker Studio e due profili utente. I ruoli di esecuzione di SageMaker Studio per gli utenti consentono agli utenti di assumere i rispettivi ruoli di runtime EMR.
- Una configurazione del ciclo di vita per abilitare la selezione del ruolo da utilizzare per la connessione EMR.
- Un database Lake Formation popolato con i dati TPC.
- Risorse di rete necessarie per la configurazione, come VPC, subnet e gruppi di sicurezza.
Creare certificati di crittografia Amazon EMR per i dati in transito
Con la versione di rilascio di Amazon EMR 4.8.0 o successiva, hai l’opzione di specificare gli artefatti per crittografare i dati in transito utilizzando una configurazione di sicurezza. Creiamo manualmente certificati PEM, li includiamo in un file .zip, lo carichiamo in un bucket S3 e quindi facciamo riferimento al file .zip in Amazon S3. Probabilmente desideri configurare il file PEM della chiave privata come certificato wildcart che consente l’accesso al dominio VPC in cui risiedono le istanze del cluster. Ad esempio, se il tuo cluster risiede nella regione us-east-1, potresti specificare un nome comune nella configurazione del certificato che consente l’accesso al cluster specificando CN=*.ec2.internal nella definizione del soggetto del certificato. Se il tuo cluster risiede in us-west-2, potresti specificare CN=*.us-west-2.compute.internal.
Esegui i seguenti comandi utilizzando il terminale del tuo sistema. Ciò genererà certificati PEM e li collegherà in un file .zip:
openssl req -x509 -newkey rsa:1024 -keyout privateKey.pem -out certificateChain.pem -days 365 -nodes -subj '/C=US/ST=Washington/L=Seattle/O=MyOrg/OU=MyDept/CN=*.us-east-2.compute.internal'
cp certificateChain.pem trustedCertificates.pem
zip -r -X my-certs.zip certificateChain.pem privateKey.pem trustedCertificates.pem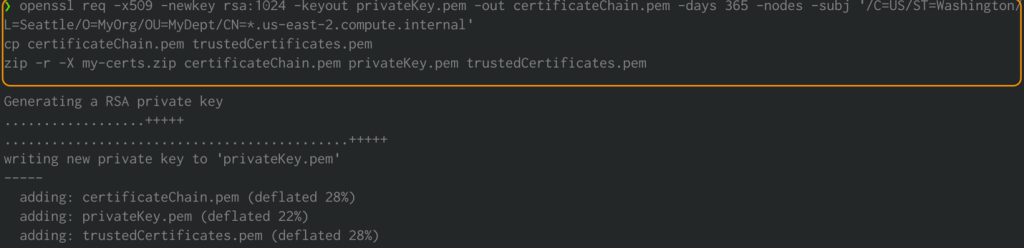
Carica il file my-certs.zip in un bucket S3 nella stessa regione in cui intendi eseguire questo esercizio. Copia l’URI S3 per il file caricato. Ne avrai bisogno durante il lancio del modello CloudFormation.
Questo esempio è solo una dimostrazione di prova di concetto. L’utilizzo di certificati auto-firmati non è consigliato e presenta un potenziale rischio per la sicurezza. Per i sistemi di produzione, utilizzare un’autorità di certificazione (CA) fidata per emettere i certificati.
Deploy del modello CloudFormation
Per eseguire la soluzione, completa i seguenti passaggi:
- Accedi alla Console di Gestione AWS come utente IAM, preferibilmente come utente amministratore.
- Scegli Lancia Stack per lanciare il modello CloudFormation:

- Scegli Avanti.
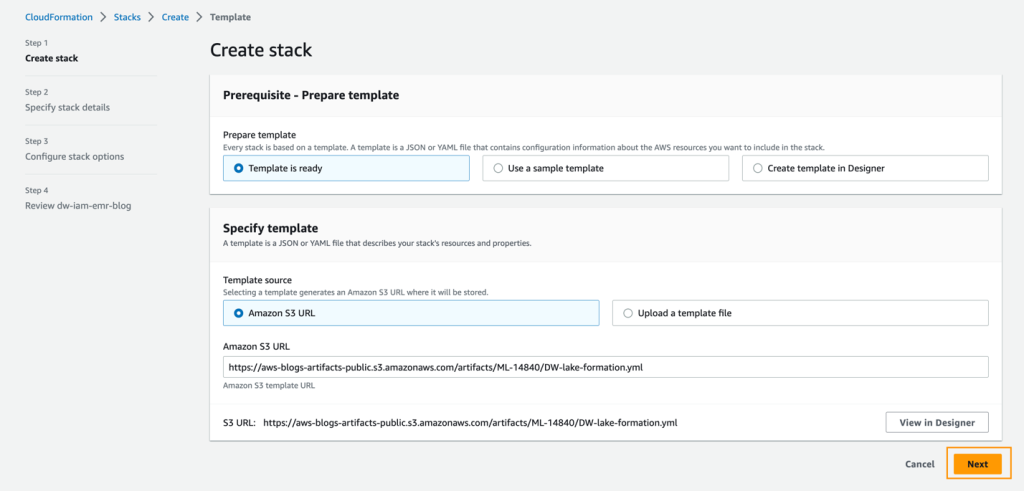
- Per Nome dello stack, inserisci un nome per lo stack.
- Per IdleTimeout, inserisci un valore per il timeout di inattività del cluster EMR (per evitare di pagare per il cluster quando non viene utilizzato).
- Per S3CertsZip, inserisci un URI S3 con la chiave di crittografia EMR.
Per istruzioni su come generare una chiave e un file .zip specifici per la tua regione, consulta la documentazione su Fornire certificati per la crittografia dei dati in transito con Amazon EMR. Se esegui il deployment in US East (N. Virginia), ricorda di utilizzare CN=*.ec2.internal. Per ulteriori informazioni, consulta Crea chiavi e certificati per la crittografia dei dati. Assicurati di caricare il file .zip in un bucket S3 nella stessa regione del deployment dello stack CloudFormation.
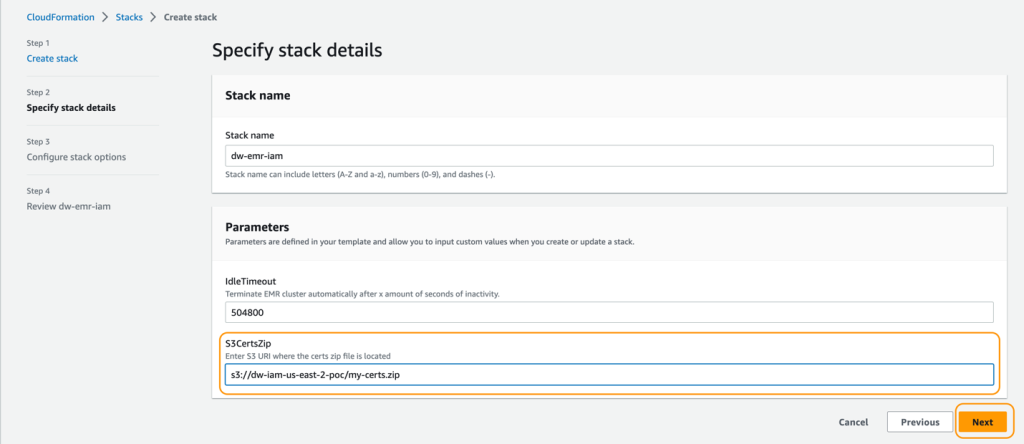
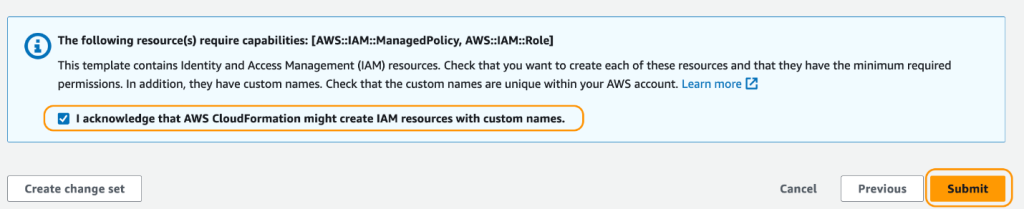
- Sulla pagina di riepilogo, selezionare la casella di controllo per confermare che AWS CloudFormation potrebbe creare risorse.
- Scegliere Crea stack.
Attendere fino a quando lo stato dello stack cambia da CREATE_IN_PROGRESS a CREATE_COMPLETE. Il processo di solito richiede da 10 a 15 minuti.
Dopo aver creato lo stack, consentire ad Amazon EMR di interrogare Lake Formation aggiornando le impostazioni di Filtraggio dati esterni su Lake Formation. Per istruzioni, fare riferimento a “Panoramica di Lake Formation”. Specificare Amazon EMR per i Valori dei tag di sessione e inserire l’ID dell’account AWS sotto ID account AWS.
Testare i permessi di accesso ai dati di test
Ora che l’infrastruttura necessaria è in atto, è possibile verificare che i due utenti di SageMaker Studio abbiano accesso a dati dettagliati. Per rivedere, David non dovrebbe avere accesso a informazioni private sui clienti. Tina ha accesso alle informazioni sulle vendite. Mettiamo alla prova ciascun tipo di utente.
Testare il profilo utente di David
Per testare l’accesso ai dati con il profilo utente di David, completare i seguenti passaggi:
- Nella console di SageMaker, scegliere Domini nel riquadro di navigazione.
- Dal dominio di SageMaker Studio, avviare SageMaker Studio dal profilo utente david-non-sensitive-customer.
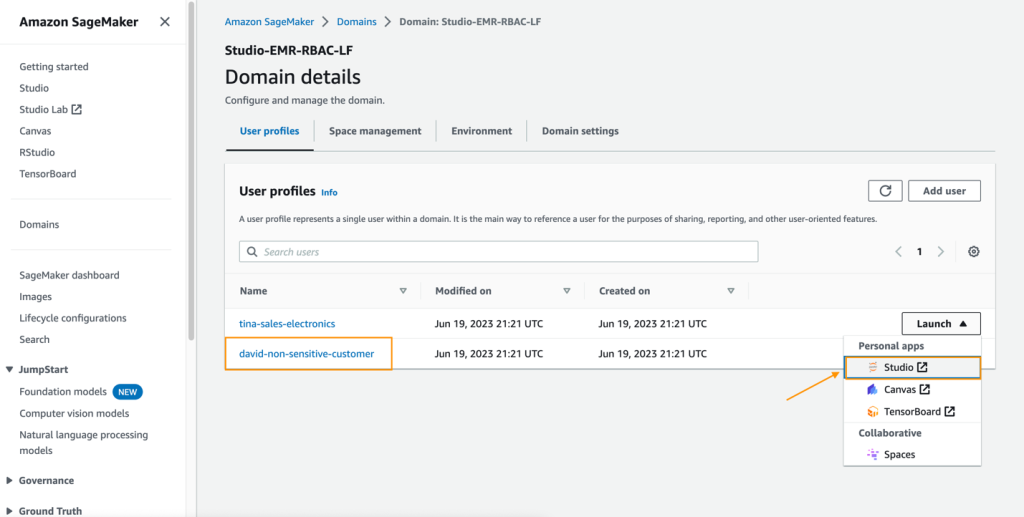
- Nel proprio ambiente di SageMaker Studio, creare un flusso di dati di Amazon SageMaker Data Wrangler e scegliere Importa e prepara i dati visivamente.
Alternativamente, nel menu File, scegliere Nuovo, quindi scegliere Flusso di Data Wrangler.
Discutiamo in dettaglio questi passaggi per creare un flusso di dati in un post successivo.
Testare il profilo utente di Tina
Il ruolo di esecuzione di SageMaker Studio di Tina le consente di accedere al database di Lake Formation utilizzando due ruoli di esecuzione di EMR. Questo viene realizzato elencando gli ARN dei ruoli in un file di configurazione nella directory dei file di Tina. Questi ruoli possono essere impostati utilizzando le configurazioni del ciclo di vita di SageMaker Studio per persistere i ruoli durante i riavvii dell’app. Per testare l’accesso di Tina, completare i seguenti passaggi:
- Nella console di SageMaker, passare al dominio di SageMaker Studio.
- Avviare SageMaker Studio dal profilo utente
tina-sales-electronics.
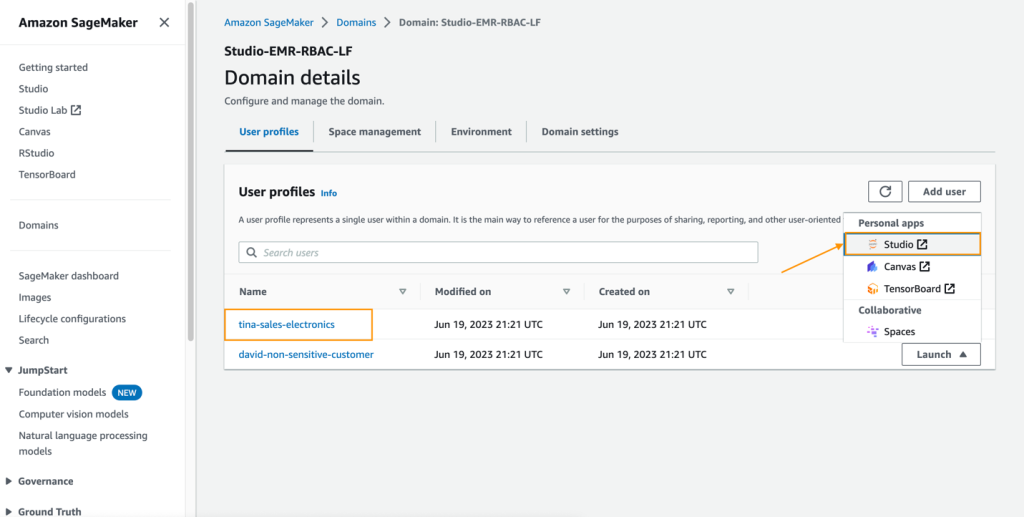
È buona pratica chiudere tutte le sessioni precedenti di SageMaker Studio nel proprio browser quando si passa da un profilo utente all’altro. Può esserci solo una sessione utente attiva di SageMaker Studio alla volta.
- Creare un flusso di dati di Data Wrangler.
Nelle sezioni seguenti, mostriamo come creare un flusso di dati all’interno di SageMaker Data Wrangler e connetterci ad Amazon EMR come origine dati. David e Tina avranno esperienze simili con la preparazione dei dati, ad eccezione dei permessi di accesso, quindi vedranno tabelle diverse.
Creare un flusso di dati di SageMaker Data Wrangler
In questa sezione, descriviamo come connettersi al cluster EMR esistente creato tramite il modello di CloudFormation come origine dati in SageMaker Data Wrangler. A scopo dimostrativo, utilizziamo il profilo utente di David.
Per creare il flusso di dati, completare i seguenti passaggi:
- Nella console di SageMaker, scegliere Domini nel riquadro di navigazione.
- Scegliere StudioDomain, creato eseguendo il modello di CloudFormation.
- Selezionare un profilo utente (per questo esempio, quello di David) e avviare SageMaker Studio.
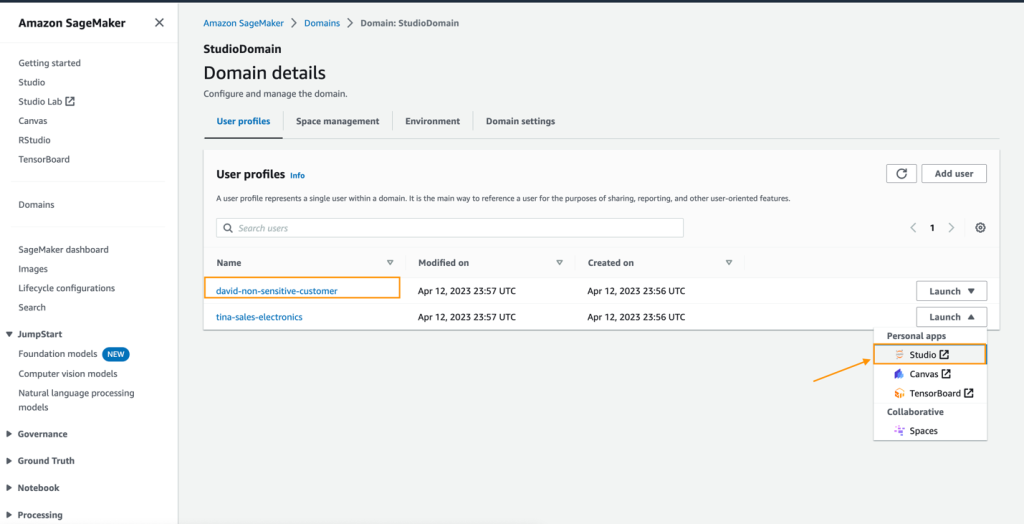
- Scegliere Open Studio.
- In SageMaker Studio, creare un nuovo flusso di dati e scegliere Importa e prepara i dati visualmente.
In alternativa, nel menu File, scegliere Nuovo, quindi scegliere Flusso Data Wrangler.
La creazione di un nuovo flusso può richiedere alcuni minuti. Dopo che il flusso è stato creato, vedrai la pagina Importa dati.
- Per aggiungere Amazon EMR come origine dati in SageMaker Data Wrangler, nel menu Aggiungi origine dati, scegliere Amazon EMR.

Puoi sfogliare tutti i cluster EMR a cui il ruolo di esecuzione di SageMaker Studio ha le autorizzazioni per visualizzarli. Hai due opzioni per connetterti a un cluster: una è tramite l’interfaccia utente interattiva e l’altra è creare prima un segreto utilizzando AWS Secrets Manager con un URL JDBC, inclusa l’informazione del cluster EMR, e quindi fornire l’ARN del segreto AWS archiviato nell’interfaccia utente per connettersi a Presto o Hive. In questo post, utilizziamo il primo metodo.
- Seleziona uno dei cluster che desideri utilizzare, quindi scegli Avanti.
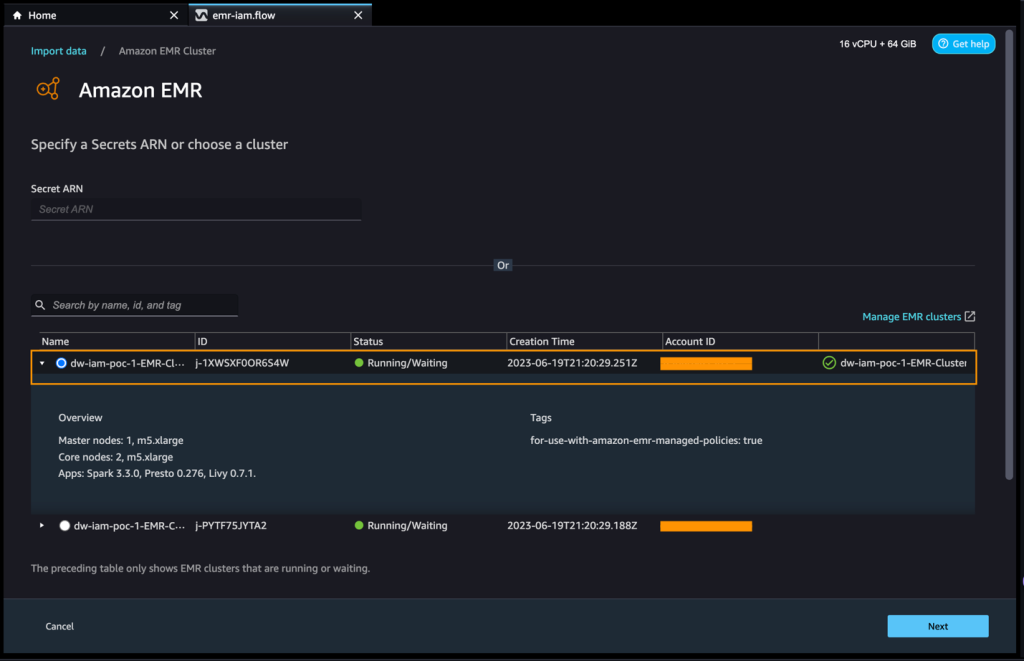
- Seleziona quale endpoint desideri utilizzare.
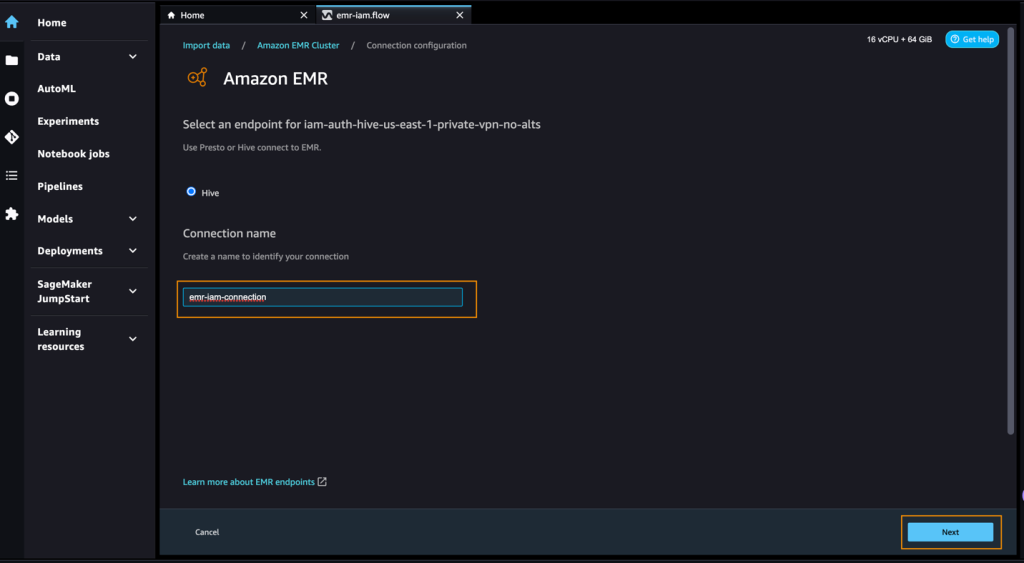
- Inserisci un nome per identificare la tua connessione, ad esempio
emr-iam-connection, quindi scegli Avanti.
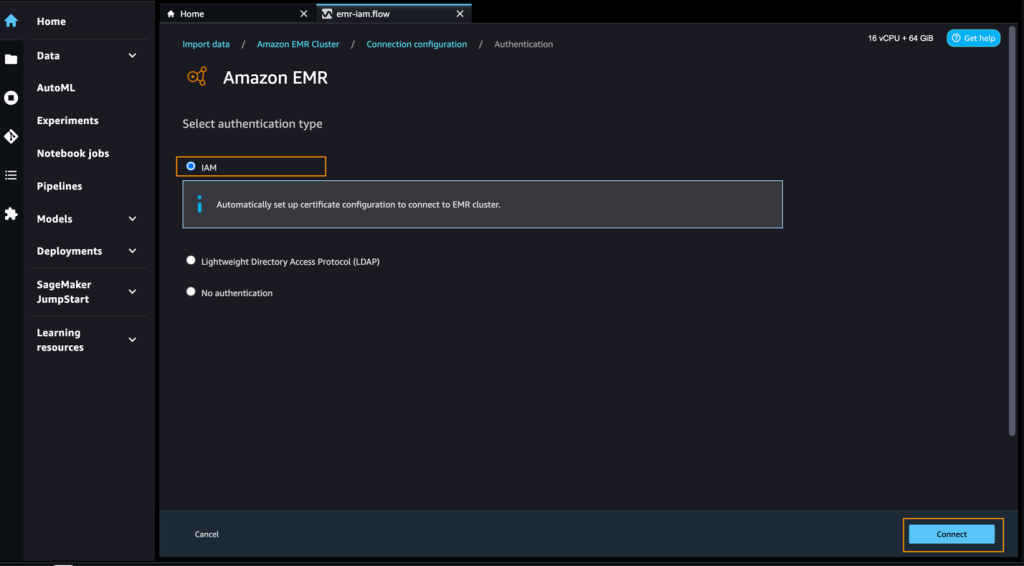
- Seleziona IAM come tipo di autenticazione e scegli Connetti.
Quando sei connesso, puoi visualizzare interattivamente un albero di database e una preview o schema della tabella. Puoi anche interrogare, esplorare e visualizzare i dati da Amazon EMR. Per una preview, di default vengono visualizzati fino a 100 record. Dopo aver fornito un’istruzione SQL nell’editor di query e aver scelto Esegui, la query verrà eseguita sull’engine Hive di Amazon EMR per visualizzare i dati. Scegli Annulla query per annullare le query in corso se stanno richiedendo un tempo insolitamente lungo.
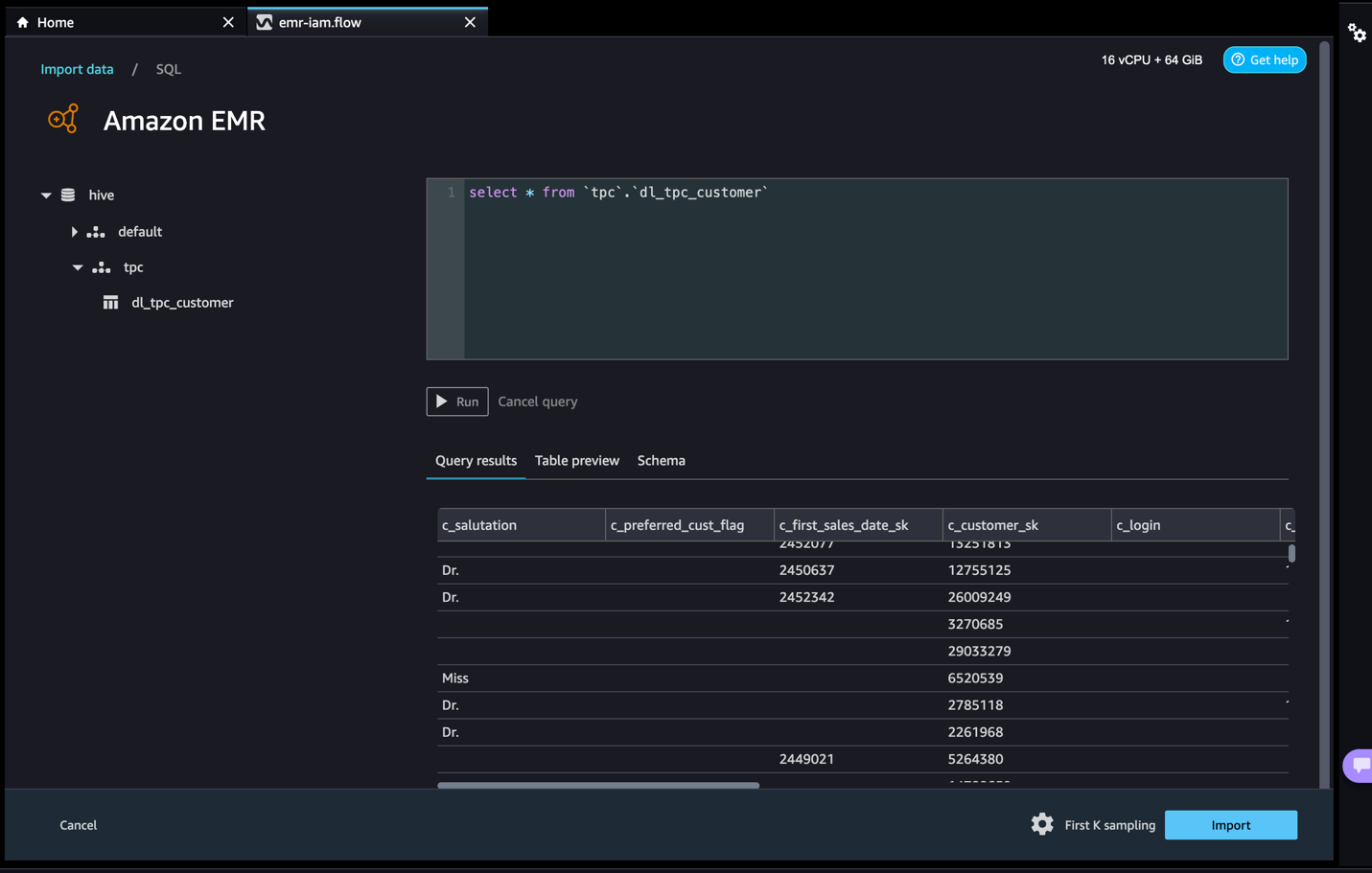
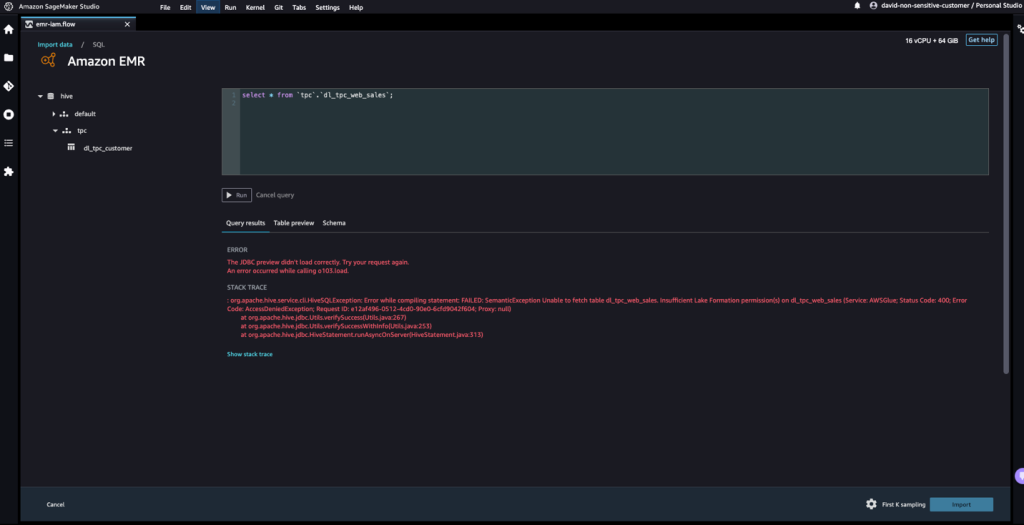
- Accediamo ai dati dalla tabella a cui David non ha le autorizzazioni.
La query produrrà il messaggio di errore "Impossibile recuperare la tabella dl_tpc_web_sales. Autorizzazioni insufficienti di Lake Formation su dl_tpc_web_sales."
L’ultimo passo è importare i dati. Quando sei pronto con i dati interrogati, hai l’opzione di aggiornare le impostazioni di campionamento per la selezione dei dati in base al tipo di campionamento (FirstK, Random o Stratified) e alla dimensione del campione per l’importazione dei dati in Data Wrangler.
- Scegli Importa per importare i dati.
Nella pagina successiva, puoi aggiungere diverse trasformazioni e analisi essenziali al dataset.
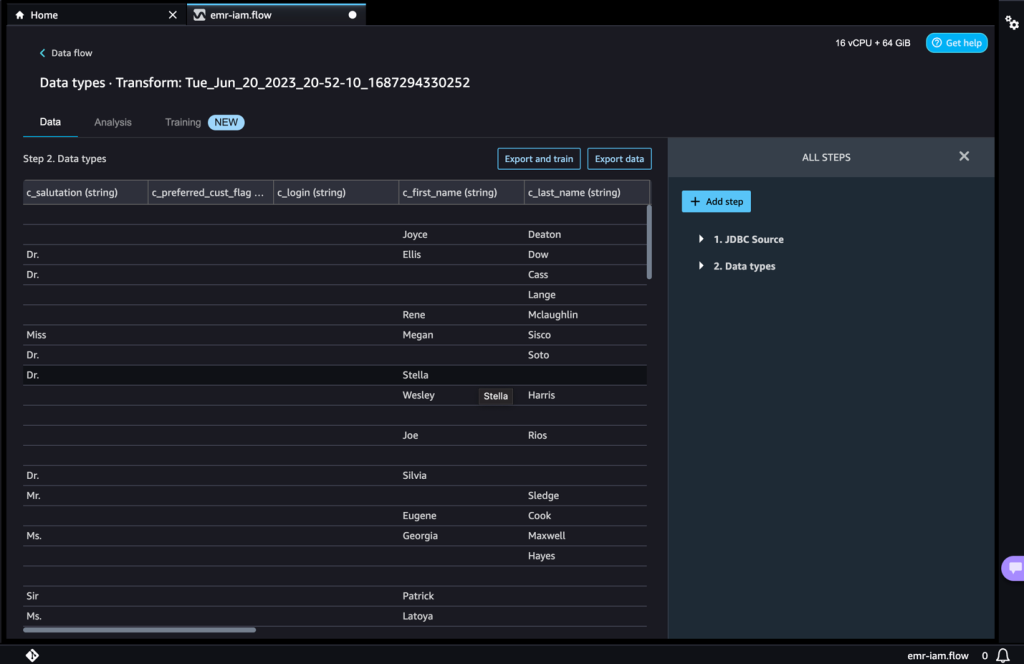
- Naviga nel flusso dei dati e aggiungi ulteriori passaggi al flusso come necessario per le trasformazioni e l’analisi.
Puoi eseguire un rapporto sull’analisi dei dati per identificare problemi di qualità dei dati e ottenere raccomandazioni per risolvere tali problemi. Vediamo alcuni esempi di trasformazioni.
- Nella visualizzazione Flusso dati, dovresti vedere che stiamo utilizzando Amazon EMR come fonte di dati utilizzando il connettore Hive.
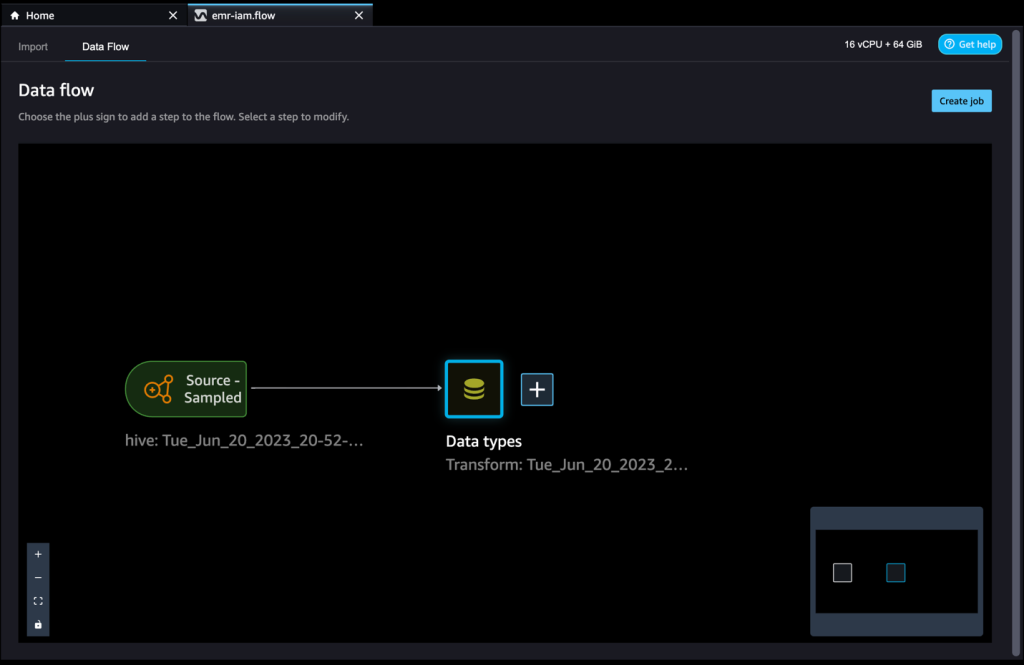
- Scegli il segno più accanto a Tipo di dati e scegli Aggiungi trasformazione.
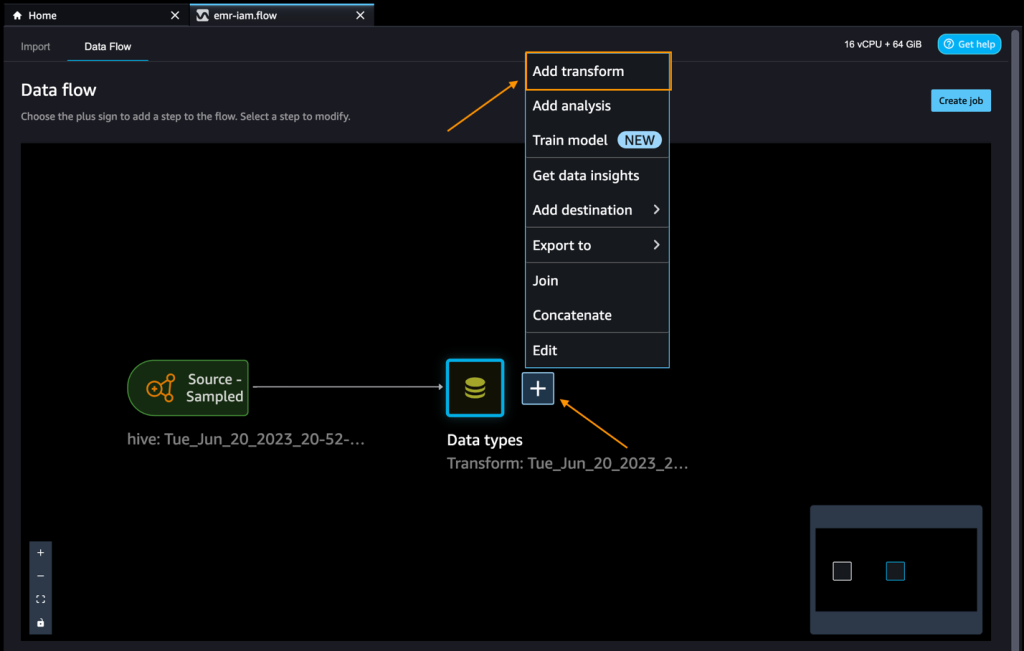
Esploriamo i dati e applichiamo una trasformazione. Ad esempio, la colonna c_login è vuota e non aggiungerà valore come caratteristica. Eliminiamo la colonna.
- Nella sezione Tutti i passaggi, scegli Aggiungi passaggio.
- Scegli Gestisci colonne.
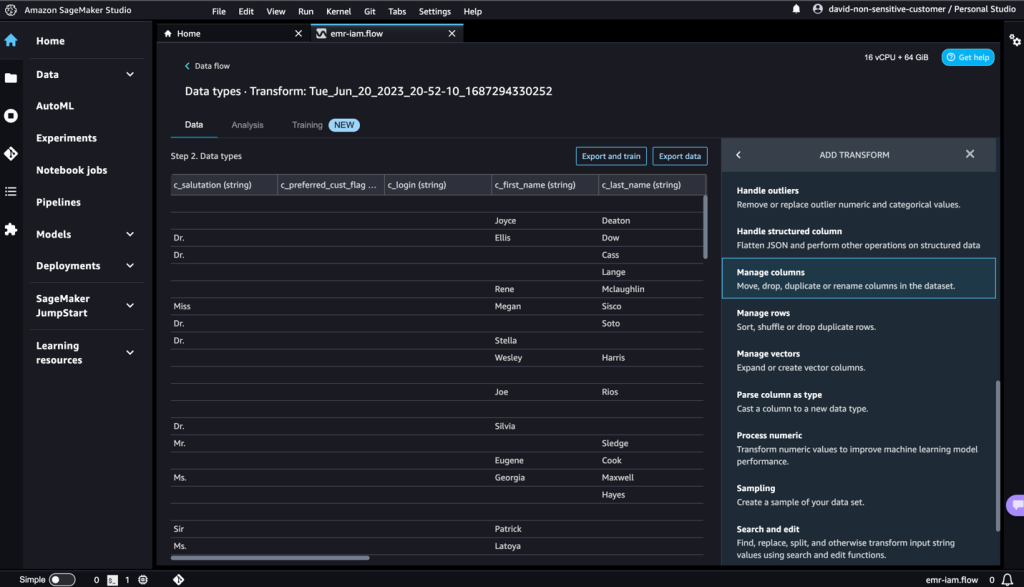
- Per Trasformazione, scegli Elimina colonna.
- Per Colonne da eliminare, scegli la colonna
c_login. - Scegli Anteprima, quindi scegli Aggiungi.
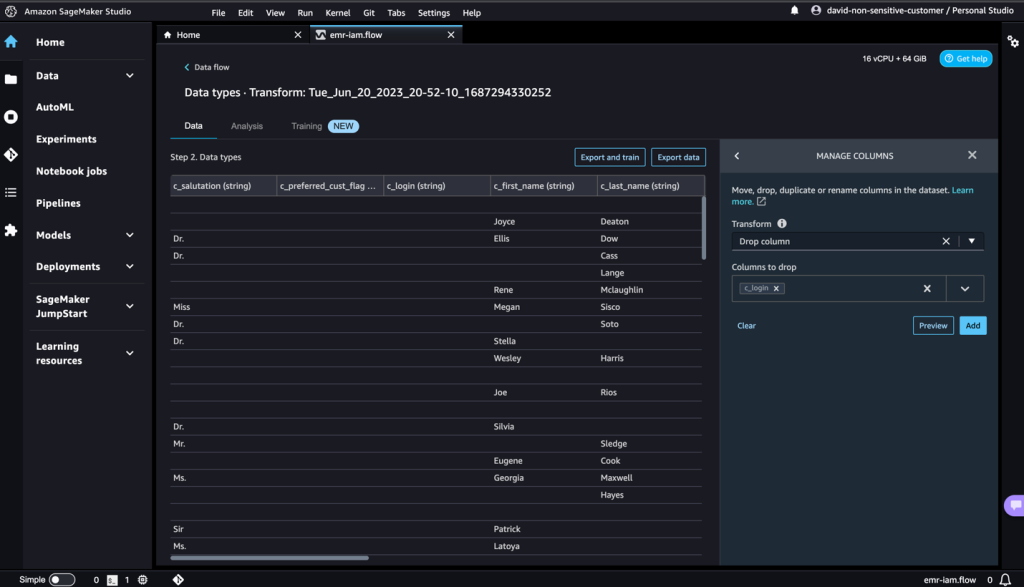
- Verifica il passaggio espandendo la sezione Elimina colonna.
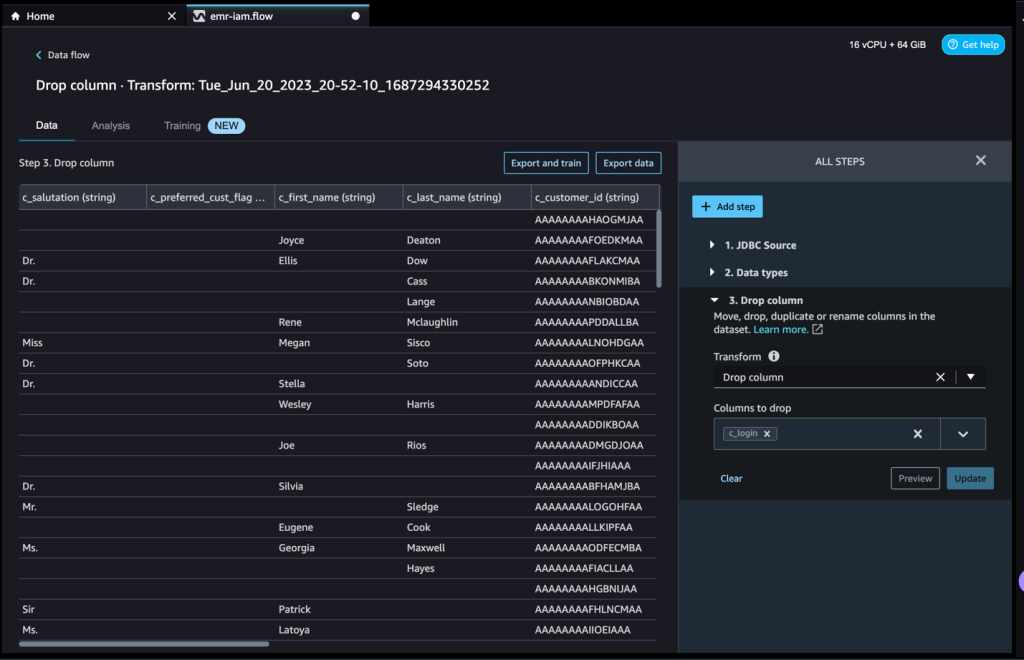
Puoi continuare ad aggiungere passaggi in base alle diverse trasformazioni richieste per il tuo dataset. Torniamo al nostro flusso di dati. Ora puoi vedere il blocco Elimina colonna che mostra la trasformazione che abbiamo eseguito.
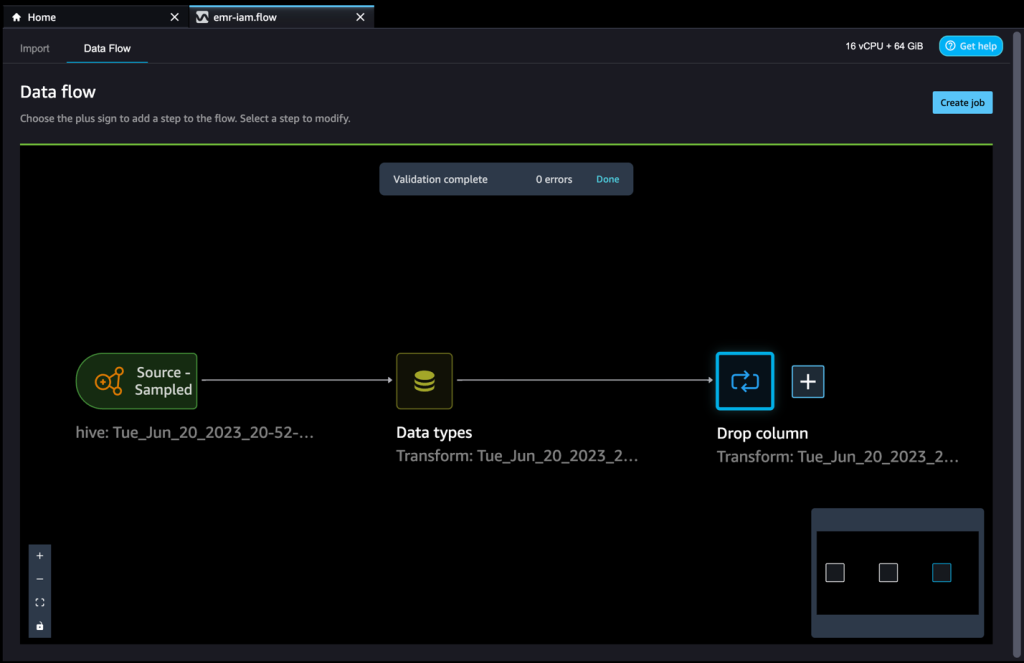
Gli esperti di ML trascorrono molto tempo nel codice di ingegneria delle caratteristiche, applicandolo ai loro dataset iniziali, addestrando modelli sui dataset ingegnerizzati e valutando l’accuratezza del modello. Data la natura sperimentale di questo lavoro, anche il progetto più piccolo porterà a molteplici iterazioni. Spesso lo stesso codice di ingegneria delle caratteristiche viene eseguito più volte, sprecando tempo e risorse computazionali per ripetere le stesse operazioni. Nelle grandi organizzazioni, ciò può causare una perdita ancora maggiore di produttività perché diversi team spesso eseguono lavori identici o addirittura scrivono codice di ingegneria delle caratteristiche duplicato perché non hanno conoscenza del lavoro precedente. Per evitare la riprocessazione delle caratteristiche, possiamo esportare le nostre caratteristiche trasformate su Amazon SageMaker Feature Store. Per ulteriori informazioni, consulta Nuova – Conserva, scopri e condividi le caratteristiche di Machine Learning con Amazon SageMaker Feature Store.
- Scegli il segno più accanto a Elimina colonna.
- Scegli Esporta in e SageMaker Feature Store (tramite il notebook Jupyter).
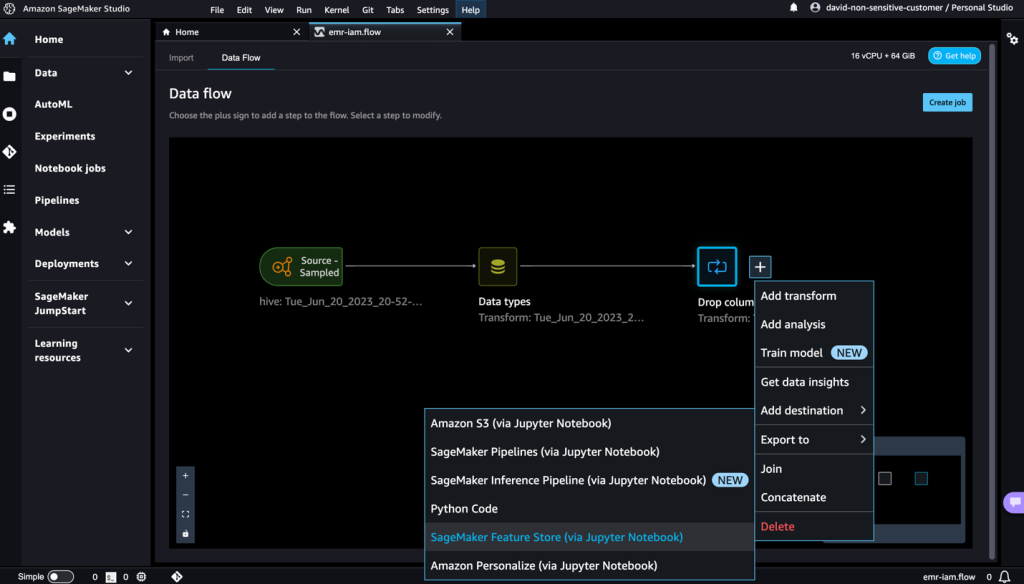
Puoi facilmente esportare le tue caratteristiche generate in SageMaker Feature Store specificandolo come destinazione. Puoi salvare le caratteristiche in un gruppo di caratteristiche esistente o crearne uno nuovo. Per ulteriori informazioni, consulta Crea e archivia facilmente le caratteristiche in Amazon SageMaker senza codice.
Ora abbiamo creato le caratteristiche con SageMaker Data Wrangler e archiviato quelle caratteristiche in SageMaker Feature Store. Abbiamo mostrato un esempio di flusso di lavoro per l’ingegneria delle caratteristiche nell’interfaccia utente di SageMaker Data Wrangler.
Pulizia
Se hai completato il tuo lavoro con SageMaker Data Wrangler, elimina le risorse create per evitare costi aggiuntivi.
- In SageMaker Studio, chiudi tutte le schede, quindi nel menu File, scegli Arresta.
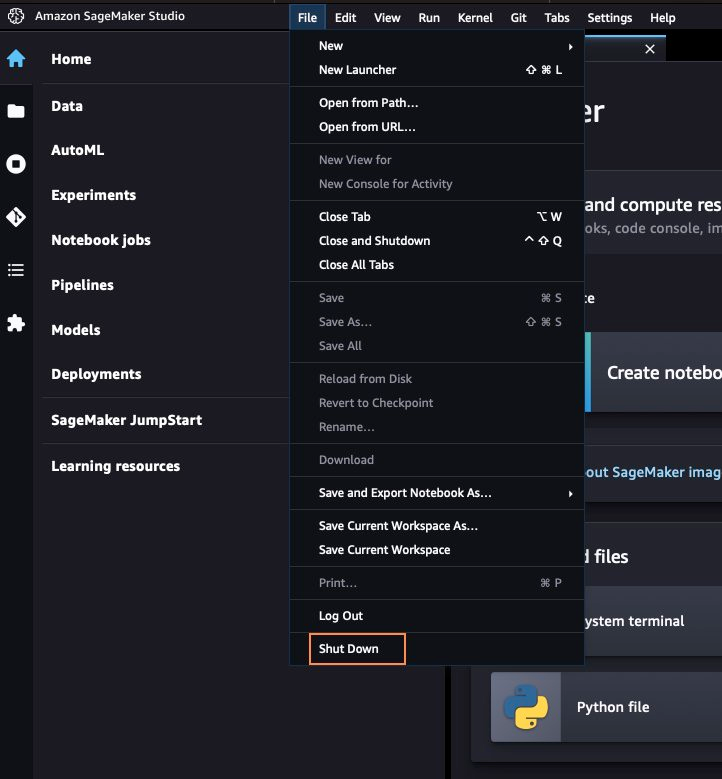
- Quando richiesto, scegli Arresta tutto.
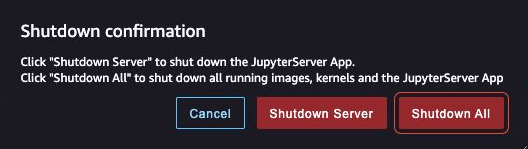
L’arresto potrebbe richiedere alcuni minuti in base al tipo di istanza. Assicurati che tutte le app associate a ciascun profilo utente siano state eliminate. Se non sono state eliminate, elimina manualmente l’app associata a ciascun profilo utente creato utilizzando il modello di CloudFormation.
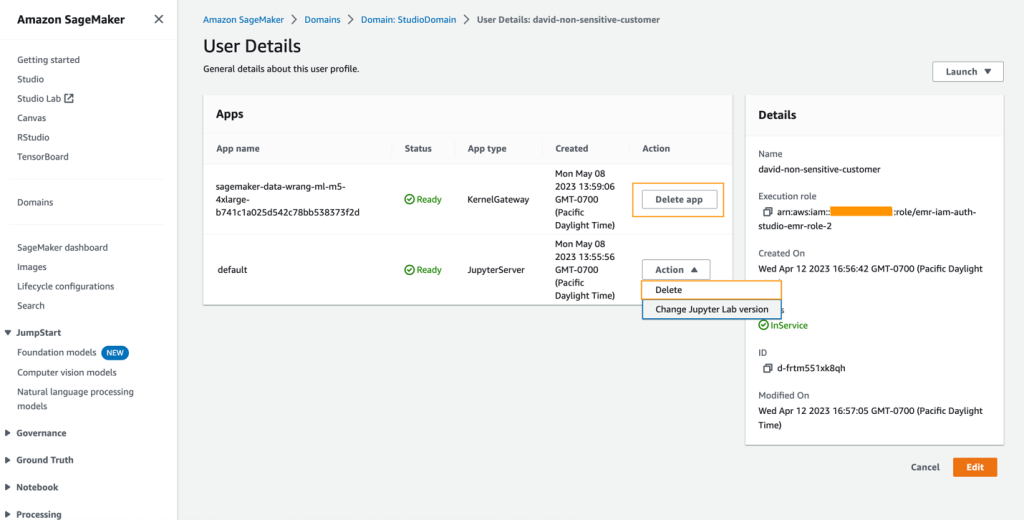
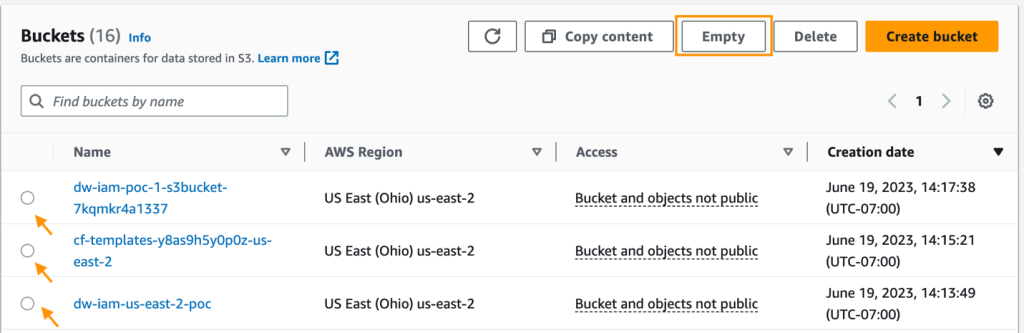
- Nella console di Amazon S3, svuota tutti i bucket S3 creati dal modello di CloudFormation durante la fornitura dei cluster.
I bucket dovrebbero avere lo stesso prefisso del nome dello stack di lancio di CloudFormation e cf-templates-.
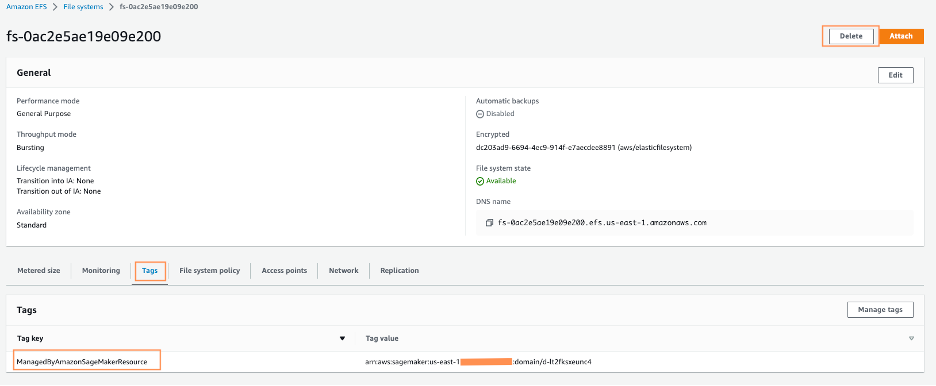
- Nella console di Amazon EFS, elimina il file system di SageMaker Studio.
Puoi confermare di avere il file system corretto scegliendo l’ID del file system e confermando l’etichetta ManagedByAmazonSageMakerResource nella scheda Tag.
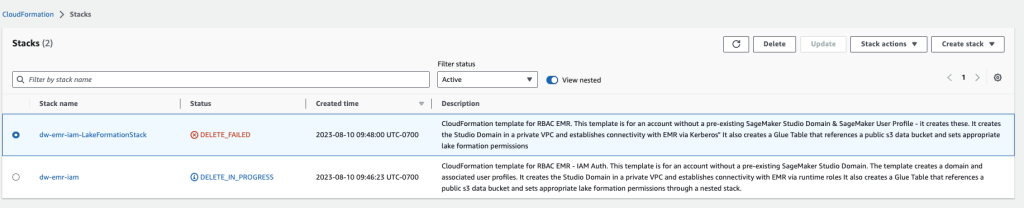
- <li+Nella console di AWS CloudFormation, seleziona lo stack creato e scegli Elimina.

Riceverai un messaggio di errore, che è normale. Torneremo su questo punto e lo puliremo nei passaggi successivi.
- Identifica la VPC creata dallo stack CloudFormation, chiamata dw-emr-, e segui le istruzioni per eliminare la VPC.
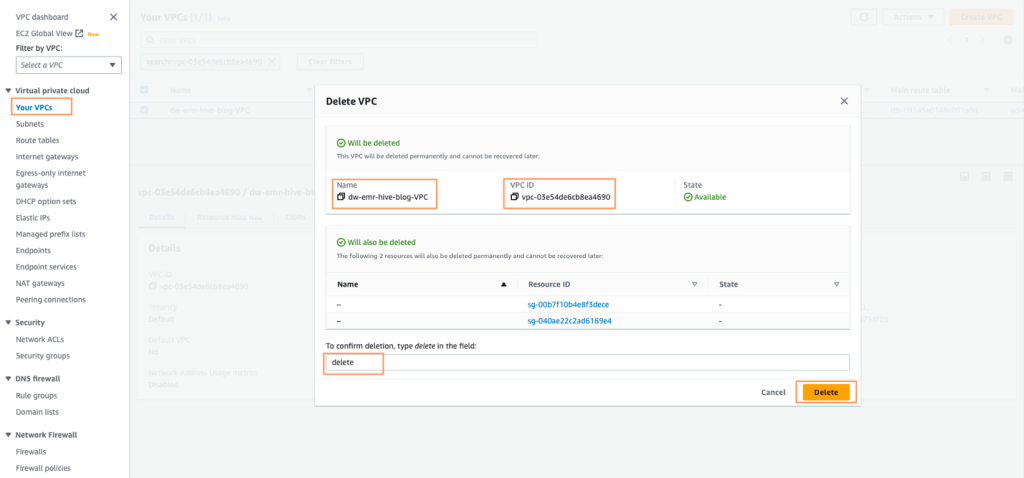
- Torna alla console AWS CloudFormation e riprova l’eliminazione dello stack per dw-emr-.
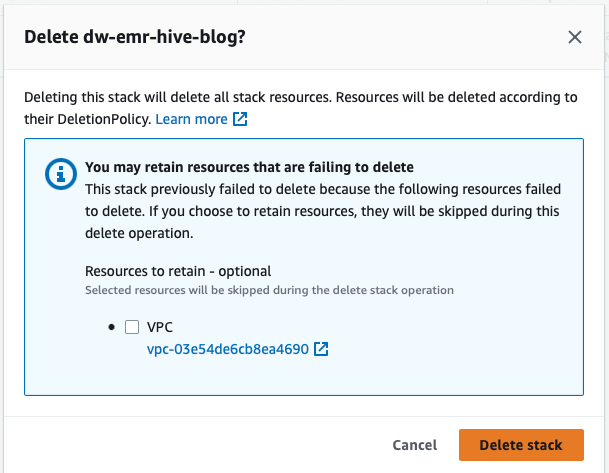
Tutte le risorse create dal template CloudFormation descritte in questo post sono state rimosse dal tuo account.
Conclusioni
In questo post, abbiamo visto come applicare un controllo dell’accesso dettagliato con Lake Formation e accedere ai dati utilizzando Amazon EMR come sorgente di dati in SageMaker Data Wrangler, come trasformare ed analizzare un dataset e come esportare i risultati in un flusso di dati per l’uso in un notebook Jupyter. Dopo aver visualizzato il nostro dataset utilizzando le funzionalità analitiche integrate di SageMaker Data Wrangler, abbiamo ulteriormente ottimizzato il nostro flusso di dati. Il fatto di aver creato una pipeline di preparazione dei dati senza scrivere una singola riga di codice è significativo.
Per iniziare con SageMaker Data Wrangler, consulta la guida Prepara dati di machine learning con Amazon SageMaker Data Wrangler.






