Nuovo modello di testo-immagine di Metas – Spiegazione del paper CM3leon
New Metas text-image model - CM3leon paper explanation
Il nuovo modello SOTA altamente efficiente di Text-to-Image(-to-Text!).
![Fonte: Composizione: Autore, Immagine: [1]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*8uAXSsuPcTE8-K1TBS_ZLw.png)
Meta ha recentemente rilasciato il suo nuovo modello di text-to-image state-of-the-art, chiamato CM3Leon [1], che NON si basa sulla diffusione come Stable-Diffusion [2], Midjourney o DALLE [3].
È un modello decoder-only con recupero aggiunto e autoregressivo!
Un boccone difficile, ma in questo post, scopriremo cosa significa tutto ciò. A questo punto, sappiamo già che i modelli attuali di generazione di immagini possono generare immagini sorprendenti ma hanno ancora certe limitazioni. Ad esempio, l’efficienza e il costo di quei modelli. O la generazione di mani! Ma non con CM3Leon, di cui gli autori sembrano essere molto orgogliosi!
La generazione in sé è fantastica, ma ciò che questo approccio autoregressivo e solo-decoder abilita anche sono le capacità di immagine-a-testo!
- Il Chief Scientist di NVIDIA, Bill Dally, terrà il discorso principale a Hot Chips
- Il viaggio di 50 anni della Teoria della Complessità ai limiti della conoscenza
- Google testa un assistente IA che offre consigli sulla vita
Risultati
Ma, ok, prima, diamo uno sguardo più da vicino ai risultati e a cosa rende CM3Leon così speciale!
![Il grafico del punteggio FID in scala logaritmica di vari modelli rispetto alle ore di GPU A100 equivalenti durante l'addestramento. Fonte: [1]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*pZ8E5XsgQzKl2Qrt-gpevA.png)
Abbiamo già guardato immagini generate bene, ma quando guardiamo i numeri nella figura sopra, possiamo davvero vedere quanto CM3Leon sia migliore rispetto ad altri modelli, come DALLE e Parti. Ora, si può discutere quanto bene il punteggio FID catturi effettivamente il realismo dell’immagine generata, ma comunque, CM3Leon stabilisce un nuovo punteggio FID state-of-the-art sul dataset MS COCO. Dove devo dire, scegliere la versione autoregressiva del modello DALLE è un po’ ingiusto.
Come funziona DALLE?
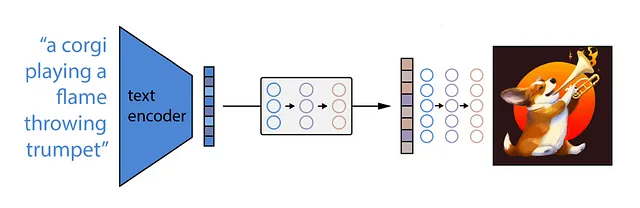
Solo su una piccola digressione, DALLE ha un modello intermedio, chiamato prior, che mappa l’embedding di testo generato da CLIP a una codifica dell’immagine corrispondente, che viene quindi utilizzata per generare l’immagine finale utilizzando la diffusione. Questo prior può essere nuovamente un processo di diffusione o autoregressivo. Entrambi sembrano produrre risultati simili, ma il processo di diffusione è più efficiente, quindi gli autori di DALLE hanno scelto quello. Quindi sì, scegliere la versione meno efficiente per il confronto qui potrebbe essere un po’ ingiusto per DALLE.
Torniamo ai risultati della generazione di immagini
![Sommario di vari modelli di text-to-image sul compito zero-shot MS-COCO misurato dal punteggio FID. Per tutti i nostri modelli, generiamo 8 campioni per ogni query di input e utilizziamo un modello CLIP per selezionare la migliore generazione. Fonte: [1]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*coRfNm3CN8DmmXrylC_-5w.png)
Ora, ok. Il bel punteggio FID da solo è fantastico, ma ancora meglio è che CM3Leon raggiunge questa performance essendo molto più efficiente!! Con il suo modello più grande di 7 miliardi di parametri, è molto più piccolo del modello Parti più grande e utilizza una frazione dei dati di addestramento e del tempo! Inoltre, gli autori introducono una nuova metrica per l’addestramento “responsabile”. Le immagini utilizzate per l’addestramento di CM3Leon sono tutte con licenza da Shutterstock, quindi (sperabilmente) niente più paura di cause legali! Poi c’è la colonna “Nr. di documenti recuperati” che è una delle principali caratteristiche del modello CM3Leon che lo rende così fantastico, e ne sapremo di più a riguardo fra un attimo. Ma in breve, dato un prompt di testo, il modello può in qualche modo recuperare immagini o addirittura testo rilevante da una banca di memoria e utilizzarlo come ulteriore contesto per il processo di generazione dell’immagine.
Cos’è considerato generazione zero-shot?
Ora, la cosa che mi fa chiedere è se il modello recupera ulteriori immagini per il processo di generazione, è davvero generazione zero-shot? Immagino che il modello stesso recuperi le immagini extra e che non siano fornite dalla persona che sollecita il modello, ma sì, non sono sicuro al 100% qui.
A proposito, nell’abstract, gli autori menzionano il loro modello di maggior successo che raggiunge un “punteggio zero-shot MS-COCO FID di 4.88”
CM3Leon raggiunge una performance di ultima generazione nella generazione di testo-immagine con un calcolo di addestramento 5 volte inferiore rispetto a metodi comparabili (zero-shot MS-COCO FID di 4.88). – Fonte: [1]
Ma questo punteggio viene raggiunto con due immagini recuperate, cioè si riferiscono al recupero come zero-shot. Ma nella loro didascalia della Figura 1, dicono quanto segue:
Mostra delle generazioni zero-shot CM3Leon (senza l’ausilio del recupero). – Fonte: [1]
Quindi, cos’è una generazione zero-shot? Con il recupero o senza?
Benchmarks multimodali
Otteniamo, fino ad ora, tutto riguardo alla generazione di immagini, ma dal momento che questo modello è un modello autoregressivo, decoder-only, praticamente come tutti i grandi LLM, può anche interpretare le immagini come token normali e usarli come contesto per la generazione di testo! In altre parole, dopo aver applicato il Fine-tuning supervisionato (o, per brevità, SFT), il nostro modello può anche svolgere compiti multimodali più complessi.
![Esempi quantitativi dopo il fine-tuning del modello CM3Leon utilizzando una vasta gamma di compiti combinati di immagini e testo. Fonte: [1]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*tDZ23diYuDA0n2CmNpMjRg.png)
È molto bravo in compiti testo-immagine intercalati come “Modifica guidata dal testo” e “Generazione basata sull’immagine all’immagine” in cui è possibile fornire una mappa di segmentazione, uno schizzo solo con i contorni o persino una mappa di profondità e, basandosi su quelli e su un prompt di testo, viene generata una nuova immagine. Oppure, con “Generazione di immagini basata spazialmente”, è possibile fornire persino le coordinate di un oggetto nel prompt di testo e l’immagine generata posizionerà quell’oggetto in quelle coordinate. Inoltre, il modello è piuttosto bravo nel generare effettivamente testo nelle immagini, cosa che non era possibile fino a poco tempo fa :)) Infine, con il corretto Fine-tuning supervisionato, CM3Leon può anche prendere immagini come input e svolgere compiti come la descrizione delle immagini con risposte brevi o lunghe, domande e risposte visive e ragionamento. Non è ancora così bravo come modelli dedicati alla descrizione delle immagini come Flamingo [4], ma dato che questo è più o meno solo un effetto collaterale del design del modello, i risultati sono comunque molto impressionanti!
Come funziona CM3Leon?
Ok, fantastico, ma come funziona CM3Leon e cosa significa modello a recupero-aumentato, autoregressivo, solo-decoder?
A questo punto, tutti più o meno sappiamo come funziona la diffusione. Un modello viene addestrato per prevedere il rumore in un’immagine in modo che quando partiamo da un rumore completamente casuale, possiamo applicare questo modello e rimuovere il rumore passo dopo passo. Questo processo di rimozione del rumore può ora essere condizionato anche dal testo in modo che possiamo guidare il processo di generazione con il nostro prompt.
I modelli autoregressivi funzionano in modo leggermente diverso. Diamo un’occhiata a come Parti implementa questa idea di un modello di generazione di immagini autoregressivo.
Cos’è Autoregressivo?
Ricordate come funzionano gli Autoencoder? Abbiamo una rete Encoder che mappa un’immagine in una qualche rappresentazione di embedding in modo che il decoder possa quindi generare la stessa immagine solo da una rappresentazione vettoriale latente. Nell’immagine sottostante, questa idea è illustrata dal modulo verde.
![Architettura autoregressiva encoder-decoder per la generazione di immagini proposta in Parti (Yu et al., 2022). Fonte: [5]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*aw7AU-ZmRPk7WD9q0ta77g.png)
Ora, cosa succederebbe se quegli embedding che il decoder (nel caso di Parti chiamato detokenizer) utilizza per generare l’immagine fossero sotto forma di token predetti da un Language Model? Pensate a come un modello GPT inizia con un semplice token Start-of-Sequence e predice il token successivo o piuttosto l’embedding del token da un dato vocabolario conosciuto in modo autoregressivo. Un vision transformer genera anche embedding per ogni token patch dell’immagine e questi possono anche essere vincolati a provenire da un certo vocabolario. Ciò significa che il nostro decoder di testo autoregressivo (modulo blu) può anche generare ogni token di embedding dell’immagine e quindi consentire al generatore di immagini (o ancora una volta, qui chiamato detokenizer) di generare l’immagine. Ora, per condizionare il processo di generazione dei token di immagine, Parti decide di adottare un approccio encoder-decoder. Utilizza l’intera architettura del Transformer per ciò per cui è stato originariamente progettato, tradurre il testo. In questo caso, semplicemente traducendo la lingua del testo nella lingua delle immagini, o, i token di testo in token di immagine. In altre parole, utilizzano la Cross-attention in cui gli embedding dell’encoder di testo (modulo giallo) vengono utilizzati come condizionamento per il decoder di testo che predice un token di immagine dopo l’altro.
Questo approccio autoregressivo risolve alcuni problemi che i modelli di diffusione avevano. Ad esempio, i modelli autoregressivi possono gestire molto meglio le lunghe frasi di testo e possono generare testo all’interno delle immagini molto bene! Ma possono farlo solo in scala. Il caso di “semplicemente aumentare le dimensioni e funzionerà” è abbastanza estremo qui. Possiamo osservare questo esempio con il canguro e il testo “Benvenuti amici!”.
![Le immagini sono state generate utilizzando lo stesso prompt ma con diverse dimensioni del modello. Fonte: [5]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*m5Q-OZR5FEwBeVusMgHG6w.png)
Cosa significa solo-decoder?
Ora sappiamo come funziona la generazione di immagini in modo autoregressivo, ma CM3Leon è un modello autoregressivo solo-decoder e non un modello encoder-decoder come Parti. Quello che questo significa praticamente è che il condizionamento del testo per il processo di generazione avviene non attraverso un encoder e cross-attention, ma come semplici token di testo nel contesto del decoder. Ciò significa che il vocabolario deve ora includere il vocabolario dei token di immagine (dove gli autori utilizzano un tokenizer già esistente) e il vocabolario dei token di testo (dove gli autori addestrano un nuovo tokenizer). Inoltre, gli autori introducono un nuovo token <break> che indica una transizione tra modalità.
![Illustrazione di un documento multimodale. Una singola sequenza contenente token di testo e immagini. Fonte: [1]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*XVKMg9_xFHHF60rAYH5TFw.png)
Ora il nostro input e output del decoder possono essere qualcosa del genere in cui iniziamo con il prompt “Una foto di un gatto mostrato su una DSLR” seguito dal token <break> e il decoder quindi predice i token di immagine successivi uno alla volta. Una volta raggiunto un altro token <break> o <EOS>, il decoder di immagini può prendere il controllo e generare l’immagine!
Per quanto riguarda i dati di addestramento, il modello può gestire casi multimodali come “Immagine di un camaleonte:” seguito dai token di immagine, dove il modello viene semplicemente addestrato sulla perdita standard di previsione del token successivo.
“Immagine di un camaleonte:” → “<Img233>”, “<Img44>”, …
Ma ciò significa anche che il modello può gestire compiti di sottotitoli per immagini semplicemente riformattando lo stesso esempio per mascherare una determinata parte del campione e aspettarsi che il modello preveda la parte mascherata dopo la richiesta <infill>.
“Immagine di un <mask>: <Img233>, … <infill> →”camaleonte”
In altre parole, il modello vede l’immagine e deve prevedere cosa contiene questa immagine.
Il nostro modello può ora generare sia testo che immagini.
Autoregressivo, fatto. Solo-decoder, fatto. Infine, come funziona questa cosa chiamata “retrieval-augmentation”?
Che cos’è il recupero-augmentation?
Ho già menzionato che questo significa essenzialmente che, dato il prompt iniziale, il modello può recuperare immagini o testo, o entrambi, e aggiungerli al suo contesto. Ora che sappiamo come funziona l’input per il modello solo-decoder, possiamo capire abbastanza facilmente quanto sia semplice aggiungere più immagini e testo al contesto.
![Illustrazione di un campione completo di dati con più elementi di immagini e testo intercalati. Fonte: [1]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*sSkA2eGMMaXxDYg3whPPYw.png)
Possiamo semplicemente aggiungere qualsiasi quantità di testo e immagini che si trovano tra i token <break> fino alla lunghezza massima del contesto consentita! E con una lunghezza di sequenza di 4096, dovremmo essere in grado di aggiungere uno o due documenti recuperati. Con il termine “documenti” si fa riferimento a elementi che possono essere singole immagini o testo, o una coppia di immagine e didascalia.
CM3Leon si basa molto sul paper RA-CM3, [6], che ha proposto di aggiungere questa caratteristica di recupero-augmentation al metodo proposto nel paper CM3, [7]. Ecco la ricerca, un paper che si basa sull’altro!
Nel paper RA-CM3, possiamo vedere molto chiaramente gli effetti del recupero di un’immagine per un determinato prompt di testo.
![Effetto del recupero di un'immagine da una banca di memoria sul processo di generazione dell'immagine. Fonte: [6]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*lihnjpu0CpKIt-SmcyL7aw.png)
Qui, ad esempio, possiamo vedere alcuni risultati ottenuti dal prompt “Bandiera francese sventolante sulla superficie della luna”, dove il CM3 senza recupero e Stable Diffusion posiziona semplicemente la bandiera americana sulla luna, ma se aggiungiamo un’immagine recuperata della bandiera francese al contesto, RA-CM3 genera un risultato corretto. Effetti simili si osservano quando si recuperano due immagini, e così via.
![Effetto della specifica manuale di un'immagine sul processo di generazione/riempimento dell'immagine. Fonte: [6]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*6-pKivvIa4X2rBSFxJoVxA.png)
Questo, ovviamente, ti consente anche di specificare manualmente un’immagine per controllare lo stile dell’immagine generata, come possiamo vedere qui in questo esempio. Fornire un’immagine di una persona con una giacca rossa porterà anche il modello a riempire un’immagine di una persona con una giacca rossa.
Interessante, quindi come funziona questo recupero? L’idea è in realtà molto semplice. Gli autori utilizzano un modello CLIP preconfezionato e congelato per codificare la query di input, ad esempio un semplice prompt di testo, e ordinare i candidati simili da una banca di memoria in base a un punteggio di rilevanza. Gli esempi di testo e immagine singoli nella banca di memoria passano semplicemente una volta attraverso il modello CLIP, ma per i documenti di immagine e didascalia, gli autori dividono il testo e l’immagine, li codificano separatamente e quindi ne fanno la media come rappresentazione vettoriale dell’intero documento.
Gli autori non selezionano semplicemente il documento più simile, ma utilizzano diverse euristiche per rendere il recupero più informativo. Ad esempio, un documento composto da un’immagine e un testo è più informativo rispetto a un documento che contiene solo testo o solo un’immagine. Oppure saltano un documento candidato se è troppo simile alla query o se è già stato recuperato lo stesso documento. E alcuni altri trucchi.
Ci sono altri dettagli minori (ma importanti!) per far sì che l’output del modello funzioni ancora meglio, ma non sono idee fondamentalmente nuove, solo trucchi aggiuntivi che generalmente sembrano migliorare le prestazioni. Ad esempio, campionare casualmente diversi valori di temperatura, o qualcosa chiamato campionamento TopP, applicare una guida senza classificatore durante l’inferenza o la loro stessa adattazione della Decodifica Contrastiva.
Quindi, alla fine, ora sappiamo come funziona il modello CM3Leon che combina il recupero-augmented, l’autoregressivo e il solo-decoder, e cosa può fare. Questa idea di recupero contribuisce in modo significativo al fatto che il modello sia così efficiente in termini di parametri e quindi di dati!
![Effetto del recupero di due immagini da una banca dati di memoria sul processo di generazione delle immagini. Fonte: [6]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*yHR0SJSwE13YVHt-obxTtg.png)
Il modello non deve memorizzare tutte le informazioni del mondo, come ad esempio cosa è un albero di ciliegio o il Monte Rushmore e come appaiono. E utilizzando un’architettura solo decoder rende l’addestramento e l’ottimizzazione per nuovi compiti molto più facili!
Dopo aver potenzialmente pensato che i modelli di diffusione siano il miglior metodo per la generazione di immagini, questo articolo dimostra ancora una volta quanto siano potenti i modelli autoregressivi come i famosi modelli di trasformatori per una vasta gamma di compiti di testo e immagini.
E se hai apprezzato la lettura di questo post, non dimenticare di lasciare un applauso e seguirmi per ulteriori entusiasmanti spiegazioni di paper sull’IA!
P.S.: Se ti piace questo contenuto e le illustrazioni, puoi anche dare un’occhiata al mio canale YouTube, dove pubblico contenuti simili ma con animazioni più accattivanti!
Riferimenti
[1] Scaling Autoregressive Multi-Modal Models: Pretraining and Instruction Tuning, L. Yu, B Shi, R Pasunuru, et al., 2023, Link al paper
[2] High-Resolution Image Synthesis with Latent Diffusion Models, R. Rombach, A. Blattmann, D. Lorenz, P. Esser, B., 2021, https://arxiv.org/abs/2112.10752
[3] Zero-Shot Text-to-Image Generation, Ramesh et al., 2021, https://arxiv.org/abs/2102.12092
[4] Flamingo: a Visual Language Model for Few-Shot Learning, B. Alayrac, J. Donahue, P. Luc, A. Miech et al., 2022, https://arxiv.org/abs/2204.14198
[5] Scaling Autoregressive Models for Content-Rich Text-to-Image Generation, Yu et al., 2022, https://arxiv.org/abs/2206.10789
[6] Retrieval-Augmented Multimodal Language Modeling, Yasunaga et al., 2022, https://arxiv.org/abs/2211.12561
[7] CM3: A Causal Masked Multimodal Model of the Internet, A. Aghajanyan et al., 2022, https://arxiv.org/abs/2201.07520





