Estrazione dei dati dai documenti senza OCR con i Transformers (2/2)
Estrazione dati da documenti senza OCR con Transformers (2/2)
Donut contro Pix2Struct sui dati personalizzati
Quanto bene comprendono questi due modelli trasformatori i documenti? In questa seconda parte ti mostrerò come addestrarli e confrontare i loro risultati per il compito di estrazione dell’indice chiave.
Aggiornamento di Donut
Quindi riprendiamo dalla parte 1, dove spiego come preparare i dati personalizzati. Ho zippato le due cartelle del dataset e le ho caricate in un nuovo dataset di huggingface qui. Il notebook di colab che ho utilizzato può essere trovato qui. Esso scaricherà il dataset, impostando l’ambiente, caricando il modello Donut e addestrandolo.
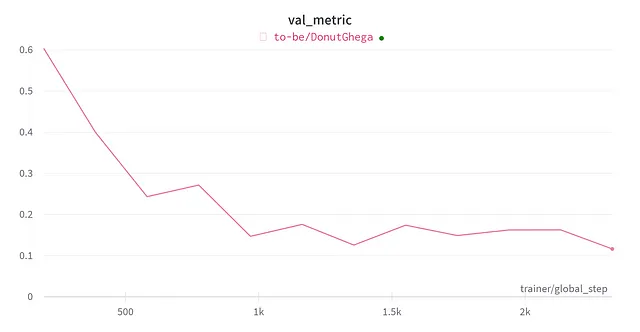
Dopo l’aggiornamento per 75 minuti, l’ho interrotto quando la metrica di validazione (che è la distanza di modifica) ha raggiunto 0,116:
A livello di campo, ottengo questi risultati per il set di validazione:
- Analizzando la difesa del FC Barcelona da una prospettiva di Data Science
- Cos’è il greenwashing e come possiamo utilizzare l’analisi dei dati per rilevarlo
- Le LLM di Google possono padroneggiare gli strumenti solo leggendo la documentazione
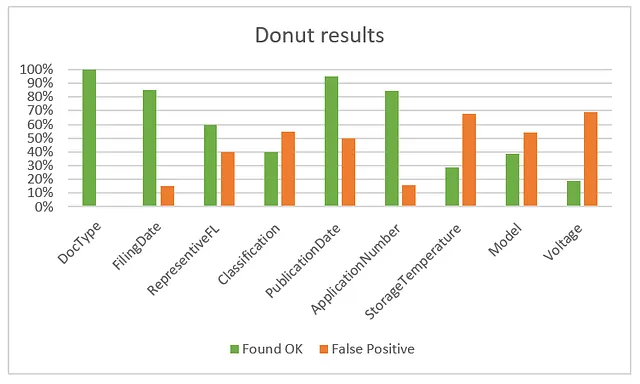
Quando guardiamo Doctype, vediamo che Donut identifica sempre correttamente i documenti come brevetto o scheda tecnica. Quindi possiamo dire che la classificazione raggiunge una precisione del 100%. Nota anche che anche se abbiamo una classe scheda tecnica, non è necessario che questa parola esatta sia nel documento per classificarlo come tale. Non importa a Donut, poiché è stato aggiornato per riconoscerla in questo modo.
Altri campi ottengono risultati abbastanza buoni, ma è difficile dire cosa succede sotto la superficie solo con questo grafico. Mi piacerebbe vedere dove il modello va bene e male in casi specifici. Quindi ho creato una routine nel mio notebook per generare una tabella di report formattata in HTML. Per ogni documento nel mio set di validazione ho un’entrata di riga come questa:

Sulla sinistra c’è il dato riconosciuto (inferito) insieme alla sua verità di riferimento. Sul lato destro c’è l’immagine. Ho anche usato dei codici di colore per avere una panoramica rapida:






