Aprire l’API OpenAI (Python)
Aprire l'API OpenAI (Python)
Una introduzione completa e adatta ai principianti con codice di esempio
Questo è il secondo articolo di una serie sull’utilizzo dei Large Language Models (LLM) in pratica. Qui presento una introduzione adatta ai principianti sull’API di OpenAI. Questo ti permette di andare oltre le interfacce di chat restrittive come ChatGPT e ottenere di più dai LLM per i tuoi casi d’uso unici. Di seguito è fornito un esempio di codice Python e il repository GitHub.
Indice:
- Cos’è un API?
- L’API di OpenAI (Python)
- Come iniziare (4 passaggi)
- Codice di esempio
Nel primo articolo di questa serie, ho descritto l’Ingegneria dei Prompt come il modo più accessibile per utilizzare i LLM in pratica. Il modo più facile (e più popolare) per farlo è tramite strumenti come ChatGPT, che forniscono un modo intuitivo, gratuito e senza codice per interagire con un LLM.
Un’introduzione pratica ai LLM
3 livelli di utilizzo dei LLM in pratica
towardsdatascience.com
Tuttavia, questa facilità d’uso ha un costo. In particolare, l’interfaccia di chat è restrittiva e non si adatta bene a molti casi d’uso pratici, come la creazione del proprio assistente di supporto clienti, l’analisi in tempo reale del sentiment delle recensioni dei clienti, ecc.
- Crea la tua prima app di Deep Learning in un’ora
- Come costruire una pila dati a 5 livelli
- Mappare la rete di Billy Corgan Analisi e mappatura delle relazioni sociali con la libreria NetworkX di Python – Parte 4
In questi casi, possiamo portare l’Ingegneria dei Prompt un passo avanti e interagire con i LLM in modo programmabile. Un modo per farlo è tramite un’API.
1) Cos’è un API?
Un Application Programming Interface (API) ti consente di interagire con un’applicazione remota in modo programmabile. Anche se può sembrare tecnico e spaventoso, l’idea è molto semplice. Considera la seguente analogia.
Immagina di avere una forte voglia delle pupusas che hai mangiato durante quella estate in El Salvador. Purtroppo, sei tornato a casa e non sai dove trovare buon cibo salvadoregno. Fortunatamente, però, hai un amico super foodie che conosce tutti i ristoranti in città.
Quindi, invii un messaggio al tuo amico.
“Ci sono dei buoni posti per le pupusas in città?”
Poi, un paio di minuti dopo, ricevi la risposta.
“Sì! Flavors of El Salvador ha le migliori pupusas!”
Anche se potrebbe sembrare irrilevante per le API, in sostanza è così che funzionano. Invii una richiesta a un’applicazione remota, ovvero invii un messaggio al tuo amico super foodie. Quindi, l’applicazione remota invia una risposta, cioè il messaggio di risposta dal tuo amico.

La differenza tra un’API e l’analogia sopra è che invece di inviare la richiesta con l’app di messaggistica del tuo telefono, utilizzi il tuo linguaggio di programmazione preferito, ad esempio Python, JavaScript, Ruby, Java, ecc. Questo è ottimo se stai sviluppando un software che richiede informazioni esterne, perché il recupero delle informazioni può essere automatizzato.
2) API di OpenAI (Python)
Possiamo utilizzare le API per interagire con i Large Language Models. Una delle più popolari è l’API di OpenAI, dove invece di digitare i prompt nell’interfaccia web di ChatGPT, puoi inviarli e riceverli da OpenAI utilizzando Python.
Questo offre praticamente a chiunque l’accesso a LLM (e ad altri modelli di Machine Learning) all’avanguardia senza dover fornire le risorse computazionali necessarie per eseguirli. Lo svantaggio, ovviamente, è che OpenAI non fa questo come un’opera di beneficenza. Ogni chiamata API costa denaro, ma ne parleremo tra poco.
Di seguito sono elencate alcune caratteristiche notevoli dell’API (non disponibili con ChatGPT).
- Messaggio di sistema personalizzabile (impostato su qualcosa come “Sono ChatGPT, un grande modello di linguaggio addestrato da OpenAI, basato sull’architettura GPT-3.5. Le mie conoscenze si basano sulle informazioni disponibili fino a settembre 2021. Oggi è il 13 luglio 2023” per ChatGPT)
- Regolazione dei parametri di input come lunghezza massima della risposta, numero di risposte e temperatura (cioè “casualità” della risposta).
- Includere immagini e altri tipi di file nelle richieste
- Estrarre utili incorporamenti di parole per attività successive
- Inserimento audio per trascrizione o traduzione
- Funzionalità di ottimizzazione fine-tuning del modello
L’API di OpenAI dispone di diversi modelli tra cui scegliere. Il miglior modello da scegliere dipenderà dal tuo caso d’uso specifico. Di seguito è riportato un elenco dei modelli attualmente disponibili [1].
![Elenco dei modelli disponibili tramite l'API di OpenAI a luglio 2023. Immagine dell'autore. [1]](https://miro.medium.com/v2/resize:fit:640/format:webp/1*DDldra_REDf4A_bBdW0McA.png)
Nota: Ogni elemento elencato sopra è accompagnato da un insieme di modelli che variano in dimensione e costo. Consulta la documentazione per le informazioni più recenti.
Prezzi e Token
Sebbene l’API di OpenAI offra agli sviluppatori un facile accesso ai modelli di Machine Learning all’avanguardia, uno svantaggio ovvio è che costa denaro. I prezzi vengono calcolati in base ai token (no, non intendo le NFT o qualcosa che usi all’arcade).
I token, nel contesto dei LLM, sono essenzialmente un insieme di numeri che rappresentano un insieme di parole e caratteri. Ad esempio, “The” potrebbe essere un token, ” end” (con lo spazio) potrebbe essere un altro, e “.” un altro ancora.
Quindi, il testo “The End.” sarebbe composto da 3 token, diciamo (73, 102, 6).
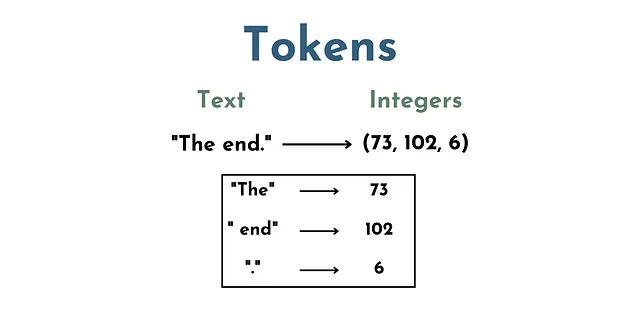
Questo è un passaggio critico perché LLM (cioè reti neurali) non “comprendono” il testo direttamente. Il testo deve essere convertito in una rappresentazione numerica in modo che il modello possa eseguire operazioni matematiche sull’input. Da qui il passaggio della tokenizzazione.
Il prezzo di una chiamata API dipende dal numero di token utilizzati nella richiesta e dal modello a cui viene effettuata la richiesta. Il prezzo per modello è disponibile sul sito web di OpenAI.
3) Iniziare (4 Passaggi)
Ora che abbiamo una comprensione di base dell’API di OpenAI, vediamo come usarla. Prima di poter iniziare a codificare, dobbiamo impostare quattro cose.
3.1) Creare un Account (ricevi un credito API di $5 per i primi tre mesi)
- Per creare un account vai alla pagina Panoramica dell’API di OpenAI e fai clic su “Iscriviti” nell’angolo in alto a destra
- Nota – Se hai già usato ChatGPT, probabilmente hai già un account OpenAI. In tal caso, fai clic su “Accedi”
3.2) Aggiungi Metodo di Pagamento
- Se il tuo account ha più di 3 mesi o il credito API gratuito di $5 non è sufficiente per te, dovrai aggiungere un metodo di pagamento prima di effettuare chiamate API.
- Fai clic sull’immagine del tuo profilo e seleziona l’opzione “Gestisci account”.
- Quindi aggiungi un metodo di pagamento cliccando sulla scheda “Fatturazione” e poi su “Metodi di pagamento”.
3.3) Imposta Limiti di Utilizzo
- Successivamente, consiglio di impostare dei limiti di utilizzo in modo da evitare di essere addebitato più di quanto hai preventivato.
- Per fare ciò, vai alla sezione “Limiti di utilizzo” nella scheda “Fatturazione”. Qui puoi impostare un limite “Soft” e un limite “Hard”.
- Se raggiungi il tuo limite mensile soft, OpenAI ti invierà una notifica via email.
- Se raggiungi il tuo limite hard, qualsiasi richiesta API aggiuntiva verrà rifiutata (quindi non sarai addebitato oltre questo limite).
3.4) Ottieni la Chiave Segreta dell’API
- Fai clic su “Visualizza chiavi API”.
- Se è la tua prima volta, dovrai creare una nuova chiave segreta. Per farlo, fai clic su “Crea nuova chiave segreta”.
- Successivamente, puoi dare un nome personalizzato alla tua chiave. Qui ho usato “my-first-key”.
- Quindi, clicca su “Crea chiave segreta”.
4) Esempio di Codice: API di Completamento della Chat
Con tutte le impostazioni effettuate, siamo (finalmente) pronti per effettuare la nostra prima chiamata API. Qui utilizzeremo la libreria openai Python, che semplifica l’integrazione dei modelli di OpenAI nel tuo codice Python. Puoi scaricare il pacchetto tramite pip. L’esempio di codice seguente (e il codice bonus) è disponibile nel repository GitHub di questo articolo.
Una breve nota sulle deprecazioni dell’API di Completamento — OpenAI sta abbandonando il paradigma del prompt libero e si sta orientando verso chiamate API basate su chat. Secondo un articolo di blog di OpenAI, il paradigma basato su chat fornisce migliori risposte, grazie alla sua interfaccia di prompt strutturata, rispetto al paradigma precedente [2].
Mentre i modelli più vecchi di OpenAI (GPT-3) sono ancora disponibili tramite il paradigma “freeform”, i modelli più recenti (come GPT-3.5-turbo e GPT-4) sono disponibili solo tramite chiamate basate su chat.
Iniziamo con una chiamata API molto semplice. Qui passeremo due input al metodo openai.ChatCompletions.create(), ovvero model e messages.
- model — definisce il nome del modello di linguaggio che vogliamo utilizzare (possiamo scegliere tra i modelli elencati in precedenza nell’articolo).
- messages — imposta il dialogo precedente come una lista di dizionari. I dizionari hanno due coppie chiave-valore (ad esempio {“role”: “user”, “content”: “Ascolta il tuo”}). Primo, “role” definisce chi sta parlando (ad esempio “role”: “user”). Questo può essere l'”utente”, l'”assistente” o il “sistema”. Secondo, “content” definisce cosa sta dicendo il ruolo (ad esempio “content”: “Ascolta il tuo”). Anche se questo può sembrare più restrittivo rispetto a un’interfaccia di prompt libero, possiamo essere creativi con i messaggi di input per ottimizzare le risposte per un caso d’uso specifico (ne parleremo più avanti).
Ecco come appare la nostra prima chiamata API in Python.
import openaifrom sk import my_sk # importazione della chiave segreta da un file esternoinport time# chiave segreta importata (o semplicemente copiala qui)openai.api_key = my_sk # creazione di una chat completionchat_completion = openai.ChatCompletion.create(model="gpt-3.5-turbo", messages=[{"role": "user", "content": "Ascolta il tuo"}])La risposta dell’API è memorizzata nella variabile chat_completion. Stampando chat_completion, vediamo che è come un dizionario composto da 6 coppie chiave-valore.
{'id': 'chatcmpl-7dk1Jkf5SDm2422nYRPL9x0QrlhI4', 'object': 'chat.completion', 'created': 1689706049, 'model': 'gpt-3.5-turbo-0613', 'choices': [<OpenAIObject a 0x7f9d1a862b80> JSON: { "index": 0, "message": { "role": "assistant", "content": "cuore." }, "finish_reason": "stop" }], 'usage': <OpenAIObject a 0x7f9d1a862c70> JSON: { "prompt_tokens": 10, "completion_tokens": 2, "total_tokens": 12 }}Il significato di ciascun campo è elencato di seguito.
- ‘Id’ = ID univoco per la risposta dell’API
- ‘Object’ = nome dell’oggetto API che ha inviato la risposta
- ‘Created’ = timestamp Unix di quando è stata elaborata la richiesta API
- ‘Model’ = nome del modello utilizzato
- ‘Choices’ = risposta del modello formattata in JSON (cioè simile a un dizionario)
- ‘Usage’ = metadati del conteggio dei token formattati in JSON (cioè simile a un dizionario)
Tuttavia, la cosa principale che ci interessa qui è il campo ‘Choices‘ poiché qui viene memorizzata la risposta del modello. In questo caso, vediamo che il ruolo “assistant” risponde con il messaggio “cuore.”
Yay! Abbiamo effettuato la nostra prima chiamata API. Ora iniziamo a giocare con i parametri di input del modello.
max_tokens
Prima di tutto, possiamo impostare il numero massimo di token consentiti nella risposta del modello utilizzando il parametro di input max_tokens. Questo può essere utile per molte ragioni a seconda del caso d’uso. In questo caso, voglio solo una risposta di una parola, quindi lo imposto su 1 token.
# impostare il numero massimo di token# creare un completamento della chatchat_completion = openai.ChatCompletion.create(model="gpt-3.5-turbo", messages=[{"role": "user", "content": "Ascolta il tuo"}], max_tokens = 1)# stampare il completamento della chatprint(chat_completion.choices[0].message.content)"""Output:>>> cuore """n
Inoltre, possiamo impostare il numero di risposte che desideriamo ricevere dal modello. Anche questo può essere utile per molte ragioni a seconda del caso d’uso. Ad esempio, se vogliamo generare un insieme di risposte tra cui possiamo selezionare quella che ci piace di più.
# impostare il numero di completamenti# creare un completamento della chatchat_completion = openai.ChatCompletion.create(model="gpt-3.5-turbo", messages=[{"role": "user", "content": "Ascolta il tuo"}], max_tokens = 2, n=5)# stampare il completamento della chatfor i in range(len(chat_completion.choices)): print(chat_completion.choices[i].message.content)"""Ouput:>>> cuore.>>> cuore e>>> cuore.>>>>>> cuore,>>>>>> cuore,"""Notiamo che non tutti i completamenti sono identici. Questo può essere una cosa buona o una cosa cattiva a seconda del caso d’uso (ad esempio, casi d’uso creativi rispetto a casi d’uso di automazione dei processi). Pertanto, può essere vantaggioso regolare la diversità dei completamenti della chat per un determinato prompt.
temperature
Risulta che possiamo farlo regolando il parametro temperature. In parole semplici, questo regola la “casualità” dei completamenti della chat. I valori per questo parametro vanno da 0 a 2, dove 0 rende i completamenti più prevedibili e 2 li rende meno prevedibili [3].
Concettualmente, possiamo pensare che temp=0 predefinirà la parola successiva più probabile, mentre temp=2 abiliterà completamenti relativamente improbabili. Vediamo come appare.
# temperatura=0# creare un completamento della chatchat_completion = openai.ChatCompletion.create(model="gpt-3.5-turbo", messages=[{"role": "user", "content": "Ascolta il tuo"}], max_tokens = 2, n=5, temperature=0)# stampare il completamento della chatfor i in range(len(chat_completion.choices)): print(chat_completion.choices[i].message.content)"""Output:>>> cuore.>>> cuore.>>> cuore.>>> cuore.>>> cuore."""Come previsto, quando temp=0, tutti e 5 i completamenti sono identici e producono qualcosa di “molto probabile”. Ora vediamo cosa succede quando alziamo la temperatura.
# temperatura=2# creare un completamento della chatchat_completion = openai.ChatCompletion.create(model="gpt-3.5-turbo", messages=[{"role": "user", "content": "Ascolta il tuo"}], max_tokens = 2, n=5, temperature=2)# stampare il completamento della chatfor i in range(len(chat_completion.choices)): print(chat_completion.choices[i].message.content)"""Output:>>> giudizio>>> Consiglio>>> consapevolezza interiore>>> cuore.>>>>>> sta ing"""Anche in questo caso, come previsto, i completamenti della chat con temp=2 erano molto più diversi e “fuori luogo”.
ruoli dei messaggi: Assistente per il completamento dei testi
Infine, possiamo sfruttare i diversi ruoli in questo paradigma di promozione basato su chat per regolare ulteriormente le risposte del modello di linguaggio.
Ricordate dall’inizio che possiamo includere contenuti di 3 ruoli diversi nei nostri prompt: sistema, utente e assistente. Il messaggio di sistema imposta il contesto (o il compito) per i completamenti del modello ad esempio “Sei un chatbot amichevole che non vuole distruggere tutti gli umani” o “Riassumi le richieste degli utenti in massimo 10 parole”.
I messaggi utente e assistente possono essere utilizzati in almeno due modi. Uno, per generare esempi per apprendimento in contesto, e due, per memorizzare e aggiornare la cronologia della conversazione per un chatbot in tempo reale. Qui useremo entrambi i modi per creare un assistente per il completamento dei testi delle canzoni.
Iniziamo creando il messaggio di sistema “Sono un assistente per il completamento dei testi delle canzoni dei Roxette. Quando viene fornita una riga di una canzone, fornirò la riga successiva della canzone.” Quindi, forniamo due esempi di messaggi utente e assistente. Seguito dallo stesso prompt utente utilizzato negli esempi precedenti, ovvero “Ascolta il tuo”.
Ecco come appare nel codice.
# prompt iniziale con messaggio di sistema e 2 esempi di compitielenco_messaggi = [{"ruolo":"sistema", "contenuto": "Sono un assistente per il completamento dei testi delle canzoni dei Roxette. Quando viene fornita una riga di una canzone, fornirò la riga successiva della canzone."}, {"ruolo":"utente", "contenuto": "So che c'è qualcosa nell'onda del tuo sorriso"}, {"ruolo":"assistente", "contenuto": "Ho un'idea dallo sguardo dei tuoi occhi, sì"}, {"ruolo":"utente", "contenuto": "Hai costruito un amore ma quell'amore si sgretola"}, {"ruolo":"assistente", "contenuto": "Il tuo piccolo pezzo di Paradiso diventa troppo scuro"}, {"ruolo":"utente", "contenuto": "Ascolta il tuo"}]# generare sequenzialmente 4 completamenti della chatfor i in range(4): # creare un completamento della chat completamento_chat = openai.ChatCompletion.create(model="gpt-3.5-turbo", messages=elenco_messaggi, max_tokens = 15, n=1, temperature=0) # stampare il completamento della chat print(completamento_chat.choices[0].message.content) nuovo_messaggio = {"ruolo":"assistente", "contenuto":completamento_chat.choices[0].message.content} # aggiungere il nuovo messaggio all'elenco dei messaggi elenco_messaggi.append(nuovo_messaggio) time.sleep(0.1)"""Output:>>> Cuore quando ti sta chiamando>>> Ascolta il tuo cuore, non c'è nient'altro che puoi fare>>> Non so dove stai andando e non so perché>>> Ma ascolta il tuo cuore prima di dirgli addio"""Confrontando l’output con i testi effettivi della famosa canzone dei Roxette, vediamo che sono una corrispondenza esatta. Ciò è dovuto alla combinazione di tutti i diversi input che abbiamo fornito al modello.
Per vedere come appare quando “alziamo la temperatura”, controlla il codice bonus su GitHub. (Avviso: diventa strano)
Conclusioni
In questo articolo ho fornito una guida per principianti all’API Python di OpenAI con esempi di codice. Il vantaggio più grande nell’utilizzare l’API di OpenAI è che puoi lavorare con potenti LLM senza preoccuparti di fornire risorse computazionali. Gli svantaggi, tuttavia, sono che le chiamate all’API hanno un costo e ci possono essere preoccupazioni sulla sicurezza nel condividere alcuni tipi di dati con un terzo (OpenAI).
Per evitare questi svantaggi, possiamo rivolgerci a soluzioni LLM open-source. Questo sarà l’argomento del prossimo articolo di questa serie, in cui esploreremo la libreria Hugging Face Transformers.
Risorse
Collegamenti: Il mio sito web | Prenota una chiamata | Chiedimi qualsiasi cosa
Social: YouTube 🎥 | LinkedIn | Twitter
Supporto: Diventa un membro ⭐️ | Offrimi un caffè ☕️
Gli Imprenditori dei Dati
Una comunità per imprenditori nel settore dei dati. 👉 Unisciti a Discord!
VoAGI.com
[1] Documentazione dei Modelli OpenAI
[2] Disponibilità di GPT-4 e API di Completamento
[3] Definizione di temperatura dalla referenza dell’API





