Web LLM Porta i Chatbot LLM nel Browser
Web LLM brings LLM Chatbots to the browser.
Non sarebbe fantastico se potessi eseguire LLM e chatbot LLM direttamente nel tuo browser? Scopriamo di più sul progetto Web LLM, un interessante passo in questa direzione.

I chatbot basati su LLM sono accessibili attraverso un’interfaccia front-end e coinvolgono un gran numero di costose chiamate API al lato server. Ma cosa succederebbe se potessimo far funzionare gli LLM interamente nel browser, utilizzando la potenza di calcolo del sistema sottostante?
In questo modo, l’intera funzionalità dell’LLM è disponibile lato client, senza doversi preoccupare della disponibilità del server, dell’infrastruttura, e così via. Web LLM è un progetto che mira a raggiungere questo obiettivo.
- Il Futuro dell’AI Esplorando la Prossima Generazione di Modelli Generativi
- StarCoder l’Assistente di Codifica Che Hai Sempre Desiderato.
- Innovazioni nella Misurazione delle Percezioni della Comunità Sfida
Scopriamo di più su ciò che spinge Web LLM e le sfide nella costruzione di un tale progetto. Esamineremo anche i vantaggi e i limiti di Web LLM.
Cos’è Web LLM?
Web LLM è un progetto che utilizza WebGPU e WebAssembly e molto altro ancora per consentire l’esecuzione di LLM e app LLM completamente nel browser. Con Web LLM, è possibile eseguire chatbot LLM nel browser sfruttando la GPU del sistema sottostante tramite WebGPU.
Si utilizza la pila del compilatore del progetto Apache TVM e si utilizza WebGPU che è stato rilasciato di recente. Oltre al rendering di grafica 3D e simili, l’API WebGPU supporta anche calcoli di GPU a scopo generale (calcoli GPGPU).
Sfide nella costruzione di Web LLM
Dal momento che Web LLM viene eseguito interamente lato client senza alcun server di inferenza, il progetto si confronta con le seguenti sfide:
- Gli LLM di grandi dimensioni utilizzano framework Python per il deep learning che supportano nativamente anche l’utilizzo della GPU per le operazioni sui tensori.
- Quando si costruisce Web LLM per l’esecuzione completa nel browser, non sarà possibile utilizzare gli stessi framework Python. E’ necessario cercare stack di tecnologie alternativi che consentano di eseguire LLM sul web utilizzando comunque Python per lo sviluppo.
- L’esecuzione di app LLM richiede tipicamente grandi server di inferenza, ma quando tutto viene eseguito lato client – nel browser – non possiamo più disporre di grandi server di inferenza.
- È necessaria una compressione intelligente dei pesi del modello per farlo entrare nella memoria disponibile.
Come funziona Web LLM?
Il progetto Web LLM utilizza la GPU e le capacità hardware del sistema sottostante per eseguire grandi modelli di lingua nel browser. Il processo di compilazione di machine learning aiuta a integrare la funzionalità degli LLM nel lato browser sfruttando TVM Unity e un insieme di ottimizzazioni.

Il sistema è sviluppato in Python e viene eseguito sul web utilizzando il runtime TVM. Questa porting sul browser web viene effettuata eseguendo una serie di ottimizzazioni.
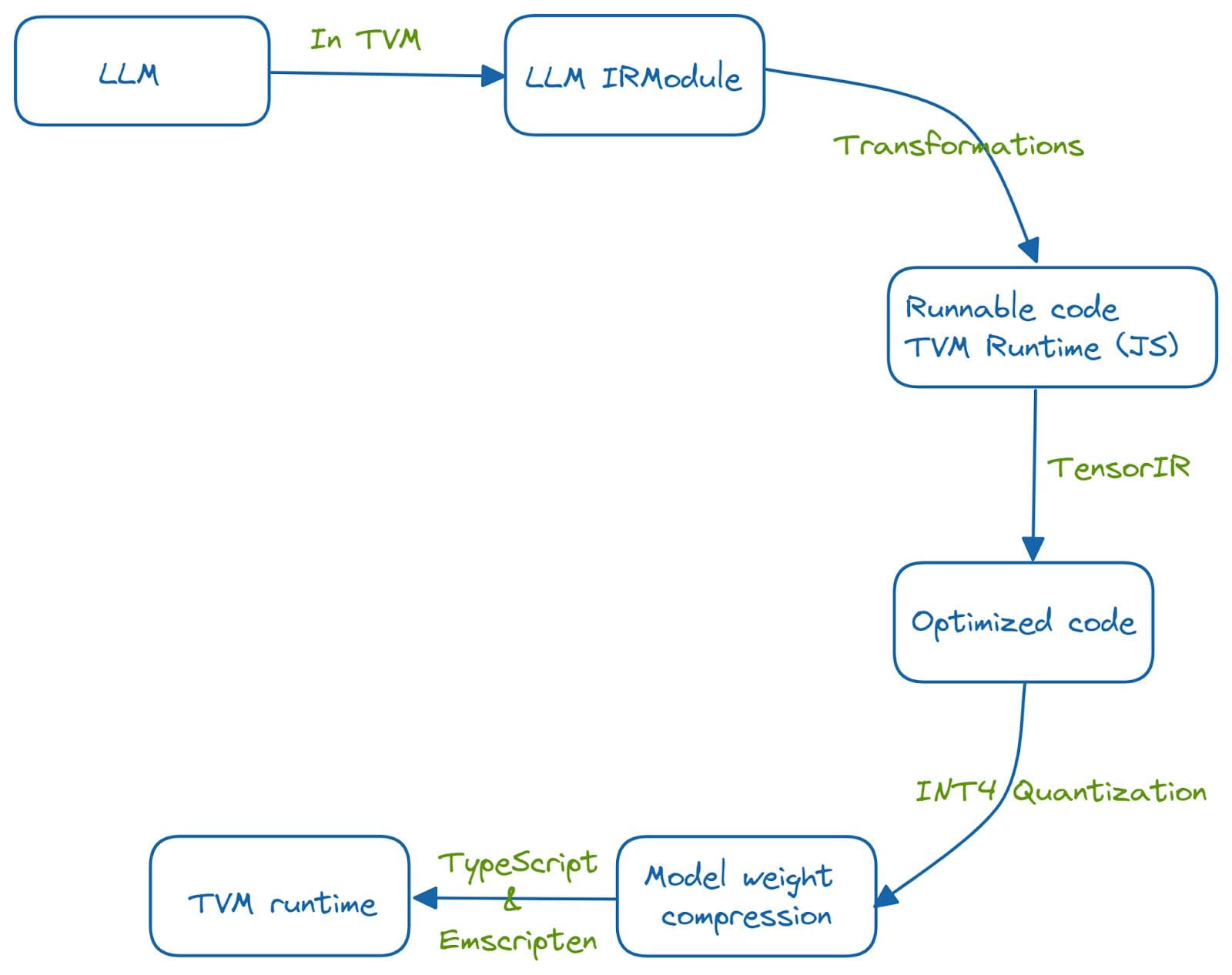
La funzionalità dell’LLM viene prima integrata in un IRModule in TVM. Vengono eseguite diverse trasformazioni sulle funzioni nell’IRModule per ottenere un codice ottimizzato ed eseguibile. TensorIR è una compilazione astratta per l’ottimizzazione di programmi con calcoli tensoriali. Inoltre, si utilizza l’quantizzazione INT-4 per comprimere i pesi del modello. E un runtime TVM è reso possibile utilizzando TypeScript ed emscripten, un compilatore LLVM che trasforma il codice C e C++ in WebAssembly.
È necessario avere l’ultima versione di Chrome o Chrome Canary per provare Web LLM. Al momento della stesura di questo articolo, Web LLM supporta gli LLM Vicuna e LLaMa.
Caricare il modello richiede del tempo la prima volta che si esegue il modello. Dopo la prima esecuzione, la memorizzazione nella cache è completa e le esecuzioni successive sono considerevolmente più veloci e presentano un minimo overhead.

Vantaggi e limiti di Web LLM
Concludiamo la nostra discussione elencando i vantaggi e i limiti di Web LLM.
Vantaggi
Oltre a esplorare la sinergia di Python, WebAssembly e altre stack di tecnologie, Web LLM presenta i seguenti vantaggi:
- Il principale vantaggio dell’esecuzione di LLM nel browser è la privacy. Grazie a questo design orientato alla privacy, che elimina completamente il lato server, non dobbiamo più preoccuparci dell’utilizzo dei nostri dati. Grazie all’utilizzo della potenza di calcolo della GPU del sistema sottostante, non dobbiamo preoccuparci che i dati raggiungano entità malevole.
- Possiamo costruire assistenti AI personali per le attività quotidiane. Pertanto, il progetto Web LLM offre un alto grado di personalizzazione.
- Un altro vantaggio di Web LLM è il ridotto costo. Non sono più necessarie costose chiamate API e server di inferenza, ma Web LLM utilizza la GPU e le capacità di elaborazione del sistema sottostante. Pertanto, l’esecuzione di Web LLM è possibile a una frazione del costo.
Limitazioni
Ecco alcune delle limitazioni di Web LLM:
- Anche se Web LLM allevia le preoccupazioni riguardanti l’immissione di informazioni sensibili, è comunque suscettibile ad attacchi sul browser.
- C’è ulteriore margine di miglioramento aggiungendo il supporto per più modelli di lingua e la scelta di browser. Attualmente, questa funzione è disponibile solo in Chrome Canary e nell’ultima versione di Chrome. Espandere questo a un insieme più ampio di browser supportati sarebbe utile.
- A causa dei controlli di robustezza eseguiti dal browser, Web LLM utilizzando WebGPU non ha le prestazioni native di un runtime della GPU. È possibile disattivare facoltativamente la bandiera che esegue i controlli di robustezza per migliorare le prestazioni.
Conclusione
Abbiamo cercato di capire come funziona Web LLM. Puoi provare a eseguirlo nel tuo browser o persino distribuirlo localmente. Considera di giocare con il modello nel tuo browser e verifica quanto sia efficace quando integrato nel tuo flusso di lavoro quotidiano. Se sei interessato, puoi anche dare un’occhiata al progetto MLC-LLM, che ti consente di eseguire LLM nativamente su qualsiasi dispositivo a tua scelta, inclusi laptop e iPhone.
Riferimenti e ulteriori letture
[1] API WebGPU, MDN Web Docs
[2] TensorIR: un’astrazione per l’ottimizzazione automatica dei programmi tensorizzati
[3] MLC-LLM Bala Priya C è una sviluppatrice e scrittrice tecnica dall’India. Le piace lavorare all’intersezione di matematica, programmazione, data science e creazione di contenuti. Le sue aree di interesse e competenza includono DevOps, data science e elaborazione del linguaggio naturale. Ama leggere, scrivere, programmare e il caffè! Attualmente sta lavorando per imparare e condividere le sue conoscenze con la comunità di sviluppatori scrivendo tutorial, guide pratiche, opinioni e altro ancora.






