Una guida per scalare MLOps
A guide to scaling MLOps.
I team di MLOps sono sotto pressione per migliorare le proprie capacità al fine di scalare l’AI. Ci siamo uniti a Ford Motors per esplorare come scalare MLOps all’interno di un’organizzazione e come iniziare.
Di Mike Caravetta & Brendan Kelly
Scaling MLOps per i tuoi team
I team MLOps sono sotto pressione per far avanzare le loro capacità per scalare l’AI. Nel 2022, abbiamo assistito ad un’esplosione di buzz intorno all’AI e all’MLOps dentro e fuori dalle organizzazioni. Il 2023 promette più hype con il successo di ChatGPT e la trazione dei modelli all’interno delle imprese.
I team MLOps cercano di espandere le loro capacità incontrando le pressanti esigenze del business. Questi team iniziano il 2023 con una lunga lista di risoluzioni e iniziative per migliorare come industrializzano l’AI. Come scaleremo i componenti di MLOps (deployment, monitoring e governance)? Quali sono le priorità principali per il nostro team?
- Dieci anni di Intelligenza Artificiale in rassegna
- Iniziare con ReactPy
- Crea una Dashboard di Analisi del Rapporto delle Serie Temporali
AlignAI si è unita a Ford Motors per scrivere questo playbook per guidare i team MLOps basandosi su ciò che abbiamo visto avere successo per scalare.
Cosa significa MLOps?
Per cominciare, abbiamo bisogno di una definizione di lavoro di MLOps. MLOps è la transizione di un’organizzazione dalla consegna di alcuni modelli AI alla consegna affidabile di algoritmi su larga scala. Questa transizione richiede un processo ripetibile e prevedibile. MLOps significa più AI e il ritorno sull’investimento associato. I team vincono in MLOps quando si concentrano sull’orchestrazione del processo, del team e degli strumenti.
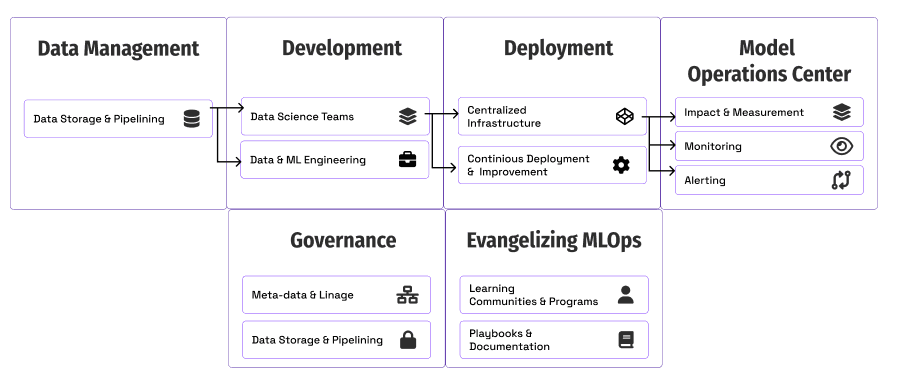
Componenti fondamentali di MLOps per scalare
Passiamo attraverso ogni area con esempi da Ford Motors e idee per aiutarti a cominciare.
- Misurazione e Impatto: come i team tracciano e misurano il progresso.
- Deployment & Infrastruttura: come i team scalano il deployment dei modelli.
- Monitoring: mantenimento della qualità e delle prestazioni dei modelli in produzione.
- Governance: creazione di controlli e visibilità intorno ai modelli.
- Evangellizzare MLOps: educare il business e gli altri team tecnici su come e perché utilizzare i metodi MLOps.
Misurazione e Impatto
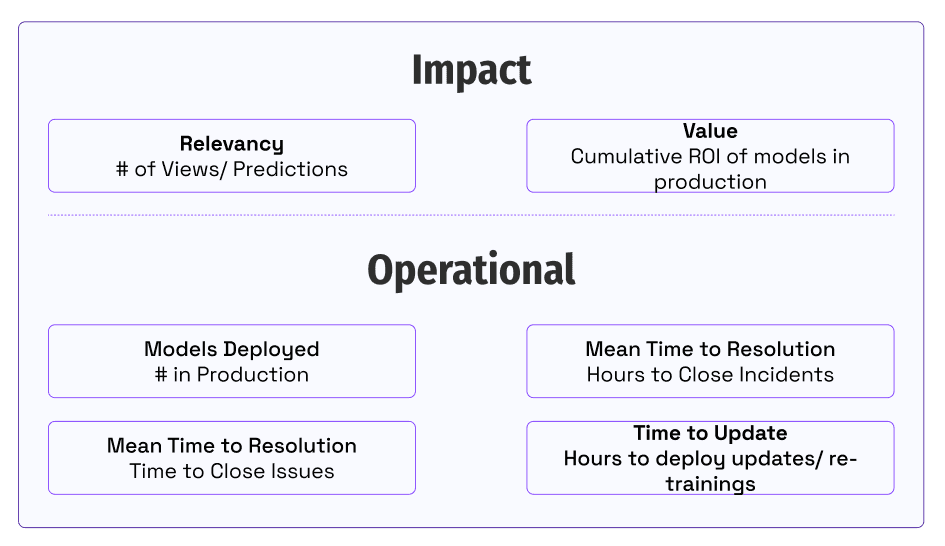
Un giorno, un dirigente aziendale entrò nel centro di comando MLOps di Ford. Abbiamo esaminato le metriche di utilizzo di un modello e abbiamo avuto una conversazione produttiva su perché l’utilizzo fosse diminuito. Questa visibilità dell’impatto e dell’adozione dei modelli è cruciale per costruire fiducia e reagire alle esigenze del business.
Una domanda fondamentale per i team che sfruttano l’AI e investono in capacità MLOps è come sappiamo se stiamo progredendo?
La chiave è allineare il nostro team su come forniamo valore ai nostri clienti e agli stakeholder del business. I team si concentrano sulla quantificazione delle prestazioni nell’impatto commerciale che forniscono e nelle metriche operative che lo abilitano. La misurazione dell’impatto cattura l’immagine di come generiamo.
Idee per cominciare:
- Come misurate il valore dei modelli in sviluppo o in produzione oggi? Come tracciate l’utilizzo e l’engagement dei vostri stakeholder del business?
- Quali sono le metriche operative o ingegneristiche per i vostri modelli in produzione oggi? Chi è responsabile del miglioramento di queste metriche? Come si dà alle persone accesso per vedere queste metriche?
- Come fanno le persone a sapere se c’è un cambiamento nel comportamento dell’utente o nell’utilizzo della soluzione? Chi risponde a queste problematiche?
Deployment & Infrastruttura
La prima sfida che il team affronta in MLOps è il deployment dei modelli in produzione. Con l’aumentare del numero di modelli, i team devono creare un processo standardizzato e una piattaforma condivisa per gestire il volume crescente. Gestire 20 modelli implementati utilizzando 20 diverse modalità può rendere le cose difficili. I team enterprise creano tipicamente risorse di infrastruttura centralizzate intorno ai modelli X. Scegliere l’architettura e l’infrastruttura giuste tra i modelli e i team può essere una battaglia in salita. Tuttavia, una volta stabilita, fornisce una solida base per costruire le capacità intorno al monitoring e alla governance.
A Ford, abbiamo creato una funzione di deployment standard utilizzando Kubernetes, Google Cloud Platform e un team per supportarli.
Lucid Link
Idee per il tuo team:
- Come centralizzerai il deployment dei modelli? Puoi creare o designare un team e risorse centralizzati per gestire gli deployments?
- Quali modalità di deployment (REST, batch, streaming, ecc.)?
- Come definirai e condividerai quelle con gli altri team?
- Quali sono gli aspetti più impegnativi o difficili per i tuoi team di modellizzazione da superare per ottenere un modello in produzione? Come può essere progettato il sistema di deployment centralizzato per mitigare questi problemi?
Monitoraggio
Un aspetto unico e impegnativo del machine learning è la capacità dei modelli di derivare e cambiare in produzione. Il monitoraggio è fondamentale per creare fiducia con gli stakeholder nell’utilizzo dei modelli. Le regole del machine learning di Google affermano di “praticare un’igiene di alerting adeguata, come rendere gli alert attuabili”. Ciò richiede che i team definiscano le aree da monitorare e come generare questi alert. Una parte impegnativa diventa rendere questi alert attuabili. Deve essere stabilito un processo per indagare e mitigare i problemi in produzione.

Presso Ford, il Model Operations Center è il punto centralizzato con schermi pieni di informazioni e dati per capire se i modelli stanno ottenendo ciò che ci aspettiamo in tempo quasi reale.
Ecco un esempio semplificato di una dashboard che cerca l’utilizzo o il conteggio dei record che scende al di sotto di una soglia predefinita.
Metriche di monitoraggio
Ecco le metriche di monitoraggio da considerare per i tuoi modelli:
- Latency: Tempo per restituire le previsioni (ad esempio, il tempo di elaborazione batch per 100 record).
- Prestazioni statistiche: la capacità di un modello di fare previsioni corrette o vicine date un set di dati di test (ad esempio, Mean Squared Error, F2, ecc.)
- Qualità dei dati: quantificazione della completezza, accuratezza, validità e tempestività dei dati di previsione o di formazione (ad esempio, % di record di previsione che mancano di una caratteristica).
- Data Drift: cambiamenti nella distribuzione dei dati nel tempo (ad esempio, cambiamenti di illuminazione per un modello di visione artificiale).
- Utilizzo del modello: frequenza con cui le previsioni del modello vengono utilizzate per risolvere problemi aziendali o utente (ad esempio, # di previsioni per il modello implementato come endpoint REST).
Idee per il tuo team:
- Come dovrebbero essere monitorati tutti i modelli?
- Quali metriche devono essere incluse con ogni modello?
- C’è uno strumento o un framework standard per generare le metriche?
- Come gestiamo gli alert e i problemi di monitoraggio?
Governance
L’innovazione crea intrinsecamente rischio, soprattutto nell’ambiente aziendale. Pertanto, guidare con successo l’innovazione richiede la progettazione di controlli nei sistemi per mitigare il rischio. Essere proattivi può risparmiare molti mal di testa e tempo. I team di MLOps dovrebbero prevedere e istruire proattivamente gli stakeholder sui rischi e su come mitigarli.
Sviluppare un approccio proattivo alla governance aiuta ad evitare di reagire alle esigenze del business. Due elementi chiave della strategia sono il controllo dell’accesso ai dati sensibili e la cattura della linea di discendenza e dei metadati per la visibilità e l’audit.
La governance offre grandi opportunità per l’automazione quando i team si espandono. Aspettare i dati è un costante freno al momentum sui progetti di data science. Presso Ford, un modello determina automaticamente se un data set contiene informazioni personali identificabili con un’accuratezza del 97%. I modelli di machine learning aiutano anche con le richieste di accesso e hanno ridotto i tempi di elaborazione da settimane a minuti nel 90% dei casi.
L’altro aspetto è il tracciamento dei metadati durante il ciclo di vita del modello. Scalare il machine learning richiede di scalare la fiducia nei modelli stessi. MLOps su larga scala richiede qualità, sicurezza e controllo integrati per evitare problemi e bias in produzione.
I team possono essere bloccati nella teoria e nelle opinioni intorno alla governance. Il miglior corso di azione è iniziare con un chiaro accesso e controllo sull’accesso degli utenti.
Da lì, la cattura dei metadati e l’automazione sono fondamentali. La tabella di seguito illustra le aree per la raccolta dei metadati. Dove possibile, sfruttare i pipeline o altri sistemi di automazione per catturare automaticamente queste informazioni al fine di evitare l’elaborazione manuale e le incongruenze.
Metadati da raccogliere
Ecco gli elementi da raccogliere per ogni modello:
- Versione/ Artefatto di modello addestrato: identificatore univoco dell’artefatto di modello addestrato.
- Dati di addestramento- Dati utilizzati per creare l’artefatto di modello addestrato.
- Codice di addestramento- Hash Git o link al codice sorgente per l’elaborazione.
- Dipendenze – Librerie utilizzate nell’addestramento.
- Codice di previsione – Hash Git o link al codice sorgente per l’elaborazione.
- Previsioni storiche – Conservare le inferenze per scopi di audit.
Idee per il tuo team:
- Quali problemi abbiamo riscontrato in tutti i progetti?
- Quali problemi stanno riscontrando o che preoccupano i nostri stakeholder aziendali?
- Come gestiamo le richieste di accesso ai dati?
- Chi le approva?
- Ci sono opportunità di automazione?
- Quali vulnerabilità creano le nostre pipeline o implementazioni di modelli?
- Quali parti dei metadati dobbiamo raccogliere?
- Come vengono archiviati e resi disponibili?
Evangelizzare MLOps
Molti team tecnici cadono nella trappola del pensiero: “se lo costruiamo, verranno”. Risolvere il problema richiede di condividere e sostenere la soluzione per aumentare l’impatto organizzativo. I team MLOps devono condividere le migliori pratiche e come risolvere i problemi unici degli strumenti, dei dati, dei modelli e degli stakeholder dell’organizzazione.
Chiunque nel team MLOps può essere un evangelista collaborando con gli stakeholder aziendali per mostrare le storie di successo. Mostrare esempi della propria organizzazione può illustrare chiaramente i benefici e le opportunità.
Le persone in tutta l’organizzazione che cercano di industrializzare l’AI hanno bisogno di educazione, documentazione e altro supporto. Le sessioni Lunch and Learn, l’onboarding e i programmi di tutoraggio sono ottimi punti di partenza. Con la crescita dell’organizzazione, programmi di apprendimento e di onboarding più formalizzati con documentazione di supporto possono accelerare la trasformazione dell’organizzazione.
Idee per il tuo team:
- Come puoi creare una comunità o apprendimenti e le migliori pratiche ricorrenti per MLOps?
- Quali sono i nuovi ruoli e le capacità che dobbiamo stabilire e condividere?
- Quali problemi abbiamo risolto che possono essere condivisi?
- Come fornite formazione o documentazione per condividere le migliori pratiche e le storie di successo con altri team?
- Come possiamo creare programmi di apprendimento o checklist per i data scientist, i data engineer e gli stakeholder aziendali per imparare a lavorare con i modelli AI?
Iniziare
I team e i leader di MLOps affrontano una montagna di opportunità equilibrando le pressanti esigenze di industrializzare i modelli. Ogni organizzazione affronta sfide diverse, date dai propri dati, modelli e tecnologie. Se MLOps fosse facile, probabilmente non ci piacerebbe lavorare sul problema.
La sfida è sempre la prioritizzazione.
Speriamo che questa guida abbia contribuito a generare nuove idee e aree da esplorare per il tuo team. Il primo passo è generare una grande lista di opportunità per il tuo team nel 2023. Poi, in base a ciò che avrà il maggior impatto sui tuoi clienti, prioritizzale senza pietà. I team possono anche definire e misurare il loro progresso di maturità rispetto ai benchmark emergenti. Questa guida di Google può fornire un framework e le tappe di maturità per il tuo team.
Idee per il tuo team:
- Quali sono le maggiori opportunità per avanzare nella nostra maturità o sofisticazione con MLOps?
- Come catturiamo e monitoriamo il nostro progresso sui progetti che avanzano la maturità?
- Generare una lista di attività per questa guida e per il tuo team. Priorità in base al tempo di implementazione e al beneficio atteso. Crea una roadmap.
Riferimenti
- https://www2.deloitte.com/content/dam/insights/articles/7022_TT-MLOps-industrialized-AI/DI_2021-TT-MLOps-industrialized-AI.pdf
- https://proceedings.neurips.cc/paper/2015/file/86df7dcfd896fcaf2674f757a2463eba-Paper.pdf
- https://developers.google.com/machine-learning/guides/rules-of-ml
- https://cloud.google.com/architecture/mlops-continuous-delivery-and-automation-pipelines-in-machine-learning
Mike Caravetta ha fornito centinaia di milioni di dollari in valore aziendale attraverso l’analisi. Al momento guida la sfida di scalare MLOps nella riduzione della complessità nel settore automobilistico presso Ford. Brendan Kelly, co-fondatore di AlignAI, ha aiutato decine di organizzazioni ad accelerare MLOps nei settori bancario, dei servizi finanziari, manifatturiero e assicurativo.