Svelando l’apprendimento non supervisionato
'Unveiling unsupervised learning.

Cos’è l’apprendimento non supervisionato?
Nell’apprendimento automatico, l’apprendimento non supervisionato è un paradigma che prevede l’addestramento di un algoritmo su un dataset non etichettato. Quindi non c’è supervisione o uscite etichettate.
- Guidare con i dati L’arte della narrazione con Anand S.
- Un modello di base per l’IA medica
- Cos’è un sistema di produzione in AI? Esempi, funzionamento e altro
Nell’apprendimento non supervisionato, l’obiettivo è scoprire modelli, strutture o relazioni all’interno dei dati stessi, piuttosto che prevedere o classificare basandosi su esempi etichettati. Comporta l’esplorazione della struttura intrinseca dei dati per ottenere intuizioni e dare un senso a informazioni complesse.
Questa guida ti introdurrà all’apprendimento non supervisionato. Inizieremo analizzando le differenze tra apprendimento supervisionato e non supervisionato, per gettare le basi per il resto della discussione. Successivamente, affronteremo le tecniche chiave dell’apprendimento non supervisionato e gli algoritmi popolari al loro interno.
Apprendimento supervisionato vs. non supervisionato
L’apprendimento automatico supervisionato e non supervisionato sono due approcci diversi utilizzati nel campo dell’intelligenza artificiale e dell’analisi dei dati. Ecco un breve riepilogo delle loro principali differenze:
Dati di addestramento
Nell’apprendimento supervisionato, l’algoritmo viene addestrato su un dataset etichettato, in cui i dati di input sono associati all’output desiderato corrispondente (etichette o valori target).
L’apprendimento non supervisionato, d’altra parte, prevede di lavorare con un dataset non etichettato, in cui non sono presenti etichette di output predefinite.
Obiettivo
Lo scopo degli algoritmi di apprendimento supervisionato è apprendere una relazione – un mapping – dallo spazio di input allo spazio di output. Una volta appreso il mapping, possiamo utilizzare il modello per prevedere i valori di output o l’etichetta di classe per i punti dati non visti in precedenza.
Nell’apprendimento non supervisionato, l’obiettivo è trovare modelli, strutture o relazioni all’interno dei dati, spesso per raggruppare i punti dati in cluster, per l’analisi esplorativa o per l’estrazione di caratteristiche.
Attività comuni
Classificazione (assegnazione di un’etichetta di classe – una delle molte categorie predefinite – a un punto dati precedentemente non visto) e regressione (previsione di valori continui) sono attività comuni nell’apprendimento supervisionato.
Raggruppamento (raggruppamento di punti dati simili) e riduzione della dimensionalità (riduzione del numero di caratteristiche pur preservando informazioni importanti) sono attività comuni nell’apprendimento non supervisionato. Ne parleremo più in dettaglio a breve.
Quando utilizzare
L’apprendimento supervisionato viene ampiamente utilizzato quando l’output desiderato è noto e ben definito, come il rilevamento dello spam via email, la classificazione delle immagini e la diagnosi medica.
L’apprendimento non supervisionato viene utilizzato quando c’è poca o nessuna conoscenza preliminare sui dati e l’obiettivo è scoprire modelli nascosti o ottenere intuizioni dai dati stessi.
Ecco un riepilogo delle differenze:
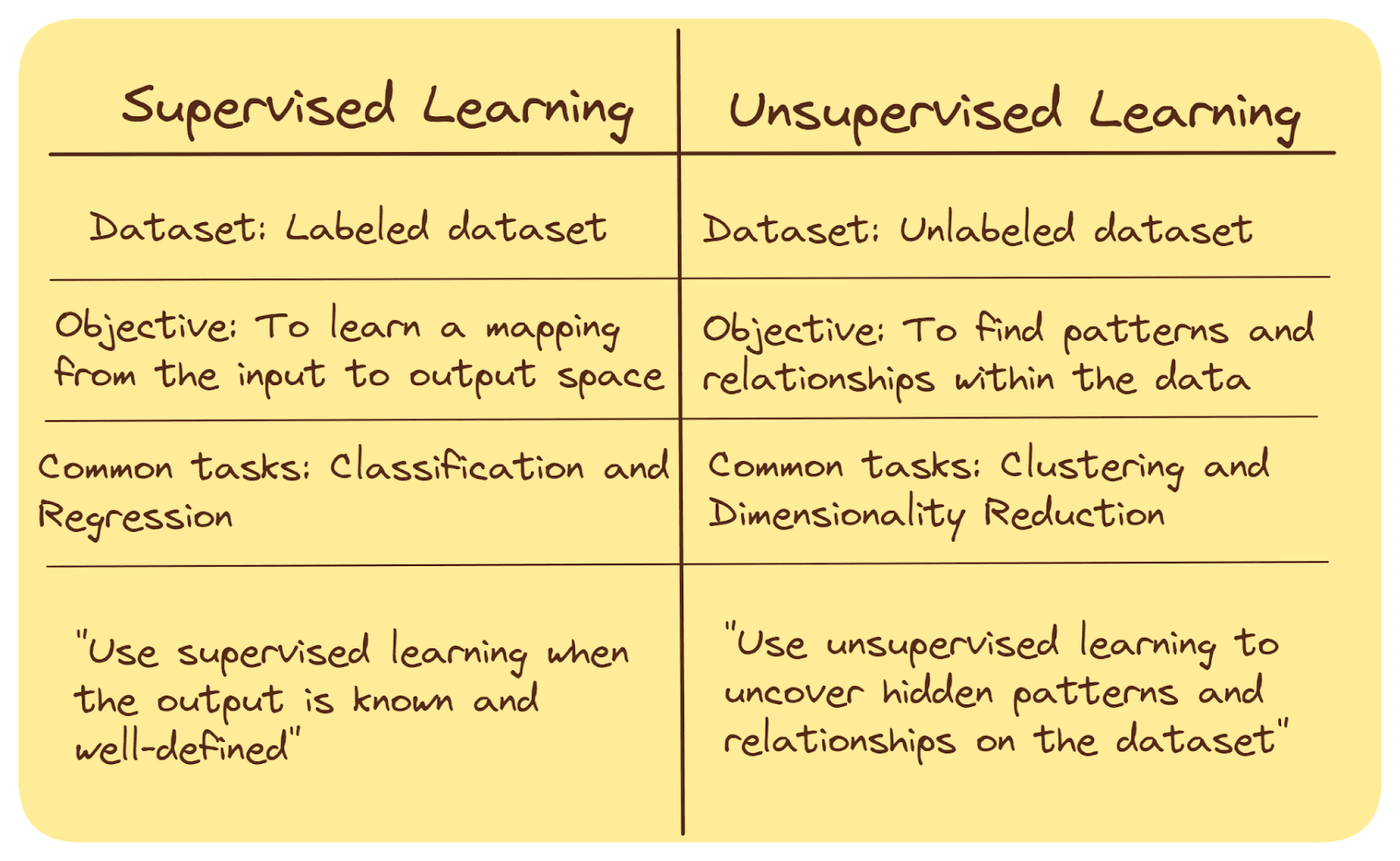
In breve: l’apprendimento supervisionato si concentra sull’apprendimento da dati etichettati per fare previsioni o classificazioni, mentre l’apprendimento non supervisionato cerca di scoprire modelli e relazioni all’interno di dati non etichettati. Entrambi gli approcci hanno le loro applicazioni – in base alla natura dei dati e al problema in questione.
Tecniche di apprendimento non supervisionato
Come discusso, nell’apprendimento non supervisionato, abbiamo i dati di input e l’obiettivo è trovare modelli o rappresentazioni significative all’interno di quei dati. Gli algoritmi di apprendimento non supervisionato lo fanno identificando similarità, differenze e relazioni tra i punti dati senza disporre di categorie o etichette predefinite.
In questa discussione, esamineremo le due principali tecniche di apprendimento non supervisionato:
- Raggruppamento
- Riduzione della dimensionalità
Cos’è il raggruppamento?
Il clustering consiste nel raggruppare insieme punti dati simili in cluster basati su una misura di similarità. L’algoritmo mira a trovare gruppi o categorie naturali all’interno dei dati, in cui i punti dati nello stesso cluster sono più simili tra loro rispetto a quelli in altri cluster.
Una volta che abbiamo raggruppato il dataset in diversi cluster, possiamo essenzialmente etichettarli. E se necessario, possiamo eseguire l’apprendimento supervisionato sul dataset clusterizzato.
Cos’è la riduzione della dimensionalità?
La riduzione della dimensionalità si riferisce alle tecniche che riducono il numero di caratteristiche – dimensioni – nei dati conservando informazioni importanti. I dati ad alta dimensionalità possono essere complessi e difficili da gestire, quindi la riduzione della dimensionalità aiuta a semplificare i dati per l’analisi.
Sia il clustering che la riduzione della dimensionalità sono potenti tecniche nell’apprendimento non supervisionato, fornendo preziosi insight e semplificando dati complessi per ulteriori analisi o modellazione.
Nel resto dell’articolo, esamineremo importanti algoritmi di clustering e riduzione della dimensionalità.
Algoritmi di clustering: una panoramica
Come discusso, il clustering è una tecnica fondamentale nell’apprendimento non supervisionato che consiste nel raggruppare insieme punti dati simili in cluster, dove i punti dati nello stesso cluster sono più simili tra loro rispetto a quelli in altri cluster. Il clustering aiuta a identificare divisioni naturali nei dati, che possono fornire insight su modelli e relazioni.
Ci sono vari algoritmi utilizzati per il clustering, ognuno con il proprio approccio e caratteristiche:
Clustering K-Means
Il clustering K-Means è un algoritmo semplice, robusto e comunemente utilizzato. Partiziona i dati in un numero predefinito di cluster (K) aggiornando iterativamente i centroidi dei cluster in base alla media dei punti dati all’interno di ciascun cluster.
Raffina iterativamente gli assegnamenti dei cluster fino alla convergenza.
Ecco come funziona l’algoritmo di clustering K-Means:
- Inizializza i centroidi dei K cluster.
- Assegna ogni punto dati – in base alla metrica di distanza scelta – al centroide di cluster più vicino.
- Aggiorna i centroidi calcolando la media dei punti dati in ciascun cluster.
- Ripeti i passaggi 2 e 3 fino alla convergenza o a un numero definito di iterazioni.
Clustering Gerarchico
Il clustering gerarchico crea una struttura a forma di albero – un dendrogramma – di punti dati, catturando similarità a più livelli di granularità. L’algoritmo di clustering agglomerativo è l’algoritmo di clustering gerarchico più comunemente utilizzato. Parte dai singoli punti dati come cluster separati e li unisce gradualmente in base a un criterio di collegamento, come la distanza o la similarità.
Ecco come funziona l’algoritmo di clustering agglomerativo:
- Inizia con `n` cluster: ogni punto dati come il proprio cluster.
- Unisci i punti dati/cluster più vicini in un cluster più grande.
- Ripeti il passaggio 2 fino a quando rimane un singolo cluster o si raggiunge un numero definito di cluster.
- Il risultato può essere interpretato con l’aiuto di un dendrogramma.
Density-Based Spatial Clustering of Applications with Noise (DBSCAN)
DBSCAN identifica cluster in base alla densità dei punti dati in un intorno. Può trovare cluster di forma arbitraria e può anche identificare punti di rumore e rilevare outlier.
L’algoritmo prevede le seguenti fasi (semplificate per includere i passaggi chiave):
- Seleziona un punto dati e trova i suoi vicini entro un raggio specificato.
- Se il punto ha vicini sufficienti, espandi il cluster includendo i vicini dei suoi vicini.
- Ripeti per tutti i punti, formando cluster collegati dalla densità.
Algoritmi di riduzione della dimensionalità: una panoramica
La riduzione della dimensionalità è il processo di riduzione del numero di caratteristiche (dimensioni) in un dataset mantenendo informazioni essenziali. I dati ad alta dimensionalità possono essere complessi, computazionalmente costosi e soggetti all’overfitting. Gli algoritmi di riduzione della dimensionalità aiutano a semplificare la rappresentazione e la visualizzazione dei dati.
Analisi delle componenti principali (PCA)
L’Analisi delle Componenti Principali, o PCA, trasforma i dati in un nuovo sistema di coordinate per massimizzare la varianza lungo le componenti principali. Riduce le dimensioni dei dati preservando il più possibile la varianza.
Ecco come puoi eseguire la PCA per la riduzione della dimensionalità:
- Calcolare la matrice di covarianza dei dati di input.
- Eseguire la decomposizione dei valori e dei vettori propri sulla matrice di covarianza.
- Ordinare i vettori propri per valori propri in ordine decrescente.
- Proiettare i dati sui vettori propri per creare una rappresentazione a dimensione inferiore.
Incastro Stocastico dei Vicini Distribuiti in modo t (t-SNE)
La prima volta che ho usato il t-SNE è stato per visualizzare le rappresentazioni delle parole. Il t-SNE viene utilizzato per la visualizzazione riducendo i dati ad alta dimensionalità a una rappresentazione a dimensione inferiore, mantenendo le similarità locali tra coppie di dati.
Ecco come funziona il t-SNE:
- Costruire distribuzioni di probabilità per misurare le similarità tra coppie di punti dati nello spazio ad alta e bassa dimensionalità.
- Minimizzare la divergenza tra queste distribuzioni utilizzando la discesa del gradiente. Spostare iterativamente i punti dati nello spazio a bassa dimensionalità, regolando le loro posizioni per minimizzare la funzione di costo.
Inoltre, ci sono architetture di apprendimento profondo come gli autoencoder che possono essere utilizzati per la riduzione della dimensionalità. Gli autoencoder sono reti neurali progettate per codificare e decodificare i dati, imparando efficacemente una rappresentazione compressa dei dati di input.
Alcune Applicazioni dell’Apprendimento Non Supervisionato
Esploriamo alcune applicazioni dell’apprendimento non supervisionato. Ecco alcuni esempi:
Segmentazione dei Clienti
Nel marketing, le aziende utilizzano l’apprendimento non supervisionato per suddividere la propria base di clienti in gruppi con comportamenti e preferenze simili. Ciò aiuta a personalizzare strategie di marketing, campagne e offerte di prodotti. Ad esempio, i rivenditori categorizzano i clienti in gruppi come “acquirenti a basso costo”, “acquirenti di lusso” e “acquirenti occasionali”.
Raggruppamento dei Documenti
Puoi eseguire un algoritmo di clustering su un corpus di documenti. Ciò aiuta a raggruppare insieme documenti simili, facilitando l’organizzazione, la ricerca e il recupero dei documenti.
Rilevamento delle Anomalie
L’apprendimento non supervisionato può essere utilizzato per identificare modelli rari e insoliti, ovvero anomalie, nei dati. Il rilevamento delle anomalie ha applicazioni nella rilevazione delle frodi e nella sicurezza delle reti per individuare comportamenti insoliti. Ad esempio, identificare transazioni fraudolente con carte di credito identificando modelli di spesa insoliti è un esempio pratico.
Compressione delle Immagini
Il clustering può essere utilizzato per la compressione delle immagini, trasformando le immagini da uno spazio di colore ad alta dimensionalità a uno spazio di colore molto più basso. Ciò riduce la dimensione di archiviazione e trasmissione dell’immagine rappresentando regioni di pixel simili con un solo centroide.
Analisi delle Reti Sociali
Puoi analizzare i dati delle reti sociali – basati sulle interazioni degli utenti – per scoprire comunità, influencer e modelli di interazione.
Topic Modeling
Nel processing del linguaggio naturale, il task di topic modeling viene utilizzato per estrarre argomenti da una collezione di documenti di testo. Ciò aiuta a categorizzare e comprendere i principali temi – argomenti – all’interno di un ampio corpus di testo.
Supponiamo di avere un corpus di articoli di notizie e non conosciamo i documenti e le relative categorie in anticipo. Possiamo quindi eseguire il topic modeling sulla collezione di articoli di notizie per identificare argomenti come politica, tecnologia e intrattenimento.
Analisi dei Dati Genomici
L’apprendimento non supervisionato ha anche applicazioni nell’analisi dei dati biomedici e genomici. Esempi includono il clustering dei geni in base ai loro pattern di espressione per scoprire potenziali associazioni con specifiche malattie.
Conclusione
Spero che questo articolo ti abbia aiutato a comprendere le basi dell’apprendimento non supervisionato. La prossima volta che lavorerai con un dataset del mondo reale, cerca di capire il problema di apprendimento in questione. E cerca di valutare se può essere modellato come un problema di apprendimento supervisionato o non supervisionato.
Se stai lavorando con un dataset con caratteristiche ad alta dimensionalità, prova ad applicare la riduzione della dimensionalità prima di costruire il modello di machine learning. Continua a imparare! Bala Priya C è una sviluppatrice e scrittrice tecnica proveniente dall’India. Le piace lavorare all’intersezione tra matematica, programmazione, data science e creazione di contenuti. Le sue aree di interesse e competenza includono DevOps, data science e elaborazione del linguaggio naturale. Ama leggere, scrivere, programmare e bere caffè! Attualmente, sta lavorando per imparare e condividere le sue conoscenze con la comunità degli sviluppatori scrivendo tutorial, guide pratiche, articoli di opinione e altro ancora.





