Tecniche di Apprendimento Ensemble Una Guida con Random Forest in Python
Guida all'Apprendimento Ensemble con Random Forest in Python
I modelli di apprendimento automatico sono diventati un componente indispensabile nella presa di decisioni in diverse industrie, ma spesso incontrano difficoltà nel gestire set di dati rumorosi o diversificati. Ecco dove entra in gioco l’apprendimento ensemble.
Questo articolo svelerà i misteri dell’apprendimento ensemble e ti presenterà il potente algoritmo dei random forest. Che tu sia un data scientist che cerca di perfezionare le proprie competenze o uno sviluppatore alla ricerca di approfondimenti pratici sulla costruzione di modelli di apprendimento automatico robusti, questo articolo è adatto a tutti!
Alla fine di questo articolo, acquisirai una conoscenza approfondita dell’apprendimento ensemble e di come funzionano i random forest in Python. Quindi, che tu sia un data scientist esperto o semplicemente curioso di ampliare le tue competenze nel machine learning, unisciti a noi in questa avventura e migliora la tua esperienza nel machine learning!
- Binny Gill, Fondatore e CEO di Kognitos – Serie di interviste
- Top 10 Aziende di Data Science negli Stati Uniti
- Possono i grandi modelli di linguaggio autovalutarsi per la sicurezza? Incontra RAIN un nuovo metodo di inferenza che trasforma l’allineamento e la difesa dell’IA senza riaffinamento
1. Cos’è l’apprendimento ensemble?
L’apprendimento ensemble è un approccio di apprendimento automatico in cui le previsioni di più modelli deboli vengono combinate tra loro per ottenere previsioni più forti. Il concetto alla base dell’apprendimento ensemble è ridurre il bias e gli errori dei singoli modelli sfruttando il potere predittivo di ciascun modello.
Per fare un esempio migliore, immagina di aver visto un animale di cui non sai a quale specie appartenga. Invece di chiedere a un solo esperto, ne chiedi dieci e prendi il voto della maggioranza di loro. Questo è noto come “voto duro”.
Il “voto duro” tiene conto delle previsioni di classe di ciascun classificatore e classifica un input in base ai voti massimi per una determinata classe. D’altra parte, il “voto morbido” tiene conto delle previsioni di probabilità per ciascuna classe di ciascun classificatore e classifica un input nella classe con la massima probabilità basata sulla media delle probabilità (calcolata sulle probabilità del classificatore) per quella classe.
2. Quando utilizzare l’apprendimento ensemble?
L’apprendimento ensemble viene sempre utilizzato per migliorare le prestazioni del modello, che includono il miglioramento dell’accuratezza di classificazione e la riduzione dell’errore medio assoluto per i modelli di regressione. Inoltre, gli apprendisti ensemble producono sempre un modello più stabile. Gli apprendisti ensemble funzionano al meglio quando i modelli non sono correlati, in modo che ogni modello possa imparare qualcosa di unico e lavorare per migliorare le prestazioni complessive.
3. Strategie di apprendimento ensemble
Sebbene l’apprendimento ensemble possa essere applicato in molti modi, quando si tratta di applicarlo nella pratica ci sono tre strategie che hanno guadagnato molta popolarità grazie alla loro semplice implementazione e utilizzo. Queste tre strategie sono:
- Bagging: Bagging, abbreviazione di bootstrap aggregation, è una strategia di apprendimento ensemble in cui i modelli vengono addestrati utilizzando campioni casuali del set di dati.
- Stacking: Stacking, abbreviazione di stacked generalization, è una strategia di apprendimento ensemble in cui addestriamo un modello per combinare più modelli addestrati sui nostri dati.
- Boosting: Boosting è una tecnica di apprendimento ensemble che si concentra sulla selezione dei dati classificati erroneamente per addestrare i modelli.
Approfondiamo ciascuna di queste strategie e vediamo come possiamo utilizzare Python per addestrare questi modelli sul nostro set di dati.
4. Apprendimento ensemble con Bagging
Il Bagging prende campioni casuali dei dati e utilizza algoritmi di apprendimento e la media per trovare le probabilità di bagging, conosciute anche come bootstrap aggregating; aggrega i risultati di più modelli per ottenere un risultato generale.
Questo approccio prevede:
- Suddividere l’insieme di dati originale in più sottoinsiemi con sostituzione.
- Sviluppare modelli di base per ciascuno di questi sottoinsiemi.
- Eseguire tutti i modelli contemporaneamente prima di eseguire tutte le previsioni per ottenere le previsioni finali.
Scikit-learn ci offre la possibilità di implementare sia un BaggingClassifier che un BaggingRegressor. Un BaggingMetaEstimator identifica sottoinsiemi casuali di un set di dati originale per adattare ciascun modello di base, quindi aggrega le previsioni dei singoli modelli di base, sia tramite voto che tramite media, in una previsione finale. Questo metodo riduce la varianza randomizzando il processo costruttivo.
Facciamo un esempio in cui utilizziamo l’estimatore di bagging utilizzando scikit-learn:
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
bagging = BaggingClassifier(base_estimator=DecisionTreeClassifier(),n_estimators=10, max_samples=0.5, max_features=0.5)
Il classificatore bagging tiene conto di diversi parametri:
- base_estimator: Il modello di base utilizzato nell’approccio bagging. Qui utilizziamo il classificatore ad albero di decisione.
- n_estimators: Il numero di stimatori che utilizzeremo nell’approccio bagging.
- max_samples: Il numero di campioni che verranno estratti dal set di addestramento per ogni stimatore di base.
- max_features: Il numero di caratteristiche che verranno utilizzate per addestrare ogni stimatore di base.
Ora adatteremo questo classificatore al set di addestramento e lo valuteremo.
bagging.fit(X_train, y_train)
bagging.score(X_test,y_test)
Possiamo fare lo stesso per compiti di regressione, la differenza sarà che useremo invece stimatori di regressione.
from sklearn.ensemble import BaggingRegressor
bagging = BaggingRegressor(DecisionTreeRegressor())
bagging.fit(X_train, y_train)
model.score(X_test,y_test)
5. Apprendimento di insieme tramite stacking
Lo stacking è una tecnica per combinare più stimatori al fine di ridurre i loro bias e produrre previsioni accurate. Le previsioni di ogni stimatore vengono quindi combinate e alimentate in un meta-modello di previsione finale addestrato tramite cross-validation; lo stacking può essere applicato sia a problemi di classificazione che di regressione.
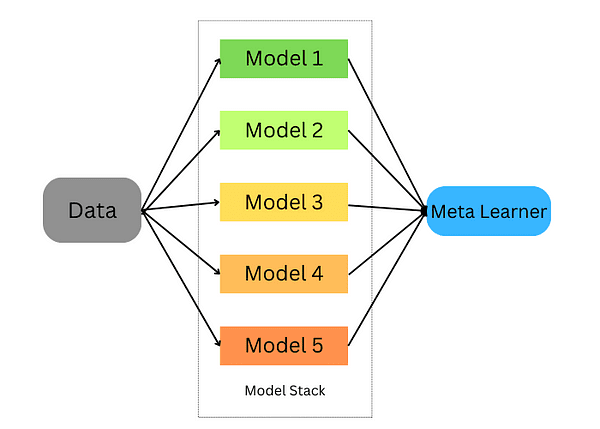
Lo stacking avviene nelle seguenti fasi:
- Dividi i dati in un set di addestramento e un set di convalida
- Dividi il set di addestramento in K fold
- Addestra un modello di base su K-1 fold e fai previsioni sul K-esimo fold
- Ripeti fino a quando hai una previsione per ogni fold
- Adatta il modello di base all’intero set di addestramento
- Utilizza il modello per fare previsioni sul set di test
- Ripeti i passaggi 3-6 per altri modelli di base
- Utilizza le previsioni dal set di test come caratteristiche di un nuovo modello (il meta-modello)
- Fai previsioni finali sul set di test utilizzando il meta-modello
In questo esempio di seguito, iniziamo creando due classificatori di base (RandomForestClassifier e GradientBoostingClassifier) e un meta-classificatore (LogisticRegression) e utilizziamo la cross-validation K-fold per utilizzare le previsioni di questi classificatori sui dati di addestramento (set di dati iris) come input per il nostro meta-classificatore (LogisticRegression).
Dopo aver utilizzato la cross-validation K-fold per fare previsioni dai classificatori di base sui set di dati di test come input per il nostro meta-classificatore, facciamo previsioni sui set di test utilizzando entrambi i set insieme e valutiamo la loro accuratezza rispetto alle loro controparti insieme impilate.
# Carica il set di dati
data = load_iris()
X, y = data.data, data.target
# Dividi i dati in set di addestramento e test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Definisci i classificatori di base
base_classifiers = [
RandomForestClassifier(n_estimators=100, random_state=42),
GradientBoostingClassifier(n_estimators=100, random_state=42)
]
# Definisci un meta-classificatore
meta_classifier = LogisticRegression()
# Crea un array per contenere le previsioni dei classificatori di base
base_classifier_predictions = np.zeros((len(X_train), len(base_classifiers)))
# Esegui lo stacking utilizzando la cross-validation K-fold
kf = KFold(n_splits=5, shuffle=True, random_state=42)
for train_index, val_index in kf.split(X_train):
train_fold, val_fold = X_train[train_index], X_train[val_index]
train_target, val_target = y_train[train_index], y_train[val_index]
for i, clf in enumerate(base_classifiers):
cloned_clf = clone(clf)
cloned_clf.fit(train_fold, train_target)
base_classifier_predictions[val_index, i] = cloned_clf.predict(val_fold)
# Adatta il meta-classificatore alle previsioni dei classificatori di base
meta_classifier.fit(base_classifier_predictions, y_train)
# Fai previsioni utilizzando l'insieme impilato
stacked_predictions = np.zeros((len(X_test), len(base_classifiers)))
for i, clf in enumerate(base_classifiers):
stacked_predictions[:, i] = clf.predict(X_test)
# Fai previsioni finali utilizzando il meta-classificatore
final_predictions = meta_classifier.predict(stacked_predictions)
# Valuta le prestazioni dell'insieme impilato
accuracy = accuracy_score(y_test, final_predictions)
print(f"Accuratezza dell'insieme impilato: {accuracy:.2f}")
6. Apprendimento di Boosting Ensemble
Il boosting è una tecnica di apprendimento automatico che riduce il bias e la varianza trasformando i weak learners in strong learners. Questi weak learners vengono applicati in sequenza al dataset; prima creando un modello iniziale e adattandolo all’insieme di addestramento. Una volta identificati gli errori del primo modello, viene progettato un altro modello per correggerli.
Esistono algoritmi e implementazioni popolari per le tecniche di apprendimento di boosting ensemble. Esploriamo i più famosi.
6.1. AdaBoost
AdaBoost è una tecnica efficace di apprendimento di ensemble, che utilizza i weak learners in modo sequenziale per scopi di addestramento. Ogni iterazione dà priorità alle previsioni errate riducendo il peso assegnato alle istanze correttamente previste; questo enfasi strategica sulle osservazioni difficili spinge AdaBoost a diventare sempre più accurato nel tempo, con la sua previsione finale determinata dall’aggregazione di voti maggioritari o dalla somma pesata dei suoi weak learners.
AdaBoost è un algoritmo versatile adatto sia per compiti di regressione che di classificazione, ma qui ci concentriamo sulla sua applicazione ai problemi di classificazione utilizzando Scikit-learn. Vediamo come possiamo usarlo per compiti di classificazione nell’esempio seguente:
from sklearn.ensemble import AdaBoostClassifier
model = AdaBoostClassifier(n_estimators=100)
model.fit(X_train, y_train)
model.score(X_test,y_test)
In questo esempio, abbiamo utilizzato AdaBoostClassifier da scikit learn e impostato n_estimators su 100. Il learner predefinito è un albero decisionale e puoi cambiarlo. Inoltre, è possibile ottimizzare i parametri dell’albero decisionale.
6.2. Extreme Gradient Boosting (XGBoost)
Extreme Gradient Boosting, o più comunemente noto come XGBoost, è una delle migliori implementazioni di ensemble learners grazie ai suoi calcoli paralleli che lo rendono molto ottimizzato per l’esecuzione su un singolo computer. XGBoost è disponibile tramite il pacchetto xgboost sviluppato dalla comunità di apprendimento automatico.
import xgboost as xgb
params = {"objective":"binary:logistic",'colsample_bytree': 0.3,'learning_rate': 0.1,
'max_depth': 5, 'alpha': 10}
model = xgb.XGBClassifier(**params)
model.fit(X_train, y_train)
model.fit(X_train, y_train)
model.score(X_test,y_test)
6.3. LightGBM
LightGBM è un altro algoritmo di boosting basato sull’apprendimento degli alberi. Tuttavia, a differenza di altri algoritmi basati sugli alberi, utilizza una crescita degli alberi basata sulle foglie che lo rende convergere più rapidamente.
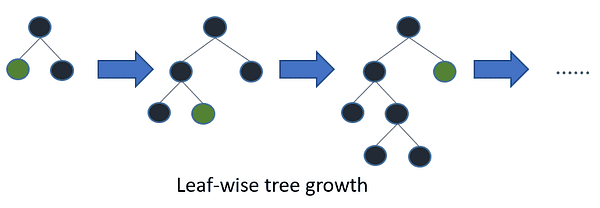
Nell’esempio seguente applicheremo LightGBM a un problema di classificazione binaria:
import lightgbm as lgb
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train)
params = {'boosting_type': 'gbdt',
'objective': 'binary',
'num_leaves': 40,
'learning_rate': 0.1,
'feature_fraction': 0.9
}
gbm = lgb.train(params,
lgb_train,
num_boost_round=200,
valid_sets=[lgb_train, lgb_eval],
valid_names=['train','valid'],
)
L’apprendimento di ensemble e le foreste casuali sono modelli di apprendimento automatico potenti che vengono sempre utilizzati dai professionisti di apprendimento automatico e dai data scientist. In questo articolo, abbiamo coperto l’intuizione di base che sta dietro di essi, quando usarli e infine abbiamo trattato gli algoritmi più popolari e come usarli in Python.
Riferimenti
- Una introduzione graduale agli algoritmi di apprendimento di ensemble
- Una guida completa all’apprendimento di ensemble: cosa devi sapere esattamente
- Una guida completa all’apprendimento di ensemble (con codici Python)
Youssef Rafaat è un ricercatore di visione artificiale e data scientist. La sua ricerca si concentra sullo sviluppo di algoritmi di visione artificiale in tempo reale per applicazioni nel settore della salute. Ha inoltre lavorato come data scientist per più di 3 anni nei settori del marketing, delle finanze e della salute.