Un’intuizione per l’AUC e il C di Harrell
Intuition for AUC and Harrell's C
Un approccio grafico

Tutti coloro che si avventurano nel campo del machine learning o della modellazione predittiva si imbattono nel concetto di test delle prestazioni del modello. I libri di testo di solito differiscono solo per ciò che il lettore impara per primo: la regressione con il suo MSE (errore standard medio) o la classificazione con una pletora di indicatori di prestazione, come l’accuratezza, la sensibilità o la precisione, per citarne alcuni. Mentre il primo può essere calcolato come una semplice frazione di previsioni corrette/sbagliate ed è quindi molto intuitivo, l’area sotto la curva ROC (AUC) può essere spaventosa all’inizio. Tuttavia, è anche un parametro frequentemente utilizzato per valutare la qualità del predittore. Analizziamo prima le sue meccaniche per capire i dettagli più minuti.
Prima di tutto, comprendi l’AUC
Supponiamo di aver costruito un classificatore binario che prevede la probabilità di un campione di appartenere a una determinata classe. Il nostro set di dati di test con classi note ha prodotto i seguenti risultati, che possono essere riassunti in una matrice di confusione e riportati in dettaglio in una tabella, in cui i campioni sono stati ordinati in base alla probabilità predetta di appartenere alla classe P (positiva):
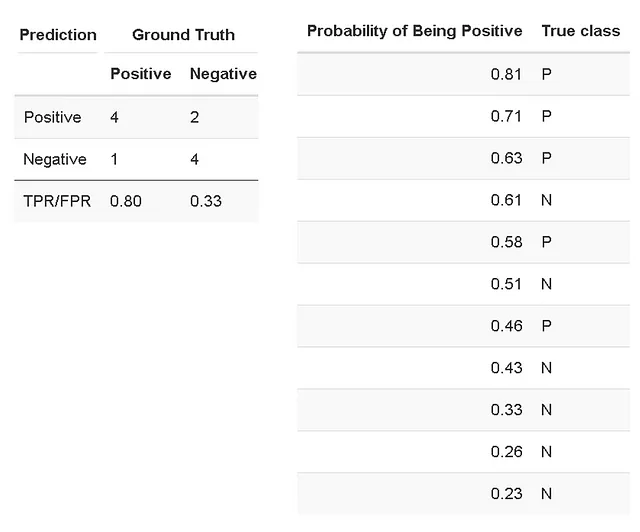
L’AUC ROC è definita come l’area sotto la curva ROC (receiver operating characteristic). La curva ROC è il grafico del tasso di veri positivi (TPR) contro il tasso di falsi positivi (FPR) [Wikipedia]. Il TPR (noto anche come sensibilità) è il rapporto tra i casi positivi correttamente identificati su tutti i casi positivi. Nel nostro caso, il TPR è calcolato come 4/5 (quattro su cinque casi sono stati classificati correttamente come positivi). L’FPR è calcolato come il rapporto tra il numero di casi negativi erroneamente categorizzati come positivi (falsi positivi) e il numero totale di casi negativi effettivi. Nel nostro caso, l’FPR è calcolato come 2/6 (due su 6 casi negativi sono stati classificati erroneamente come positivi, se impostiamo la soglia di “positività” alla probabilità di 0,5).
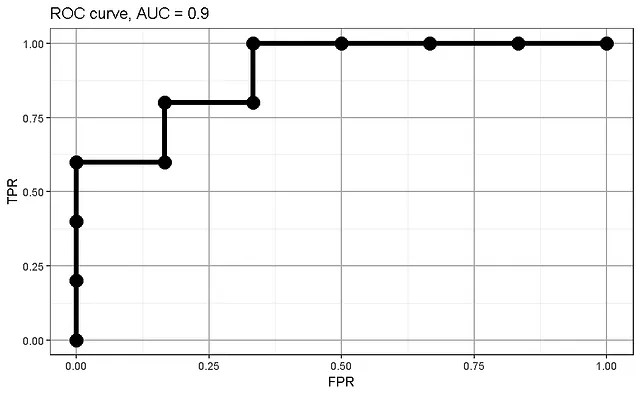
Possiamo tracciare la curva ROC utilizzando i valori di TPR e FPR e calcolare l’AUC (Area Under Curve):
- Oltre i voti Utilizzare l’IA per prevedere e spiegare le prestazioni degli studenti
- 10 Modi per Migliorare le Prestazioni dei Sistemi di Generazione Potenziata dalla Recupero
- Qualcosa di Pensieri nel LLM Prompting Una panoramica del Ragionamento Strutturato nel LLM
Da dove provengono i valori individuali di TPR/FPR per la curva AUC? A tal fine, consideriamo la nostra tabella delle probabilità e calcoliamo TPR/FPR per ogni campione, impostando la probabilità a cui consideriamo un campione come positivo come quella indicata nella tabella. Anche quando superiamo il livello usuale di 0,5, in cui i campioni vengono di solito dichiarati “negativi”, continuiamo ad assegnarli come positivi. Seguiamo questa procedura nel nostro esempio:
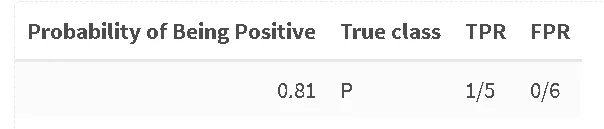
Un campione su cinque positivi è stato classificato correttamente come positivo con una soglia di 0,81, nessun campione è stato previsto come negativo. Continuiamo fino a quando non incontriamo il primo esempio negativo:
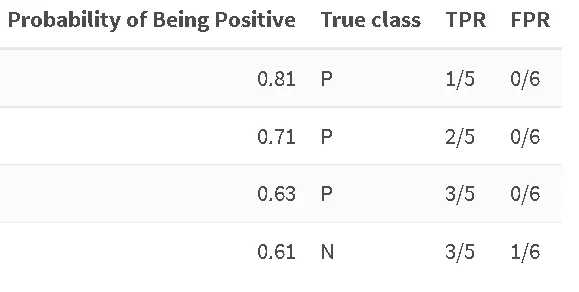
Qui, il nostro TPR si ferma al valore precedente (3 su 5 campioni positivi sono stati previsti correttamente), ma l’FPR aumenta, abbiamo erroneamente assegnato uno su sei campioni negativi alla classe positiva. Continuiamo fino alla fine:
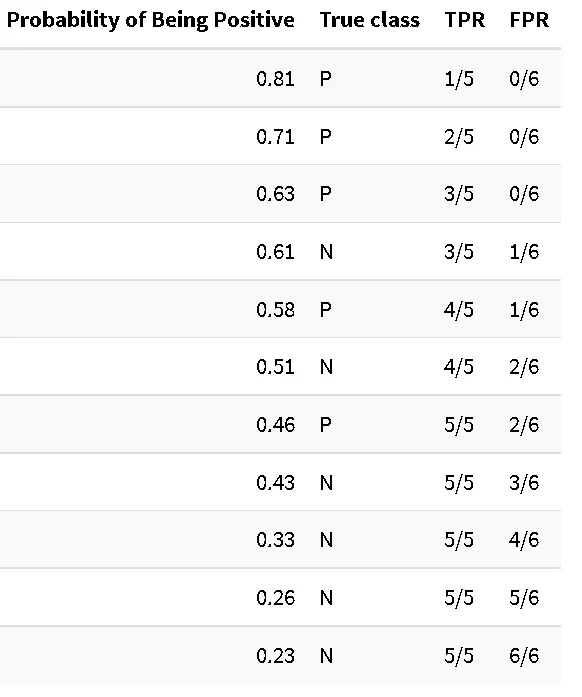
Eccola: arriviamo alla tabella completa che viene utilizzata per creare la curva ROC.
Perché l’indice di Harrell C non è altro che l’AUC
Ma cosa succede con l’indice di Harrell C (noto anche come indice di concordanza o C-index)? Consideriamo il compito specifico di prevedere la morte in caso di una particolare malattia, ad esempio il cancro. Alla fine, tutti i pazienti moriranno, indipendentemente dal cancro – un semplice classificatore binario non sarà di grande aiuto. I modelli di sopravvivenza tengono conto della durata fino all’evento (morte). Più presto si verifica l’evento, maggiore è il rischio che l’individuo incontri l’evento. Se si volesse valutare la qualità di un modello di sopravvivenza, si dovrebbe guardare all’indice di concordanza (aka Concordance, aka Harrell’s C).
Per comprendere il calcolo dell’indice di concordanza, è necessario introdurre due nuovi concetti: coppie permissibili e coppie concordanti. Le coppie permissibili sono coppie di campioni (ad esempio: pazienti) con esiti diversi durante l’osservazione, ovvero durante il periodo in cui è stato condotto l’esperimento, un paziente di tale coppia ha sperimentato l’esito, mentre l’altro è stato censurato (ovvero non ha ancora raggiunto l’esito). Queste coppie permissibili vengono quindi analizzate per verificare se l’individuo con il punteggio di rischio maggiore ha sperimentato l’evento, mentre quello censurato no. Questi casi vengono chiamati coppie concordanti.
Semplificando un po’, l’indice di concordanza viene calcolato come rapporto tra il numero di coppie concordanti e il numero di coppie permissibili (omitto il caso dei legami di rischio per semplicità). Facciamo un esempio, supponendo di aver utilizzato un modello di sopravvivenza che calcola il rischio anziché la probabilità. La tabella seguente contiene solo coppie permissibili. La colonna “Concordanza” è impostata su 1 se il paziente con il punteggio di rischio maggiore ha sperimentato l’evento (faceva parte del nostro gruppo “positivo”). L’id è semplicemente il numero di riga della tabella precedente. Presta particolare attenzione al confronto tra l’individuo 4 con il 5 o il 7.
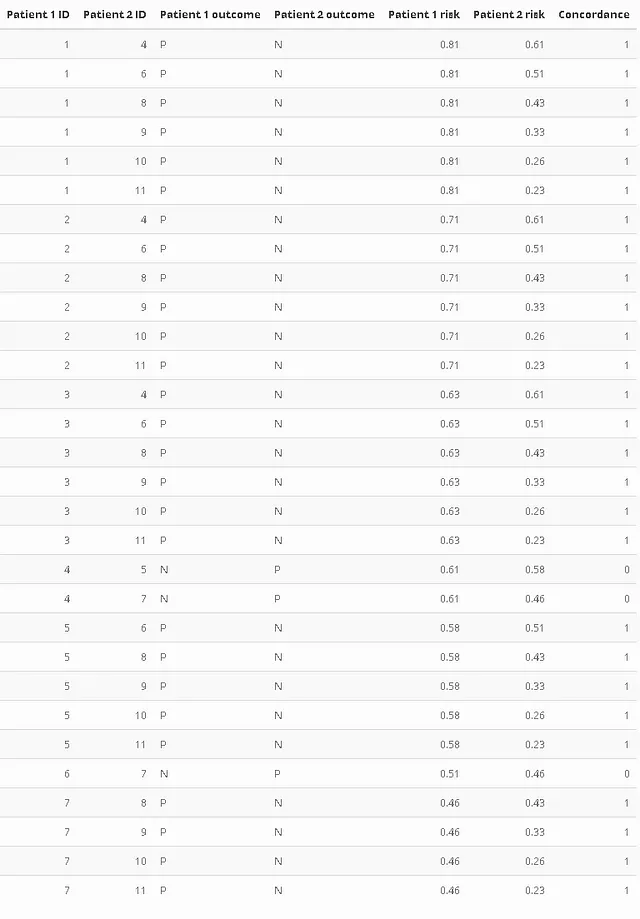
Questo ci lascia con 27 coppie concordanti su 30 permissibili. Il rapporto (l’indice semplificato di Harrell C) è C = 0,9, che ci ricorda sospettosamente l’AUC calcolata in precedenza.
Possiamo costruire una matrice di concordanza che visualizza come viene calcolata la statistica C, come suggerito da Carrington et al. Il grafico mostra i punteggi di rischio dei veri positivi rispetto ai punteggi di rischio dei veri negativi e mostra la proporzione di coppie correttamente classificate (verde) su tutte le coppie (verde + rosso) se interpretiamo ogni quadrato della griglia come la rappresentazione di un campione:
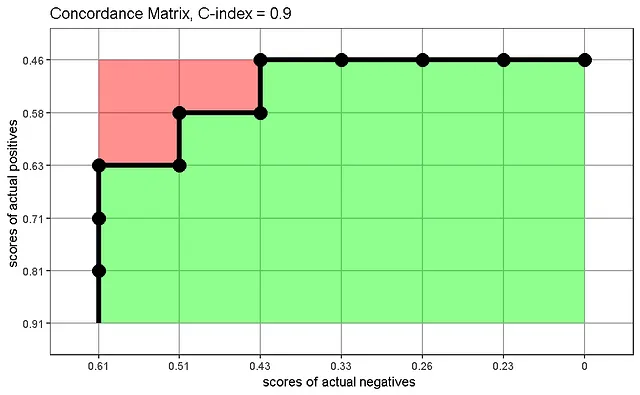
La matrice di concordanza mostra le coppie correttamente classificate in concordanza verso il basso a destra, le coppie classificate in modo errato verso l’alto a sinistra e un confine in mezzo che corrisponde esattamente alla curva ROC che abbiamo visto in precedenza.
Analizzando il processo di costruzione di una curva ROC e della matrice di concordanza, riconosciamo una somiglianza: in entrambi i casi abbiamo classificato i nostri campioni in base alla loro probabilità/punteggio di rischio e abbiamo verificato se la classifica corrispondeva alla verità. Più alziamo la soglia di probabilità per la classificazione, più otteniamo falsi positivi. Più basso è il rischio dei casi positivi effettivi, più probabile sarà che un caso negativo effettivo venga classificato erroneamente come positivo. Tracciando i nostri dati classificati di conseguenza, abbiamo ottenuto una curva con la stessa forma e area, che chiamiamo AUC o Harrell’s C, a seconda del contesto.
Spero che questo esempio abbia aiutato a sviluppare un’intuizione sia per l’AUC che per l’indice di Harrell C.
Riconoscimenti
L’idea di confrontare questi due parametri è emersa da una discussione fruttuosa durante il meetup del Gruppo di Studio Avanzato sull’Apprendimento Automatico, complimenti a Torsten!
Riferimento: Carrington, A.M., Fieguth, P.W., Qazi, H. et al. Un nuovo AUC parziale concordante e una parziale curva c per dati sbilanciati nella valutazione degli algoritmi di apprendimento automatico. BMC Med Inform Decis Mak 20, 4 (2020). https://doi.org/10.1186/s12911-019-1014-6






