Come Identificare i Dati Mancanti nei Dati a Serie Temporale
Identificazione dei Dati Mancanti nelle Serie Temporali
I dati in serie temporali, raccolti quasi ogni secondo da una molteplicità di fonti, sono spesso soggetti a diversi problemi di qualità dei dati, tra cui la mancanza di dati.
Nel contesto dei dati sequenziali, le informazioni mancanti possono verificarsi per diverse ragioni, ovvero errori che si verificano nei sistemi di acquisizione (ad esempio, sensori difettosi), errori durante il processo di trasmissione (ad esempio, connessioni di rete difettose) o errori durante la raccolta dei dati (ad esempio, errori umani durante la registrazione dei dati). Queste situazioni generano spesso valori mancanti sporadici ed espliciti nei nostri dataset, corrispondenti a piccoli vuoti nel flusso di dati raccolti.
Inoltre, le informazioni mancanti possono anche verificarsi naturalmente a causa delle caratteristiche del dominio stesso, creando vuoti più ampi nei dati. Ad esempio, una caratteristica che smette di essere raccolta per un certo periodo di tempo, generando dati mancanti non espliciti.
Indipendentemente dalla causa sottostante, avere dati mancanti nelle nostre sequenze in serie temporali è molto pregiudizievole per la previsione e la modellazione predittiva e può avere gravi conseguenze sia per singoli individui (ad esempio, valutazione errata del rischio) che per i risultati aziendali (ad esempio, decisioni aziendali sbagliate, perdita di ricavi e opportunità).
- Israele costruisce una rete di spazio aereo di droni
- Nuovo metodo rivoluzionario per addestrare chip neuromorfi
- Come l’IA sta trasformando la gestione dei servizi IT
Quando si preparano i dati per approcci di modellazione, un passaggio importante è quindi essere in grado di identificare questi modelli di informazione sconosciuta, poiché ci aiuteranno a decidere sull’approccio migliore per gestire i dati in modo efficiente e migliorarne la coerenza, sia attraverso una qualche forma di correzione dell’allineamento, interpolazione dei dati, imputazione dei dati o, in alcuni casi, eliminazione caso per caso (ovvero, omissione dei casi con valori mancanti per una caratteristica utilizzata in un’analisi specifica).
Per questo motivo, eseguire un’analisi approfondita dei dati esplorativi e del profilo dei dati è indispensabile non solo per comprendere le caratteristiche dei dati, ma anche per prendere decisioni informate su come preparare al meglio i dati per l’analisi.
In questo tutorial pratico, esploreremo come ydata-profiling può aiutarci a risolvere questi problemi con le nuove funzionalità introdotte nella nuova versione. Utilizzeremo il set di dati sulla inquinamento negli Stati Uniti, disponibile su Kaggle (Licenza DbCL v1.0), che fornisce informazioni sui pollutanti NO2, O3, SO2 e CO negli stati degli Stati Uniti.
Tutorial pratico: Profilazione del dataset sull’inquinamento negli Stati Uniti
Per iniziare il nostro tutorial, dobbiamo prima installare l’ultima versione di ydata-profiling:
pip install ydata-profiling==4.5.1Poi, possiamo caricare i dati, rimuovere le caratteristiche non necessarie e concentrarci su ciò che vogliamo investigare. Per l’esempio, ci concentreremo sul comportamento particolare delle misurazioni degli inquinanti atmosferici presso la stazione di Arizona, Maricopa, Scottsdale:
import pandas as pd
data = pd.read_csv("data/pollution_us_2000_2016.csv")
data = data.drop('Unnamed: 0', axis = 1) # rimozione dell'indice non necessario
# Seleziona i dati da Arizona, Maricopa, Scottsdale (Site Num: 3003)
data_scottsdale = data[data['Site Num'] == 3003].reset_index(drop=True)Ora siamo pronti per iniziare a profilare il nostro dataset! Ricordiamo che, per utilizzare la profilazione delle serie temporali, dobbiamo passare il parametro tsmode=True in modo che ydata-profiling possa identificare le caratteristiche dipendenti dal tempo:
# Cambia 'Data Local' in datetime
data_scottsdale['Date Local'] = pd.to_datetime(data_scottsdale['Date Local'])
# Crea il Profilo dei dati
profile_scottsdale = ProfileReport(data_scottsdale, tsmode=True, sortby="Date Local")
profile_scottsdale.to_file('profile_scottsdale.html')Panoramica delle serie temporali
Il rapporto di output sarà familiare a quello che già conosciamo, ma con un’esperienza migliorata e nuove statistiche riassuntive per i dati in serie temporali:
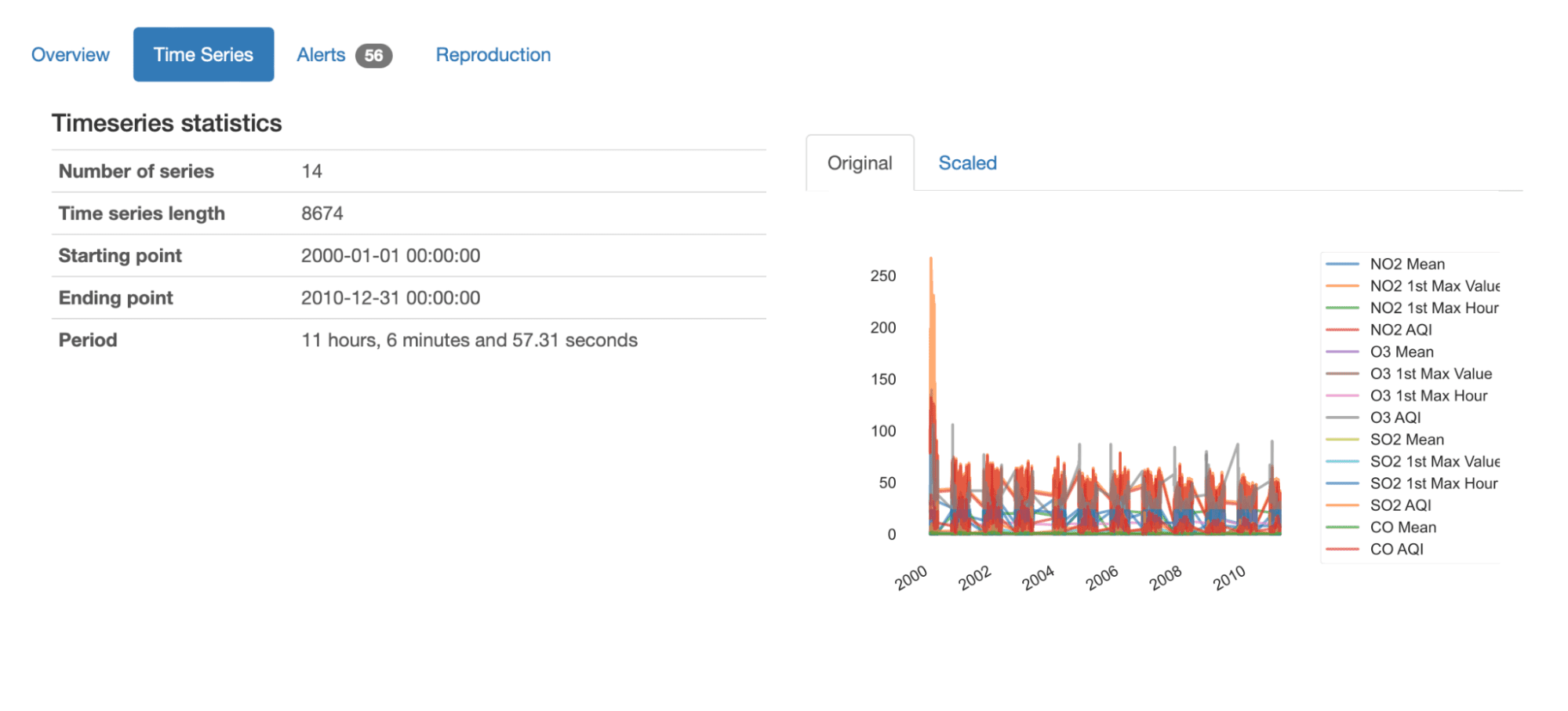
Immediatamente dall’anteprima, possiamo ottenere una comprensione generale di questo dataset guardando le statistiche riassuntive presentate:
- Contiene 14 serie temporali diverse, ciascuna con 8674 valori registrati;
- Il dataset riporta dati di 10 anni da gennaio 2000 a dicembre 2010;
- Il periodo medio delle sequenze temporali è di 11 ore e (quasi) 7 minuti. Ciò significa che in media abbiamo misurazioni ogni 11 ore.
Possiamo anche ottenere un grafico di panoramica di tutte le serie di dati, sia nei loro valori originali che scalati: possiamo facilmente comprendere la variazione complessiva delle sequenze, così come i componenti (NO2, O3, SO2, CO) e le caratteristiche (Media, 1° Valore Massimo, 1° Ora Massima, AQI) che vengono misurate.
Ispezione dei dati mancanti
Dopo aver avuto una visione generale dei dati, possiamo focalizzarci sugli aspetti specifici di ogni sequenza temporale.
Nella versione più recente di ydata-profiling, il report di profilazione è stato notevolmente migliorato con analisi dedicate per i dati di serie temporali, ovvero la segnalazione delle metriche “Time Series” e “Gap Analysis”. L’identificazione delle tendenze e dei modelli mancanti è estremamente facilitata da queste nuove funzionalità, in cui sono ora disponibili statistiche di riepilogo specifiche e visualizzazioni dettagliate.
Qualcosa che si evidenzia immediatamente è il modello irregolare che tutte le serie temporali presentano, in cui sembrano verificarsi determinati “salti” tra le misurazioni consecutive. Ciò indica la presenza di dati mancanti (“lacune” di informazioni mancanti) che dovrebbero essere studiate più attentamente. Diamo uno sguardo al S02 Media come esempio.

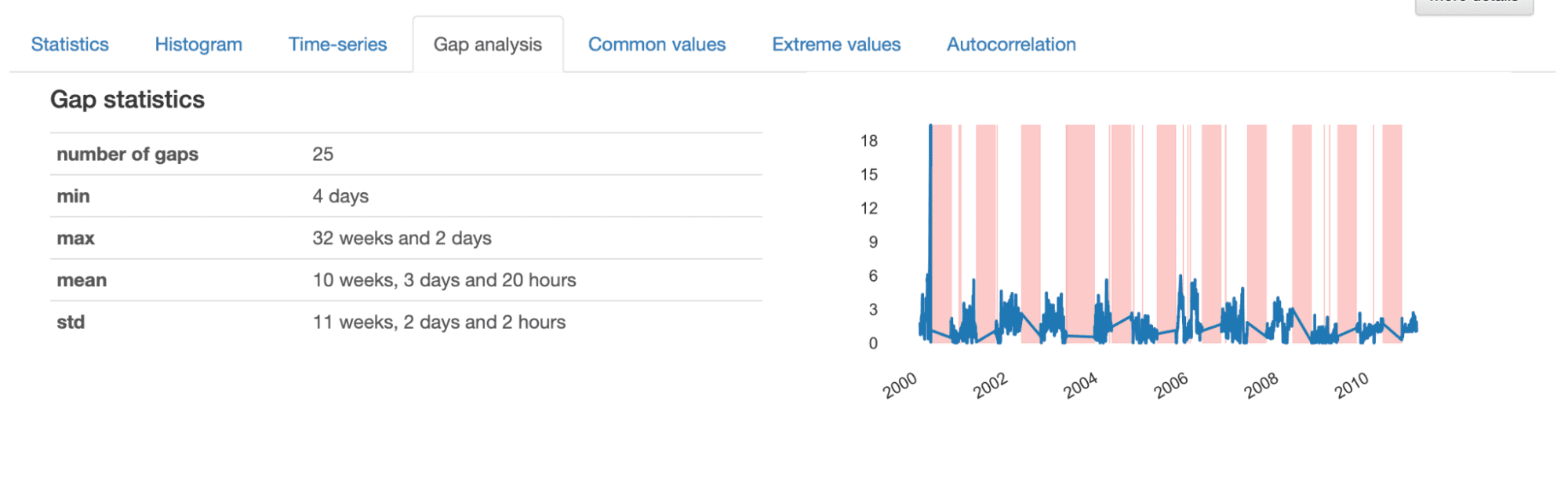
Quando esaminiamo i dettagli forniti nella Gap Analysis, otteniamo una descrizione informativa delle caratteristiche delle lacune identificate. Nel complesso, ci sono 25 lacune nella serie temporale, con una lunghezza minima di 4 giorni, una massima di 32 settimane e una media di 10 settimane.
Dalla visualizzazione presentata, notiamo lacune “casuali” rappresentate da strisce più sottili e lacune più ampie che sembrano seguire un modello ripetitivo. Ciò indica che sembra che ci siano due diversi modelli di dati mancanti nel nostro dataset.
Le lacune più piccole corrispondono a eventi sporadici che generano dati mancanti, molto probabilmente a causa di errori nel processo di acquisizione, e spesso possono essere facilmente interpolati o eliminati dal dataset. Al contrario, le lacune più ampie sono più complesse e devono essere analizzate in modo più dettagliato, poiché potrebbero rivelare un modello sottostante che deve essere affrontato in modo più approfondito.
Nel nostro esempio, se dovessimo indagare sulle lacune più ampie, scopriremmo infatti che riflettono un modello stagionale:
df = data_scottsdale.copy()
for year in df["Date Local"].dt.year.unique():
for month in range(1,13):
if ((df["Date Local"].dt.year == year) & (df["Date Local"].dt.month ==month)).sum() == 0:
print(f'L'anno {year} manca il mese {month}.')# L'anno 2000 manca il mese 4.
# L'anno 2000 manca il mese 5.
# L'anno 2000 manca il mese 6.
# L'anno 2000 manca il mese 7.
# L'anno 2000 manca il mese 8.
# (...)
# L'anno 2007 manca il mese 5.
# L'anno 2007 manca il mese 6.
# L'anno 2007 manca il mese 7.
# L'anno 2007 manca il mese 8.
# (...)
# L'anno 2010 manca il mese 5.
# L'anno 2010 manca il mese 6.
# L'anno 2010 manca il mese 7.
# L'anno 2010 manca il mese 8.Come sospettato, la serie temporale presenta alcune lacune di informazioni di grandi dimensioni che sembrano essere ripetitive, addirittura stagionali: nella maggior parte degli anni, i dati non sono stati raccolti tra maggio e agosto (mesi da 5 a 8). Questo potrebbe essere accaduto per motivi imprevedibili o decisioni aziendali note, ad esempio, legate al taglio dei costi o semplicemente legate alle variazioni stagionali degli inquinanti associate a modelli meteorologici, temperatura, umidità e condizioni atmosferiche.
Sulla base di queste scoperte, potremmo quindi indagare su perché ciò sia accaduto, se qualcosa dovrebbe essere fatto per evitarlo in futuro e come gestire i dati attualmente disponibili.
Considerazioni finali: Imputare, Eliminare, Riallineare?
In tutto questo tutorial, abbiamo visto quanto sia importante comprendere i modelli dei dati mancanti nelle serie temporali e come una profilazione efficace possa svelare i misteri dietro le lacune di informazioni mancanti. Dai settori delle telecomunicazioni, della sanità, dell’energia e delle finanze, tutti i settori che raccolgono dati di serie temporali si troveranno prima o poi di fronte a dati mancanti e dovranno decidere il modo migliore per gestirli ed estrarre tutta la conoscenza possibile da essi.
Con una profilazione completa dei dati, possiamo prendere decisioni informate ed efficienti in base alle caratteristiche dei dati a nostra disposizione:
- I vuoti di informazione possono essere causati da eventi sporadici derivanti da errori nell’acquisizione, trasmissione e raccolta dei dati. Possiamo risolvere il problema per evitare che si ripeta e interpolare o imputare i vuoti mancanti, a seconda della loro lunghezza;
- I vuoti di informazione possono anche rappresentare modelli stagionali o ripetuti. Possiamo scegliere di ristrutturare il nostro flusso di lavoro per iniziare a raccogliere le informazioni mancanti o sostituire i vuoti con informazioni esterne provenienti da altri sistemi distribuiti. Possiamo anche identificare se il processo di recupero è stato infruttuoso (magari a causa di un errore di battitura nell’ingegneria dei dati, tutti abbiamo quei giorni!).
Spero che questo tutorial abbia fatto luce su come identificare e caratterizzare correttamente i dati mancanti nei tuoi dati di serie temporali e non vedo l’ora di vedere cosa scoprirai nella tua analisi dei vuoti! Lasciami un commento se hai domande o suggerimenti o trova la Community Data-Centric AI! Fabiana Clemente è co-fondatrice e CDO di YData, unendo comprensione dei dati, causalità e privacy come suoi principali campi di lavoro e ricerca, con la missione di rendere i dati operativi per le organizzazioni. Come appassionata esperta di dati, conduce il podcast When Machine Learning Meets Privacy ed è ospite nei podcast Datacast e Privacy Please. Parla anche a conferenze come ODSC e PyData.






