Allenare un Agente a Padroneggiare il Tris Attraverso il Gioco Autonomo
Allenamento Agente Tris Autonomo
Sorprendentemente, un agente software non si stanca mai del gioco.
Ah! La scuola primaria! Questo era il momento in cui abbiamo imparato competenze preziose, come l’alfabetizzazione, l’aritmetica e il gioco del tris in modo ottimale.
Giocare a tris con un amico senza farsi scoprire dall’insegnante è un’arte. Devi passare discretamente il foglio di gioco sotto il banco dando l’impressione di essere attento alla materia. Il divertimento era probabilmente più nell’operazione sotto copertura che nel gioco stesso.
Non possiamo insegnare l’arte di evitare di farsi scoprire in classe a un agente software, ma possiamo addestrare un agente a padroneggiare il gioco?
Nel mio post precedente, abbiamo studiato un agente che impara il gioco SumTo100 attraverso l’auto-gioco. Era un gioco facile che ci ha permesso di visualizzare il valore di stato, il che ci ha aiutato a sviluppare un’intuizione su come l’agente impara il gioco. Con il tris, stiamo affrontando uno spazio di stato molto più ampio.
- Progettare città resilienti presso Arup utilizzando le capacità geospaziali di Amazon SageMaker
- Adam Ross Nelson su Confident Data Science
- Prova pratica con l’apprendimento supervisionato Regressione lineare
Puoi trovare il codice Python in questo repository. Lo script che esegue l’addestramento è learn_tictactoe.sh:
#!/bin/bashdeclare -i NUMBER_OF_GAMES=30000declare -i NUMBER_OF_EPOCHS=5export PYTHONPATH='./'python preprocessing/generate_positions_expectations.py \ --outputDirectory=./learn_tictactoe/output_tictactoe_generate_positions_expectations_level0 \ --game=tictactoe \ --numberOfGames=$NUMBER_OF_GAMES \ --gamma=0.95 \ --randomSeed=1 \ --agentArchitecture=None \ --agentFilepath=None \ --opponentArchitecture=None \ --opponentFilepath=None \ --epsilons="[1.0]" \ --temperature=0 dataset_filepath="./learn_tictactoe/output_tictactoe_generate_positions_expectations_level0/dataset.csv" python train/train_agent.py \ $dataset_filepath \ --outputDirectory="./learn_tictactoe/output_tictactoe_train_agent_level1" \ --game=tictactoe \ --randomSeed=0 \ --validationRatio=0.2 \ --batchSize=64 \ --architecture=SaintAndre_1024 \ --dropoutRatio=0.5 \ --learningRate=0.0001 \ --weightDecay=0.00001 \ --numberOfEpochs=$NUMBER_OF_EPOCHS \ --startingNeuralNetworkFilepath=None for level in {1..16}do dataset_filepath="./learn_tictactoe/output_tictactoe_generate_positions_expectations_level${level}/dataset.csv" python preprocessing/generate_positions_expectations.py \ --outputDirectory="./learn_tictactoe/output_tictactoe_generate_positions_expectations_level${level}" \ --game=tictactoe \ --numberOfGames=$NUMBER_OF_GAMES \ --gamma=0.95 \ --randomSeed=0 \ --agentArchitecture=SaintAndre_1024 \ --agentFilepath="./learn_tictactoe/output_tictactoe_train_agent_level${level}/SaintAndre_1024.pth" \ --opponentArchitecture=SaintAndre_1024 \ --opponentFilepath="./learn_tictactoe/output_tictactoe_train_agent_level${level}/SaintAndre_1024.pth" \ --epsilons="[0.5, 0.5, 0.1]" \ --temperature=0 declare -i next_level=$((level + 1)) python train/train_agent.py \ "./learn_tictactoe/output_tictactoe_generate_positions_expectations_level${level}/dataset.csv" \ --outputDirectory="./learn_tictactoe/output_tictactoe_train_agent_level${next_level}" \ --game=tictactoe \ --randomSeed=0 \ --validationRatio=0.2 \ --batchSize=64 \ --architecture=SaintAndre_1024 \ --dropoutRatio=0.5 \ --learningRate=0.0001 \ --weightDecay=0.00001 \ --numberOfEpochs=$NUMBER_OF_EPOCHS \ --startingNeuralNetworkFilepath="./learn_tictactoe/output_tictactoe_train_agent_level${level}/SaintAndre_1024.pth" doneLo script cicla attraverso chiamate a due programmi:
- generate_positions_expectations.py: Simula partite e memorizza gli stati di gioco con il rendimento atteso scontato.
- train_agent.py: Addestra la rete neurale per alcune epoche sul dataset generato più recentemente.
Il ciclo di addestramento
L’apprendimento del gioco da parte dell’agente avviene attraverso un ciclo di generazione di partite e addestramento per prevedere l’esito della partita dallo stato di gioco:
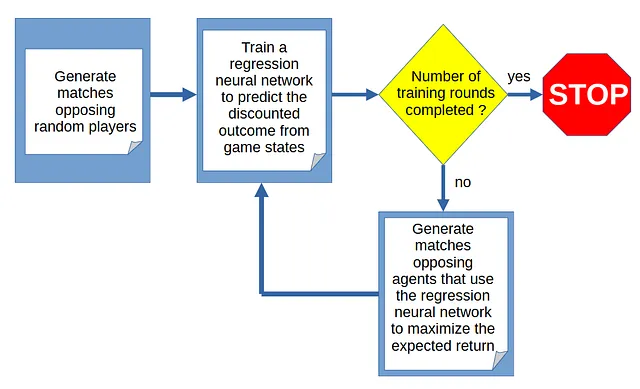
Generazione di partite
Il ciclo inizia con la simulazione di partite tra giocatori casuali, cioè giocatori che scelgono casualmente dalla lista delle azioni legali in un dato stato di gioco.
Perché stiamo generando partite giocate casualmente?
Questo progetto riguarda l’apprendimento tramite auto-gioco, quindi non possiamo fornire all’agente alcuna informazione a priori su come giocare. Nel primo ciclo, poiché l’agente non ha idea delle mosse buone o cattive, le partite devono essere generate tramite gioco casuale.
La Figura 2 mostra un esempio di una partita tra giocatori casuali:
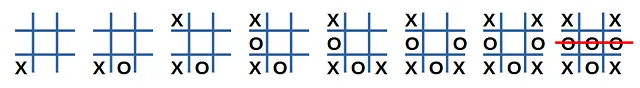
Che lezione possiamo imparare osservando questa partita? Dal punto di vista del giocatore ‘X’, possiamo assumere che questo sia un esempio di gioco scadente poiché si è conclusa con una sconfitta. Non sappiamo quali mosse siano responsabili della sconfitta, quindi supporremo che tutte le decisioni prese dal giocatore ‘X’ siano state sbagliate. Se alcune decisioni sono state buone, scommettiamo sulle statistiche (altre simulazioni potrebbero passare attraverso uno stato simile) per rettificare il valore previsto dello stato.
L’ultima azione del giocatore ‘X’ ha un valore di -1. Le altre azioni ricevono un valore negativo scontato che decadono geometricamente per un fattore γ (gamma) ∈ [0, 1] man mano che andiamo all’indietro verso la prima mossa.
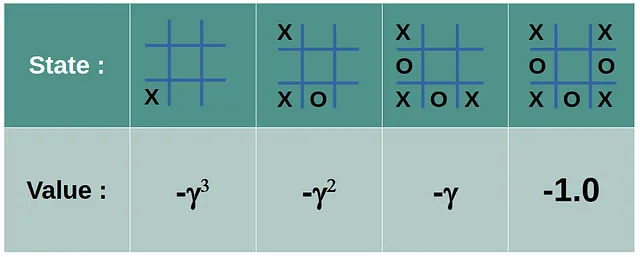
Gli stati delle partite che hanno portato a una vittoria ricevono valori scontati positivi simili. Gli stati estratti dai pareggi ricevono un valore di zero. L’agente assume il punto di vista del primo e del secondo giocatore.
Gli stati di gioco come tensori
Abbiamo bisogno di una rappresentazione tensoriale per lo stato di gioco. Utilizzeremo un tensore [2x3x3] in cui la prima dimensione rappresenta i canali (0 per ‘X’ e 1 per ‘O’), e le altre due dimensioni rappresentano le righe e le colonne. L’occupazione di una casella (riga, colonna) viene codificata come 1 nell’elemento (canale, riga, colonna).
![Figura 4: Rappresentazione dello stato di gioco tramite un tensore [2x3x3]. Immagine dell'autore.](https://miro.medium.com/v2/resize:fit:640/format:webp/1*MJ0TM_9SmsJBGi01mufQxA.png)
Le coppie di (tensore di stato, valore target) ottenute dalla generazione di partite costituiscono il dataset su cui la rete neurale si addestrerà in ogni round. Il dataset viene creato all’inizio del ciclo, sfruttando l’apprendimento che è avvenuto nei round precedenti. Mentre il primo round genera un gioco completamente casuale, quelli successivi generano partite gradualmente più realistiche.
Iniezione di casualità nel gioco
Il primo turno di generazione delle partite oppone giocatori casuali. I turni successivi oppongono l’agente a se stesso (da qui il termine “self-play”). L’agente è dotato di una rete neurale di regressione addestrata per prevedere l’esito della partita, il che gli consente di scegliere l’azione legale che produce il valore atteso più alto. Per promuovere la diversità, l’agente sceglie le azioni in base a un algoritmo epsilon-greedy: con probabilità (1-ε), viene scelta l’azione migliore; altrimenti, viene scelta un’azione casuale.
Addestramento
La Figura 5 mostra l’evoluzione delle perdite di validazione durante cinque epoche per un massimo di 17 turni di addestramento:
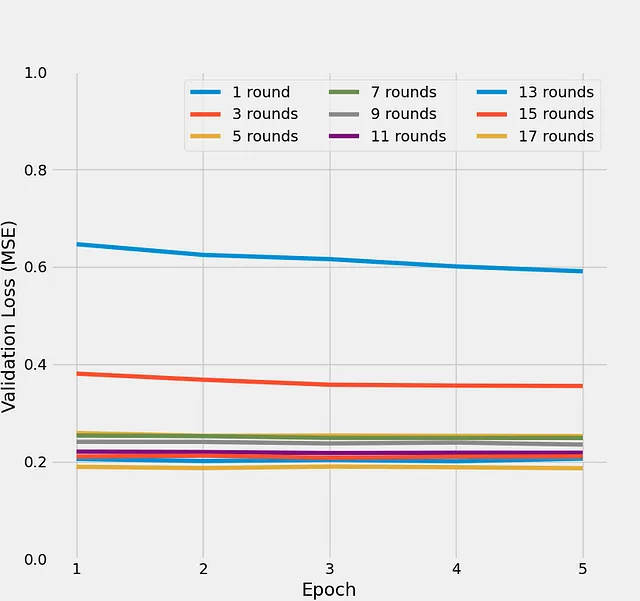
Possiamo vedere che i primi pochi turni di addestramento mostrano una rapida diminuzione delle perdite di validazione, dopodiché sembra esserci un plateau intorno a una perdita di errore quadratico medio di 0,2. Questo trend mostra che la rete neurale di regressione dell’agente migliora nella previsione dell’esito di una partita giocata contro se stessa, da uno stato di gioco dato. Poiché le azioni di entrambi i giocatori sono non deterministiche, c’è un limite alla prevedibilità dell’esito della partita. Questo spiega perché la perdita di validazione smette di migliorare dopo alcuni turni.
Miglioramento da un turno all’altro
Con il gioco SumTo100, potevamo rappresentare lo stato su una griglia 1D. Tuttavia, con il tris, non possiamo visualizzare direttamente l’evoluzione del valore dello stato. Una cosa che possiamo fare per misurare il miglioramento è mettere l’agente contro la versione precedente di se stesso e osservare la differenza tra le vittorie e le sconfitte.
Utilizzando ε = 0,5 per la prima azione di entrambi i giocatori e ε = 0,1 per il resto della partita, eseguendo 1000 partite per confronto, ecco cosa otteniamo:
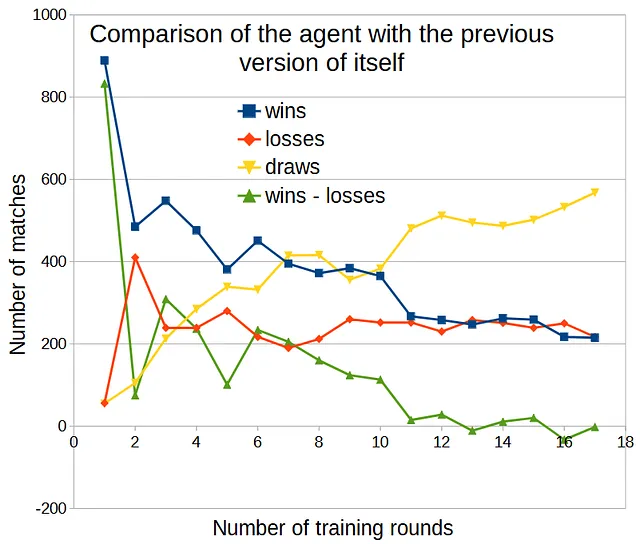
Il numero di vittorie superava il numero di sconfitte (mostrando un miglioramento) fino a 10 turni di addestramento. Dopo di che, l’agente non ha migliorato di turno in turno.
Test
È ora di vedere come gioca il nostro agente a tris!
Una caratteristica utile di avere una rete neurale di regressione è la possibilità di visualizzare la valutazione dell’agente di ogni mossa legale. Giochiamo una partita contro l’agente, mostrando come giudica le sue opzioni.
Gioco manuale
L’agente inizia, giocando ‘X’:
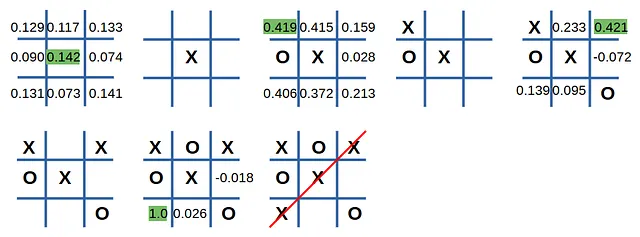
Ecco come vieni brutalmente schiacciato da una macchina senza anima a tris!
Appena ho messo l’O nella casella (1, 0), il rendimento atteso è aumentato da 0,142 a 0,419, e il mio destino è stato sigillato.
Vediamo come se la cava quando l’agente gioca per secondo:
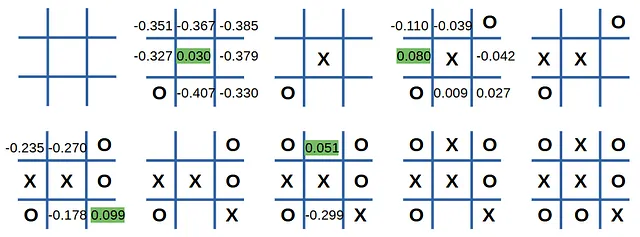
Non è caduto nella trappola e la partita è finita in pareggio.
Partite contro un giocatore casuale
Se simuliamo un gran numero di partite contro un giocatore casuale, ecco cosa otteniamo:
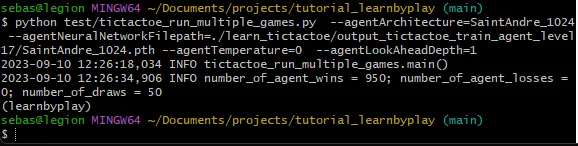
Su 1000 partite (l’agente ha giocato per primo in metà delle partite), l’agente ha vinto 950 partite, non ha perso nessuna e ci sono state 50 pareggi. Questo non è una prova che il nostro agente stia giocando in modo ottimale, ma ha sicuramente raggiunto un buon livello di gioco.
Conclusioni
Come continuazione di Training an Agent to Master a Simple Game Through Self-Play, in cui il gioco era facile da risolvere e lo spazio degli stati era piccolo, abbiamo utilizzato la stessa tecnica per padroneggiare il tris. Anche se si tratta ancora di un problema giocattolo, lo spazio degli stati del tris è abbastanza grande da richiedere alla rete neurale di regressione dell’agente di trovare dei pattern nei tensori di stato. Questi pattern permettono la generalizzazione per tensori di stato non visti in precedenza.
Il codice è disponibile in questo repository. Provateci e fatemi sapere cosa ne pensate!