Prova pratica con l’apprendimento supervisionato Regressione lineare
Pratica con la regressione lineare supervisionata

Panoramica di base
La regressione lineare è l’algoritmo fondamentale di apprendimento supervisionato per la previsione delle variabili target continue in base alle caratteristiche di input. Come suggerisce il nome, si assume che la relazione tra la variabile dipendente e la variabile indipendente sia lineare. Quindi, se proviamo a tracciare la variabile dipendente Y in funzione della variabile indipendente X, otterremo una linea retta. L’equazione di questa linea può essere rappresentata da:
- Python in Excel Questo cambierà per sempre la Data Science
- Tecniche di Apprendimento Ensemble Una Guida con Random Forest in Python
- Binny Gill, Fondatore e CEO di Kognitos – Serie di interviste
Dove,
- Y Output previsto.
- X = Caratteristica di input o matrice delle caratteristiche nella regressione lineare multipla
- b0 = Intersezione (dove la linea interseca l’asse Y).
- b1 = Pendenza o coefficiente che determina la ripidezza della linea.
L’idea centrale nella regressione lineare ruota attorno alla ricerca della linea di miglior adattamento per i nostri punti dati in modo che l’errore tra i valori effettivi e previsti sia minimo. Lo fa stimando i valori di b0 e b1. Utilizziamo quindi questa linea per effettuare previsioni.
Implementazione usando Scikit-Learn
Ora capisci la teoria alla base della regressione lineare, ma per solidificare ulteriormente la nostra comprensione, costruiamo un semplice modello di regressione lineare utilizzando Scikit-learn, una popolare libreria di apprendimento automatico in Python. Segui i passaggi per una migliore comprensione.
1. Importa le librerie necessarie
Prima di tutto, è necessario importare le librerie richieste.
import os
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error
2. Analisi del dataset
Puoi trovare il dataset qui. Contiene file CSV separati per l’addestramento e il test. Visualizziamo il nostro dataset e analizziamolo prima di procedere.
# Carica i dataset di addestramento e test dai file CSV
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
# Visualizza le prime righe del dataset di addestramento per comprendere la sua struttura
print(train.head())
Output: 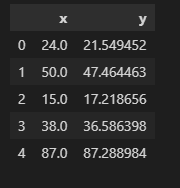
Il dataset contiene 2 variabili e vogliamo prevedere y in base al valore x.
# Verifica le informazioni sui dataset di addestramento e test, come i tipi di dati e i valori mancanti
print(train.info())
print(test.info())
Output:
RangeIndex: 700 entries, 0 to 699
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 x 700 non-null float64
1 y 699 non-null float64
dtypes: float64(2)
memory usage: 11.1 KB
RangeIndex: 300 entries, 0 to 299
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 x 300 non-null int64
1 y 300 non-null float64
dtypes: float64(1), int64(1)
memory usage: 4.8 KB
L’output precedente mostra che abbiamo un valore mancante nel dataset di addestramento che può essere rimosso con il seguente comando:
train = train.dropna()
Inoltre, verifica se il tuo dataset contiene duplicati e rimuovili prima di alimentarlo al tuo modello.
duplicates_exist = train.duplicated().any()
print(duplicates_exist)
Output:
Falso
2. Preparazione del Dataset
Ora, prepara i dati di addestramento e di test e il target con il seguente codice:
#Estrazione delle colonne x e y per il dataset di addestramento e di test
X_train = train['x']
y_train = train['y']
X_test = test['x']
y_test = test['y']
print(X_train.shape)
print(X_test.shape)
Output:
(699, )
(300, )
Puoi vedere che abbiamo un array unidimensionale. Sebbene tecnicamente si possano utilizzare array unidimensionali con alcuni modelli di apprendimento automatico, non è la pratica più comune e potrebbe comportare comportamenti inaspettati. Pertanto, riorganizzeremo il tutto in (699,1) e (300,1) per specificare esplicitamente che abbiamo una singola etichetta per ogni punto dati.
X_train = X_train.values.reshape(-1, 1)
X_test = X_test.values.reshape(-1,1)
Quando le caratteristiche sono su diverse scale, alcune possono dominare il processo di apprendimento del modello, portando a risultati incorretti o subottimali. A tal fine, eseguiamo la standardizzazione in modo che le nostre caratteristiche abbiano una media di 0 e una deviazione standard di 1.
Prima:
print(X_train.min(),X_train.max())
Output:
(0.0, 100.0)
Standardizzazione:
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)
print((X_train.min(),X_train.max())
Output:
(-1.72857469859145, 1.7275858114641094)
Ora abbiamo completato i passaggi essenziali di pre-elaborazione dei dati e i nostri dati sono pronti per scopi di addestramento.
4. Visualizzazione del Dataset
È importante visualizzare innanzitutto la relazione tra la variabile di destinazione e la caratteristica. Puoi farlo creando un grafico a dispersione:
# Crea un grafico a dispersione
plt.scatter(X_train, y_train)
plt.xlabel('X')
plt.ylabel('Y')
plt.title('Grafico a Dispersione dei Dati di Addestramento')
plt.grid(True) # Abilita la griglia
plt.show()
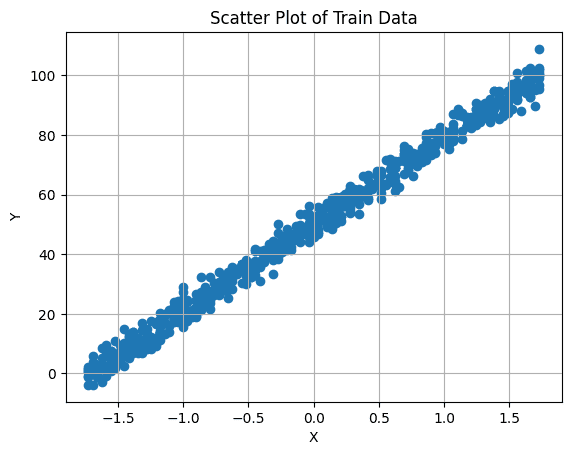
5. Creazione e Addestramento del Modello
Ora creeremo un’istanza del modello di regressione lineare utilizzando Scikit Learn e cercheremo di adattarlo al nostro dataset di addestramento. Trova i coefficienti (pendenze) dell’equazione lineare che meglio si adatta ai tuoi dati. Questa retta viene quindi utilizzata per effettuare le previsioni. Il codice per questo passaggio è il seguente:
# Crea un modello di regressione lineare
model = LinearRegression()
# Adatta il modello ai dati di addestramento
model.fit(X_train, y_train)
# Utilizza il modello addestrato per prevedere i valori di destinazione per i dati di test
predictions = model.predict(X_test)
# Calcola l'errore quadratico medio (MSE) come metrica di valutazione per valutare le prestazioni del modello
mse = mean_squared_error(y_test, predictions)
print(f'L\'errore quadratico medio è: {mse:.4f}')
Output:
L'errore quadratico medio è: 9.4329
6. Visualizza la Retta di Regressione
Puoi graficare la retta di regressione con il seguente comando:
# Grafica la retta di regressione
plt.plot(X_test, predictions, color='red', linewidth=2, label='Retta di Regressione')
plt.xlabel('X')
plt.ylabel('Y')
plt.title('Modello di Regressione Lineare')
plt.legend()
plt.grid(True)
plt.show()
Output: 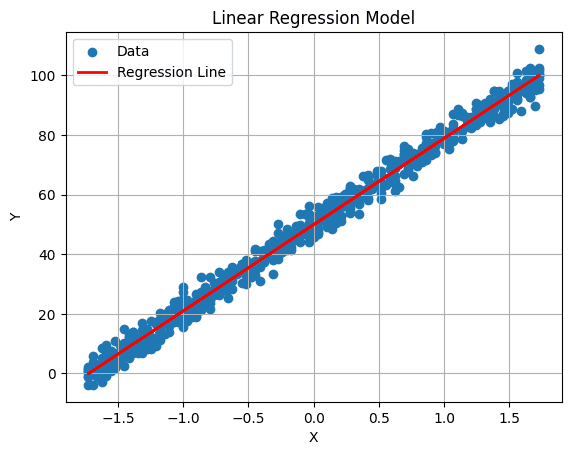
Conclusion
Ecco a voi! Hai implementato con successo un modello fondamentale di regressione lineare utilizzando Scikit-learn. Le competenze acquisite qui possono essere estese per affrontare set di dati complessi con più caratteristiche. È una sfida che vale la pena esplorare nel tuo tempo libero, aprendo le porte al mondo emozionante della risoluzione dei problemi e dell’innovazione basata sui dati. Kanwal Mehreen è una sviluppatrice di software aspirante con un forte interesse per la scienza dei dati e le applicazioni dell’IA in medicina. Kanwal è stata selezionata come Google Generation Scholar 2022 per la regione APAC. Kanwal ama condividere le conoscenze tecniche scrivendo articoli su argomenti di tendenza ed è appassionata di migliorare la rappresentanza delle donne nell’industria tecnologica.